
基于注意力机制的众包任务推荐算法
2020-03-05 04:22:08赵祺雯彭瑞袁平
现代计算机 2020年3期
赵祺雯,彭瑞,袁平
(1.四川大学计算机学院,成都610065;2.重庆理工大学软件工程(两江人工智能学院),重庆400054;3.重庆第二师范学院数学与信息工程学院,重庆400067)
0 引言
随着信息技术和互联网行业的发展,信息过载的问题日益严峻。个性化推荐能够有效缓解这一问题并取得不俗的成果,能够帮助用户在以指数增长的资源中快速、准确地定位到自己需要的内容。众包指的是一个公司或机构把过去由员工执行的工作任务,以自由自愿的形式外包给非特定的(而且通常是大型的)大众志愿者的做法,众包平台一般由任务发布方、任务承接方(工人)和平台组成,发布方发布任务后工人提交自己的方案,最后由发布方决定中标人,中标人可获得相应报酬。面对众多的信息,工人难以迅速选出适合自己的任务。为了降低搜索成本,工人大多选择最近发布或排在前两页的任务,较高的搜索成本可能会降低工人的参与度,并且不利于保证任务完成的质量。帮助工人挑选与自己相关的任务是任务选择的研究重点[1]。
同时相较于主流的电商、视频新闻推送等平台,众包平台有其独有的特征,如:①众包的需求是不可重复销售的并且任务存在于系统中的时间短。②发布方提供的需求或者工人提供的服务都被他们的技能/兴趣所限制。本文将通过基于物品的协同过滤方法,利用注意力机制为用户交互过任务分配重要性权重,同时利用任务的属性信息代替id作为学习特征的输入,提高任务承接方的中标率。
1 众包任务推荐研究现状
在众包模式下,仲秋雁等人[2]提出一种考虑工人兴趣和能力的任务推荐方法,首先通过TF-IDF工人兴趣偏好模型,然后基于胜任力理论分析构建工人的KSAO能力集合融入到模型中,构建新的工人模型;在此基础上,利用几种相似性度量计算工人建融合兴趣和能力的综合相似度,以此选取临近集并生成推荐。Aldahari E等人[3]提出众包任务推荐应同时满足任务发布方、工人和平台三方的利益,其中通过计算工人的专业度得分和发布可能的报酬,但手工特征的方法缺少说服力切繁杂。施战等人[13]以任务发布者的收益最大化为优化目标,利用贪心技术设计了一种高效的任务分配机制。其次设计了一种基于历史信息的用户可靠性更新机制并将支付给用户的最终报酬与用户的可靠性挂钩。最后,从任务发布者的总效益、任务完成率和用户可靠性三个方面分析设计机制的有效性。在非众包模式下,Cheng Z等人[4]提出A3NCF模型,基于一种自适应方面注意力机制,可以捕捉同一用户对不同产品偏好的不同。首先用topic model从评论中提取user和item的特征,将提取出的特征分别与embedding后的user和itemid按点逐位相加融合,随后经过全连接层,其输出和user、item特征共同作为注意力网络的输入,最后通过MLP层进行评分预测。在bit-wise level上,Lian J等人[5]提出了Compressed Interaction Network(CIN)网络结构,目的在生成的特征在vector-wise level上,CIN结合RNN和CNN的特性完成多阶特征的抽取,并且最终和DNN以及Linear整合到一起完成显性特征的使用。其中,CIN中每一层的神经元都是根据前一层的隐层以及原特征向量推算而来。
2 个性化推荐方法
2.1 协同过滤
Item-CF通过用户历史记录推荐相关物品[7],已广泛应用于工业,因为其具有强可解释性,而且它可以使得实时个性化更容易实现,评估相似性的计算离线进行,在线的推荐模型只需要去执行,查找相似项,这很容易达到实时。Item-CF主要分为两个部分,①获取user和item的特征,可以通过如id、评论文本、属性等获取。②user和item特征间的交互,可以简单地使用相似度度量如余弦相似度,也可以用神经网络MLP[8]、CNN[10]、PNN[9]等。最终对隐式或显示反馈进行预测。
2.2 注意力机制
Attention机制的基本思想是:打破了传统编码器-解码器结构在编解码时都依赖于内部一个固定长度向量的限制。通过训练一个模型对输入进行选择性的学习并且在模型输出时将输出序列与之进行关联。Chaudhari S等人[6]按序列数将注意力机制分为distinc⁃tive(当候选和查询状态分别属于两个不同的输入和输出序列时);co-attention(同时输入多个输入序列,共同学习它们的注意力权重);self(查询和候选状态属于相同序列)。本文为组成工人特征的任务记录学习重要程度的权重,因此使用self-attention的方式[12]。
3 基于注意力机制的众包任务推荐算法
本文提出基于属性的注意力协同过滤模型AACF(Aspects-Based Attentive Collaborative Filtering)。使用任务的属性信息学习任务的表征来代替仅仅使用任务的id。任务的属性分为类别型属性(任务类别、任务形式)、数值型属性(报酬)和文字型属性(标题)。模型结构如图1所示。
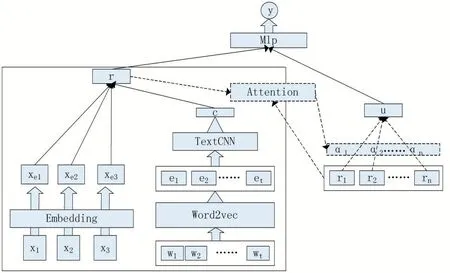
图1算法结构图
x1x2分别为任务类别和形式的category输入,x3为报酬金额经分桶处理后的category输入,经embed⁃ding层后输出各自的特征向量xej(j=1,2,3)。Wi(i=1,2,…,t)是经中文分词处理后的标题序列,t为标题最大长度,经Word2Vec模型后得到标题词向量ei(i=1,2,…,t),其维度为d,那么对于这个句子,便可以得到t行d列的矩阵A∈RS×d。作为Text-CNN[11]的输入最后得到标题特征向量c,其维度为k。Text-CNN优势在于与传统图像的CNN网络相比,网络结构更加简单,只有一层卷积,一层max-pooling,最后将输出外接Softmax来n分类。由xej和c相加得到任务的特征向量r。
工人特征向量由其历史记录中交互过的任务rm(m=1,2,…,n)经attention模块分配注意力权重后加权相加得到。图中虚线为attention部分。第i个工人交互过的任务注意力权重为ai由公式(2)得到。
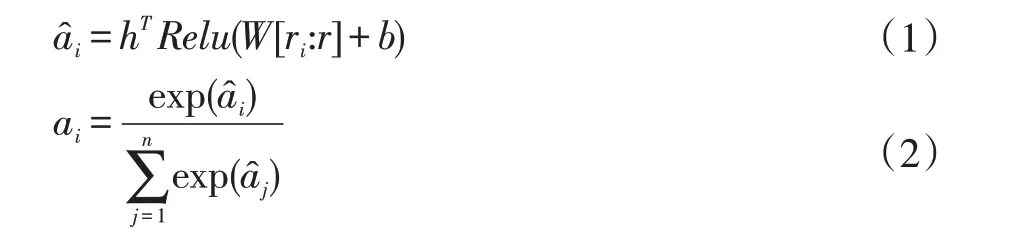
其中W和b分别是隐藏层的权重矩阵和偏置向量,hT将隐藏层映射到注意力因子,使用ReLU作为激活函数,ReLU在注意力网络中有更好表现。
最后将得到的任务特征向量r和工人特征向量u经concat操作后输入一个两层mlp网络。
训练使用logloss公式(3)作为优化时的损失函数。

其中N为正负样本总数,λ控制防止过拟合参数L2正则化的强度,Y+为正负样本集合,将工人投标并中标的记录作为正样本。Y-是负采样后负样本,负采样的候选集由工人投标但未中标,且任务周期包含工人发生交互行为日期的任务组成,(显然,由于众包任务的时效性,工人未发生交互的任务不能划分为工人没有兴趣,很可能仅仅因为这段时间工人没有承接任务的意愿),本文按候选集的15%进行负采样,采样后正负样本比例约为1:3。
4 实验与结果分析
4.1 数据集与环境
本文使用八爪鱼工具爬取网站一品威客的已完成数据,去除没有中标记录的工人的投标记录后数据集详情如表1所示

表1数据集详情
选取任务名称、任务赏金、任务分类和任务形式四个任务属性用于构建任务特征。
实验环境为Windows10操作系统16GB内存Intel Core i7 8700 CPU@3.20GHz,TensorFlow 1.13.1,Python 3.6.8。
4.2 参数设置
实验室将数据集按照任务发布时间分为训练集和测试集,分别占80%和20%。用中文分词工具jieba对标题分词,Word2Vec预训练的标题词向量维度=64,标题最长截断=18,任务和工人的特征维度=16,在利用CNN得到标题特征时,卷积核大小=3、通道数=10,工人最大交互任务数量=10。学习率=0.0001,批次训练数条数=128,为防止过拟合,采用l2正则化惩罚率=0.001,全连接层间dropout rate=0.2。训练中使用Adam进行优化,Adam通过计算梯度的一阶矩估计和二阶矩估计而为不同的参数设计独立的自适应性学习率。
4.3 评估指标
推荐系统评价是验证推荐系统是否合格的重要环节之一,本文采用AUC和HR作为评估指标。AUC(Area under ROCcurve)的物理意义为任取一对例和负例,正例得分大于负例得分的概率。HR(Hit Ratio)即测试集中,能够落在推荐列表中的top K之中的记录数,占总测试记录数的比例,由公式(4)得到。本文中由于每个时间点的负采样条数不同,因此不采用固定的K值,而采用百分比的形式,如K@10为推荐列表前10%的Hit Ratio。
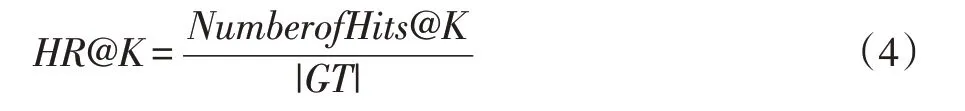
4.4 实验结果与分析
本文通过是否加入注意力机制验证注意力机制在众包任务推荐场景下的效果,并且都通过对任务属性的学习得到任务特征。实验结果AUC如图2,HR如表2所示。

图2实验结果AUC曲线图

表2实验结果HR对比
可以看到,加入注意力机制的模型在AUC和HR@10、HR@15都有更好的表现,HR指标越高代表工人越可能在推荐列表的前面就找到中标可能性大的任务。
5 结语
本文首先区别众包模式下对工人进行任务推荐和常规平台相比的特点并指出现有工作不足。随后利用item-CF结合attention model的方法实现众包模式下对工人任务中标率的预测,并且使用任务属性信息代替id学习任务特征,包括使用Text-CNN学习任务文本特征。利用众包平台真实数据,实验结果表明,在其他条件一致的情况下,利用任务属性特征较id,和融入at⁃tention机制在两个评估指标上都有更好的推荐效果。
猜你喜欢
中国新闻周刊(2023年47期)2024-01-15 12:41:04
九江职业技术学院学报(2022年1期)2022-12-02 09:46:54
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
保定学院学报(2022年2期)2022-04-07 02:26:50
许昌学院学报(2018年4期)2018-05-02 12:27:37
传媒评论(2017年3期)2017-06-13 09:18:10
中华建设(2017年1期)2017-06-07 02:56:14
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
读写算(下)(2015年11期)2015-11-07 07:21:09
中国火炬(2015年11期)2015-07-31 17:28:41
