
面向深度学习识别高空农作物的方法
2020-03-07 12:48陈小帮左亚尧王铭锋
计算机工程与设计 2020年2期
陈小帮,左亚尧,王铭锋,马 铎
(1.广东工业大学 计算机学院,广东 广州 510006;2.西安工业大学 电子信息工程学院,陕西 西安 710032)
0 引 言
早期农业研究中广泛应用了遥感技术,主要基于卫星载体和高空平台的土壤测量或植物电磁辐射,如作物生长[1]、作物土壤[2,3]、作物定位[4]、作物区绘制[5],等等。为了准确描述遥感的图像,通常需要提取各种特征,其中包括线性特征、光谱特征、纹理特征、基于对象的特征等。特别地,高空或卫星农作物图像的识别主要集中于图像的光谱信息,如通过多光谱识别农作物[4]、可见光的区分作物[6]、超光谱的作物害虫检测[7]等等。但是,受限于技术手段,多光谱传感器成像速度有限,并且在提取遥感图像的特征信息过程中不够全面,图像识别准确率还存在一定的限制。同时,样本标记的代价过高,其实施成本昂贵。因此,高光谱遥感技术对农作物高空或卫星图像处理,其性能还有很大的提升空间。
在深度学习[8,9]的热潮下,图像识别处理的卷积神经网络(convolutional neural network,CNN)能够获取各种结构丰富数据的本质特征,类似人类系统处理数据保留有用结构信息的作用,对农业图像处理也有极其有效的作用。Sa等利用深度卷积神经网络对不同水果图像进行测试,为自动农业开发提供了更为先进的物体检测方式[10];Lottes等利用卷积神经网络进行区分农作物与杂草茎,验证了该方法的可靠性并提高了茎检测的准确性[11];Kamilaris等采用深度学习技术对农业问题进行了研究,结果验证了深度学习技术优于常用的图像处理技术并可提供更高的精度[12];傅隆生等提出的深度学习模型进行多簇猕猴桃果实图像的识别方法,表明卷积神经网络在田间果实识别方面具有良好的应用前景[13]。
然而,上述研究存在两方面的不足。首先,利用卫星和载人飞机两种手段获取图像,存在时间和空间分辨率相关的问题,并且数据集的获取过程中受到诸多的因素干扰,存在一定的噪声。其次,已有研究主要以近距离拍摄的图像作为输入,鲜少以高空农作物图像直接作为输入并结合深度学习来识别农作物的工作。
鉴于此,本文运用廉价和便捷的无人机作为采集手段,利用其高空间、高分辨率的优势,更好、更方便地采集农作物图像。并针对其训练样本有限的困境,探讨如何结合数据增强、农作物图像预处理等技术,改进VGG深度学习模型,解决无人机航拍图像中的农作物识别的问题,实验验证了方法的有效性。
1 相关技术
目前,深度学习在图像识别的方向上取到较好的效果,其主要构成是卷积神经网络。采用卷积核与池化等非线性操作,搭建网络模型,可对多媒体数据具有很强的识别感知能力。并且,当目标领域中仅有少量有标签的样本数据甚至没有时,迁移学习能够通过迁移已有的知识来解决该类问题。
1.1 迁移学习
为克服无人机所拍摄的图像数量过少,优化参数预训练过程,则可选用已训练好权重的卷积神经网络,再用实际数据集进行有监督的参数微调,这正好与迁移学习思想一致。因此,本文引入迁移学习用于克服目标类别训练样本不足的问题。
迁移学习这种机器学习的方法是将一个预训练的模型重新用在另一个任务中,与域和任务两个概念有关,其定义可参见文献[14]。在概率论的角度中,可表示为P(Y|X), 因此,任务可表示为T={Y,P(Y|X)}。
给定一个源域Ds, 一个对应的源任务Ts, 还有目标域Dt以及目标任务Tt, 在Ds≠Dt, Ts≠Tt的情况下,通过Ds和Ts的信息,学习到目标域Dt的条件概率分布P(Yt|Xt), 因此有标签的目标样本可远远少于源样本。
模型训练需要大量图像,其采集工作量巨大。而引入迁移学习,一方面极大地减少训练图像数据集的规模,减轻无人机拍摄的工作量,同时可提高图像训练速度的问题。Maxime 等[15]在VOC2007和VOC2012上利用迁移学习方法训练权重得到了很好的效果。
1.2 VGG模型
CNN是大多数最先进的计算机视觉解决方案的核心,适用于各种任务。它将特征提取和分类两个模块集成一个系统,通过识别图像的特征来进行提取并基于有标签数据进行分类。随着时间的推移,所提出的CNN架构的准确度越来越高。典型的深度CNN主要由卷积层、池化层和全连接层组成,将原始像素级别的特征抽象成表达能力强的高层特征,提供简易、高效的特征选取过程。
在此,本文只针对VGG16[16]原模型进行介绍。该模型为牛津大学VGG组提出,通过多次重复使用同一大小的卷积核来提取更复杂和更具表达性的特性,如图1所示。
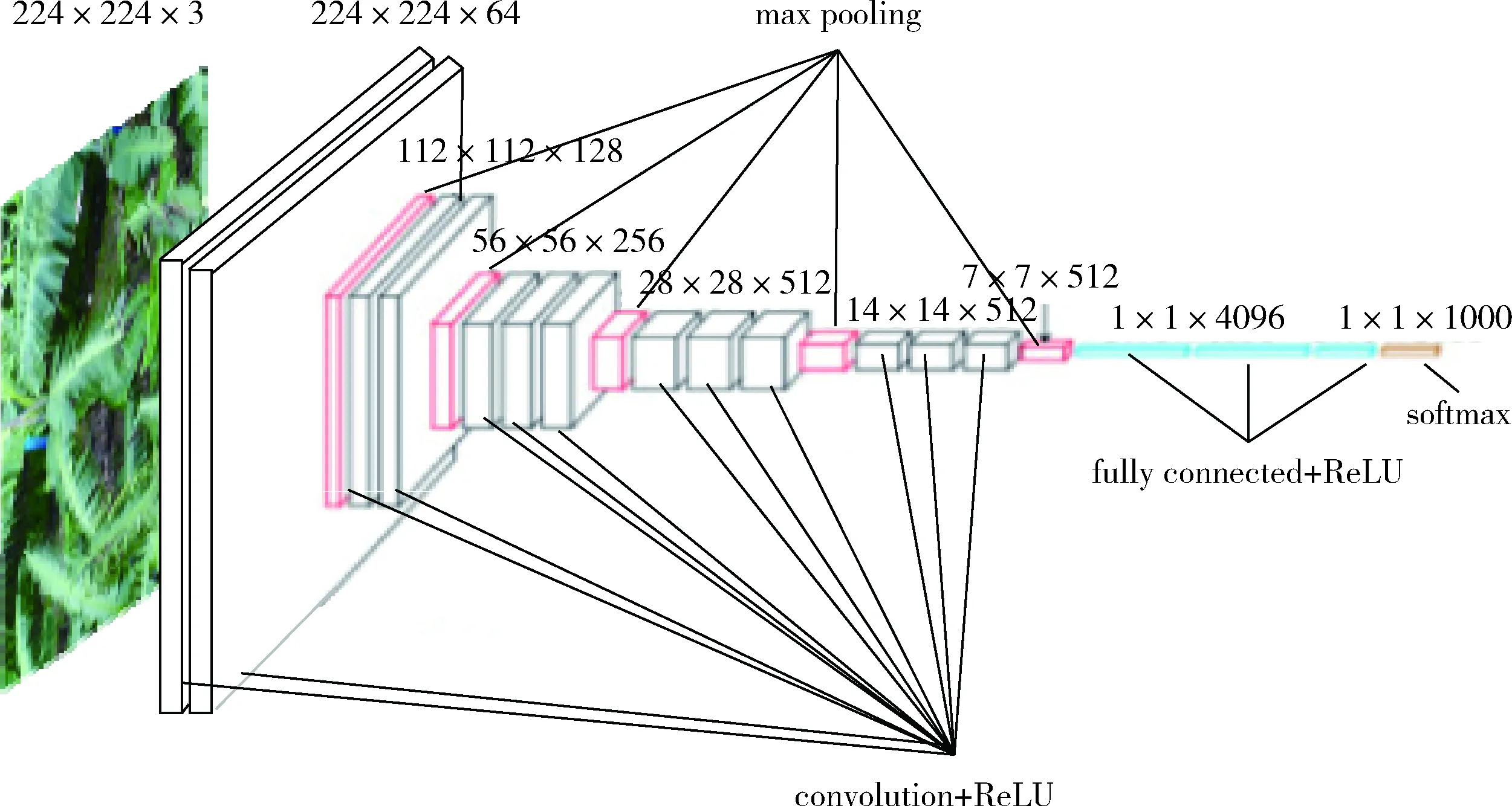
图1 原模型VGG16
其网络中含有参数的有16个层,采用若干个卷积层,之后紧跟一个可以压缩图像大小的池化层作为模型的基本框架。其中包含13个卷积层,有5个池化层,有3个全连接层与1个Softmax层。各部分采用计算算法如下:
(1)卷积层。可提取图像的不同特征,其尺寸计算原理如式(1)和式(2)
(1)
(2)
式中:ho、hi为输出、输入高度;wo、wi为输入、输出宽度;hk、wk为卷积核高度、宽度;p为填充;s为步长;网络模型统一采用3×3的卷积核。利用j个不一样的卷积核对图像进行卷积,可生成j个不一样的特征图,卷积层计算公式如式(3)所示
(3)
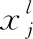
(2)池化层。主要对输入进行抽样,聚合统计卷积层的不同特征,减少特征计算量,防止过拟合。其操作运算原理如式(4)所示
(4)
(3)全连接层。第一个全连接层FC1有4096个节点,上一层POOL2是7×7×512=25088个节点,则该传输需要4096×25088个权值,所以其内存开销很大。在softmax中,类标签y可取k个不同的值,对于输入的x, 设函数p(y=j|x;w) 是x属于类别j的概率值,则计算公式如式(5)所示
(5)
式中:w为模型参数。
(4)激活函数。每个隐层的激活单元都是ReLU。相比其它激活函数,在线性函数中,深度网络中的ReLU表达能力更强;而在非线性函数中,ReLU可令模型的收敛速度维持在一个稳定状态。利用ReLU能够在稀疏后的模型中更好地挖掘相关特征,拟合训练数据。其激活函数定义如式(6)所示
f(x)=max(0,x)
(6)
2 模型改进
为了构建更适用于高空农作物图像识别的模型,通过对高空农作物图像进行特征分析,利用增强前后模型的识别准确度的变化,分别对3种模型进行实验对比和分析,选取其适合的模型。并在此基础上对模型进行了改进,以提高模型的识别率。
2.1 特征分析
本文利用无人机拍摄的农作物图像与以往的图像识别数据有较大的区别,比如高度和视角不同,会导致所拍摄的图像大小和形状也有所差异,对图像处理带来一些挑战。
就拍摄距离而言,农作物图像为高空图像,与近距离产生的图像相比,难于利用一般的神经网络进行特征提取与识别;另外,近距离的图像通常为单一类别,而高空的农作物图像包含了多种类别。无人机拍摄图像覆盖面积广大,包含多种作物,从而增加农作物分类识别的困难。
同时,要求所采用的神经网络能实现较高的识别率,能够对特征不分明情况下的农作物识别。比如通过输出花的数据集与无人机拍摄图像的特征,对比第一个卷积层的特征输出,如图2所示,可发现,肉眼便可以识别出近距离的雏菊,但难于准确辨认高空拍摄的黄瓜。

图2 近距离植物与高空植物卷积层特征
2.2 模型的对比
为找出更加适合农业图像识别的模型,对Inception-V3、VGG16和VGG19这3种模型进行对比,通过实验进行选优。保证客观性,所有模型的基本参数都设置为:学习率为0.01;迭代次数为10 000次;采用花的数据[17],其中包含5种花,共3670张图片,经过翻转增加了1倍的数据。
通过实验,3种模型在数据翻转前后的准确率见表1。
本文对比3种模型在数据翻转后的准确率。用花的数据集翻转后,Inception-V3准确率反而降低了,另外两种模型都有所提高。
而反观VGG16和VGG19两者之间的准确率,相差并

表1 3种模型在数据翻转前后的平均准确度
不大,但前者平均精度更高,在训练过程中比后者更快,性能更好,因此本文选取VGG16为基本的模型。
在花的数据集上,VGG能得到很好的表达效果,但是部署在GPU上并非易事,因为该网络模型在内存和时间上的计算要求比较高。VGG的卷积层通道数大,且网络架构weight数量相当大,很消耗磁盘空间,训练非常慢,由于其全连接节点的数量较多,再加上网络比较深,VGG16有533 MB+,VGG19有574 MB。这使得部署VGG比较耗时。
2.3 拟合优化
为了防止训练数据不足而导致过拟合,本文在原模型的第二个全连接层fc7添加正则化因子,提高图像的识别率。
此外,考虑到获取更好的分类结果,本文采用SVM分类器[18]替换掉原模型VGG16的分类器Softmax。由Vapnik开发的SVM用于二分类,其目标是找到最佳超平面f(w,x)=w·x+b以分隔给定的数据集成为两类。SVM通过优化参数w解决问题
(7)
其中,WTW是L1标准化,C是惩罚因子, y′是实际标签,b是阈值。
为了优化拟合问题,提供更稳定的结果,采用hinge loss函数
(8)
为验证改进模型的效果,本文默认正则因子为0.04,采用上文提到的花的数据进行训练,迭代次数均设置为 10 000 次,批处理BatchSize为200,并设置学习速率为0.01。设置SVM惩罚因子为9个因子,分别为0.1、0.2、0.3、0.4、0.5、0.6、0.7、0.8和0.9,实验结果表明,加入正则化后所得到的准确率几乎比无正则化的高,其对比结果如图3所示。
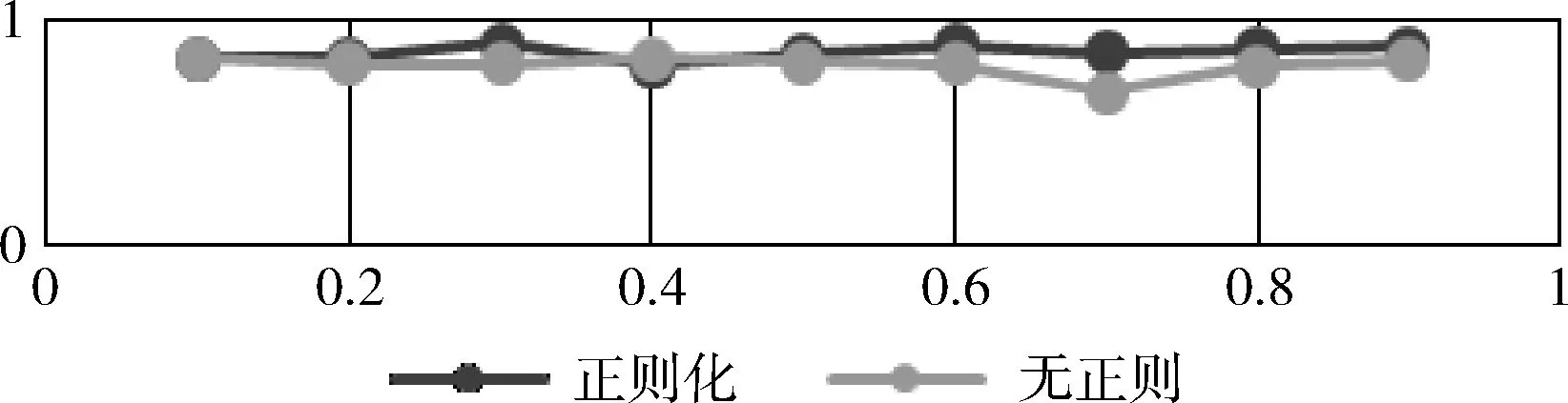
图3 模型有无正则化的准确率对比
原模型VGG16与改进后模型对比。两种模型均用 Imagenet 数据集训练好了权重,再采用花的数据进行训练与测试,迭代次数均设置为10 000次,批处理BatchSize为200,并设置学习速率为0.01。原模型获得精度为0.885,在不改变正则化因子并均设置为0.04下,调整分类器SVM的惩罚因子为0.3时,改进后的模型精度为0.8904。因此,改进后的模型识别率更高,而且可进行因子调整,从而提高识别率,灵活性更强,更适合作为农作物图像识别的模型。
3 识别处理
确定好模型之后,研究工作进入农作物图像识别的过程。本研究采用Phantom 4 Advanced无人机拍摄。有效像素为20 MP,镜头距离地面为5 m、10 m、15 m、30 m,可清晰拍摄尺寸为5472像素×3078像素的图像,图像格式为jpeg,水平分辨率与垂直分别率均为72dpi。
为解决图像数据不足的问题,在进行农作物图像识别之前,除了采用迁移学习思想,还进行了图像数据增强。并且,分析高空农作物图像特点,进行预处理以提高图像识别率。
本文处理平台为笔记本计算机,处理器为Inter(R)Core(TM)i5-8250U CPU@1.60 GHz×8,磁盘为109.4GB,运行环境为:Ubuntu18.04.1 64位、python3、pycharm2018.2.1社区版、tensorflow1.10版本以及可视化工具tensorboard、jupyter,选取的框架为Tensorflow[19]。
3.1 数据增强有效性
为了克服无人机拍摄的农作物图像数据少,远远不满足模型训练的特征提取的缺点,需利用标记好的原始图片进行裁剪,从而增强数据,以防止图像数据过度拟合。
一般增加训练数据可通过图像滑动、图像旋转、光学畸变、渐晕效果、颜色渐变、图像裁剪等方法,从而使得图像的鲁棒性得到提高。Krizhevsky等[20]曾利用ImageNet进行实验并得到了很好的验证效果。此外,结合百度的最新研究成果[21],其中的数据增强实现误差为5.3%,是 ImageNet 上达到的最好结果,表2为1张图进行图像增强后的数据量。从表中可知颜色渐变与图像裁剪方式增加的数据量比较大。然而,神经网络对光源变换、颜色变换比较敏感,图像在改变光照、变换神经网络的情况下,目标农作物将被识别成另外一类。在此,本文主要采用裁剪的方式增加数量集。一方面可以保证数据集的增加,同时也能减少工作量节约时间。
按照VGG模型输入层的要求,分割图片为224像素×224像素。由于无人机高空拍摄的目标农作物处于中心范围,在原始5472像素×3078像素的图片中心上裁剪出2240像素×2240像素的中心图片,再将中心图片分割成100张224像素×224像素的图片并编号为n_1到n_100。
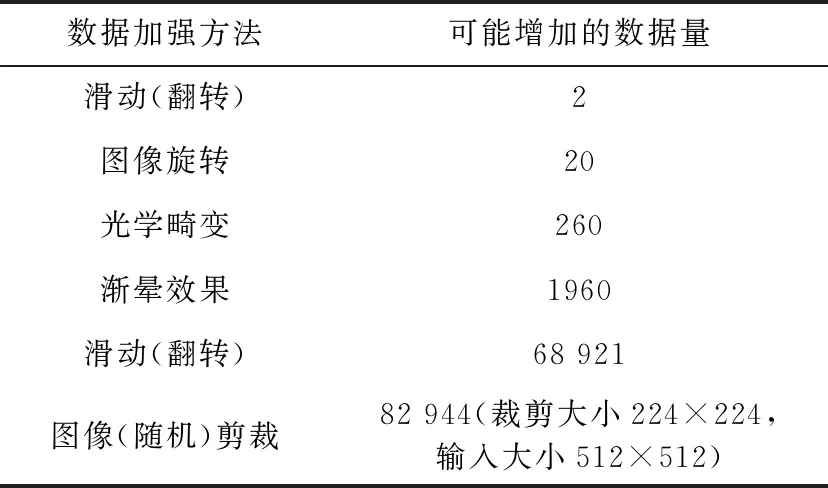
表2 不同增强方式的可能增加数量
n张原始图片有n张中心图片,可分割成100n张224像素×224像素的图片,由此可实现一变多而增加样本数量。图像数据增强过程如图4所示。
尽管通过数据增强对数据量进行扩充,但是为了进一步补充训练数据的有效性,还通过google搜索图像的方式,获取无人机所拍摄的农作物类别,人工挑选充实到图像训练样本集合。
为了验证数据增强对数据训练是否有效,利用改进的模型,进行数据集增强前后的实验。对花的数据集翻转后,其数据集比原来的增加了1倍,默认正则化因子为0.04,迭代次数均设置为10 000次,并设置学习速率为0.01,调整上文提到的SVM的9个惩罚因子。实验结果表明,翻转后的准确率在惩罚因子为0.04时达到了0.9082,其对比如图5所示。

图4 图像数据裁剪增强过程
通过实验数据显示,利用花的原数据进行训练的准确率有较大的波动,翻倍后,准确率波动相对不大,并且都能在0.8以上,存在最高准确率,因而,数据翻倍后对模型识别准确度是有效的。
3.2 数据处理的对比
在数据预处理中,通常可以删除不相关的实例以及噪声或冗余数据,如此高质量的数据将带来高质量的结果并降低数据挖掘的成本。
本文先利用裁剪后的农作物图像进行翻转增加1倍数据集,生成图片路径和标签列表,随机打乱数据集,防止特定序列对学习带来不利的影响。进而设置队列,将图片分批次载入,这样在训练时可从队列中获取一个batch,传送至网络训练,又有新的图片进入队列,循环反复。如此,队列能起到训练数据到网络模型间的数据管道的作用,减少一时过多地占用内存。在读取到图片后,则进行图像格式解码,防止不同类型的图像混在一起,这里图像统一用jpeg。
此外,无人机拍摄的为农作物彩色图像,而识别的彩色图像所包含的信息量较大,受光源变换以及颜色变换等比较敏感,也会增加数据训练的成本,本文对图像特征进行归一化,将像素值缩放到[0,1],并进行白化从而获取好的特征。为了提高数据的准确率,对农作物数据集进行了灰度处理,分别保存为无灰度和灰度的两种数据集,并利用改进的模型进行了实验。实际数据集为9类农作物,训练数据、测试集与验证集按8∶1∶1比例,所设置迭代次数均为10 000次,学习速率为0.001,正则化因子为0.04,通过调整上文提到的分类器SVM的9个惩罚因子,最后得到数据集有无灰度化的准确率,如图6所示。

图6 有无灰度化的准确率
实验数据显示,当SVM惩罚因子为0.8时,两种数据集分别取得最高的准确率0.9680与0.9817。并且,经过灰度化的农作物数据集普遍比无灰度化的数据集的准确率高,由此易看出,经过灰度处理,更有利于提取高空农作物图像的特征,提高图像识别准确率。
3.3 训练的变化图
为克服数据集不足的缺点,结合迁移学习的思想,利用Imagenet数据集为VGG16模型提供最优的初始权值,再通过预处理后的农作物图像对上文改进的模型结构进行微调。实际高空农作物图像数据集为9类农作物,训练数据、测试集与验证集按8∶1∶1比例,实验设置迭代次数均为10 000次,学习速率为0.001。通过TensorBoard获取测试集的准确率与损失函数图,其变化如图7所示。

图7 准确率与损失度
结果显示,在迭代次数不断增加情况下,测试集的分类误差逐渐降低,随着训练迭代到4000次时,准确率便趋于稳定,且后面验证集和训练集间的误差值相差不大,由此可得模型具有良好状况。4000次迭代后,训练损失值基本上收敛稳定,说明网络模型训练已达到了预期的效果。
3.4 识别结果
首先,结合迁移学习的思想,采用Imagenet训练好权重的VGG16模型实现农作物图像的识别。Imagenet数据集包含1000类的自然场景图像,图像总量大于100万,与识别目标农作物图像具有相似性,利用它进行大规模网络训练是比较合适的。在给定的Imagenet数据集为一个源域Ds和识别出该数据集图像为学习任务Ts, 无人机拍摄的图像作为目标域Dt和识别出农作物为目标学习任务Tt。 通过利用Ds和Ts中的知识,迁移学习便能实现目标预测函数f(*) 在Dt中性能的提高。其过程如图8所示。
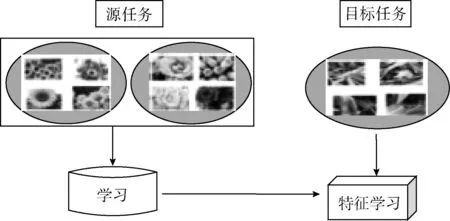
图8 迁移学习过程
在实际的农作物图像数据集中,包含两种输入,一种是模型微调时已标记农作物图像的输入,另一种为待识别农作物图像的输入,每种数据集均需要进行灰度化、去均值等预处理,使图像符合网络训练的要求。
其次,对训练好权重的VGG16模型进行改进。在其第二个全连接层添加正则化因子,并将分类器softmax改为SVM分类器,实现模型优化,防止过拟合。
接着,利用已标记农作物图像对改进的模型进行微调,合理丢弃数据,防止过拟合,计算识别结果和标记的差异,调整参数,以此达到较高的识别准确率。
最后,保存微调后的参数,输入待识别农作物图像,通过SVM分类器显示识别结果。
完整的农作物图像识别算法如图9所示。

图9 农作物图像识别算法
随机选取一张无人机高空拍摄的农作物图像,预处理后,输入到上文微调好的模型中进行图像识别,所得结果如图10所示。该结果为最后全连接层的特征分类,显示玉
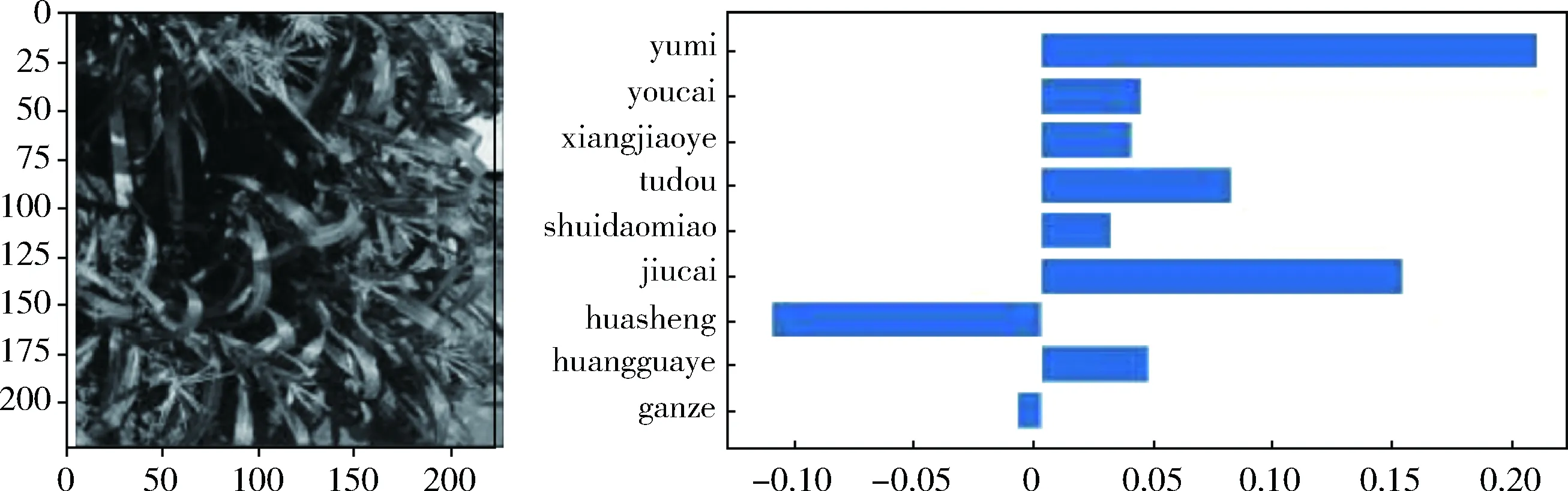
图10 随机测试识别结果
米所占的特征概率比较大,与实际相符。然而,特征概率值并不高,说明高空图像识别的特征提取还有待完善。
4 结束语
本文通过迁移学习和数据增强方式有效地解决了无人机拍摄的目标图像数据集少造成的不足。分析高空拍摄农作物图像的特点,对输入图像进行预处理并改进传统模型,提高模型的精确度与农作物的识别率。然而,高空图像的特征提取还不够完善,所取得的结果还有待提高,是本文接下来的工作。能将深度学习与农业相结合、农业与无人机结合、深度学习与无人机结合,对促进传统农业向现代农业的发展,具有很高的研究价值与应用前景。
猜你喜欢
今日农业(2022年16期)2022-11-09
今日农业(2022年15期)2022-09-20
今日农业(2022年13期)2022-09-15
环球时报(2022-02-28)2022-02-28
今日农业(2021年16期)2021-11-26
电子制作(2019年16期)2019-09-27
中国交通信息化(2019年4期)2019-07-13
小天使·一年级语数英综合(2019年2期)2019-01-10
小天使·一年级语数英综合(2018年11期)2018-11-23
电子制作(2018年19期)2018-11-14
