
政务微博评论中情感极性分析方法研究
2020-03-05 07:11马超余辉夏文蕾管为栋
现代情报 2020年3期
马超 余辉 夏文蕾 管为栋
摘 要:[目的/意义]研究政务微博评论中的情感极性分析方法,为政务微博情感倾向判断提供依据并为未来情感分析研究指出方向。[方法/过程]基于字典的情感分析方法构建情感极性分析模型,以上海公安机构微博为实例,验证模型的可用性,并分析微博已有属性信息在情感分析中的作用。最后对微博的这些信息以及情感极性进行相关性分析。[结果/结论]本文的情感极性分析模型具有可用性,微博评论量和转发量之间存在着显著正相关性,并且在转发量较低时,评论量与情感极性存在着显著负相关关系。且当微博点赞量大于评论量时,微博内容自身带有正向情感倾向。
关键词:政务微博;情感极性;显式信息;相关关系
DOI:10.3969/j.issn.1008-0821.2020.03.016
〔中图分类号〕G206 〔文献标识码〕A 〔文章编号〕1008-0821(2020)03-0157-12
Abstract:[Purpose/Significance]The paper provides the basis for government micro-blog emotions tend and the future research direction by studying the method of emotional polarity.[Method/Process]With the case of shanghai municipal public security bureau weibo,this paper showed the usability of the emotional polarity model,and analyzed the function of explicit information.Finally,the study gave the correlation analysis of this information.[Result/Conclusion]The result uncovered the accuracy of the model and that there was significant correlation between comments and forwarding number.At the same time,there was significant correlation between comments and emotional polarity with the low amount of forwarding.Moreover,when the amount of like was larger than the number of comments,the content of weibo itself has a positive emotional tendency.
Key words:government micro-blog;emotional polarity;explicit information;correlation
隨着国家对电子政务的重视以及近年来社会媒体的发展,以社会媒体为平台的电子政务应用逐渐成为主流,政务微博作为国内最大的社会媒体平台在网络舆情和社会治理方面都具有显著作用[1]。截至2018年上半年,新浪微博用户规模为3.37亿人,截至2018年6月,新浪平台已经认证政务机构微博137 677个[2]。在社交媒体环境中,需要分析不同敏感话题的舆论传播规律和特征,以及社交媒体环境中的主题和热点,从而以点带面,把握社交网络舆情发展规律进而有效引导[3]。近年来图片识别技术、流媒体处理技术不断发展,丰富了社会媒体的表现形式,而在可处理的政务信息中,文本由于其自身的易处理性、权威性、明确性始终占有重要地位。情感分析就是文本分析的一个重要应用,如在政府出台新的试行政策前,在政务微博上征求民意,通过分析公民的情感倾向来对政策进行调整;在突发事件中,在政务微博中分析出不同地区的受灾程度来调整救援力度;在舆情控制中,通过网民情感变化趋势预测舆情走向等。而现有关于情感分析的研究多以产品为对象,对于服务内容的评论分析较少,而政府机构也无法处理公民对政务信息的全部反馈。
政务微博评论的情感分析和其他产品类有以下几个区别:1)政务微博通常不带商业性,多以为人民服务为宗旨,所以评论中的意见倾向都是基于公民本身的考虑,更具有研究意义;2)产品类评论可能需要对应产品特征,而政务微博评论考虑整体情感倾向即可;3)政务微博较产品类微博更具权威性,公民受其他因素影响较小,政务微博下的转发、评论和点赞行为较为规范,即三大属性信息的可用性程度更高。
1 相关研究
1.1 情感分析
情感分析是文本分析的一个重要代表应用,学者们将情感分析应用到了各个领域。涂海丽等通过在线旅游的评论数据建立了游客的情感分析模型,为旅游经营者提供直观的旅游目的地的情感倾向[4]。唐晓波等在产品评论领域通过计算情感词与特征搭配的权重,构建了特征本体的评论情感分析方法[5]。孟伟花等在学术质量评价方面,结合情感分析和Altmetrics评价方案,解决了学术影响力只考虑关注度而忽视极性的问题[6]。刘雯等以雅安地震为例,把情感分析应用到了对自然灾害的舆情分析中,以计算的情感值为基础来预测舆情走势[7]。
极性识别是情感分析的关键,极性识别最细致的是单词级,然后可以聚合到更高级别,目前主要有两种技术,即使用词典作为参照库和使用特定领域内的训练文档集作为词项极性的知识源[8]。前者通过个人为特定任务或机构开发通用词典,人工或者自动生成情感极性,这一类效果依赖于词典与当前处理文档集的适应度,王科等总结归纳情感词典构建方法,并从知识库、语料库方面指出了各种中英情感词典方法中的优缺点[9];后者则是从已经标注了观点的文档集中训练出预测极性的概率模型,它的准确率和训练文档集的大小有关,并且也要求训练文档集和预测文本具有一定的匹配性。
为了利用好大量已经标记可用训练集,如淘宝网的评论内容、星级以及好中差评结论这类显示标注了评论整体极性的文本,已有学者对一些网站的购物、饮食以及电影等的评论信息进行了分析,减少了对情感词典和训练文档集大小的依赖,如马松岳等以豆瓣电影网为对象,验证了电影打分和评论极性之间的较高相关性,与情感强度间的弱相关性[10]。
1.2 政务微博
目前政务微博的研究国外主要集中在Facebook和Twitter两大社交平台,国内则是以新浪微博居多。此外,腾讯微博、微信公众号也属于政务博客的重要阵营。如张志安等认为应该把握微博和微信的特点,在政务工作上传承和协同发挥“双微”的作用[11];石婧等以上海市政务微博和微信文本为分析对象,划分出了“双微”关系的4种类型并分析了每种类型的特征,为更好地应用于政务服务提供了参考[12]。孟川瑾等对优秀政务微博“@问政银川”模型进行分析,为国内政务微博发展困境指明方向[13]。周莉等采用内容分析法,研究了政务微博在突发事件中的特征和影响,为政府引导突发事件提出建议[14]。包明林等根据国内政务微博发展,以用户视角构建了政务微博服务质量评价指标体系[15],胡吉明等则是以政务信息发布质量为对象构建评价模型,指明服务质量的提升方向[16]。
在政务微博研究上,国内研究涉及政务微博的运营模式、在各种事件中的作用、评价服务质量等。相比国外研究少了统计分析类和内容分析类的研究,如Stamati T等通过统计公民参与Facebook数据来说明政府和粉丝在有无选举期间的特点是否有区别[17];Gascó M等对英国一次暴动期间的5 984位公民的Twitter进行内容和情感分析,发现公民容易被其他非危机事件影响,可以利用来帮助相关组织处理事件[18];Medaglia R等在绘制社会媒体政府整体状况时把相关研究内容分为了环境、用户特点、用户行为、平台性质、管理、效率六大类[19],这基本涵盖了目前政务微博的各大内容研究主题。
1.3 微博信息分析
本文的微博信息指的是不用分析就能得到的明顯信息,像微博三大属性信息(转发量、评论量和点赞量)或者话题、形式等,这些信息可以较为直观地显示出一些潜在的重要信息,本研究暂将些类信息称为显式信息。段尧清等在以政务网微信公众号为对象时就从政务信息本身的标题、形式、内容和来源4个方面的显式信息进行了统计分析,得出此类信息的主要特征,为促进政务类信息传播提供参考依据[20]。王克岭等立足于点赞视角,运用路径分析和PLS分析,并通过实证研究表明点赞行为与行为从众性、内容重要性、兴趣和情感性的显著正向影响[21]。颜月明等则是通过H指数和R指数思想提出影响力评估模型,模型表明高点赞量的文章更能得到大众的认可[22]。在评论研究上,发掘评论的内容是研究热点,也有学者通过评论的一些显式信息来研究评论的一些特性,如张艳辉等通过评论者的信息等级、文本长度、是否有图片等来判断评论的有用性[23]。在转发研究上,汤胤等在研究社会媒体转发行为时,以社会认知理论为基础,表明了个人感知对转发影响力较大[24]。
微博评论中都是短文,没有标题,形式以文本为主,所以微博最直接的显式信息就是点赞数、评论数和转发数这3个数值型数字,但这类信息不同于淘宝产品评价那样直接根据星级数值判断满意程度,更没有直接的好评、中评和差评3类定性界定,所以需要对这些数据进行一定分析和处理,得到近似于星级评价的效果。
1.4 研究评述
总结相关研究,政务微博评论内容较少被学者们重视,而现有的微博评论情感分析也还存在以下几点不足:1)目前还没有一个较好的方法去验证情感分析结果的准确性及度量情感强度;2)研究多是关于产品、饮食类,政务微博由于起步相对较晚,不带商业性,导致前期政务微博评论情感相关研究利用较少;3)情感分析多基于情感词典或者训练文档集方法,和其他网购、影评平台相比,在显式信息利用上还没有进行较充分的研究。
本文首先对政务微博评论情感进行分析,求证本文提出的情感分析模型在政务微博评论中的可用程度;接着用本模型分析结果对比微博的一些显式信息,试图寻找与政务微博评论情感极性相关的显式信息,来减少对情感词典和训练文档集大小的依赖。
2 模型设计
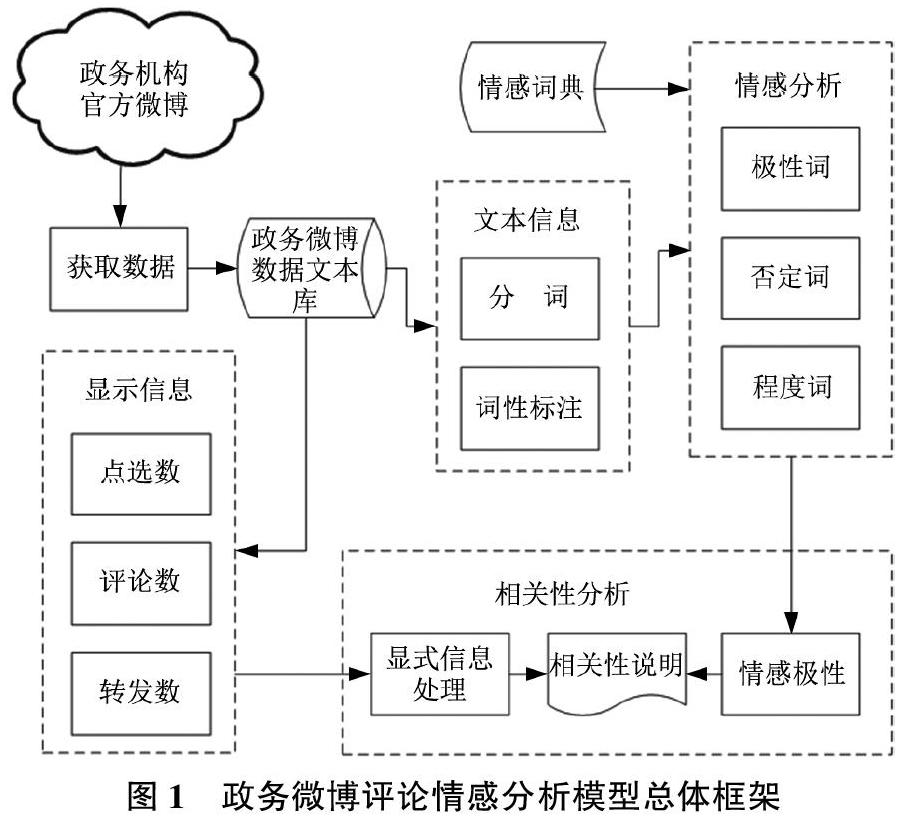
政务微博评论情感分析模型框架图如图1所示,简要流程可以分为以下几个模块:1)获取微博数据;2)文本信息处理,包括对评论内容进行分词和词性标注;3)情感分析,主要是通过情感词典对极性词、否定词和程度词的判断;4)显式信息的准备与处理(通常包括点赞数、评论数、转发数等);5)情感极性与显式信息相关性分析。
2.1 数据准备
本研究微博数据来自新浪微博平台,由于政务微博应该具有权威性,所以选取的微博是来自政务机构官方认证的微博。数据获取方式为Python爬虫程序,数据获取后存储于MySQL数据库。本模型选用词典的方法来判断文本情感极性,即每个词有一定有概率属于某种极性,为了权威性和可靠性更高,这里选用公开的知网HowNet情感词典。该情感词典包括中文和英文的程度级别词语、负面评价词语、负面情感词语、正面评价词语、下面情感词语和主张词语,本模型中主要用到中文的正负面情感词语以及程度级别词。
否定词会直接影响评论情感极性的判断,所以这里词典中还需要补充否定词典。学者张乐等在研究短文本情感折射模型中运用Word2vec对基础情感词典扩充并取得较好结果[25]。本研究先给出基础否定词汇,然后通过Word2vec进行扩充,选取与各基础词相似度较高的前100个词作为初始否定词集,然后人工进行筛选,得到最终否定词集。由于微博的社会网络性,这里Word2vec的训练数据来源选取的维基百科数据。本研究选取的基础否定词有:不、没、无和非。经过扩展后的部分否定词及与基础词相似度如表1所示。
2.2 文本處理
本模型在微博论文文本处理上主要包括两个重要内容,中文分词和词性标注。分词是为了能与情感字典以及否定词集进行匹配,同时分词后也便于词性的标注,进行更为精准地处理文本情感极性。唐晓波等在对产品评论情感挖掘时就总结出了情感词一般出现在谓语中,状语和定语对感强度有影响等[26]。
Python是这两年非常受欢迎的文本分析语言,本研究从爬虫到分词以及词性标注都是用Python语言编写,分词和词性标注采用Python环境下自带的jieba分词系统。由于全模式分词中否定词多次出现会影响情感极性,所以研究选择精确模式分词。
2.3 情感分析
微博评论文本主体都是由一些短文本组成,还有很大部分是由个别词组成,所以传统的句法结构分析在评论文本中并不适用,这里直接根据精确模式分词后的词性标注,需要分是否有谓语动词来分析。如果没有谓语动词,即无情感词可匹配,不采取任何操作,或情感极性值记为0;如果有谓语动词,提取评论中的谓语动词来遍历情感词典中的词以判断谓语动词的情感极性得到初步的情感极性判断,然后根据是否含有否定词来重新判断评论的情感极性,最后根据情感词典中的程度词典来赋予极性权重,得出单条评论的情感极性值。在实际处理中,为了追求准确与便捷,也可以用评论句子中的所有词去遍历情感词典,避免词性标注不准确带来的遗漏。之后依次去遍历否定词典和程度词典,得到更有说服力的结论。单条政务微博评论的情感分析简要流程如图2所示。
2.4 显式信息分析
由于本研究不涉及用户研究,中国社会也提倡人人平等,这里将所有公民的评论权重一致对待,即单条微博的情感倾向性由支持这条微博的人数与不支持这条微博的人数比例来判断。由于微博的机制,支持可以由点赞和正向情感的评论来表示,反对和中立通过负向或中立情感评论来表示。本研究用Z来表示单条微博的支持度,即当Z大于1时,单条微博情感整体倾向为正。除了直接分析点赞数、评论数、转发数三者之间的关系外,研究还应该对三者之间进行过数学处理后的数值进行分析,如三者中任意两者的比值与情感极性值的比较,或三者中有相关性的两个进行均值处理后代替原来只用其中一个参数的比例等。下面介绍一个点赞数与评论数的比值和它与情感极性值比较的理由和意义。
L/C,其中L代表单条微博点赞数,C代表单条微博评论数,即点赞数与评论数的比值。选取理由是点赞可以粗略看作是对微博的认同,即判断情感极性为正向,在单一变量条件下,点赞数越多,可以认为该微博在公民中的情感正向值越高。而评论中情感暂时无法简单判断出来,可以假设评论中全都是负面情感,那么点赞数与评论数的比值即等于正向情感与负向情感的比值,可以判断出单条微博的整体情感极性,即有式(1)成立。
其中E(正)表示正向情感倾向数,E(负)表示负向情感倾向数。而在实际操作中,评论中情感有正有负,真实的负向情感值E(负)应该小于此时的评论数C,真实的支持度应该大于基于假设计算出来的值,如式(2)所示。
所以如果单条微博的L/C值大于1,那么此条微博的整体情感支持度就大于1,此时可以假定微博整体情感极性判断为正向。
2.5 相关性假设
相关关系是一种非确定性的关系,相关系数是研究变量之间线性相关程度的量。本文用简单相关系数来衡量各组数值之间是否存在相关关系,用字母r表示,用来度量两个变量间的线性关系,即两个变量X和Y之间的线性相关系数r定义如式(3)所示[27]。
1)从整体上分析,点赞数、评论数和转发数两两之间存在相关关系;
2)点赞数、评论数和转发数分别和微博情感极性之间存在着相关关系;
3)点赞数、评论数和转发数之间进行计算处理后与微博情感极性之间存在着相关关系,如当微博点赞数超过评论数时,微博情感倾向为正向的概率较大,即在一定前提条件下,微博的三大属性信息与评论的情感极性存在着相关关系。
3 实验设计与相关结论
国外已有学者研究表明交通、住房和工作这类主题是公民最关心的政务话题[28]。但在中国,公安的官方微博是拥有粉丝最多的机构,所以本实验以上海公安机构微博评论为对象,在新浪微博平台上对上海市公安局官方微博“警民直通车—上海”在2017年9月1日到2018年8月31日之间发布的微博评论进行分析,去除重复性评论以及空的(没有文本信息)评论信息,初步处理后数据量为3 582条微博,以及30 948条评论。本实验设计有两个目的,首先是要验证本模型情感分析方法的准确性,然后用模型的情感结论来分析微博的显式信息是否有参考价值。
3.1 情感验证与结果标准化
本小节进行初步人工验证,确定模型的可用性,并对情感分析结果进行统一的优化处理。具体的验证根据情感分析流程依次为情感词判断、否定词判断和程度词判断的验证,最后对复合句进行判断。模型验证举例如表2所示。
从表2中可以看出本模型对于极性判断是准确可行的,从整体极值上看,得出的极值为单句评论中的正向情感和负向情感比值,但这个比值在不同单句中的差值较大,不利于得到整体情感。考虑到一条微博评论代表一个公民的情感,需要对每条评论进行标准化处理,重新分配情感权重。极性pol的判断和情感支持度pos的标准化代码为:
#情感极性pol判断
if Pos>Neg:pol=1
else:
if Neg>Pos:pol=-1
else:pol=0
#情感极性比值,标准化到-1到1之间的情感值
if Pos+Neg==0:pos=0
else:
pos=2*(Pos/(Pos+Neg)-0.5)
其中Pos代表单条评论中正向情感倾向度,Neg代表单条评论中负向情感倾向度。一条微博的所有评论情感值相加,代表这条微博评论的整体情感倾向。经标准化后的单条评论情感值为[-1,1]之间的数值,后期研究如果考虑到每个公民的情感表达程度影响大小不同,可以用具体的情感数值来进行计算。在只考虑情感极性的情况下,可以直接用情感极性判断值pol来计算。
3.2 情感极性判断应用结果
为了后续研究显式信息的作用,先要验证本模型在单条微博所有的评论情感极性判断的准确性。本研究对象为政务微博信息,政务微博多与民生问题相关,这里选取上海市公安局微博中,以溺水为关键词的相关微博进行情感分析验证,具体选取的事件和相关分析结果如表3所示。
在微博事件惊险溺水视频中,实际情感倾向为负主要原因是视频中小孩的监护人带孩子在海边玩时轻视了大海的危险性,小孩险些被海浪冲走,模型结果与实际倾向一致。在微博离岸流悲剧中,主要是对离岸流的科普性知识,微博评论应该是正向情感或者不带情感的,实际查看后发现评论中只有较少关于微博本身内容,多是在为另一些事件在维权引发的负面情绪。安全爱心班中,评论没有一条是与微博内容相关的,结果没有任何意义。水中救援教程视频中,模型结果为不带情绪,实际分析为微博评论中正向情绪受到了“唐小僧”事件的负面评论影响。防溺水提示的微博中,一共只有3条评论,并不带明显的情感极性。警方提醒防溺水微博中,评论走向了调侃的风格,整体呈现出正向极性。男子跳江消防救起微博中,评论的负面情绪主要来源于批评男子自杀行为。溺水救生指南微博中,评论没有特别的负面情绪,民众发表了一些对于指南的一些疑问。
从表3中可以看出模型基本在情感极性分析上可用,但准确度需要进一步衡量。这里采用准确率来计算,并将评论数作为对比结果正确的微博事件权重,按式(4)所示计算准确率。
其中c为情感极性判断正确的微博评论数,s为样本所有评论数之和。如果将可用的对比结果暂且归为不准确一类,根据上面的溺水相关微博分析结果计算p值为69.5%,将可用的对比结果归为准确,p值为85.7%。由应用结果准确性分析可知,本模型在不考虑内容相关性的情况下的可用性较高。
3.3 相关性分析
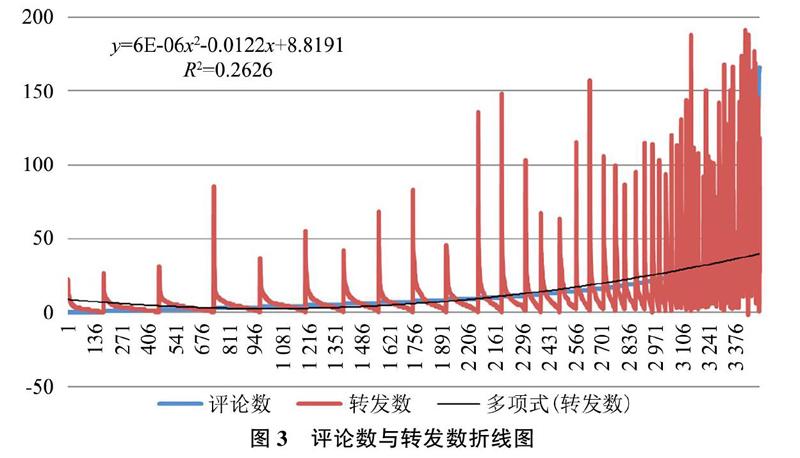
在分析微博的点赞数、转发数和评论数三者之间关系时,用上筛选后的全部样本3 582条微博内容以及其所有评论情感分析的情感值。根据相关系数的缺点,即它接近于1的程度与数据组数n相关,当n较小时,相关系数的波动较大,对有些样本相关系数的绝对值可能碰巧接近于1;当n较大时,相关系数的绝对值容易偏小。特别是当n=2时,相关系数的绝对值总为1。因此在样本容量n较小时,仅凭相关系数较大就判定变量x与y之间有密切的线性关系是不妥当的。本研究将样本微博数n从较数值取到3 582之间来观察相关系数的变化。部分n值和对应的相关系数如表4所示。
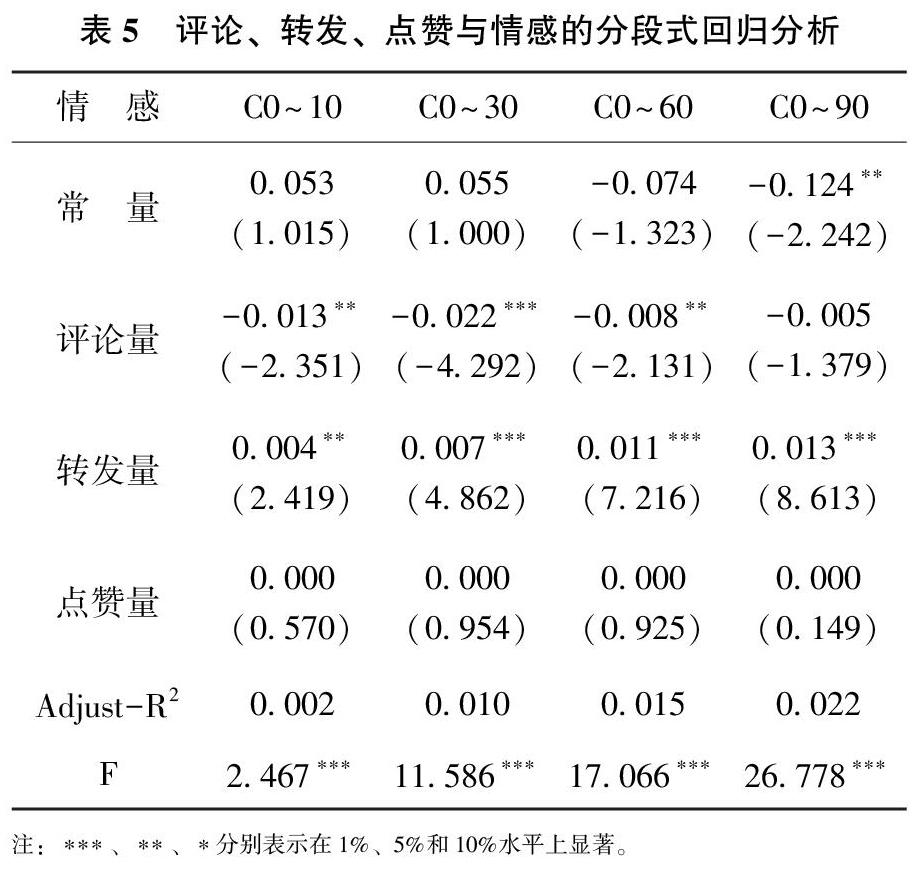
通常当0 从得出的相关系数表中,还可以得出在n<224时,情感极性与评论和转发之间也有较为显著的相关性,但随着样本n的增加,相关性减小。即说明假设二中微博评论情感与点赞、评论和转发都没有直接的相关性。假设二并目前还不能成立,已有的三大属性信息还不能直接代替文本情感分析方法去判断微博评论情感倾向,还需要平台未来提供更多的显式信息。 因此对微博和评论做进一步深度分析,用来排除一些个别因素,如单个指标数量极多的情况,本研究进行了分段式回归分析,多次试验后发现以评论量进行分段效果较好,研究在评论量各分段区间内评论、转发和点赞与情感的关系,分析结果如表5所示。当评论量在0~90区间时,仅转发与情感分别在5%和1%水平上显著正相关,而评论和点赞与情感的相关性不显著;当评论量在0~60区间时,评论和转发与情感的相关系数分别为-0.008和0.011,分别在5%和1%水平上显著。当评论量在0~30区间时,评论和转发与情感的相关系数分别为-0.022和0.007,且都在1%水平上显著;当评论量在0~10区间时,评论和转发与情感的相关系数分别为-0.013和0.004,且都在5%水平上显著;即假设三中在转发量较低时评论量与微博评论情感呈负相关关系。 3.4 实验验证 为了论证本文分析结果的可靠性,本实验从统计方法和话题实例两个方面进行检验。本文选取了同一研究对象不同时间段的数据为分析样本。实验选取了近期(实验数据之后)上海公安机构政务微博进行验证,获取了2018年10月20日到2019年5月20日之间的微博及相关评论信息,进行初步筛选后,得到2 812条微博和31 043条评论,作为实验检验数据集。 3.4.1 统计方法检验 为了检验整体是否符合研究结论,本文选取全部检验数据集进行验证是否支持假设一,结果评论量和转发量之间相关关系仍显著,如表6所示。 本文对检验样本进行了分段回归分析,结论表明在评论量在0~10之间验证中,评论量与情感的相关系数为-0.044,且在1%水平上显著,转发量与情感的相关系数为0.001,且在5%水平上显著,说明在评论为0~10这个区间内评论量与情感极性显著负相关,而转发与情感显著正相关。说明评论与情感显著负相关以及转发量与情感极性显著正相关这一结论在同一样本的不同时间段同样成立。分析結果如下表7所示。
[7]刘雯,高峰,洪凌子.基于情感分析的灾害网络舆情研究——以雅安地震为例[J].图书情报工作,2013,(20):104-110.
[8]拉姆什·沙尔达,杜尔森·德伦,埃弗雷姆·特班.商务智能:数据分析的管理视角[M].北京:机械工业出版社,2017.
[9]王科,夏睿.情感词典自动构建方法综述[J].自动化学报,2016,(4):495-511.
[10]马松岳,许鑫.基于评论情感分析的用户在线评价研究——以豆瓣网电影为例[J].图书情报工作,2016,(10):95-102.
[11]张志安,曹艳辉.政务微博和政务微信:传承与协同[J].新闻与写作,2014,(12):57-60.
[12]石婧,周蓉,李婷.政務服务“双微联动”模式研究——基于上海市政务微博与政务微信的文本分析[J].电子政务,2016,(2):50-59.
[13]孟川瑾,卢靖.基于新公共服务的政务微博运行机制——“@问政银川”案例研究[J].电子政务,2016,(4):45-53.
[14]周莉,李晓,黄娟.政务微博在突发事件中的信息发布及其影响[J].新闻大学,2015,(2):144-152.
[15]包明林,刘蓉,邹凯,等.政务微博服务质量评价指标体系研究[J].现代情报,2015,(9):93-97.
[16]胡吉明,李雨薇,谭必勇.政务信息发布服务质量评价模型与实证研究[J].现代情报,2019,39(10):78-85.
[17]Stamati T,Papadopoulos T,Anagnostopoulos D.Social Media for Openness and Accountability in the Public Sector:Cases in the Greek Context[J].Government Information Quarterly,2015,32(1):12-29.
[18]Gascó M,Bayerl P S,Denef S,et al.What Do Citizens Communicate About During Crises?Analyzing Twitter Use During the 2011 UK Riots[J].Government Information Quarterly,2017,34(4):635-645.
[19]Medaglia R,Zheng L.Mapping Government Social Media Research and Moving it Forward:A Framework and A Research Agenda[J].Government Information Quarterly,2017,34(3):496-510.
[20]段尧清,程宁静,肖博.基于政务微信公众号的易得性信息特征研究[J].情报科学,2016,(7):131-135.
[21]王克岭,张甜溪,段玲.微信公众号软文内部点赞影响因素研究[J].西安财经学院学报,2018,(2):71-77.
[22]颜月明,赵捧未.一种微信公众号影响力的评估方法[J].情报杂志,2016,(9):141-145.
[23]张艳辉,李宗伟.在线评论有用性的影响因素研究:基于产品类型的调节效应[J].管理评论,2016,(10):123-132.
[24]汤胤,徐永欢,张萱.基于社会认知理论的社交媒体用户转发行为研究[J].图书馆工作与研究,2016,(6):68-76.
[25]张乐,闫强,吕学强.面向短文本的情感折射模型[J].情报学报,2017,(2):180-189.
[26]唐晓波,肖璐.基于情感分析的评论挖掘模型研究[J].情报理论与实践,2013,(7):100-105.
[27]何春雄,龙卫江,朱锋峰.概率论与数理统计[M].2012.
[28]Bonsón E,Royo S,Ratkai M.Citizens' Engagement on Local Governments' Facebook Sites.An Empirical Analysis:The Impact of Different Media and Content Types in Western Europe[J].Government Information Quarterly,2015,32(1):52-62.
[29]孙华俊.思想政治教育心理环境的创设与优化[J].江汉大学学报:社会科学版,2019,36(2):104-112.
[30]张柳,王晰巍,王铎,等.微博环境下高校舆情情感演化图谱研究——以新浪微博“高校学术不端”话题为例[J].现代情报,2019,39(10):119-126.
(责任编辑:郭沫含)
猜你喜欢
今传媒(2016年12期)2017-01-09
商业经济(2016年6期)2017-01-03
文艺生活·中旬刊(2016年9期)2016-11-07
今传媒(2016年8期)2016-10-17
人民论坛(2016年27期)2016-10-14
