
基于深度学习的作物病虫害可视化知识图谱构建
2020-03-04 13:35吴赛赛周爱莲谢能付梁晓贺汪汇涓李小雨陈桂鹏
农业工程学报 2020年24期
吴赛赛,周爱莲,谢能付,梁晓贺,汪汇涓,李小雨,陈桂鹏
基于深度学习的作物病虫害可视化知识图谱构建
吴赛赛1,周爱莲1※,谢能付1,梁晓贺1,汪汇涓1,李小雨1,陈桂鹏2
(1. 中国农业科学院农业信息研究所,北京 100086;2. 江西省农业科学院农业经济与信息研究所,南昌 330200)
针对作物病虫害领域存在实体关系交叉关联、多源异构数据聚合能力差、知识共享困难等问题,利用知识图谱以结构化的形式描述实体间复杂关系的优势,该研究提出了一种基于深度学习的作物病虫害知识图谱构建方法。该方法在领域本体的基础上,以一种与领域语料相适应的新标注模式实现实体和关系的联合抽取。将实体和关系抽取任务转化为序列标注问题,对实体和关系进行同步标注,有效提高标注效率;为了解决重叠关系抽取问题,直接对三元组建模而不是分别对实体和关系建模,通过标签匹配和映射即可获得三元组数据。利用来自转换器的双向编码器表征量(Bidirectional Encoder Representations from Transformers,BERT)-双向长短期记忆网络(Bi-directional Long-Short Term Memory,BiLSTM)+条件随机场(Conditional Random Field,CRF)端到端模型进行试验,结果表明效果优于基于普通标注方式的流水线方法和联合学习方法中的卷积神经网络(Convolutional Neural Networks,CNN)+BiLSTM+CRF、BiLSTM+CRF等经典模型,F1得分为91.34%。最后,将抽取到的知识存储到Neo4j图数据库中,直观地反映知识图谱的内部结构,实现知识可视化和知识推理。该研究构建的知识图谱可为作物病虫害智能问答系统、推荐系统、智能搜索等下游应用提供高质量的知识库基础。
作物;病虫害;模型;知识图谱;深度学习;实体关系联合抽取
0 引 言
2012年,谷歌推出知识图谱(Knowledge Graph,KG)概念,为知识管理提供了一种新途径。知识图谱实质上是一种结构化的语义知识库,以结构化的形式描述客观世界中概念、实体及其关系,一般以(实体,关系,实体)、(实体,属性,属性值)的三元组形式来表示。知识图谱能将领域的异构知识结构化,且擅于描述实体之间交互关系,将领域知识做了显性化沉淀和关联,很好地解决领域内数据分散、复杂以及孤岛化问题,在医疗、生物、金融等领域得到广泛应用[1]。根据知识覆盖范围不同,知识图谱分为开放领域知识图谱[2-5]和垂直领域知识图谱[6-8]。开放知识图谱比较注重广度,垂直领域知识图谱则注重深度,但由于缺乏标注训练语料、过度依赖于专家等原因,一般规模较小,构建成本较高。
病虫害一直以来都是影响中国农作物生产的重要因素,随着信息技术的发展,互联网成为获取病虫害防控知识的主要来源,然而当前作物病虫害领域开源知识主要以传统数据库形式进行存储,存在聚合能力差、利用率低下、知识共享困难等问题。鉴于知识图谱对领域知识管理的良好表现,目前农业领域知识图谱已有一些成果,但对于作物病虫害知识图谱的深入研究仍较少。华东师范大学基于碎片化农业大数据构建了面向智慧农业的知识图谱及其应用系统(https://github.com/qq547276542/ Agriculture_KnowledgeGraph);夏迎春[9]首先根据作物病虫害数据分类标准生成本体层,再在其基础上扩展实体层,初步形成知识图谱,并实现知识图谱可视化;吴茜[10]利用本体等技术构建农业领域知识图谱,其中涵盖了农作物品种、农作物病虫害以及农药肥料数据;王丹丹[11]构建了水稻知识图谱等。但这些知识图谱在规模化、智能化、体系化等方面仍有很大的提升空间,如何有效抽取半结构化或非结构化数据、解决文本中重叠关系的提取、减少人工特征的投入等,仍是十分有挑战性的工作。
知识图谱构建是知识表示、知识抽取以及知识存储等技术的结合。知识表示是一种计算机可以接受的用于描述知识的数据结构,但早期的知识表示方式表达性不强,且缺乏灵活性,因此目前本体已经成为最常用的知识表示、知识共享和知识重用方法。知识抽取是知识图谱构建的核心环节,包括命名实体识别(Name Entity Recognition,NER)和关系抽取(Relation Extraction,RE)任务。按照NER和RE两个任务完成的顺序不同,实体关系抽取可分为流水线方法和联合学习方法。流水线方法[12-14]将NER和RE分成2个独立的子任务,首先识别出文本中的实体,再对实体对之间的语义关系进行分类,虽然更加灵活且易于建模,但将2个任务分割的方式存在错误传播、信息丢失、实体冗余等问题。因此近年来实体关系联合学习方法成为主流,根据建模对象不同,分为参数共享和序列标注2类子方法。参数共享方法是分别对实体和关系进行建模,通过共享联合的编码层进行联合学习,实现2个子任务之间的交互[15-16],但仍存在无法剔除冗余实体信息的问题。因此,有学者[17-21]研究将实体关系的联合抽取转化为序列标注问题,在一定程度上解决实体冗余以及重叠关系问题。Liu等[22]根据作物病虫害数据特征,仔细分析近年来病虫害知识图谱构建的关键技术和方法,总结出本体学习、机器学习、深度学习等是实现知识自动抽取的重点技术,也是当前作物病虫害知识图谱的研究热点。知识图谱主要有2种存储方式,基于资源描述框架(Resource Description Framework,RDF)的存储和基于图数据库的存储。RDF的重要设计原则在于数据的易发布和共享,而图数据库以属性图为基本的表示形式,更易于表达现实的业务场景,实现高效的图查询和搜索。因此近年来基于图数据库的知识图谱存储成为主流方式,Neo4j作为一个开源的图数据库系统,是目前用于知识图谱存储的主要途径。
如何从海量复杂的作物病虫害相关数据中准确提取病原、为害部位、防治药剂等有用知识,是作物病虫害知识图谱构建的关键问题。随着信息技术的发展,深度学习已逐渐渗透到知识图谱构建的各个环节中[23]。为了提高知识抽取的效率和准确性,降低知识图谱构建成本,本研究在领域本体的基础上,以一种新颖的语料标注模式实现实体和关系的联合抽取,对实体和关系进行同步标注,直接对三元组进行建模,通过标签匹配和映射即可获取三元组,同时利用来自转换器的双向编码器表征量(Bidirectional Encoder Representations from Transformers,BERT)-双向长短期记忆网络(Bi-directional Long-Short Term Memory,BiLSTM)+条件随机场(Conditional Random Field,CRF)端到端模型进行训练和预测。最后,将抽取到的三元组数据存储到Neo4j图数据库中,实现知识图谱的可视化展示和知识推理。该知识图谱可为作物病虫害智能问答系统、推荐系统、智能搜索等下游应用提供高质量的知识库基础,有效应用于作物品种选择、病虫害防控、施肥灌溉等农业生产方面。
1 材料与方法
知识图谱构建分为自底向上和自顶向下2种方式。自底向上是指数据驱动方式,更加适用于开放领域知识图谱;而垂直领域由于其特定行业的专业性、复杂多变的业务需求以及对高质量数据的要求,多采用自顶向下的构建模式[24],即首先定义好本体与数据模式,再将实体及其相互关系填充到知识图谱中。本研究采用自顶向下的知识图谱构建方式,具体构建流程如图1所示,主要包括数据获取、本体构建、知识抽取和知识存储。

图1 作物病虫害知识图谱构建流程
1.1 数据采集与预处理
本研究的主要数据来源是中国作物种质信息网-作物病虫害知识网站(http://www.cgris.net/disease/ default.html),通过采用Python编程语言的Scrapy框架进行数据爬取,同时结合规则和人工审核等方式进行数据预处理,得到无噪声纯文本语料。由于网站XPath路径不规则,无法采用统一的XPath页面解析方法进行网页内容的直接爬取,因此以一条病虫害数据为一个基本单位,以多层级页面爬虫方式,共爬取1 619条数据,包括水稻、麦类、豆类、玉米、杂粮、薯类、棉麻、油料、糖烟、茶桑、药用植物、贮粮共12类农作物的病虫害数据。由于爬取到的数据中还存在含有网页导航、广告、重复值等无关内容和数据缺失等问题,因此利用正则表达式结合人工审核的方式,对数据中的冗余值和缺失值进行清理和补全,预处理之后的文本仍保留了原网页固有的半结构化数据形式,主要包含病虫害名称及其症状、病原、传播途径和发病条件以及防治方法等属性。
1.2 作物病虫害本体构建
本体是概念模型的明确的规范说明[25],作物病虫害本体即以一种计算机能理解的语言形式对作物病虫害知识进行描述和组织,通过上层本体的构建,可以有效地组织和管理数据层。本研究使用开源本体构建工具Protégé[26],不需要复杂难懂的本体构建语言,即可定义顶层逻辑概念、实体之间关系、实体属性,还可以对关系和属性的定义域和值域设置相应的约束。将作物病虫害本体控制为4层(图2),包括了6类父类概念,分别为病虫害、作物、病原、地理、分类学和农药。为了更精确地描述病虫害实体与其他实体类型之间的相互关系,根据数据表示特征,结合实际业务需求和领域专家指导,预定义实体间的关系集合和实体的属性集合,关系集合包括{为害作物,为害部位,分布区域……},属性集合包括{症状,为害特点,防治方法……},同时对关系和属性设定了相应的定义域和值域,明确知识抽取的边界。定义域和值域的意义在于给关系和属性的取值设定一定范围的约束,比如对于“为害作物”这个关系来说,其主体只能是病虫害实体,而其对象只能是农作物实体。

图2 面向作物病虫害知识图谱的本体模型
1.3 半结构化知识抽取
从中国作物种质信息网-作物病虫害知识网站上将数据爬取下来时,同时也获取了其半结构化信息,如标题、段落层级以及小标题等,通过实践发现可以通过利用这些半结构化特征,构造相应规则进行(名称:作物病虫害;属性1:属性值1;属性2:属性值2;……;属性:属性值)实例的抽取。首先将文本解析为结构化.json格式,其中每个作物病虫害实体为一个对象,病虫害的每个属性与属性值组成一个键值对,然后基于Python编程语言的py2neo模块,直接传入Cypher语句,将1 619条作物病虫害实例存储到Neo4j图数据库中(图3),其中每条实例为一个节点,节点包含了作物病虫害实体名称、症状、病原、防治方法等实体属性及属性值信息,如{名称:水稻云形病;症状:又称叶枯病……;病原:(Hashioka et Yokogi) W. Gams……;……;防治方法:(1)选用无病种子……}。
1.4 非结构化知识抽取
在半结构化知识抽取中是以整段文本作为一个属性值,但在属性值的文本中还包含很多未挖掘到的隐藏信息,如水稻云形病的症状属性值中,还隐藏着别名、分布区域、为害部位等实体关系信息,而抽取这些关系时属于基于非结构化数据的知识抽取。从非结构化文本中提取三元组是一个有挑战性的工作,与一般语料相比,本研究的作物病虫害语料有以下3点特殊之处:1)一条数据仅围绕一个作物病虫害实体而展开,因此在同一条数据的三元组抽取中,头实体是固定的,只需提取尾实体与两者间的关系即可。2)实体分布密度高,作物病虫害实体与文本中多个实体生成关系对,且头尾实体之间距离较长。句中的高密度实体分布看似能够促进命名实体识别模型拟合,但同一实体多次参与不同类型关系对的组成,在有限的标注信息支撑下,一旦模型缺乏句子级别语义信息的表征能力,将容易导致对交错关系的欠拟合,且距离较长的2个实体之间的关系较难抽取[27]。3)实体间关系复杂。文本中经常同时出现防治农药和禁用农药实体,实体名称相似度极高,但隶属的关系类型完全不同甚至是互斥的,在一定程度上加大关系抽取的工作难度。

图3 半结构化知识存储结果示例
根据上述的本领域语料特征,结合文献[17—21]中将实体关系的联合抽取任务转化为序列标注问题的思想,本研究以一种语料标注模式“主实体+关系+首-内部-尾-单-其他”(Main_Entity+Relation+Begin-Inside-End-Single- Other,ME+R+BIESO)实现实体和关系的联合抽取,对实体和关系进行同步标注,直接对三元组建模而不是分别对实体和关系建模,通过标签匹配和映射直接得到三元组数据,有效提高了标注效率,还解决了重叠关系的抽取问题。为进一步表征更全面的句子级别语义特征,缓解实体关系交错关联和实体之间距离较长等问题,本研究引入BERT预训练语言模型,利用BERT-BiLSTM+ CRF端到端模型进行训练和预测,不仅能抽取词级特征,还能实现句子级别语义特征的深入挖掘和学习。
1.4.1 ME+R+BIESO标注方法介绍
在一条数据仅围绕一个主实体(Main_Entity,ME)而展开描述的语料文本中进行实体和关系的抽取,本质上只需抽取与ME存在关系的实体{1,2,…,X,…X}以及2个实体之间的关系{1,2,…,R,…R},其中X表示与ME存在关系的第个实体,R表示X与ME之间的关系类型。为减少实体冗余,仅对本体中预定义关系集合内的关系进行抽取。
ME+R+BIESO标注模式旨在对主实体和主实体与各实体间的关系进行同步标注,首先将主实体标注为ME标签,当文本中某实体X与ME之间存在关系R,则直接将X的标签设置为R,并用首-内部-尾-单-其他(Begin-Inside-End-Single-Other,BIESO)标志来表示ME和实体X中字符的位置信息(表1)。每匹配到一条数据中的标签ME和同一关系R的完整BIE、BE或S集合,便取出标签集合所对应的实体ME和X,通过标签映射和数据解析,形成(ME,R,X)三元组。

表1 ME+R+BIESO标注方法的标签含义说明
注:X为与主实体存在关系的第个实体。
Note:Xis thethentity that has a relation with the main entity.
以描述水稻云形病实体的数据为例(图4),首先将水稻云形病标注为ME,由于叶枯病与水稻云形病之间存在别名关系,因此将叶枯病标注为别名(Other Name,ON),叶片与水稻云形病之间的关系为为害部位,则将叶片标注为为害部位(Damage Posotion,DP)。当匹配到主实体ME和关系ON的BIE标签集合,即生成三元组(水稻云形病,别名,叶枯病);匹配到ME和DP的BE集合,即生成三元组(水稻云形病,为害部位,叶片)。直至匹配到下一个主实体标签ME,则说明上一个主实体所对应的三元组已全部抽取完成。

注:ME为主实体,ON为别名关系,DP为为害部位关系。
ME+R+BIESO标注方法只关注主实体与各实体之间的关系类型R而无需关注实体本身所属的实体类型,只在预定义关系集合上进行标注和抽取,减少无关实体对的冗余性和错误传播。同时,对于ME与多个X之间存在重叠关系的问题,也可通过标签匹配和映射即可获得多个对应的三元组。此外,基于传统标注和流水线的实体和关系抽取方法需先对实体进行标注和识别,再对存在关系的实体对之间的关系进行标注和分类,而ME+R+BIESO方法对实体和关系进行同步标注,至少节省一半的标注成本。但该标注方法也存在一定的局限性,即仅考虑一对多的重叠关系情况,而对于多对多的重叠关系将成为未来的探索方向。
1.4.2 BERT-BiLSTM+CRF模型解析
在ME+R+BIESO标注模式的基础上,利用基于BERT字嵌入的BiLSTM+CRF端到端模型对标签进行训练和预测。模型整体框架如图5所示,主要包含3个部分:标注语料首先通过 BERT预训练语言模型生成基于上下文信息的字向量;然后将字向量输入到BiLSTM模块进行双向编码,输出每个标签的预测分数值;最后,利用CRF模块对BiLSTM模块输出的结果进行解码,通过训练学习得到标签转移概率和约束条件,获得最终的预测标注序列。
在自然语言处理(Natural Language Processing,NLP)任务中,需要通过语言模型将文字转化为向量形式以供计算机理解,传统的语言模型如Word2Vec[28]、Glove[29]等单层神经网络无法很好地表征字词的多义性,因此Devlin等[30]提出了BERT预训练语言模型,负责将原始输入转换为向量形式,然后将向量输入到BiLSTM层学习上下文特征。BERT是第一个用于预训练和NLP技术的无监督、深度双向模型,创新性地使用遮蔽语言模型和下一句预测2个任务进行预训练,使得通过BERT得到的词向量不仅隐含上下文词级特征,还能有效捕捉句子级别特征[31]。

注:E1,E2…EN为来自转换器的双向编码器表征量的嵌入,序列中的每个词都是由词向量、段向量和位置向量3个部分相加而得;T1,T2,…TN为来自转换器的双向编码器表征量的目标,是经过双向转换器进行特征提取后得到的含有丰富语义特征的序列向量;B-ON为标签ON所对应实体的首字符;I-ON为标签ON所对应实体的内部字符;E-ON为标签ON所对应实体的尾字符。
BiLSTM[32]以BERT生成的词向量作为输入,通过捕获上下文特征,获取更全面的语义信息。长短期记忆网络[33](Long-Short Term Memory,LSTM)是循环神经网络[34](Recurrent Neural Network,RNN)的一种变体,在RNN基础上引入了记忆单元和门控机制,对上下文历史信息进行有选择性的遗忘、更新和传递,从而学习到长距离的语义依赖,同时能减少网络深度和有效缓解梯度消失、梯度爆炸问题。BiLSTM由一个前向LSTM与一个后向LSTM组合而成,将原有的按照顺序输入的序列转化为一正一反的2个输入,使得整个网络能够同时获得前向和后向的信息,可以更好地捕捉较长距离的双向语义依赖,在中文序列标注中具有更好的表现。
虽然BiLSTM充分捕获上下文信息,但有时不考虑标注标签间的依赖信息。如B-ON标签后面可以接I-ON或E-ON标签,但如果接B-DP、I-DP、O等标签即是非法标签序列。CRF[35]可以通过训练学习得到标签转移概率,为预测的标签添加一些约束条件,防止非法标签的出现。因此,将CRF作为BiLSTM的输出层,可以获得最佳的三元组标注结果。
1.4.3 试验评价指标和配置环境
为了精确评测模型的性能优劣,本研究采用实体关系抽取领域的3项基本评价指标,准确率(Precision,%)、召回率(Recall,%)以及F1得分(F1-score,%)来评价模型性能。各评价指标的计算方法如式(1)~式(3)所示

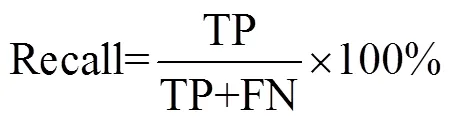

式中TP为预测正确的阳样本,FP为预测错误的阳样本,FN为预测错误的阴样本。
本研究的试验设备配置及环境为:Intel(R) Xeon(R) Bronze 3106 CPU @1.70GHz;GPU:NVIDIA GeForce RTX 2080 Ti(11G);内存32GB;Python3.7;Tensorflow2.2.0。
2 结果与分析
本研究共有1 619条作物病虫害试验数据(表2),基于交叉验证的重采样策略,以7∶3的比例划分为训练集和测试集放入BERT-BiLSTM+CRF模型进行试验。为了验证ME+R+BIESO标注方法和BERT-BiLSTM+CRF模型的优越性,分别选用流水线方法和联合学习方法中的其他经典模型作为基准模型进行对比试验,各个模型试验结果如表3所示。
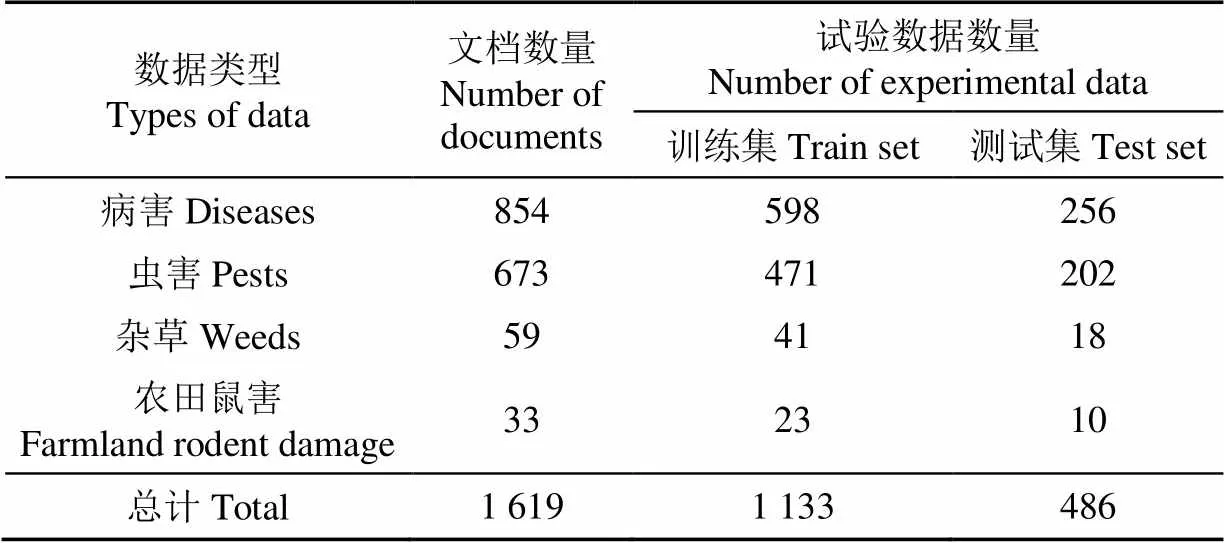
表2 BERT-BiLSTM+CRF模型的试验数据集分配
在训练过程中,按照显存容量设置批处理大小;按照语句平均长度设置序列的最大长度;根据训练日志判断损失函数的收敛情况,并对随机失活率和学习率进行微调,直到训练的损失稳定收敛;为扩展系统输出能力设置长短期记忆网络(Long Short Term Memory,LSTM)单元数目。经过多次调试和试验,选择核心参数最优组合:批处理大小为64,序列的最大长度为256,随机失活率为0.4,学习率为0.01,LSTM 单元数目为200。
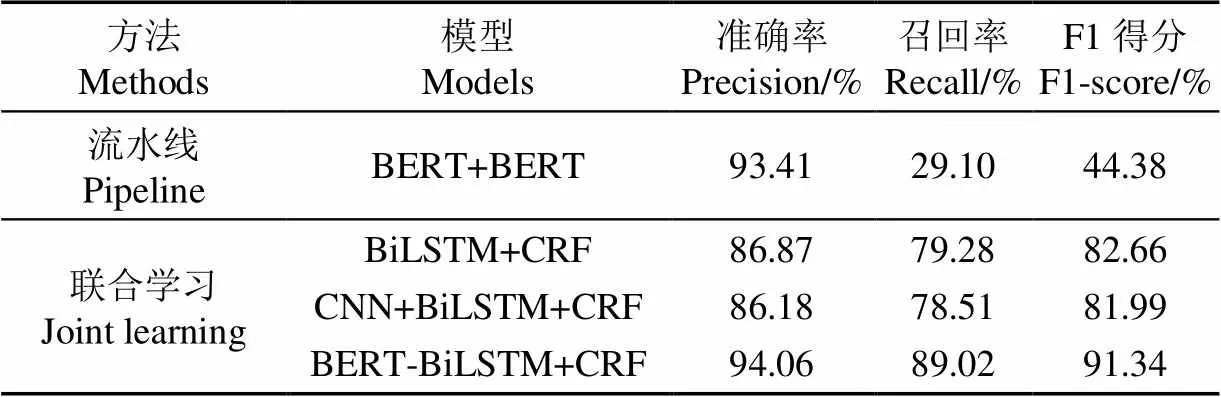
表3 实体和关系抽取模型性能对比
为了验证ME+R+BIESO标注方法和BERT- BiLSTM+CRF模型在实体和关系抽取任务中的优越性,本研究选用了流水线方法中的BERT+BERT模型和联合学习方法中的BiLSTM+CRF和CNN+BiLSTM+CRF模型进行对比试验。基于流水线的方法采用传统的实体和关系标注方法,利用BIO方式标注实体,再对存在关系的实体对进行分类标注。首先使用BERT搭建关系的分类模型,接着用预测出来的关系和作物病虫害文本,使用BERT搭建一个实体抽取模型。因此实体抽取模型就是预测每一个令牌的标示,最后根据标示可提取出实体对。基于联合学习的实体和关系抽取方法,采用本研究提出的ME+R+BIESO标注方法,分别利用BiLSTM+CRF、CNN+BiLSTM+CRF以及BERT- BiLSTM+CRF端到端模型进行试验。由试验结果可知,虽然流水线方法的准确率较高,为93.41%,但整体效果失衡,由于召回率严重偏低,为29.10%,导致F1得分仅为44.38%,通过对生成的最终预测数据的分析,发现文本中距离较近的实体对之间的关系一般能准确预测,但是距离较远的实体对基本无法预测,这说明流水线方法在用于长距离关系预测时具有很大的局限性。在联合抽取模型的对比试验中,BERT-BiLSTM+CRF模型的性能明显优于BiLSTM+CRF和CNN+BiLSTM+CRF模型。相对于BiLSTM+CRF和CNN+BiLSTM+CRF,BERT- BiLSTM+CRF的准确率分别提高了7.19~7.88个百分点,召回率提高了9.74~10.51个百分点,F1得分提高了8.68~9.35个百分点,F1得分达到91.34%。CNN+BiLSTM+CRF模型在BiLSTM+CRF的基础上增加了CNN层,但效果并没有得到优化,F1得分反而降低了0.67个百分点。不过在BiLSTM+CRF层上增加BERT预训练语言模型后,F1得分提高了8.68个百分点,说明BERT能够辅助提升模型对文本的语义表征能力,更大限度地捕捉作物病虫害文本中交错关联的实体关系,从而优化了实体关系抽取任务的效果。
BERT-BiLSTM+CRF模型对主实体与各实体间关系的预测结果如表4所示,整体效果较为均衡,F1得分为90%左右,但“为害部位”关系的预测结果明显低于平均水平,尤其是召回率仅为58.15%,这是拉低模型整体效果的重要因素。通过对“为害部位”关系的对应语料文本和最终生成的预测结果进行分析,发现文本中对同一作物部位的描述方法不统一,如“叶片”、“叶肉”、“叶面”、“叶背”、“叶鞘”、“幼叶”、“嫩叶”、“叶”等词语均为描述“叶子”这一部位。因此,这样的情况导致在预测过程中出现很多预测错误的阴样本,使得召回率严重偏低,从而影响模型整体预测水平。

表4 利用BERT-BiLSTM+CRF模型对主实体及主实体与实体间关系类型的预测结果
本研究的实体关系抽取是在本体所预定义的关系集合基础上进行的,关系预定义为非结构化知识抽取确定了边界,减少冗余信息的无效抽取,同时结合ME+ R+BIESO标注方法和BERT-BiLSTM+CRF模型进行试验,在很大程度上提高了实体关系抽取的效率和准确性,保证知识图谱的质量。
3 知识图谱存储
目前知识图谱的存储方式分为基于RDF三元组和基于图数据库。RDF三元组一般采用关系数据库进行存储,查询较为灵活高效,但同时会存储大量冗余信息,需要定时进行维护。图数据库将知识图谱的实体和概念作为图顶点,实体属性和关系作为边,以图的形式进行存储,比较直观地反映知识图谱的内部结构,有利于进行图查询以及知识推理,且可扩展性较强。Neo4j是一个开源的图数据库系统,底层使用图数据结构进行存储,大幅度提升数据检索的性能,是目前用于知识图谱存储的主要途径。因此本研究将作物病虫害知识图谱存储于Neo4j图数据库中。
由于本研究数据量不是特别大,因此采用Neo4j数据库自带Cypher语言中的LOAD CSV方式,首先将通过解析获取的实体节点和关系数据分别保存为.csv文件并放置在Neo4j的import文件夹中,然后通过Cypher语言的LOAD CSV语句导入节点和关系。采用Cypher语句将实体与实体间的关系存储到Neo4j图数据库中,形成作物病虫害知识图谱,其中包括1 619条病虫害实例信息,28 894个三元组,部分可视化展示如图6所示,其中粉红色节点为作物病虫害实体,蓝色节点为与作物病虫害实体存在关系的实体,边则为两者间的关系类型。知识图谱中交互关联的节点为隐藏关系的推理提供了很好的知识基础,如“水稻云形病”与“叶枯病”节点之间的边表示为“别名”,与“50%甲基硫菌灵可湿性粉剂”节点之间的边表示为“防治农药”,则可推理出“叶枯病”与“50%甲基硫菌灵可湿性粉剂”实体之间也存在“防治农药”的关系。

图6 作物病虫害知识图谱的可视化
4 结 论
1)本研究提出了一种基于深度学习的作物病虫害知识图谱构建方法,该方法根据作物病虫害领域的语料特征,在领域本体的基础上对半结构化和非结构化知识进行半自动化抽取,并将知识图谱存储于Neo4j图数据库中,实现实体交互关系的可视化展示和知识推理。该知识图谱研究方法在农业智能问答系统、农业物联网、农业大数据分析等方面的应用提供方法参考。
2)以一种与领域数据相适应的语料标注方式,完成非结构化知识中的实体和关系联合抽取。对实体和关系进行同步标注,三元组通过标签匹配和映射可直接获取,不仅有效提高了标注效率,还解决了一对多重叠关系抽取问题。
3)利用来自转换器的双向编码器表征量(Bidirectional Encoder Representations from Transformers,BERT)-双向长短期记忆网络(Bi-directional Long-Short Term Memory,BiLSTM)+条件随机场(Conditional Random Field,CRF)端到端模型在数据集上进行训练和预测,试验结果表明F1得分为91.34%。
尽管本研究实现的作物病虫害知识图谱已初具规模,但仍有改进空间,未来将在构建方式、多对多重叠关系抽取、自动更新等方面进行探索。知识图谱构建可采用“自顶向下”+“自底向上”相结合的方式,将自定义本体模型和数据驱动方式结合起来,既设定了清晰的逻辑概念层次,又能从公开数据集中进行自动知识抽取,同时保证知识图谱的质量和规模性。研究可扩展性和可移植性更强的实体与关系标注方法和训练模型,以解决语料中的多对多重叠关系提取问题。随着网络数据的快速更新,需要及时对知识图谱数据进行更新和补充,通过知识融合、知识推理等技术,实现知识图谱的自动更新升级。
[1]徐增林,盛泳潘,贺丽荣,等. 知识图谱技术综述[J]. 电子科技大学学报,2016,45(4):589-606. Xu Zenglin, Sheng Yongpan, He Lirong. et al. Review on knowledge graph techniques[J]. Journal of University of Electronic Science and Technology of China, 2016, 45(4): 589-606. (in Chinese with English abstract)
[2]Auer S, Bizer C, Kobilarov G, et al. Dbpedia: A Nucleus for a Web of Open Data[M]. Berlin, Heidelberg: Springer Berlin Heidelberg, 2007.
[3]Bollacker K, Evans C, Paritosh P, et al. Freebase: A collaboratively created graph database for structuring human knowledge[C]//Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data. New York, United States, 2008.
[4]Vrandečić D. Wikidata: A new platform for collaborative data collection[C]//Proceedings of the 21stInternational Conference on World Wide Web. New York, United States, 2012.
[5]Niu Xing, Sun Xinruo, Wang Haofen, et al. Zhishi. me-weaving Chinese linking open data[C]//International Semantic Web Conference, Berlin, Heidelberg, Germany, 2011.
[6]Swartz A. Musicbrainz: A semantic web service[J]. IEEE Intelligent Systems, 2002, 17(1): 76-77.
[7]Dodds K. Popular geopolitics and audience dispositions: James Bond and the Internet Movie Database (IMDb)[J]. Transactions of the Institute of British Geographers, 2006, 31(2): 116-130.
[8]阮彤,孙程琳,王昊奋,等. 中医药知识图谱构建与应用[J]. 医学信息学杂志,2016,37(4):8-13. Ruan Tong, Sun Chenglin, Wang Haofen, et al. Construction of traditional Chinese medicine knowledge graph and its application[J]. Journal of Medical Informatics, 2016, 37(4): 8-13. (in Chinese with English abstract)
[9]夏迎春. 基于知识图谱的农业知识服务系统研究[D]. 合肥:安徽农业大学,2018. Xia Yingchun. Agriculture Knowledge Service System Based on Knowledge Graph[D]. Hefei: Anhui Agricultural University, 2018. (in Chinese with English abstract)
[10]吴茜. 基于知识图谱的农业智能问答系统设计与实现[D]. 厦门:厦门大学,2019. Wu Qian. Design and Implementation of Agricultural Intelligent Q&A System Based on Knowledge Graph[D]. Xiamen: Xiamen University, 2019. (in Chinese with English abstract)
[11]王丹丹. 宁夏水稻知识图谱构建方法研究与应用[D]. 宁夏:北方民族大学,2020. Wang Dandan. Research and Application of Construction Method of Rice Knowledge Graph in Ningxia[D]. Ningxia: Northern University for Nationalities, 2020. (in Chinese with English abstract)
[12]Socher R, Huval B, Manning C D, et al. Semantic compositionality through recursive matrix-vector spaces[C]// Joint Conference on Empirical Methods in Natural Language Processing & Computational Natural Language Learning, Jeju Island, Korea, 2012.
[13]Marrero M, Urbano J, Sánchez-Cuadrado S, et al. Named entity recognition: Fallacies, challenges and opportunities[J]. Computer Standards & Interfaces, 2013, 35(5): 482-489.
[14]Kumar S. A survey of deep learning methods for relation extraction[J/OL]. Computer Science, 2017, [2017-05-10], https: //arxiv. org/pdf/1705. 03645. pdf.
[15]Miwa M, Bansal M. End-to-end relation extraction using LSTMs on sequences and tree structures[C]//Proceedings of the 54thAnnual Meeting of the Association for Computational Linguistics, Berlin, Germany, 2016.
[16]Katiyar A, Cardie C. Going out on a limb: Joint extraction of entity mentions and relations without dependency trees[C]//Proceedings of the 55thAnnual Meeting of the Association for Computational Linguistics, Vancouver, Canada, 2017.
[17]Zheng Suncong, Wang Feng, Bao Hongyun, et al. Joint extraction of entities and relations based on a novel tagging scheme[C]//Proceedings of the 55thAnnual Meeting of the Association for Computational Linguistics, Vancouver, Canada, 2017.
[18]Zeng Xiaorong, Zeng Daojian, He Shizhu, et al. Extracting relational facts by an end-to-end neural model with copy mechanism[C]//Proceedings of the 56thAnnual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 2018.
[19]Dai Dai, Xiao Xinyan, Lyu Yajuan, et al. Joint extraction of entities and overlapping relations using position-attentive sequence labeling[C]// Thirty-third AAAI Conference on Artificial Intelligence, Honolulu, United States, 2019, 33: 6300-6308.
[20]Luo Xukun, Liu Weijie, Ma Meng, et al. A bidirectional tree tagging scheme for jointly extracting overlapping entities and relations[J/OL]. Computation and Language, 2020, [2020-09-07], https: //arxiv. org/pdf/2008. 13339. pdf.
[21]奥德玛,杨云飞,穗志方,等. 中文医学知识图谱CMeKG构建初探[J]. 中文信息学报,2019,33(10):1-9. Ao Dema, Yang Yunfei, Sui Zhizfang, et al. Preliminary study on the construction of Chinese medical knowledge graph[J]. Journal of Chinese Information Processing, 2019, 33(10): 1-9. (in Chinese with English abstract)
[22]Liu Xiaoxue, Bai Xuesong, Wang Longhe, et al. Review and trend analysis of knowledge graphs for crop pest and diseases[J]. IEEE Access, 2019, 7(14): 62251-62264.
[23]张善文,王振,王祖良. 结合知识图谱与双向长短时记忆网络的小麦条锈病预测[J]. 农业工程学报,2020,36(12):172-178. Zhang Shanwen, Wang Zhen, Wang Zuliang. Prediction of wheat srtipe rust disease by combining knowledge graph and bidirectional long short-term memory network[J]. Transactions of the Chinese Society Agricultural Engineering (Transactions of the CSAE), 2020, 36(12): 172-178. (in Chinese with English abstract)
[24]李思珍. 基于本体的行业知识图谱构建技术的研究与实现[D]. 北京:北京邮电大学,2019. LI Sizhen. The Research and Implementation of Ontology-based Enterprise Knowledge Graph Construction[D]. Beijing: Beijing University of Posts and Telecommunications, 2019. (in Chinese with English abstract)
[25]Gruber T R. A translation approach to portable ontology specifications[J]. Knowledge Acquisition, 1993, 5(2): 199-220.
[26]Noy N F, Crubézy M, Fergerson R W, et al. Protégé-2000: An open-source ontology-development and knowledge-acquisition environment[C]//AMIA Annual Symposium proceeding, California, United States, 2003.
[27]宁尚明,滕飞,李天瑞. 基于多通道自注意力机制的电子病历实体关系抽取[J]. 计算机学报,2020,43(5):916-929. Ning Sangming, Teng Fei, Li Tianrui. Multi-channel self-attention mechanism for relation extraction in clinical records[J]. Chinese Journal of Computers, 2020, 43(5): 916-929. (in Chinese with English abstract)
[28]Mikolov T, Chen K, Corrado G, et al. Efficient estimation of word representations in vector space[C]// 1stInternational Conference on Learning Representations, Arizona, United States, 2013.
[29]Pennington J, Socher R, Manning C. Glove: Global vectors for word representation[C]//Association for Computational Linguistics, Doha, Qatar, 2014.
[30]Devlin J, Chang M W, Lee K, et al. BERT: Pre-training of deep bidirectional transformers for language understanding[C]// Association for Computational Linguistics, Minneapolis, United States, 2018.
[31]张秋颖,傅洛伊,王新兵. 基于BERT-BiLSTM-CRF的学者主页信息抽取[J]. 计算机应用研究,2020,37(增刊1):47-49. Zhang Qiuying, Fu Luoyi, Wang Xinbing. Scholar homepage information extraction based on BERT-BiLSTM-CRF[J]. Application Research of Computers, 2020, 37(Supp. 1): 47-49. (in Chinese with English abstract)
[32]Graves A, Fernández S, Schmidhuber J. Bidirectional LSTM networks for improved phoneme classification and recognition[C]//International Conference on Artificial Neural Networks, Warsaw, Poland, 2005.
[33]Sundermeyer M, Schluter R, Ney H, et al. LSTM neural networks for language modeling[C]// Conference of the international speech communication association, Portland, Oregon, United States, 2012.
[34]Mikolov T, Karafiát M, Burget L, et al. Recurrent neural network based language model[C]// Inter speech, Conference of the International Speech Communication Association, Makuhari, Chiba, Japan, 2015.
[35]Lafferty John, Mccallum A, Pereira F C N, et al. Conditional random fields: Probabilistic models for segmenting and labeling sequence data[C]//International Conference on Machine Learning (ICML), Massachusetts, United States, 2001.
Construction of visualization domain-specific knowledge graph of crop diseases and pests based on deep learning
Wu Saisai1, Zhou Ailian1※, Xie Nengfu1, Liang Xiaohe1, Wang Huijuan1, Li Xiaoyu1, Chen Guipeng2
(1.,,100086,; 2.,,330200,)
The knowledge graph describes the concepts, entities, and their relationships in the objective world in a structured form. It has a better ability to organize, manage, and understand massive amounts of information, and can structure heterogeneous knowledge in the field. It can be widely used in medical, biological, financial, etc. In view of the current situation in the field of crop diseases and insect pests, there are multiple relationship pairs between the same entity and multiple entities, multi-source heterogeneous data, poor aggregation ability, low utilization, and the possibility of knowledge sharing. Combining Natural Language Processing (NLP) and text mining technologies, this study focused on data acquisition, ontology construction, knowledge extraction, and knowledge storage, researched on the construction of crops diseases and insect pests knowledge graph based on deep learning. Firstly, this study used the Scrapy crawler framework of the Python programming language to crawl data from web pages related to crop diseases and insect pests, and performed data cleaning and data supplementation through data preprocessing methods. Secondly, according to the characteristics of the domain corpus, the Protégé ontology construction tool was used to complete the semi-automatic construction of the crop diseases and insect pests ontology predefined the set of properties and relations and set the corresponding domains and ranges. Then, based on the ontology, the rule method was used to extract semi-structured knowledge, and the deep learning method was used to extract unstructured knowledge. In the process of unstructured knowledge extraction, a text annotation mode “Main_Entity+Relation+BIESO” (ME+R+BIESO) adapted to the domain corpus was also proposed. Based on a predefined set of relationships, entities and relationships were simultaneously annotated, it contained entity and relationship information at the same time, and directly modeling the triples instead of separately modeling entities and relationships. The corresponding triples were also directly obtained through analysis, which not only saved at least half of the cost of labeling but also realized the joint extraction of entity relations and solved the problem of overlapping relation extraction. And this study used the Bidirectional Encoder Representation from Transformers (BERT)- Bi-directional Long-Short Term Memory (BiLSTM)+ Conditional Random Field (CRF) end-to-end model to experiment on the crop diseases and insect pests dataset. First, this study used the BERT pre-training language model to encode words, extracted text features, and used the generated vector as the input of the BiLSTM layer; BiLSTM integrated contextual information into the model at the same time, and performed bidirectional encoding to achieve effective prediction of label sequences; finally, this study used the CRF module to decode the output result of BiLSTM, and the label transition probability and constraint conditions were obtained through training and learning, and the entity label category of each character was obtained. The experimental results showed that the precision was 94.06%, the recall was 89.02%, and the F1 value reached 91.34%, which was much better than the pipeline method and classic models such as BiLSTM+CRF and Convolutional Neural Networks (CNN)+BiLSTM+CRF in the joint extraction method. The joint extraction of entity relations based on this annotation mode not only improved the efficiency and accuracy of annotation but also solved the problem of overlapping relations in the corpus. Finally, the extracted knowledge was stored in the graph database to realize the visual display of the knowledge graph and deep knowledge mining and reasoning. Combined the deep learning technology to realize the semi-automatic construction of the knowledge graph, which was of great significance for the detection of crop diseases and insect pests, forecasting and early warning, and the establishment of prevention models in the intelligent production system. It could provide a high-quality knowledge base for crop diseases and insect pests question answering systems, recommendation systems, search engines, and other applications, which could be effectively applied to crop variety selection, pest prevention and control, and fertilization and irrigation.
crops; diseases and pests; models; knowledge graph; deep learning; joint extraction of entity and relation
吴赛赛,周爱莲,谢能付,等. 基于深度学习的作物病虫害可视化知识图谱构建[J]. 农业工程学报,2020,36(24):177-185.doi:10.11975/j.issn.1002-6819.2020.24.021 http://www.tcsae.org
Wu Saisai, Zhou Ailian, Xie Nengfu, et al. Construction of visualization domain-specific knowledge graph of crop diseases and pests based on deep learning[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2020, 36(24): 177-185. (in Chinese with English abstract) doi:10.11975/j.issn.1002-6819.2020.24.021 http://www.tcsae.org
2020-10-20
2020-11-27
国家自然科学基金面上项目(31671588);国家社科基金青年项目(20CTQ019);江西现代农业科研协同创新专项(JXXTCX201801-03);中国农业科学院农业信息研究所创新工程项目(CAAS-ASTIP-2016-AII)
吴赛赛,研究方向为农业知识图谱、智能问答。Email:82101185233@caas.cn
周爱莲,副研究员,研究方向为农业信息管理。Email:zhouailian@caas.cn
10.11975/j.issn.1002-6819.2020.24.021
TP391
A
1002-6819(2020)-24-0177-09
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
计算机与生活(2022年3期)2022-03-13
古今农业(2021年2期)2021-08-14
少先队活动(2020年12期)2021-01-14
今日农业(2020年20期)2020-12-15
今日农业(2020年17期)2020-12-15
今日农业(2020年24期)2020-03-17
五邑大学学报(自然科学版)(2019年3期)2019-09-06
计算机技术与发展(2018年12期)2018-12-20
新城乡(2018年6期)2018-07-09
