
中大型企业数据湖建设与升级的研究
2020-03-04 22:17卢康权
科学与财富 2020年36期
摘 要:随着企业数字化转型的不断推进,业界对海量数据的存储、计算和价值挖掘的体系方法也在不断的演进,本文主要分析了企業数据湖建设的方法和理念,对比了数据湖和传统数据仓库的特点,推演了数据湖架构的升级演进过程,并且通过实际的案例展示了企业数据湖的建设流程和实践经验。
关键词:数据湖;数据仓库;数据治理;计算引擎
0 引言
在数据量爆发式增长的数字经济新时代,数据已经成为与土地、劳动力、资本和技术并列的生产要素之一,是驱动数字经济进步的推动剂。数字资源作为企业的核心资源,得到了前所未有的重视,数字化转型也成为大中型企业IT建设的重点。一般来说,企业数字化转型的过程往往都经历一个自然的演化周期:最初阶段的数据集市(DataMart)将各类应用程序所产生的数据统一存储在统一的集中式数据库内[1];在此基础上,数据仓库(Data Warehouse)按照主题领域将多个数据集市集中整合,主要用于归档、综合和深层的数据分析[2-3],但其针对非结构类数据和实时处理水平较差[4-5];而数据湖(Data Lake)是近期比较热门的概念[6-7],其是大数据存储、处理、分析、展示的基础架构。数据湖以数据为导向,能够实现全量数据采集、存储和多范式处理以及数据全生命周期管理,主要解决中大型企业对存储海量任意类型数据、完善的数据资产管理能力、更多样的分析能力、更复杂的企业级应用支撑的诉求。本文将重点阐述数据湖的特点和架构,并以实际案例为基础,总结并探讨中大型企业在数字化转型过程中如何建设并升级成数据湖的经验。
1 数据湖的特点
数据湖是数据仓库在企业数字化转型过程中逐渐演变而来的,要理解数据湖首先要说明其和数据仓库之间的区别。首先,数据仓库的主要目标用于历史数据的存储和处理,其存储的数据是高度结构化的并且一般以表格形式和结构进行存储,而数据湖可以存储任意不同类型的海量数据,除了结构化数据,还包含半结构化和无结构的媒体数据。例如海量的图片、视频、PDF、CSV、XML等。其次数据仓库存储的主要是加工后的业务数据,其本身是经过处理过的,而数据湖更多存储的是未经过处理的原始数据,无论业务数据的内容、格式和模式都是原封不动的,无需进行结构化处理,是生产数据的副本。第三,对于数据的Schema来说,数据仓库是在数据写入之前完成设计的,即先要根据业务来定义数据模型,在数据导入时需要完全跟既定数据模型吻合,其好处是数据、业务耦合度高,但灵活性差,而数据湖架构认为业务的不确定性是常态,通过保持数据原始状态,保留一定的灵活性,将Schema的设计延后,放在数据读取前,让数据具备灵活贴合业务的能力,更加适合高速变化的业务需求。第四,数据仓库具备批处理流程、商业BI分析和基本的可视化等分析能力,数据湖在数据仓库的基础上补全实时处、交互式分析等技术能力,根据企业的实际需要增加流式计算引擎、交互式分析引擎、机器学习引擎、大规模图计算引擎等。最后,两者面向的用户不同,数据仓库主要面向业务分析人员,而由于数据湖具备的上述特征,其对用户的综合能力要求更高,目标用户主要是数据科学家、数据开发人员等。
2 企业数据湖架构演进
数据湖作为新一代企业级数据基础设施,其架构的核心主要包括三部分内容:分布式对象存储、丰富的数据计算引擎以及全链路的数据安全管控。数据湖架构应充分考虑可扩展性,随着数据不断的在数据湖累积、沉淀和演化以及面向数据的业务需求不断扩张和升级,数据湖不仅要提供可持续提升的存储及计算能力,还要不断加强数据管理。例如企业数字化转型初期可能只需要对数据进行跑批处理能力并通过定义好的数据驾驶舱或数字大屏进行展示即可,但随着业务规模的不断扩张以及业务对数据分析时效性诉求的不断提升,可能需要对海量大数据(亿级别数量)进行交互式的即席分析和展示能力,以及支持流式数据实时分析能力以及强大的机器学习能力等[8-10]。
数据湖架构的演进可以分为几个阶段,初期是基于开源离线数据处理架构Hadoop,包括了存储核心HDFS、计算模型MapReduce、资源管理Yarn以及众多的大数据衍生产品,例如数据引擎Hbase、分析引擎Hive、交互式引擎Impala等[11-14]。随着技术水平提升和业务需求变化,一些实时性要求高的处理场景催生了流式计算引擎,例如Flink、Storm等。第二阶段的Lambda架构将流式计算和批量计算统一化处理,用户无需关注底层是批处理还是流式处理,数据能够按照统一的范式得到处理结果即可,从而确保了上层应用的访问一致性。然而Lambda的“流批一体化”处理链路过于复杂,因此产生了第三阶段的Kappa架构,即基于统一的流式计算引擎来处理批量和流式两种计算逻辑,其中批量数据可以通过增加并发量和时间窗口来实现批处理。
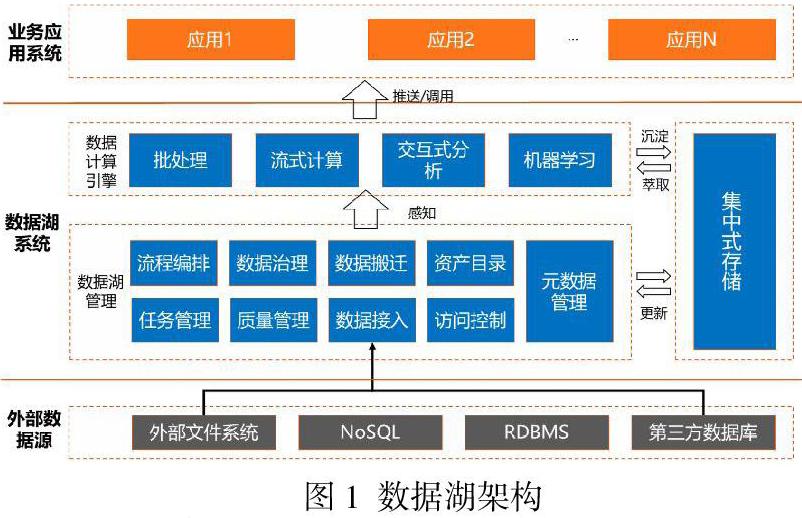
从传统的Hadoop到Lambda再到Kappa架构,主要演进的是大数据存储和处理能力,而数据湖架构更强调的是对企业全量数据的管理、加工和输出能力,具体可分为原数据管理、数据接入、数据质量管理、数据治理、数据搬迁、访问控制、任务管理、流程编排、数据资产目录几部分管理组件,如图1所示。数据湖可对各类外部异构的数据源进行抽取迁移,支持对处理数据的各类任务进行管理、编排、调度和监测,能够实现“库表行列”级别的数据访问控制,且通过元数据处理,使得计算引擎在处理数据时能直接获取数据分布、数据结构、数据模式等信息,而无需人工干预。
3 企业数据湖建设实践
以某金融监管机构为例,其数字化转型也经历了从建设数据集市到数据仓库再到数据湖的演变过程。建设数据湖是为了更加贴近企业业务而进行的,所有数据湖所包括的特性,例如元数据管理、数据资产目录、数据权限、大规模流式计算、交互式分析、机器学习技术等,都是为了更好的适应业务变化,提供更好的用户界面。企业数据湖建设的基本流程:
一、数据盘点。对于一个金融监管部门来说,构建数据湖首先就要对自身组织的内部数据以及被监管机构的外部数据全面摸底及调研,包括来源、类型、形态、结构、存量、增量等。并通过数据盘点过程进一步梳理数据和内部/外部组织的关系,为后续确定数据湖平台角色、用户、分工和功能提供打下基础。
二、技术选型。根据数据盘点摸底的情况,结合监管业务的要求,来确定技术选型。在存储引擎选型上,综合考虑到响应速度要求、使用频率、并发用户、成本等因素,数据湖应该采用的存储引擎应该具有内置多模特性,不仅能将海量原始数据进行存储,并且可以通过适当的存储引擎存储数据分析处理的结果。在实践中,我们将基于简单应用的数据可存储在Mysql中,大规模结构化数据存放在HDFS,对于海量的非结构化原始数据可存放在分布式对象存储系统如OSS(阿里) [15]、OBS(华为)、S3(AWS)。完全依赖于业务对于计算的要求选择合适的计算引擎,对于数据的加载、转换、处理使用批量计算引擎,对于需要实时计算的内容,会使用流计算引擎,对于部分实时性要求高的探索类的分析情形,则需要使用交互式分析引擎,而针对预测、回归等场景,需要引入机器学习/深度学习框架[16]。在实践中我们采用了Maxcompute、Blink、Hologres这套组合配置,能够完全胜任当前的业务需求。
三、数据整合。根据业务要求完成各种数据的梳理和归类,形成元数据资源,构建数据模型,分析数据血缘关系、形成数据地图、并完成数据的接入和整合。在实践中,我们将被监管机构的数据通过专门的数据报送工具DRP来完成结构化数据和非结构化数据的全量抽取和增量接入,并且分门别类的存储,通过数据智能研发平台进行数据血缘分析。
四、应用治理。从业务应用着手,逐步确定需求,而在数据ETL的处理中,逐步生成可使用的数据,最后形成数据模型、指标架构和对应的质量体系。数据湖技术预留了数据的处理与建模空间,能迅速跟随业务的发展变化。在实践中,我们针对各个业务处室的需求建立了金融大数据业务模型,采用数据智能研发平台实现了数据智能开发、任务管理、任务调度、数据安全隐私保护、数据迁移转换等功能[17-19]。
五、业务支撑。数据湖通过数据服务,来支撑各种类型的应用系统、BI展示工具、大屏工具。在实践中,我们建设了金融决策驾驶舱、数字大屏,并部署了BI软件,来支撑定制化多样化的报表展示。
4 结语
在中大型企业数字化推进过程中,数据湖的建设和升级是一个不断演化的过程,它更多是一种理念、一套架构方法论和一系列评判标准,而非一套成型的标准模板。针对不同业务场景、不同数据规模、不同的建设成本,数据湖都会有不同的实现路径。数据湖的核心是不断提速数据应用,简化数据采集和存储的复杂度,确保数据一致、实现统一安全管理,同时也能支持多类型处理范式等。而数据湖的建设也难免遇到很多技术上的挑战,例如把所有原始数据放到数据湖中,会增加数据利用难度,数据治理更加繁杂,数据服务效率不高,数据安全性等问题,这些问题都需要在不断迭代更新进行解决。
参考文献:
[1]马凯航,高永明,吴止锾等. 大数据时代数据管理技术研究综述[J].软件,2015,36(10):46-49
[2]张云佐,赵昕玥,高雪彤,等. 基于大数据的信息管理系统的设计与实现[J]. 软件,2018,39(9):64-68
[3]尹航,杨欢,崔海斌,等. 基于大数据应用的虚拟化云平台建设方法研究[J]. 软件,2018,39(4):201-207
[4]李苏. 基于央行视角的分布式大数据技术应用探析[J]. 软件,2018,39(3):127-129
[5]谌迅. 大数据资产管理系统的设计与实现[J].软件,2016,37(02):50-53
[6]AWS Lake Formation- Build a secure data lake in days. https://aws.amazon.com/lake-formation/
[7]陈永南,许桂明,张新建. 一种基于数据湖的大数据处理机制研究[J].计算机与数字工程,2019,47(10):2540-2544
[8]信怀义. 基于商业银行大数据访问规律的HDFS 副本策略优化研究[J].软件,2015,36(11):74-79
[9]周彩冬,潘维民. 大数据在商业银行反洗钱的应用[J].软件,2016,37(02):01-07
[10]陈惠娟,加云岗. 大数据时代下的信贷风险预警系统研究[J]. 软件,2018,39(01):39-44
[11]王书梦,吴晓松. 大数据环境下基于MapReduce 的网络舆情热点发现[J]. 软件,2015,36(7):108-113
[12]倪礼豪,叶海鹏. 三网融合环境下企业私有云PaaS 平台构建研究[J]. 软件,2015,36(8):51-54
[13]陈若飞,姜文红. Hadoop 作业调度本地性的研究与优化[J]. 软件,2015,36(2):64-68
[14]李可,李昕. 基于Hadoop 生态集群管理系统Ambari 的研究与分析[J].软件,2016,37(02):93-97
[15]基于OSS的EB级数据湖. https://developer.aliyun.com/article/772300
[16]智能數据湖运营平台DAYU. https://www.huaweicloud.com/product/dayu.html
[17]卜晓波. 试论大数据云计算环境下的数据安全[J]. 软件,2018,39(2):197-199
[18]刘文. 基于大数据优化网络的安全性策略的研究[J]. 软件,2018,39(9):205-208
[19]王刚. 基于云计算的大数据安全隐私保护研究[J]. 软件,2018,39(10):60-63
作者简介:
卢康权,1978年7月,男,浙江东阳人,硕士,工程师,大数据计算、区块链方向.
(中国人民银行杭州中心支行科技处 浙江 杭州 310001)
猜你喜欢
电子乐园·下旬刊(2021年3期)2021-02-08
自然资源信息化(2019年4期)2019-03-29
录井工程(2017年3期)2018-01-22
中国教育信息化·高教职教(2016年12期)2017-04-15
电脑知识与技术(2017年3期)2017-03-27
科技创新导报(2017年1期)2017-03-21
电子制作(2016年15期)2017-01-15
山东工业技术(2016年15期)2016-12-01
科技与创新(2016年9期)2016-05-28
湖南师范大学社会科学学报(2015年5期)2015-09-25
