
基于图学习的社会网络图像标签排序算法
2020-03-07 12:47王婧
计算机工程与设计 2020年2期
王 婧
(1.中国科学院 计算机网络信息中心,北京 100190;2.北京电子科技职业学院 电信工程学院,北京 100176)
0 引 言
随着Web2.0平台的快速发展,许多社会网络图像(Social image)共享网站(例如Flickr,Photosig,以及Instagram)蓬勃发展,此类网站允许用户上传并分享自己拍摄的照片[1]。另一方面,由于移动互联网技术,以及廉价存储设备和智能手机的普及,人们可以便捷的访问互联网。因此,海量的由用户提供的照片被迅速上传到各图像共享网站,并与其他用户分享[2,3]。图像共享网站不仅允许用户上传照片,还允许用户为照片提供描述其语义信息的词语(也称“标签”)。
图像分享网站鼓励用户为上传的照片提供语义标签,标签可以看作索引关键字,为图像赋予准确的标签将显著提高基于标签的图像检索系统的性能[4,5]。但是,用户的标注行为具有较高的主观性和多样性,部分用户提供的标签准确性和完整性都不高,甚至有些用户会提供和图像的语义信息毫无关联的标签。因此,用户提供的标签和图像的视觉内容之间存在语义鸿沟,这为社会网络图像搜索和挖掘带来了很大的困难[6]。
基于上述分析,本文旨在通过对用户提供的标签进行重排序,进而去除与图像语义信息无关的噪声标签,从而有效提高图像标签的准确性。本文的创新点主要表现在以下两个方面:
(1)提出了一种融合图像视觉相似度和标签语义相似度的加权投票方法,投票过程综合了不同用户的标注行为和标注习惯,使得标签排序结果更加客观准确。
(2)利用视觉近邻图像的标签集构造标签图模型,并充分利用近邻投票结果和图模型中标签之间的关系,利用迭代计算进行目标图像的标签排序。
1 相关工作
图像共享网站为提高图像检索系统的性能开辟了全新的研究思路,吸引了众多学者的关注。许多学者致力于研究如何为图像赋予准确的语义标签。为图像赋予准确的语义描述信息(标签)是基于文本的图像检索(text-based image retrieval,TBIR)系统的关键环节,李锡荣等对图像标签指派,图像标签优化以及基于标签的图像检索进行了综述,全面介绍了Web 2.0时代TBIR系统遇到的新问题,以及涉及的新理论和新方法[7]。
Hu等提出一种基于鲁棒多视图半监督学习模型的图像标注方法。该方法利用基于图拉普拉斯矩阵的半监督学习挖掘数据的内在结构信息[8]。Jiu等提出一种基于非线性深度核学习的图像标注方法,利用深度多层网络重新定义了多核[9]。Li等提出了一种基于弱监督深度矩阵分解算法的图像标注及优化方法,通过对弱监督标注信息、视觉结构和语义结构的协同分析[10]。Verma等提出一种两阶段K最近邻算法以及一个度量学习框架,并将其用于图像标注[11]。Feng等提出一种基于语义概念共现模式的图像标注和检索方法[12]。
针对已有的社会网络图像标签进行排序,提高图像语义信息描述的准确性,对于TBIR系统具有十分重要的意义。Li等提出基于近邻投票(neighbor voting,NV)的标签排序方法[13],该方法利用目标图像的视觉近邻为其标签进行投票,并利用投票分值进行标签排序。Liu等提出基于概率密度估计(probability density estimation,PDE)和随机漫步(random walk,RW)的标签排序方法(简称PDE-RW)[14],该方法利用概率密度估计得到标签的初始相关度,然后利用随机漫步算法对标签相关度进行优化。Zhang等提出基于压缩域视觉词语(visual words in compressed domain,VWCD)的标签排序方法[15],该方法利用SIFT特征描述子从低分辨率图像中抽取视觉词语,并在此基础上利用近邻投票策略进行标签排序。Guo等提出基于显著性检测(saliency detection,SD)的标签排序方法[16],该方法充分利用图像显著性检测结果进行标签排序,从计算机视觉的角度为图像标签排序提出了新的解决思路。
上述方法利用不同的机器学习模型和算法针对图像的语义挖掘和语义标注问题展开了研究,获得了较好的实验结果。通过对上述研究工作的深入分析,对上述研究工作存在的不足之处总结如下:
不足之处1:上述方法主要采用人工设定的图像特征描述方法(例如,SIFT特征描述子),虽然获得了较好的性能,但是与利用深度学习得到的图像特征尚有一定的差距。如果能利用深度学习框架得到更加准确的图像特征描述,对于提升图像的语义挖掘准确性具有积极意义。
不足之处2:社会网络中的图像标签是图像上传者人为设定的,存在较高的主观性以及较高的噪声。而利用上述方法进行图像的语义挖掘时对图像的初始标签有较高的依赖性,这在一定程度上限制了图像语义挖掘的准确性。
本文针对已有研究工作的不足之处展开深入研究,针对不足之处1,将SIFT特征、卷积神经网络特征以及视觉词袋模型相结合,提出了一种图像视觉特征描述方法;针对不足之处2,采用近邻投票策略以及联合多社会图像的标签图模型,将相关图像的语义信息传播至目标图像,可以较好地解决目标图像的初始语义标签不准确的问题。
2 问题描述
本文将通过研究标签排序算法解决两个主要问题:①去除噪声标签;②根据标签的语义信息与图像的视觉特征之间的相关度进行标签排序。
2.1 社会网络图像标签排序
假设社会网络图像数据集表示为Θ,标签字典表示为T。对于社会网络图像I∈Θ以及标签t∈T,将计算标签相关度的函数定义为H(t,I), 该函数应满足如下两个条件:
条件1:假设两幅社会网络图像I1,I2∈Θ以及标签t∈T, 如果标签t与图像I1的相关度高于图像I2, 则满足下述条件
H(t,I1)>H(t,I2)
(1)
条件2:假设两幅社会网络图像的标签t1,t2∈T以及社会网络图像I∈Θ, 如果标签t1比标签t2更适合描述图像I的语义信息,则满足下述条件
H(t1,I)>H(t2,I)
(2)
图1给出了社会图像标签相关度计算流程。首先,构建社会图像数据集,从该数据集中获取目标图像的视觉近邻。然后,所有视觉近邻都投票给目标图像的标签。此外,为了提高重要视觉近邻的投票权值,投票分值由视觉相似度和标签相关性加权计算得到。接下来,利用近邻投票结果,在标签图上进行随机漫步,从而计算出标签相关度。
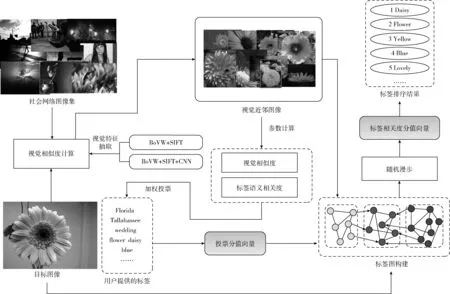
图1 社会图像标签排序流程
2.2 图像视觉相似度计算
本文将对两种图像特征描述方法进行对比分析:①视觉词袋模型(bag of visual words,BoVW)+尺度不变特征变换(scale-invariant feature transform,SIFT),②BoVW+SIFT+CNN(convolutional neural network)。
从图像训练集中抽取SIFT特征描述子,并将其进行聚类,从而学习出由256个视觉词汇构成的视觉词典。利用视觉词典,本文将一幅图像表示为256维的特征向量(简称BoVW+SIFT特征),该特征向量中的每一维对应于一个视觉词,其取值为该视觉词出现在该幅图像中的次数。本文将充分融合CNN特征与BoVW+SIFT特征,获得更为有效的图像视觉特征描述。
从图像训练集中学习出的码书(Codebook)表示为CB=(cb1,cb2,…cbk), 其中cbi表示码书中的第i个视觉词。本文将一组特征描述符表示为固定维度的向量,并将描述SIFT特征的向量s分配给与其距离最近的视觉词 (cbi=Nb(s))
(3)
对于视觉词cbi, 将其与距离最近的视觉词之间的差异进行累加,计算方法如下
(4)
式(4)的主要任务是计算视觉近邻为视觉词cbi的所有SIFT特征描述子与cbi的距离之和,并将其作为向量fv的第i个维度fvi。 在此基础上,构造128×k维向量fv
fv=[fv1,fv2,…,fvi,…,fvk],fvi∈R128
(5)
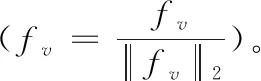
本文从GoogLeNet的pool5层中抽取1024维的CNN特征(表示为fp)。
利用式(6)对向量fv和fp进行融合
f=[fv,fp]
(6)
特征向量f的维度为2048维,利用PCA白化进行降维处理
(7)
其中,MPCA表示主成分分析(principal component analysis,PCA)变换矩阵,参数h表示降维处理后保留的特征维数,svi表示第ith个奇异值。接下来,使用L2范数归一化获取1024维的稠密向量。
在上述过程基础上,利用K-means算法学习出由1000个视觉词语构成的视觉词典,利用该词典,每幅图像都可以表示为1000维的特征向量(称为BoVW+SIFT+CNN)。
图像Ii和Ij的视觉相似度计算方法如下
(8)
其中,fi,fj分别表示图像Ii和Ij的特征向量。
3 基于图学习的标签排序算法
标签相关度是指图像的视觉特征与标签的语义信息之间的相关程度。对于目标图像Ij, 其视觉邻居Ik对标签ti的投票分数可以通过对图像视觉相似度和标签语义相似度的线性加权计算而得
Vote(ti,Ij,Ik)=λ·Simv(Ij,Ik)+(1-λ)·Sims(ti,T(Ik))
(9)
其中,λ为权值参数,Sims(ti,T(Ik)) 表示标签ti和图像Ik的标签集合T(Ik)之间的语义相似度,计算方法如下
(10)
其中,Sims(ti,tj) 表示标签ti和tj之间的语义相似度。由式(10)可知,Sims(ti,T(Ik)) 计算标签ti与标签集合T(Ik) 中各标签的语义相似度的平均值。标签ti与标签tj之间的语义距离d(ti,tj) 定义为
(11)
其中,参数N(ti) 和N(tj) 分别表示被标签ti和tj所标注的图像的数量,参数N(ti,tj) 表示同时被标签ti和tj所标注的图像的数量。参数Γ表示Google图像搜索引擎中所有图像的数量,标签ti和tj之间的语义相似度Sims(ti,tj) 可以通过如下公式计算
(12)
参数σt表示经验集。
文本构造基于标签图和随机漫步的标签相关度挖掘模型。在标签图中,标签从目标图像及其视觉邻居中过去,并将用户提供的标签视作图的顶点,标签相关性作为边权值。为降低计算开销,将低于阈值的边从标签图中去掉。有一幅目标图像及其两个视觉邻居的标签如图2所示。
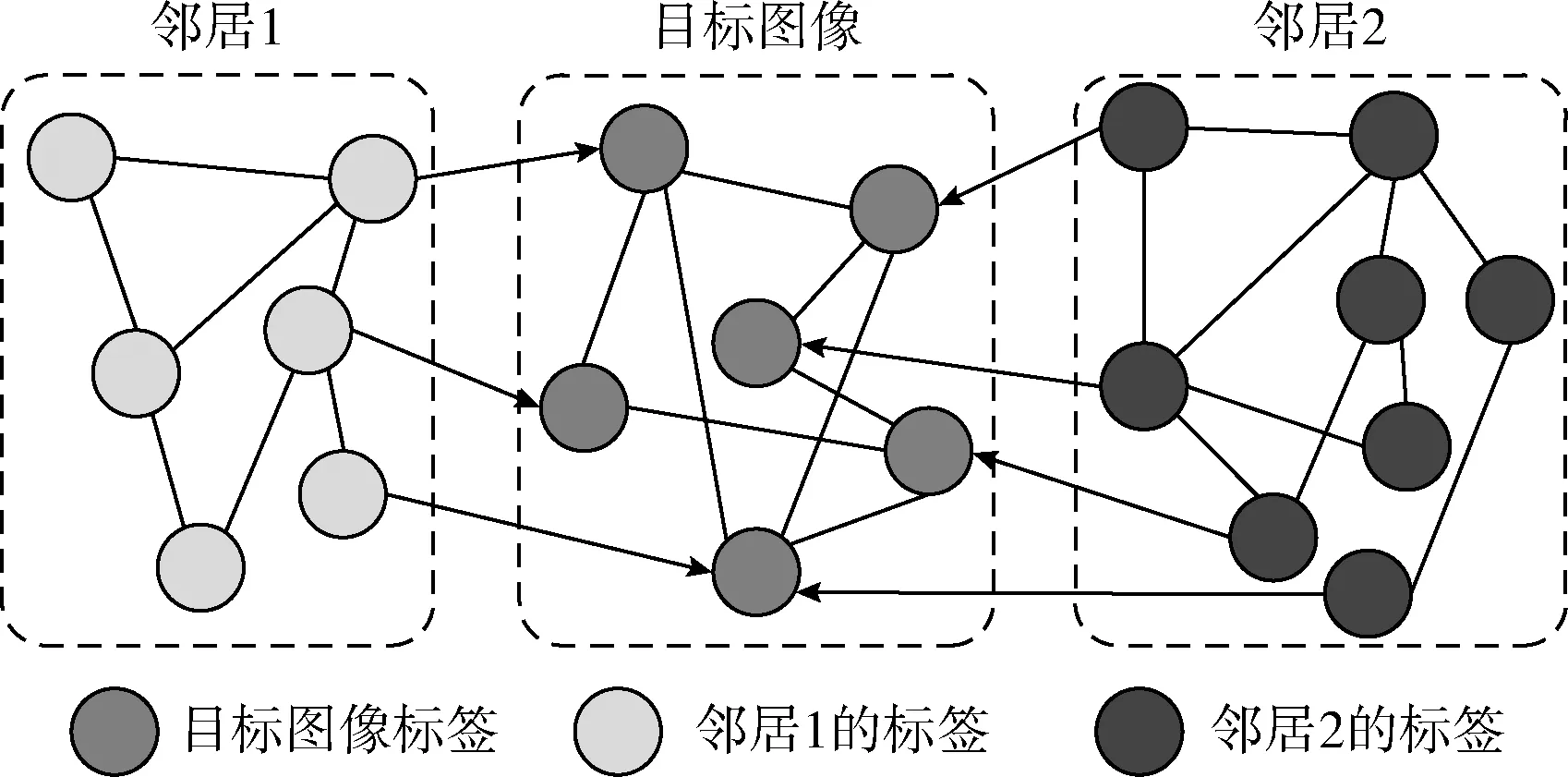
图2 标签图示例
假设标签图表示为G=(V,E), 其中V,E分别表示标签图的顶点和边,并且满足V=VS+VN。 其中,VS,VN分别表示目标图像及其视觉邻居的标签。为了防止目标图像反向影响其视觉邻居图像,目标图像和其视觉邻居之间的边是有向的,其它边是无向的。标签图G的转移概率矩阵表示为M, 该矩阵的元素mij表示由标签ti转移至tj的概率,mij的计算方法如下
(13)
概率转移矩阵M的定义如下
(14)
其中,MS和MN分别表示描述VS和VN转移概率的方阵,MSN表示存储由VN至VS的转移概率的矩阵。
算法1:基于图学习的标签排序
输入:目标图像I以及用户提供的标签集T={t1,t2,…,tN}, 视觉邻居 {I1,I2,…,IK}。
输出:标签排序结果T*。
(1)将用户提供的标签输入到维基百科,删除没有匹配项的标签,将剩余标签构成的集合表示为 {t1,t2,…,tM}。
(2)将所有视觉邻居图像的投票分值求和
(15)
其中,Votei表示所有视觉邻居对标签ti的投票权。
(3)构建投票分值向量Vote=(Vote1,Vote2,…,VoteM)。
(4)标签相关度分值向量定义为R={r1,r2,…,rM}, 其中ri表示标签ti的相关度分值。
(5)标签相关度分值向量的初始状态设置为R(0)=(1,1,…,1)。
(6)利用随机漫步算法,标签相关度分值的第lth次迭代可以通过如下公式计算得到
R(l)=(φM)lR(0)+(1-φ)(I-φM)-1(I-(φM)l)Vote
(16)
(7)标签相关度分值向量的计算方法如下
(17)
(8)根据标签相关度分值向量R对标签集{t1,t2,…,tM} 进行降序排序,排序后的标签序列表示为T*。
算法1中的参数φ(参见式(16))表示投票分数的初始状态和转移矩阵对标签相关度计算产生的影响,该算法的时间复杂度为O(n3)。
4 实验结果及分析
为验证算法的有效性,本文利用MIRFlickr25k数据集[17]进行实验,该数据集包括25 000幅Flickr图像。本文选取MIRFlickr25k数据集中常用的10个图像标签,根据这10个标签进行图像的分类和标签排序的性能评测。这10个标签为:①sky,②flower,③dog,④sea,⑤girl,⑥bird,⑦snow,⑧lake,⑨beach,⑩street。
4.1 性能评价指标
本实验采用均值平均精度(mean average precision,MAP)以及归一化折损累积增益(normalized discounted cumulative gain,NDCG)作为性能度量方法。MAP的定义中使用了平均准确性(average precision,AP),MAP表示查询集中所有查询词检索结果的平均准确性。假设q和Q分别表示查询词以及查询词集合,MAP的计算方法如下
(18)
本文实验为每个社会网络图像标签设置5个相关度等级:①非常相关(5分),②相关(4分),③一般相关(3分),④弱相关(2分)以及⑤不相关(1分)。假设一幅社会网络图像排序后的标签集为 {t1,t2,…,tn}, 则其NDCG值计算方法如下
(19)
其中,r(i) 表示标签ti的相关度,τn表示归一化常数。
4.2 参数设置
本小节实验中视觉特征统一采用BoVW+SIFT特征。
4.2.1 近邻数量的选取
近邻投票是本文方法的关键问题,而近邻数量的选取对投票结果有着至关重要的影响。因此,本文将讨论如何选取合适的近邻数量。由式(9)的投票权值计算方法可知,投票分值有两种类型的因素构成:①视觉相似度;②标签相关度。接下来,将本文方法与其它3种投票方法利用MAP值进行性能对比,具体包括:①只使用视觉相似度的加权投票;②只使用标签相关度的加权投票;③无加权投票(作为性能评测的基准)。实验结果如图3所示。

图3 不同方法的MAP值对比
如图4所示,利用本文提出的图像标签相关度计算方法,可以显著提高图像标签排序的准确性,从而有效提高MAP值。原因在于,本文提出的方法充分利用了图像的视觉特征和标签的语义信息进行加权投票,使得与目标图像具有较高相关度的近邻图像具有更高的投票权。此外,还可观察出,相比标签相关度,视觉相似度对近邻投票过程更加重要。从图4还可以看出本文提出的方法在近邻数量取6000时,MAP达到最大值。因此,在接下来的实验中,将本文方法的近邻数量设置为6000。通过分析可知,视觉近邻数量太少和太多都无法获得最优的MAP值。原因在于,视觉近邻数量过少将导致投票过程对标签语义信息的覆盖度降低;而视觉近邻数量过多将使得投票过程包含过多的噪声信息,从而降低投票的有效性。
与性能评测基准相比,包括本文方法在内的3种不同方法获得的性能提升如图4所示。

图4 MAP性能提升分析
从图4可以看出,本文提出的方法与其它加权投票策略相比,能够获得更高的MAP性能提升。当近邻数量高于9000时,基本上可以保证约20%以上的MAP性能提升。
综上,本文方法可以得到比其它方法更高的MAP值,并且对近邻数量的变化并不敏感,具有较高的鲁棒性。
4.2.2 参数λ的选取
如式(9)所示,通过对图像视觉相似度和标签语义相似度的线性加权可以计算出目标图像的投票分数。参数λ决定着图像视觉相似度和标签语义相似度对投票分值计算产生的影响。因此,λ的选取直接影响着标签相关度计算的准确性。图5中给出了近邻数量以及参数λ的取值对MAP值的影响。
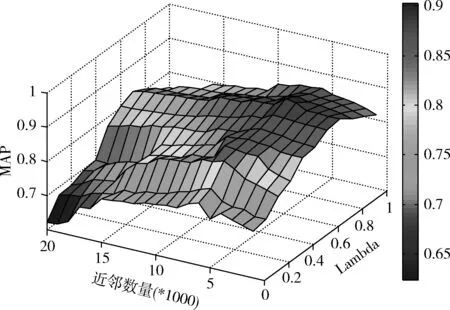
图5 参数λ的选取
由图5可知,当参数λ取0.7,近邻数量取6000时,本文方法能够得到最大MAP值。这也说明,相比标签的语义信息,图像的视觉特征对加权投票过程更加重要。
4.2.3 参数φ的选取
如式(16)所示,参数φ表示投票分数的初始状态和转移矩阵对标签相关度计算产生的影响,该参数的选取也是本文方法的关键问题之一。根据上述实验结果,将λ设置为0.7,近邻数量设置为6000,测试φ的不同取值对MAP的影响,实验结果如图6所示。
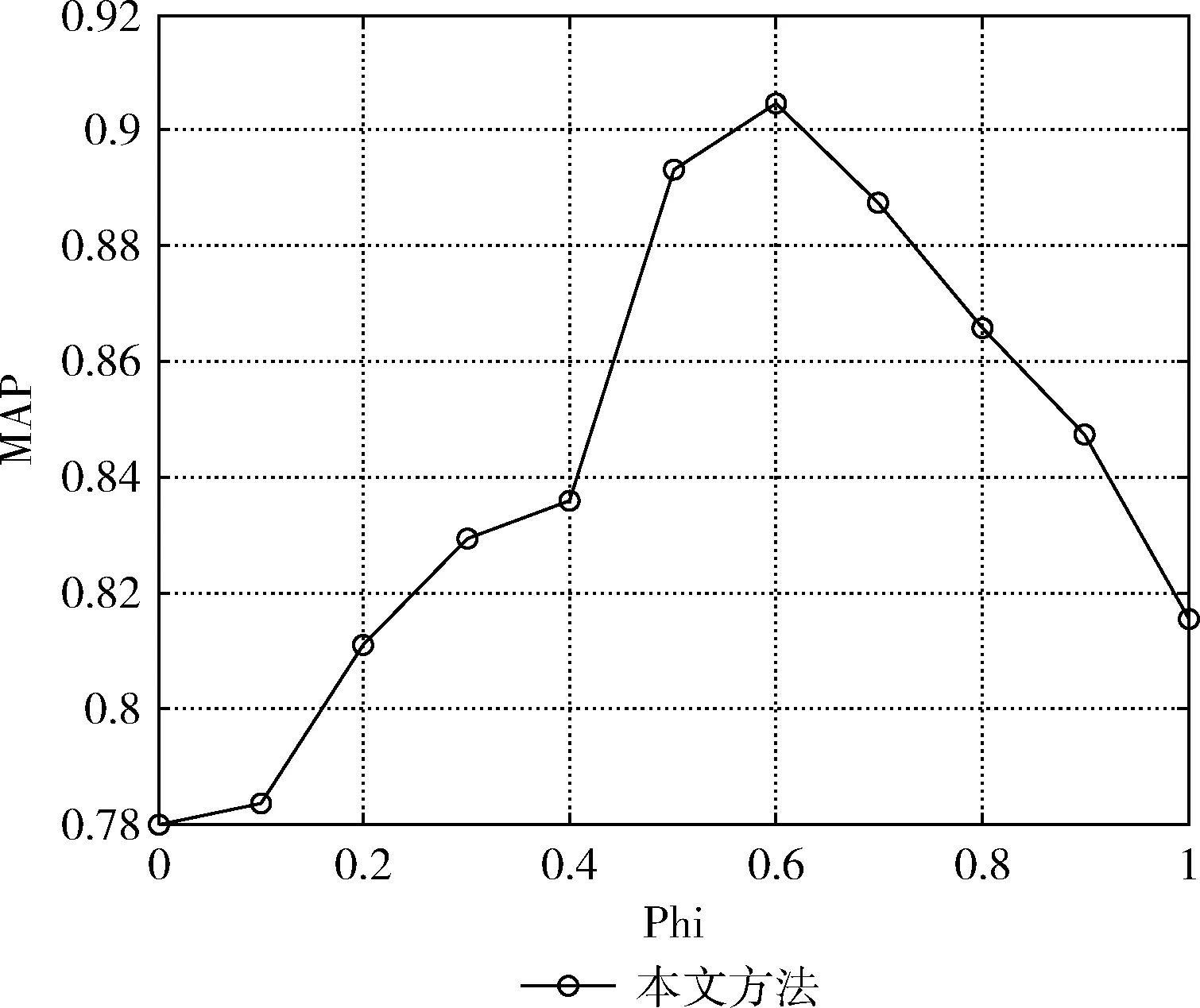
图6 参数φ的选取
由图6可知参数φ取0.6时MAP取得最大值,并且投票分数的初始状态比转移矩阵对标签相关度的影响更大。
4.3 性能评测及分析
4.3.1 标签排序
图像标签相似度计算常用于标签排序,因此本部分通过标签排序结果对标签相关度计算的准确性进行评价。为了使得性能评价结果更加准确、客观,使用NDCG将本文方法与经典的标签排序方法进行性能对比,标签排序性能对比分析所选用的方法包括:NV[13],PDE-RW[14],VWCD[15],SD[16],SR[18],MMRIM[19],以及TW-TV[20]。
接下来,利用NDCG对上述方法与本文方法进行性能对比,为了验证两种视觉特征BoVW+SIFT以及BoVW+SIFT+CNN的有效性,本文分别采用这两种视觉特征进行各种排序方法的性能评测(如图7所示)。
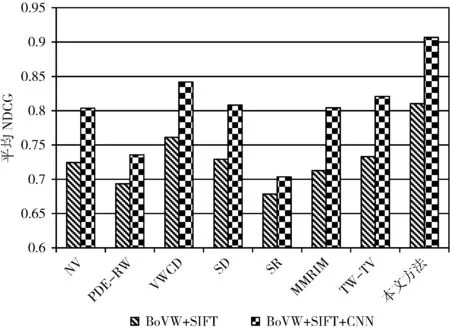
图7 平均NDCG值
由图7可知,本文方法的平均NDCG值高于其它方法;并且BoVW+SIFT+CNN特征比BoVW+SIFT特征具有更好的图像语义描述能力,从而能够有效提高标签排序的准确性。下面的实验中都将采用BoVW+SIFT+CNN视觉特征。
为进一步说明本文方法在不同图像类别上的标签排序性能,分别给出各排序方法在不同图像类别上的平均 NDCG 值,实验结果如图8所示。
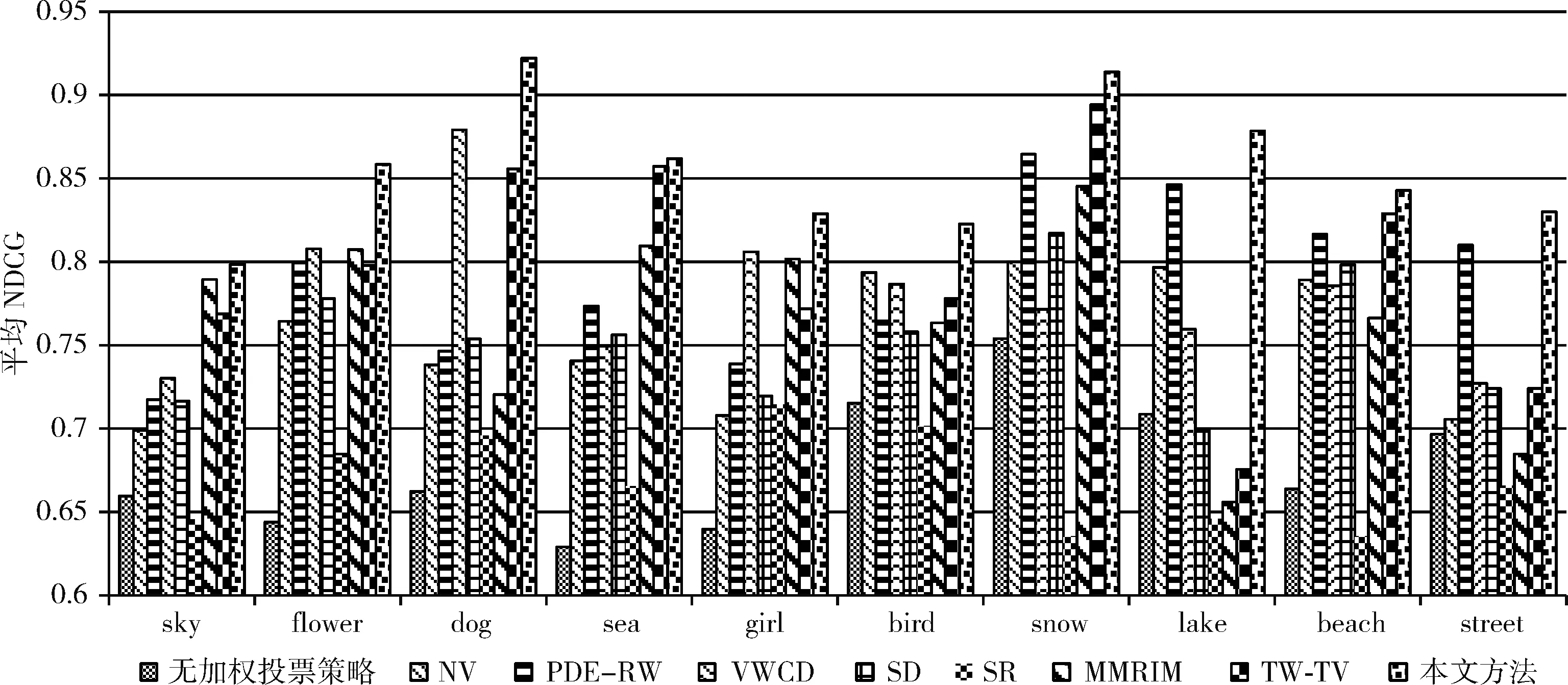
图8 不同类别图像的标签排序结果
由图8可知,本文方法在所有类别的图像标签排序上都获得了优于其它方法的性能,而其它方法在不同图像类别上的标签排序性能不够稳定。
本文方法的标签排序性能优于其它方法的主要原因在于:①本文方法充分挖掘图像的视觉相似度以及标签的语义相似度,从而进行近邻加权投票;此外,本文方法通过构建标签图模型,将近邻图像标签的语义信息传播给目标图像,能够有效提高标签相关度计算的准确性。②本文方法利用对视觉近邻图像及其标签进行加权投票,通过对图像低层视觉特征和标签高层语义信息的充分融合,有利于跨越“语义鸿沟”。③NV采用近邻投票策略进行标签排序,但是未对不同的视觉近邻和不同的标签进行加权处理,导致最终排序结果不够准确。④PDE-RW通过对标签图的随机漫步进行标签排序,但是该方法需要具有准确语义标签的训练图像集,当训练图像集的语义标签不够准确时,该方法的性能会大幅下降。⑤VWCD利用近邻投票策略进行标签排序,投票过程并未对视觉邻居进行加权处理,也没有充分考虑标签间的关系。⑥SD采用计算机视觉的方法通过显著性检测进行标签排序,该方法能够有效检测图像中的显著物体,但是,对于显著物体以外的其它语义概念的排序性能不够理想。⑦SR使用线性SVM分类器将图像分为有显著物体和没有显著物体两类,然后对这两类图像分别进行处理从而得到标签排序结果。但是该方法对于有显著物体的图像标签排序结果较好(例如:Flower,Dog,Girl,Bird),而且其它类别图像标签排序的结果都不够理想。⑧MMRIM模型和TW-TV模型虽然都考虑了图像与标签之间的关系,并对模型进行了优化,但是没有充分考虑同类别图像之间的语义关联,当初始标签噪声较大时,排序结果不够理想。
为了更加清晰地描述本文方法的标签排序性能,表1中给出了本文方法对MIRFlickr25k数据集中的5幅图像的标签排序结果。

表1 社会网络图像标签排序实例
由表1可知,本文方法可以有效地进行图像标签排序,排在前五位的标签都与图像的视觉特征有较高的语义相关度。
4.3.2 基于标签的图像检索
为了更加全面评价本文方法的有效性,本文利用基于标签的图像检索系统进一步验证提出的标签排序方法的有效性。本文将基于标签排序方法的图像检索与其它3种图像检索策略进行对比分析:①基于兴趣度的图像检索(策略1);②基于上传时间的图像检索(策略2);③基于初始标签顺序的图像检索(策略3)。其中,策略1和策略2是Flickr为用户提供的两种图像检索策略。使用本文方法进行图像检索时,检索词在图像标签序列中排序越高,则该图像在检索结果中的排序也越高。
由图9可知,基于本文标签排序方法的图像检索系统能够获得比其它图像检索策略更好的性能,这也从侧面说明本文提出的标签排序方法对于提高图像检索系统的性能具有重要意义。
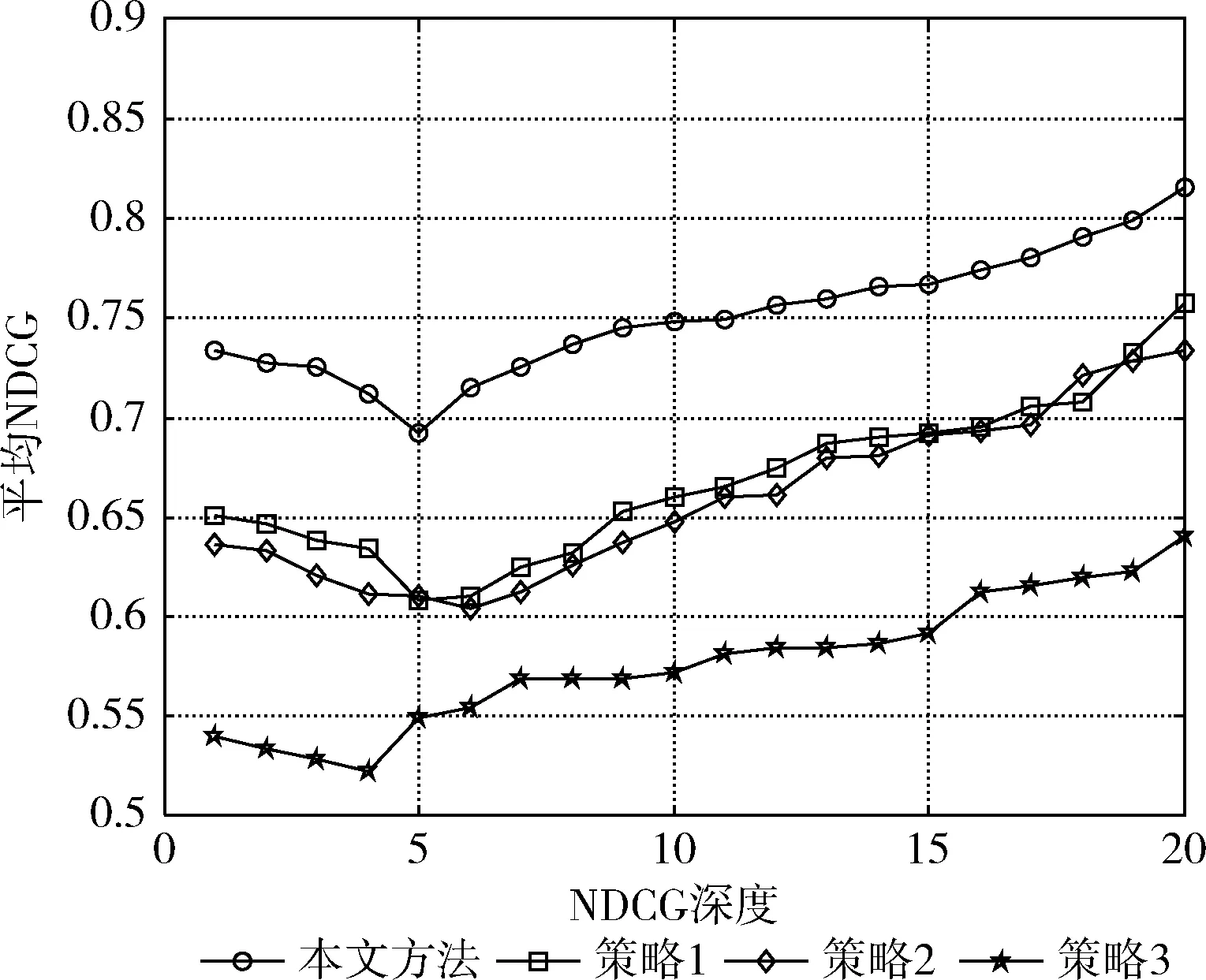
图9 图像检索性能对比
5 结束语
本文提出了一种社会网络图像标签排序算法。利用目标图像的视觉近邻图像为其进行标签加权投票,并在投票过程中充分考虑图像间的视觉相似度和标签间的语义相似度。此外,利用目标图像及其视觉近邻图像的标签构造标签图,在标签图上进行随机漫步计算出标签与图像的相关度,从而完成标签排序。实验结果验证了本文方法的有效性。
在下一步研究工作中,我们将对本文尚未解决的问题展开深入研究,主要包括:①如何在标签排序时充分考虑用户的兴趣偏好,进行个性化标签排序;②如何在标签排序时充分考虑标签的语义多样性,从而为图像检索结果的多样化表示提供思路。
猜你喜欢
中学生数理化·七年级数学人教版(2022年11期)2022-02-14
科普童话·学霸日记(2020年1期)2020-05-08
开放教育研究(2020年2期)2020-03-31
小天使·一年级语数英综合(2019年2期)2019-01-10
中国社会历史评论(2016年2期)2016-06-27
现代语文(2016年21期)2016-05-25
专利代理(2016年1期)2016-05-17
长江学术(2016年4期)2016-03-11
质量与标准化(2010年5期)2010-05-03
质量与标准化(2010年3期)2010-05-03
