
基于追逃博弈的非合作目标接近控制
2020-03-05 05:06:18罗建军王明明
宇航总体技术 2020年1期
柴 源,罗建军,王明明,韩 楠
(1. 西北工业大学航天飞行动力学技术重点实验室, 西安 710072;2. 西北工业大学青岛研究院,青岛 266200)
0 引言
空间自主交会是航天领域的一大研究热点。随着航天技术的不断进步,合作目标的自主交会技术已经比较成熟,并成功应用于空间站、在轨服务等多种空间任务中。目前,空间非合作目标如故障卫星、空间垃圾等的自主接近引起了学者的广泛关注[1]。
非合作目标由于其非合作性,具有如下特征:信息层面不沟通、机动行为不配合、先验知识不完备等。因此在设计追踪航天器的轨道控制方法时需要综合考虑接近过程中的不确定性。针对非合作目标接近问题,目前已经开展了部分研究工作。根据建模方法的不同可将已有研究分为3种:基于视线坐标系的建模与控制、基于目标轨道坐标系的建模与控制、基于追踪航天器轨道坐标系的建模与控制。在目标轨道坐标系下,王洪宇等[2]提出了一种全局鲁棒最优滑模控制器来克服非合作目标所带来的不确定性。但是由于目标航天器的轨道半径和速度无法直接得到,基于目标坐标系的建模具有局限性。在基于视线坐标系的建模与控制方面,陈统等[3]建立了姿轨联合运动模型,并结合具有鲁棒性的模糊控制理论实现对非合作目标的接近;殷泽阳等[4]提出了低复杂度预设性能控制方法,实现在未知系统参数情况下的快速高精度目标接近,但是基于视线坐标系的建模为非线性模型,增加了控制求解难度。在追踪航天器轨道坐标系下,卢山等[5]设计了针对自主交会和拦截两种接近模式的基于李雅普诺夫的控制律;郭永等[6]基于人工势场法与蔓叶线理论的障碍物模型,提出了可以避障的滑模控制器。该坐标系下,追踪航天器可以基于自身的轨道信息及星载传感器测量得到相对位置和速度信息等进行控制器设计,更加方便简洁。因此,本文采用基于追踪航天器轨道坐标系的相对运动模型,以便于控制律的设计。
根据上述分析,多数设计方法都是通过提高控制器的鲁棒性来克服非合作目标的机动以及外界干扰等。但是由于非合作目标机动上界的不确定,控制器的设计存在保守性,不利于燃料的优化和接近精度的提高。
博弈论研究的是多个参与者的最优控制与决策问题,其中每一位参与者通过各自目标函数的优化获得控制策略[7]。近年来,博弈控制方法在各种工程问题的研究中也得到了应用。Abouheaf等[8]、Lin[9]和Mylvaganam等[10]将博弈控制方法应用到多智能体一致性、编队和避障等问题中。韩楠等[11]利用微分博弈实现了多颗微小卫星对失效航天器的姿态接管控制。Innocenti等[12]利用基于状态相关里卡提方程SDRE的非合作微分博弈控制实现交会任务。追逃博弈研究追捕者与逃逸者以不同的策略完成追捕任务的协调过程[13]。Bardhan等[14]基于追逃博弈设计了导弹拦截导引律,Li等[15]将近圆轨道上的两个航天器追逃问题转化为两点边值优化问题进行求解。因此,本文将非合作目标视为理性的博弈参与者,设计追踪航天器的追逃博弈控制方法,从而实现非合作目标的精确接近。为了简化纳什均衡的求解,追逃博弈模型选择线性二次型微分博弈模型[16],以得到控制策略的显式表达式,便于在线应用。
本文介绍了追踪航天器的追逃博弈控制器的设计思路,基于追踪航天器和非合作目标的轨道相对运动模型,设计了与相对距离和燃耗有关的目标函数,并建立了二者的追逃博弈模型,推导了追逃博弈的均衡策略,并给出了策略求解算法,通过数值仿真验证了非合作目标接近的追逃博弈控制方法的有效性。
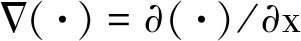
1 设计思路
本文面向非合作目标接近的轨道控制问题,试图提出一种基于线性二次型追逃博弈的控制方法。追逃博弈将参与双方定义为追踪者和逃脱者,在博弈过程中各博弈方均以己方最大利益为目标,一方的得益必然导致另一方的损失,二者的得失总和为0[14]。将非合作目标接近问题描述为追逃博弈问题,其中追踪航天器扮演追踪者,非合作目标扮演逃避者。要接近非合作目标,一方面,追踪航天器要选择其控制策略以调节到某种状态,并尽量减少博弈过程中的燃料消耗。另一方面,理性的非合作目标试图调节到使追踪航天器难以追上的状态,选择其控制策略的同时将自身燃料消耗降至最低。将二者互相冲突的目标归纳为追逃博弈的目标函数
(1)
式中,X为相对状态量,具体含义在下文给出。u为追踪者的控制量,v为逃逸者的控制量。Q>0,Ru>0,Rv>0均为对称矩阵。追踪航天器的目标是最小化J,而非合作目标则期望最大化J。
在考虑二者动力学约束的情况下,通过优化二者的目标函数,建立追逃博弈模型:
(2)
通过建立在追踪航天器上的轨道相对运动方程,将非合作目标轨道接近的任务要求转化为追逃博弈控制优化问题中的动力学约束。通过最优化问题的求解得到纳什均衡控制策略,追踪航天器尽可能在燃耗最小的情况下实现非合作目标的接近。
2 非合作目标接近的追逃博弈建模
空间非合作目标接近问题涉及两个近距离航天器间的轨道运动,本节先给出追踪航天器轨道坐标系下追踪航天器和非合作目标的相对运动模型,之后建立二者的追逃博弈模型。
2.1 相对运动建模
本文中下标e和p分别代指非合作目标和追踪航天器。在惯性坐标系下,非合作目标追踪航天器的轨道运动方程分别为
(3)
式中,rp和re分别为追踪航天器和非合作目标在惯性坐标系下的位置矢量;up和ue分别为追踪航天器和非合作目标的控制加速度;μ为地球引力常数,μ=3.986×1014m3/s2。
定义追踪航天器和非合作目标的相对位置为
r=re-rp
(4)
则惯性坐标系下的相对运动方程为
(5)
将式(5)投影在追踪航天器本体坐标系中可得
(6)
式中,ωe和ωp分别表示二者的轨道角速度,r表示惯性系下的位置矢量。
在二者相对距离和非合作目标地心距之比足够小,即r≪re的条件下,re=r+rp的2阶及高阶泰勒展开项可忽略不计,则相对轨道运动方程写成状态空间形式
(7)
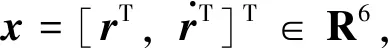
其中
其中
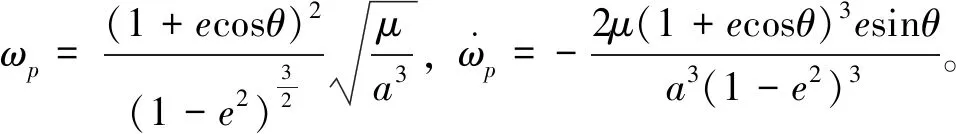
式(7)为非合作目标和追踪航天器之间的相对运动方程。由于目标航天器为非合作目标,无法得到其轨道信息,因此坐标系建立在追踪航天器上。追踪航天器可以基于自身的轨道信息及星载传感器测量得到相对位置和速度信息,以便进行博弈问题的建模和求解。
2.2 追逃博弈建模
追逃博弈由以下3个要素构成:博弈参与者N={p,e}、各参与者容许策略集Ui、参与者目标函数J[7]。为满足非合作目标接近的任务要求,设计如下目标函数
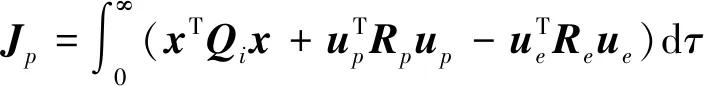
(8)
其中,Q∈R6×6、Rp∈R3×3、Re∈R3×3为对称正定的加权矩阵。
非合作目标和追踪航天器进行追逃博弈时,二者通过独立优化各自目标函数(8)来获得控制策略。该策略称为纳什均衡,其定义如下:
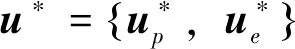
(9)
其中Ui为参与者i的容许控制策略集。
对应于可行控制策略集ui∈Ui的值函数为
(10)
则非合作目标接近的追逃博弈问题可由下式描述
(11)
追踪航天器通过求解上述优化问题,得到追逃博弈的纳什均衡策略,以实现对非合作目标的接近。
3 非合作目标接近的博弈控制策略
本节先给出追逃博弈控制策略的状态反馈表达式,之后给出李亚普诺夫迭代法进行状态反馈矩阵的求解。
3.1 追逃博弈控制策略
值函数的微分等价为
(12)
其中,V(0)=0。
定义哈密尔顿函数为
(13)
对应最优值函数的反馈控制策略为
(14)
将其代哈密尔顿函数中可得HJ方程为
(15)
其中,V*(0)=0。
假设最优值函数在状态x(t)下有线性二次型形式的解
(16)
则追踪航天器和非合作目标对应的纳什均衡反馈控制策略为
(17)
则HJ方程可以整理为
(18)
整理得
(19)
通过对上述代数黎卡提方程(19)进行求解,可以得到对称正定矩阵P,从而根据式(17)得到状态反馈控制策略。
本文控制策略与传统的线性二次型调节器(LQR)方法有相似之处。LQR方法是现代控制理论中较成熟的一种状态空间设计法,针对线性系统,设计与系统状态和控制输入相关的二次型目标函数
(20)
利用动态规划推导得到代数黎卡提方程
(21)
从而得到状态反馈的最优控制律
(22)
但是本文的控制策略是基于追逃博弈得到的,考虑最优性的同时,比传统的LQR控制有更好的鲁棒性。
3.2 控制策略求解
代数黎卡提方程(19)的求解已有丰富的研究成果[17],本文采用李雅普诺夫迭代法进行计算。该方法将代数黎卡提方程解耦为李雅普诺夫方程来独立运算,算法速度快,准确性高。
迭代算法
(A-SPP(k))TP(k+1)+P(k+1)(A-SPP(k))=
-(Q+P(k+1)SpP(k+1)+P(k+1)SeP(k+1)),
k=0,1,2,…
(23)
初值选择
0=ATP(0)+P(0)A+Q-P(0)SpP(0)
(24)
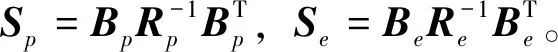
通过迭代求解李亚普诺夫方程式(20)和式(21)可以得到矩阵P。
4 仿真算例及结果分析
为了突出本控制器的优势,本节将基于追逃博弈的控制方法与传统LQR控制进行对比,通过3组数值仿真算例验证基于追逃博弈的控制方法应用于非合作目标接近问题的有效性。假设追踪航天器初始时刻相对于非合作目标的位置为r=[300,150,-100]Tm,追踪航天器进行非合作目标逼近,最终二者的相对运动状态为0。追踪航天器的控制加速度幅值约束为umax=5m/s2。仿真轨道初始值如表1所示。
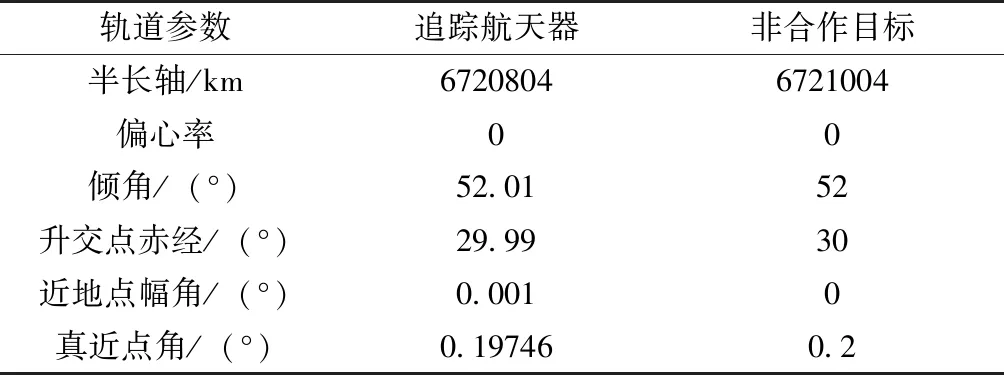
表1 初始轨道参数
算例1假设空间非合作目标不存在机动。该工况相对理想,用于检验所提出控制方法的可行性。本文方法选择权重矩阵为:Q=10-5I6,Rp=0.01I3,Re=0.02I3。LQR方法选择权重矩阵为:Q=10-5I6,R=0.01I3。仿真时间为200s,仿真步长为0.1s。
图1和图3分别为本文提出的方法在接近过程中,非合作目标和追踪航天器相对距离和相对速度随时间的变化曲线。图2和图4分别为LQR提出的方法在接近过程中,非合作目标和追踪航天器相对距离和相对速度随时间的变化曲线。经过约40s,两种控制器均使追踪航天器与非合作目标的相对距离稳定在0.5m左右。
图5和图6分别为两种控制器下追踪航天器的控制加速度随时间变化曲线。可以看出,在整个非合作目标接近过程中,初始相对距离较远,接近非合作目标所需控制力较大,随着相对距离的减小,控制力逐渐减少并趋于0。通过上述分析,在非合作目标无机动的理想情况下,两种方法均可实现对非合作目标的接近。
算例2假设非合作目标的未知机动为纳什均衡策略。该工况下,非合作目标为理性的博弈参与者,有意识地与追踪航天器对抗。假设非合作目标的最大控制加速度umax=2m/s2。本文方法选择加权矩阵为:Q=10-5I6,Rp=0.01I3,Re=0.02I3。LQR方法选择目标函数中的矩阵为:Q=10-5I6,Rp=0.01I3。仿真时间为200s,仿真步长为0.1s。
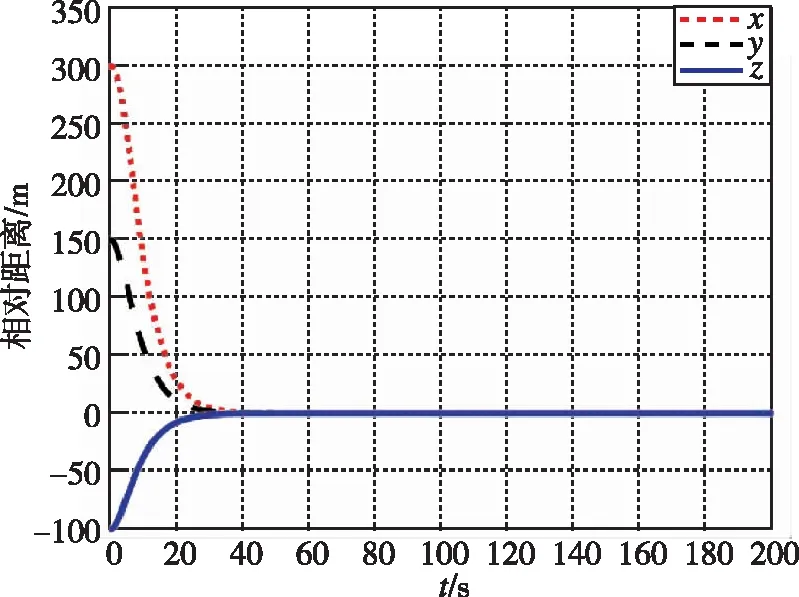
图1 相对距离随时间变化曲线(本文)Fig.1 Relative distance by game
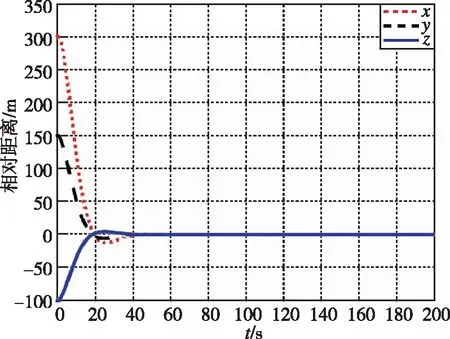
图2 相对距离随时间变化曲线(LQR)Fig.2 Relative distance by LQR
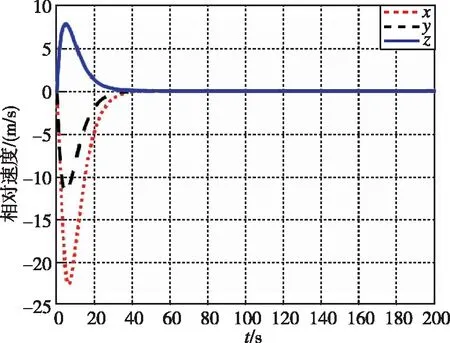
图3 相对速度随时间变化曲线(本文)Fig.3 Relative velocity by game
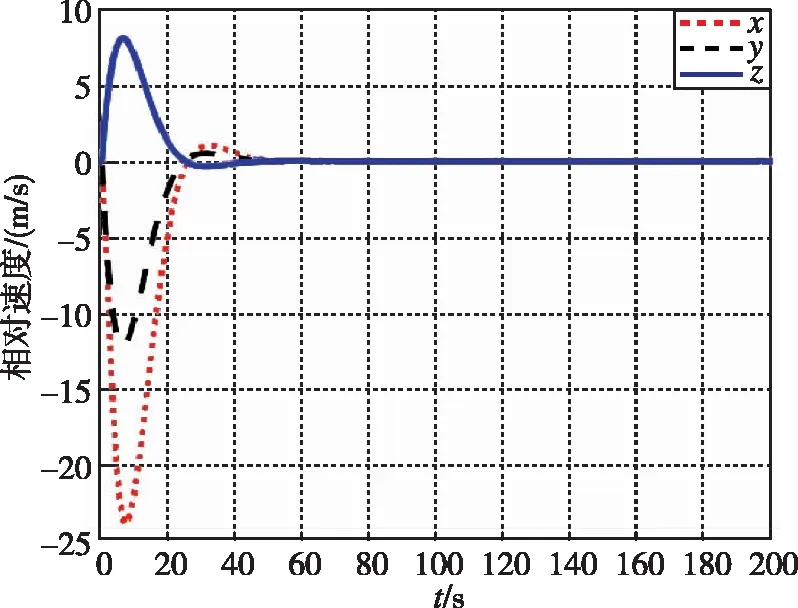
图4 相对速度随时间变化曲线(LQR)Fig.4 Relative velocity by LQR
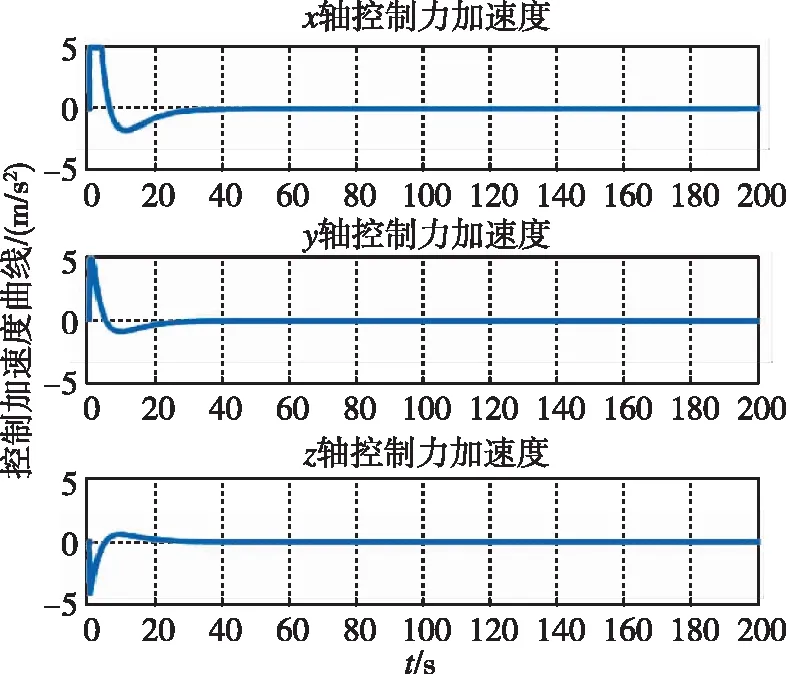
图5 控制加速度随时间变化曲线(本文)Fig.5 Control acceleration by game
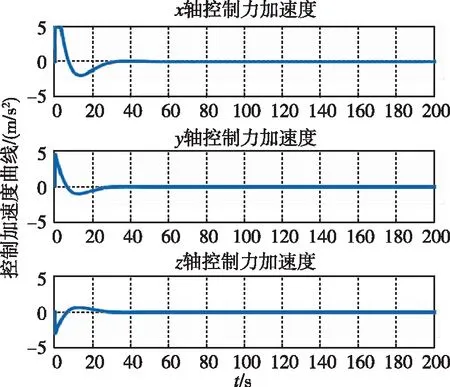
图6 控制加速度随时间变化曲线(LQR)Fig.6 Control acceleration by LQR
图7和图8为追逃博弈方法与LQR方法分别作用下的相对位置变化图。图9和图10为两种控制分别作用下的相对速度变化图。可以看出,在非合作目标采取纳什均衡策略时,本文所提出的方法能够快速平滑地使相对距离收敛到0.5m左右的稳定值。而LQR方法则是震荡收敛状态,所需时间较长。
图11和图12分别为两种控制器下追踪航天器的控制加速度随时间变化曲线。可以看出,基于追逃博弈的控制方法可以在燃耗较少的情况下快速收敛到0。对比二者的目标函数,在二者都采取纳什均衡策略的情况下,即基于追逃博弈的控制下,J*=104;而在LQR控制下,J*=141,由此也可以验证式(9)的右不等式成立。
算例3假设非合作目标存在未知机动[4]:
本文方法选择权重矩阵为:Q=10-5I6,Rp=0.01I3,Re=0.008I3。LQR方法选择权重矩阵为:Q=10-5I6,Rp=0.01I3。仿真时间为200s,仿真步长为0.1s。
在本工况下,图13和图14为追逃博弈方法与LQR方法分别作用下的相对位置变化图。图15和图16为两种控制方法下的相对速度变化图。可以看出,尽管非合作目标存在未知机动,追逃博弈的控制方法仍可以实现状态的收敛,精度在1m左右。而LQR方法鲁棒性不足,无法实现非合作目标的接近。
图17和图18分别为两种控制器下追踪航天器的控制加速度随时间变化曲线。可以看出,控制加速度持续并不为0,而是随着非合作目标的运动震荡。
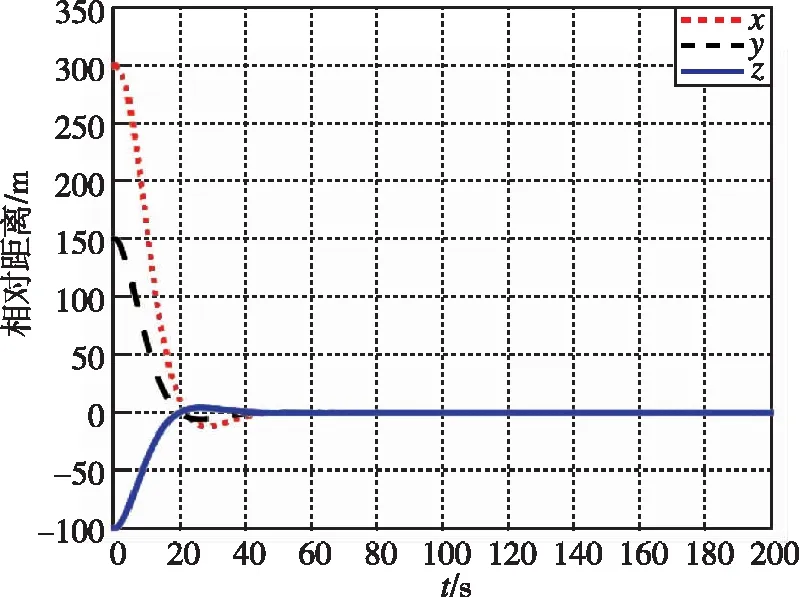
图7 相对距离随时间变化曲线(本文)Fig.7 Relative distance by game
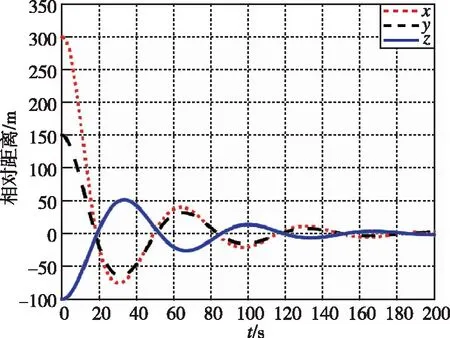
图8 相对距离随时间变化曲线(LQR)Fig.8 Relative distance by LQR
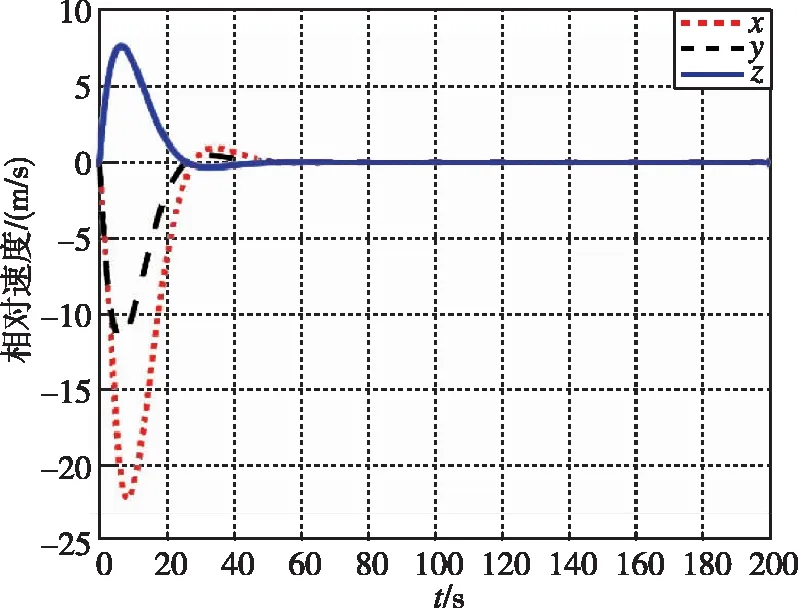
图9 相对速度随时间变化曲线(本文)Fig.9 Relative velocity by game
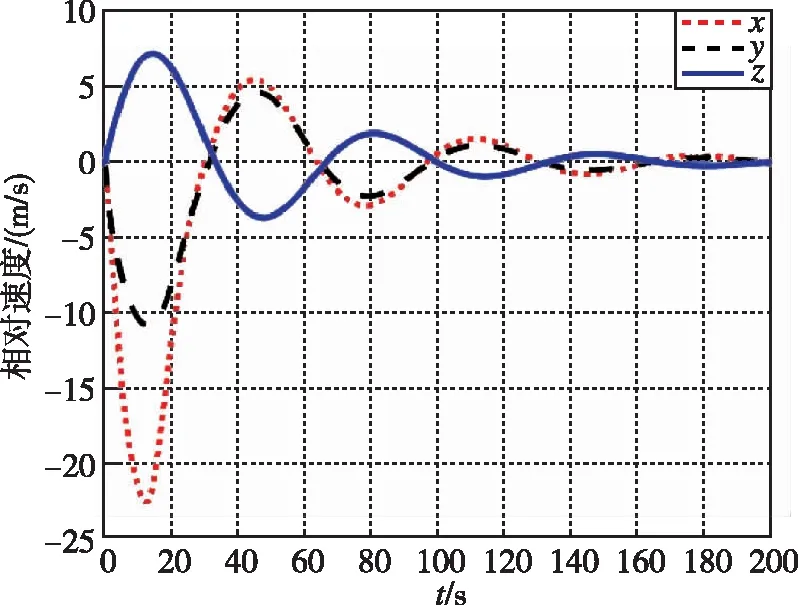
图10 相对速度随时间变化曲线(LQR)Fig.10 Relative velocity by LQR
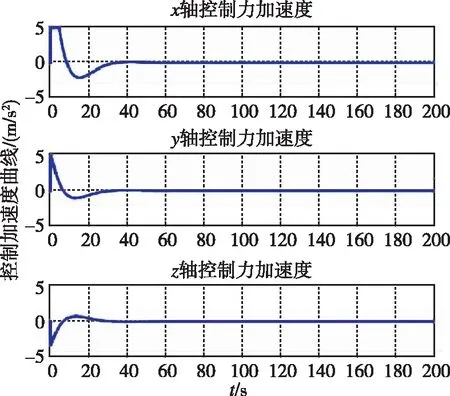
图11 控制加速度随时间变化曲线(本文)Fig.11 Control acceleration by game
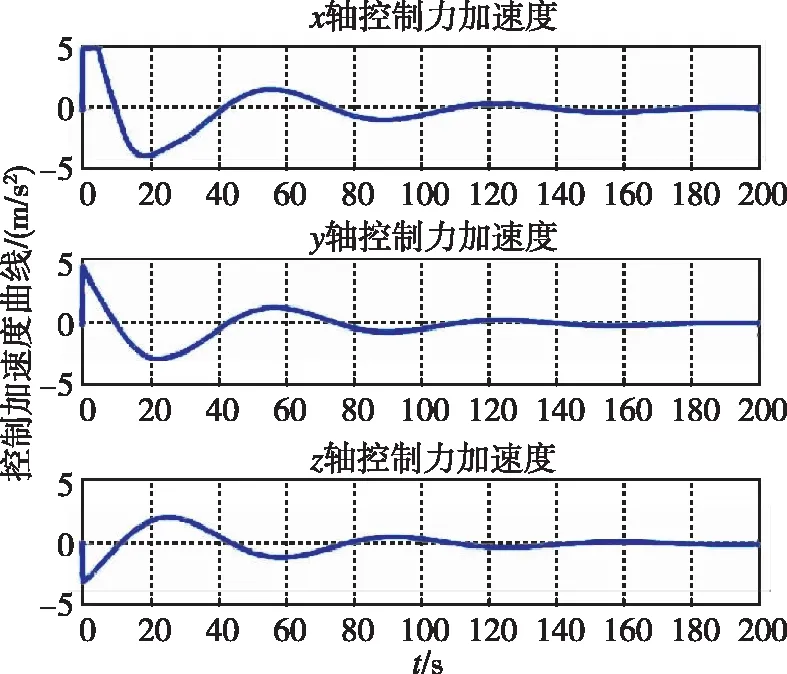
图12 控制加速度随时间变化曲线(LQR)Fig.12 Control acceleration by LQR
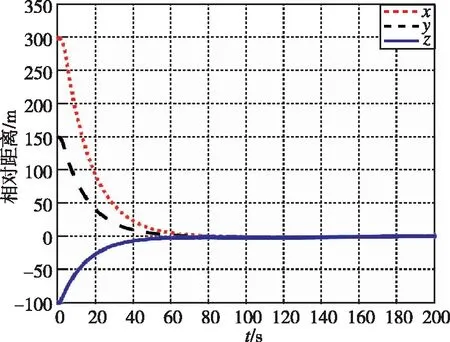
图13 相对距离随时间变化曲线(本文)Fig.13 Relative distance by game
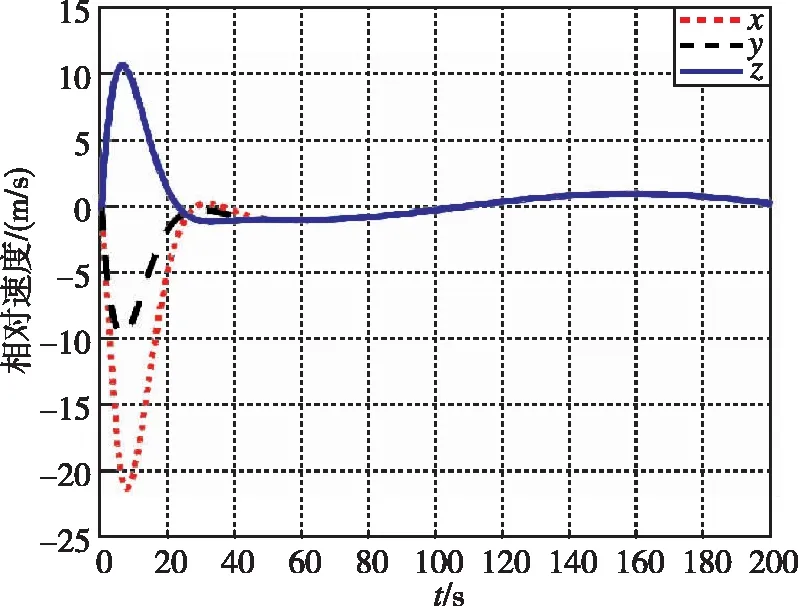
图14 相对距离随时间变化曲线(LQR)Fig.14 Relative distance by LQR
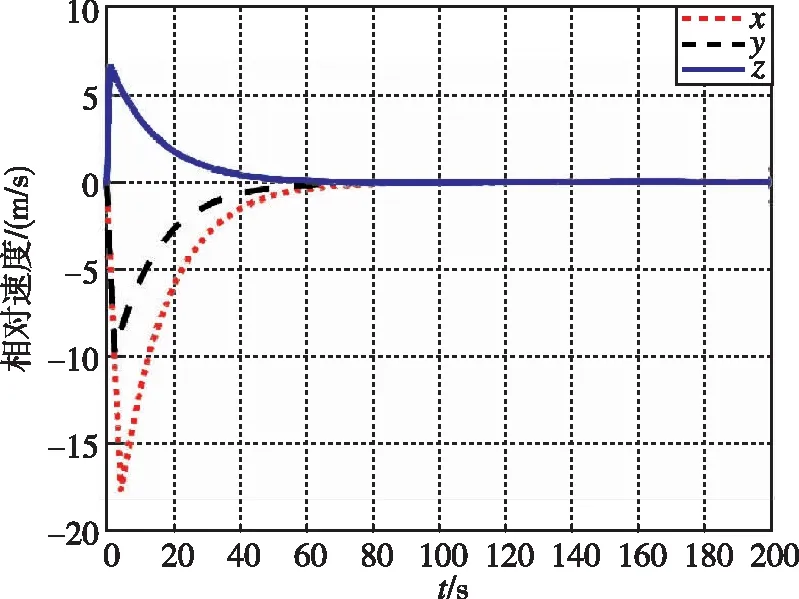
图15 相对速度随时间变化曲线(本文)Fig.15 Relative velocity by game
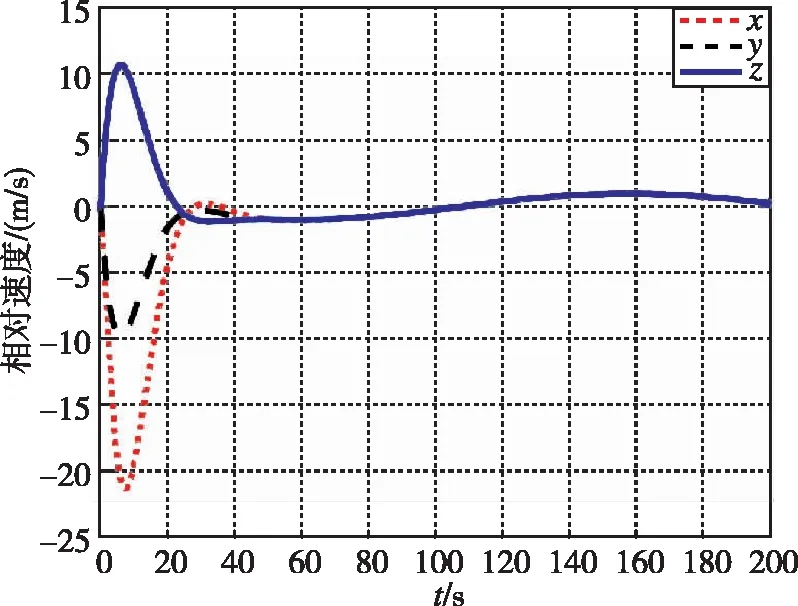
图16 相对速度随时间变化曲线(LQR)Fig.16 Relative velocity by LQR
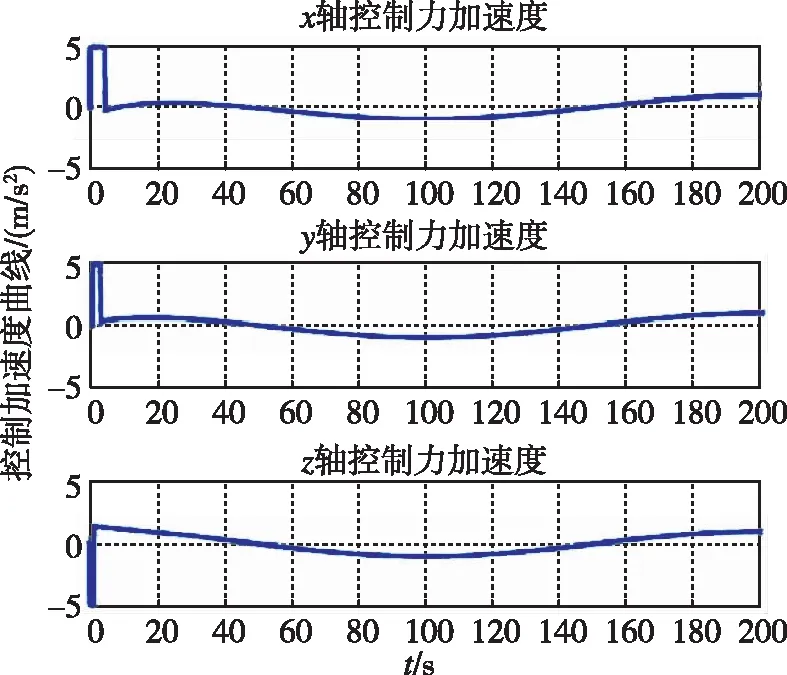
图17 控制加速度随时间变化曲线(本文)Fig.17 Control acceleration by game
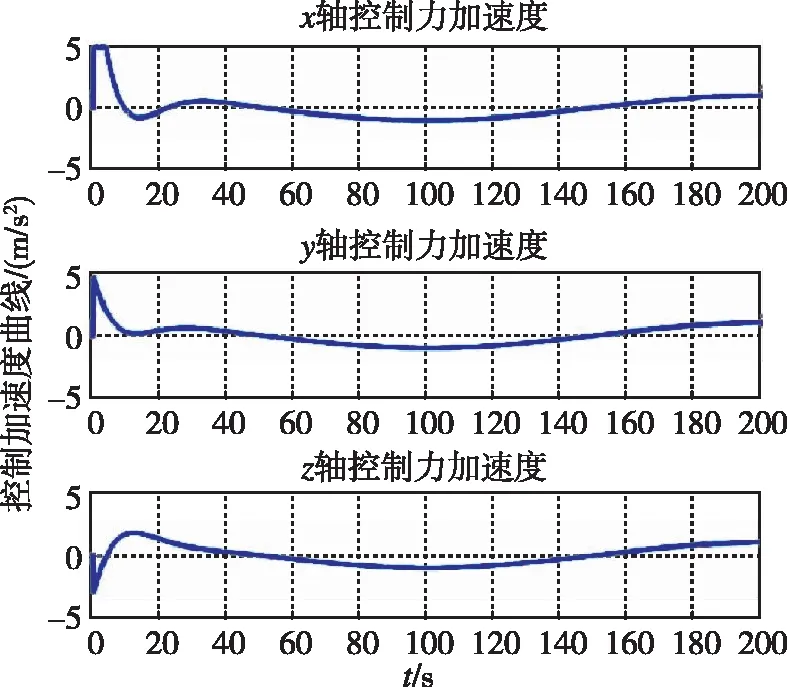
图18 控制加速度随时间变化曲线(LQR)Fig.18 Control acceleration by LQR
5 结论
本文针对空间非合作目标的接近控制问题,基于追逃博弈方法设计了追踪航天器的轨道控制器。面向非合作目标接近的任务要求,合理设计了博弈的目标函数,并结合二者的动力学约束,实现了对非合作目标和追踪航天器之间追逃博弈的数学描述。结合线性化动力学,通过优化二次型目标函数,得到线性二次型追逃博弈的纳什均衡解策略。基于追逃博弈的控制策略具有显式表达式,方便工程应用。数值仿真验证了本文设计的追逃博弈控制方法对于存在未知机动的非合作目标的有效性。本文未考虑接近过程中的姿态运动,后续研究将进一步考虑能够实现非合作目标接近的姿轨联合博弈控制。
猜你喜欢
国际太空(2022年7期)2022-08-16 09:52:50
能源工程(2020年6期)2021-01-26 00:55:22
国际太空(2019年9期)2019-10-23 01:55:34
山东冶金(2019年3期)2019-07-10 00:54:04
国际太空(2018年12期)2019-01-28 12:53:20
国际太空(2018年9期)2018-10-18 08:51:32
消费导刊(2018年10期)2018-08-20 02:57:02
中学生数理化·七年级数学人教版(2018年4期)2018-06-28 03:26:28
数学大世界(2018年1期)2018-04-12 05:39:03
中等数学(2017年2期)2017-06-01 12:21:50
