
基于知识图谱的自然语言中歧义字段切分系统设计
2020-03-03 13:20杨凡任丹
现代电子技术 2020年1期
杨凡 任丹

摘 要: 传统自然语言中歧义字段切分系统设计对于歧义字段的分辨能力较差,切分效率差,准确度低。针对上述问题,设计一种基于知识图谱的自然语言中歧义字段切分系统。系统硬件设计了三个模块:采集及分词知识提取模块负责对自然语言中的字段进行收集与信息提取,辨别歧义字段;算法与测试模块处理负责检测所捕捉字段的歧义字段信息,提高系统精准度;分词识别模块负责对歧义字段进行系统切分。软件设计了系统的各项功能,包括系统分词精度提升功能、速度提升功能、完备性增强功能、可维护性以及系统可移植性增强功能,综合整理各结构的性能,进一步提高整体系统切分能力,以实现对歧义字段的切分目的。为检测系统工作效果,与传统系统进行实验对比,结果表明,基于知识图谱的自然语言中歧义字段切分系统设计的切分效果优于传统系统设计。
关键词: 知识图谱; 自然语言; 歧义字段切分; 系统设计; 信息提取; 效果检测
中图分类号: TN02?34 文献标识码: A 文章编号: 1004?373X(2020)01?0044?04
Design of natural language ambiguity field segmentation system
based on knowledge map
YANG Fan, REN Dan
Abstract: The segmentation system of ambiguous field in traditional natural language has poor resolution ability, poor segmentation efficiency and low accuracy. To solve these problems, a knowledge map based segmentation system of ambiguity field in natural language is designed. Three modules are designed for the system hardware. The acquisition and segmentation knowledge extraction module is responsible for collecting and extracting the information from fields in natural language, and distinguishing the ambiguous fields. The algorithm and testing module is responsible for detecting the ambiguous field information of captured fields, and improving the accuracy of the system. The segmentation recognition module is responsible for segmenting the ambiguous fields. The various functions are designed for the system software, including the functions of accuracy improvement, speed?up, and completeness, maintainability and portability enhancement. The performance of each structure is also integrated and the ability of the whole system to segment ambiguous fields is further improved. In order to detect the working effect of the system, some comparative experiments for the system are carried out in combination with traditional systems. The results show that the design of ambiguity field segmentation system based on knowledge map is better than that of the traditional system.
Keywords: knowledge map; natural language; ambiguity field segmentation; system design; information extraction; effect detection
0 引 言
在社会发展的过程中,我国的中文信息事业不断发展,中文信息处理技术不断提高,由于人类需要中文信息的分享与个体享用,所以也就需要更高的中文信息处理能力,由于中文信息存在较大的字段差异,因此,对于自然语言中歧义字段的切分更加重要[1]。在科技与信息产业的有力支持下,自然语言中歧义字段的切分也成了较为重要的事件[2]。自然语言中的歧义字段以普遍字段的形式存在,在语句中对于字段的使用具有较大的影响,使得所检索的语言为使用者提供两种语言解释,模糊语言表达概念,词义不准确,无法引导自然语言进行语言交流,最终影响自然语言的使用[3]。为此,需要对自然语言中歧义字段进行切分处理,在正常语言语义分析的条件下,进行基本结构与理论的自动分词操作,同时分析出分词系统的性能指标数值,并对分析出的数值进行进一步的追踪处理,不断进行切分操作,直至完成歧义字段切分[4]。
传统系统大多专注于歧义字段的表面,在进行字段切分的过程中仅仅切换字段形式,而未彻底改变字段歧义含义,无法消除使用者对字段的模糊定位,并且系统在运行的过程中受到的干扰较大,系统的运行时间较长,工作效率较低,对歧义字段的切分效果较差[5]。针对上述问题,本文提出一种基于知识图谱的自然语言中歧义字段切分系统设计,对整体系统进行结构设计,对系统的分词精度、分词速度、整体系统功能的完备性与可维护性及系统的可移植性进行综合设计处理,增强系统整合度,提高系统切分能力,以达到对歧义字段切分的目的[6]。通过实验验证了系统的有效性,实验证明,该系统在较大程度上提高了歧义字段切分的准确率,同时缩减了系统所需切分时间,大大提高了系统工作效率,增强系统切分能力。
1 自然语言中歧义字段切分系统硬件设计
自然语言歧义字段切分系统中较为核心的结构为分词中心系统,系统需要具有实用化的特点,并时刻检查其准确性与实用性程度,为此,进行系统硬件设计,分别进行系统分词精度、速度、系统功能完备性与可维护性以及系统可移植性的设计[7]。本文研究的基于知识图谱的自然语言中歧义字段切分系统硬件主要分为采集及分词知识提取模块、算法与测试模块、分词识别模块,系统硬件结构如图1所示。
1.1 采集及分词知识提取模块
采集及分词知识提取模块主要负责中文信息的文字采集,同时对信息中的交集歧义字段进行系统识别,通过知识库中的分词知识进行歧义处理,最终产生分词结果[8]。
在字段的采集中,采取改进后的字段扫描法对收集到的字符串进行逐词正向值匹配,进而找到第一个词汇的位置,并以此为初始点,进行逐词查找,匹配不成词的具体位置,同时划分查找的字段为交集歧义字段。查找后,进行进一步的歧义处理,提取知识库中的字段知识信息对字段进行歧义划分,并根据分词结果,利用知识学习方法扩充知识库中的知识储备量,其总体框图如图2所示。
在系统的分词知识提取中,要综合考虑全部规则处理后的歧义字段切分条件,同时设定某一个字段出现的频率为[P],[P]为语句中字段的总数量与句子出现的总量的比值,将此比值作为分词知识的频率因子,最后进行歧义字段的切分[9]。
1.2 算法与测试模块
由于本文系统分词操作中所选取的算法主要为以字词库与文字统计相结合的分词方式,因此,要对此种算法技能进行机能检测。在系统进行字段分词之前,同时选择不同检测方法,在完成系统字段分词后,系统屏幕上会显示系统分词过程中所耗费的总体时间,并根据此时间进行适度的系统时间处理调整。将系统网页与用户进行交互链接,同时在系统输入指令中进行文字字段的输入,将分词最终结果在屏幕上显示为文本框内输入形式,算法与测试模块示意图如图3所示。
此模块功能较为独立,可以提供较为全面的网络接口与字段信息传输,能够进行综合处理。在算法模块中,为总系统提供系统调用接口,与系统进行交互单独计算,同时保证算法与接口的功能相同,并进行实际检测与对比[10]。进一步将此模块分为字段词典管理与分词处理两个部分,在字段词典管理中,调用系统中心字段控制台,避免其在网络页面上的使用,同时进行词典的系统构建与软件更新操作。在分词处理中,先输入系统原始字段文本信息,并采用单独权值算法将文本信息中的字段词汇切分出来,进行系统运算,最终返回到分词结果中,完成系统操作。在测试模块中,对中心系统提供图形界面,并对输出输入文档进行数据管理,保存算法模块中的分词结果,并进行算法效果的检测,最终统计系统字段分词的结果[11]。
算法与测试模块工作过程示意图如图4所示。
1.3 分词识别模块
在分词识别模块中,利用计算机模拟人脑对于句子的权重理解,在分词的同时进行文本信息语法、句式及语义分析,并根据语法数据以及语义分析结果处理歧义现象。首先对总体控制部分进行语句协调,利用分字词系统的相关词汇、句子等的语法及语义分析结果对歧义字段进行分词识别,并需要同时使用数量庞大的语言语句知识数据信息,对信息中相近出现的每个字词进行组合频率的系统统计,同时计算它们之间的互现频度,以获取的互现频度来表示其结合关系的紧密程度。如果紧密程度超出规定标准参数,则可视为本字段组构成了一个词汇,进而达到对歧义字段的構成分析,并在此基础上进行数据统计,分辨系统是否需要对词典进行分词识别与切分操作[12]。分词识别模块结构图如图5所示。
由于此模块具有一定的局限性,为此,添加统计方法进行新式词汇的识别,并将串频字词统计与字符串相匹配,同时发挥分词切分速度较快、系统效率较高的优势,最终达到对分词的识别目的,并进一步实现对歧义字段的系统切分[13]。
2 自然语言中歧义字段切分系统软件设计
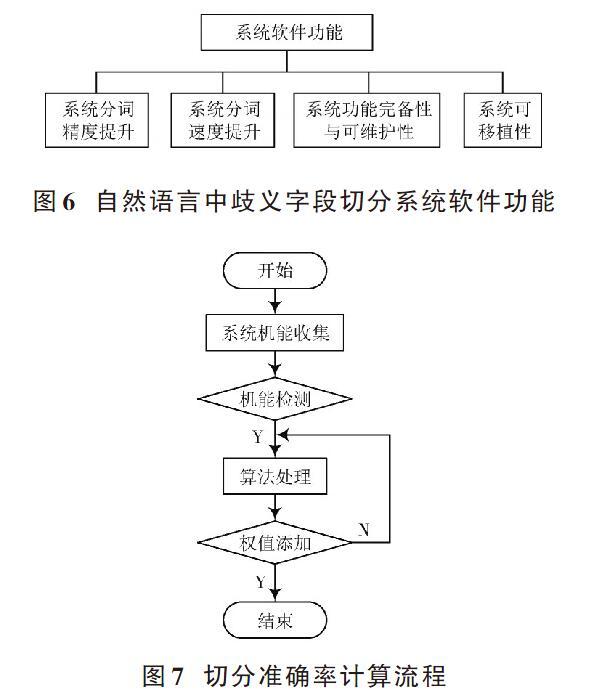
根据切分系统硬件结构设计软件程序,系统能够实现的功能如图6所示。
分词精度主要是保证切分的精确度,为核心系统的重要技术衡量标准。本文系统中,句子为连写模式,字词间空格较少,因此,本文系统首先需要解决字段切分问题。首先排除分词中中文姓名、地点名称、机构名称等专有名词的识别,在不影响更高一级处理的条件下,获取分词系统较高的准确率。从系统的整体机能、专用词汇识别以及歧义分析几个角度进行机能检测。为此,自动分词系统的切分准确率公式为:
[K=i=13αiKi]
式中:[K1,K2,K3]分别为系统机能综合测试、歧义测试以及专用词汇测试的精确度;[αi]([i=]1,2,3)为全部测试的添加权值。算法流程图如图7所示。
分词速度为单位时间下系统对于汉字处理的总个数,通常要满足分词的基本准确度条件,作为另一个较为重要的系统标准而存在,并且对于分词准确度的算法较多,本文利用辅助手段,通过对系统想象、原则主义、神经网络框架以及专业系统等方法进行算法加强,同时排除影响因素:汉字符号机械切分的同时搜索词典的时间、自然语言中歧义字段的查询与系统矫正等。在中文信息的处理过程中,先对数量较为庞大的文本信息进行区分处理,同时合理考虑系统总体成本问题。通过人机交互处理的方式,解决字段中的歧义问题,并根据问题进行策略的统计与人机连接口的系统设计,由于系统在运行过程中会对切分速度造成影响,因此,要综合处理系统切分器的机能反应,并进行反应检测,从而减少系统切分时间的影响。
针对自动分词系统的功能完备性与可维护性,本文系统着手考虑系统的词库增减删除、字词修改、字段查询以及语句成批处理等基本系统能力,同时对系统进行修正性维护处理,适应性与维护性系统机能增强处理[14]。首先满足系统数据信息存储以及运算功能补充的属性条件,综合处理词库的储存构造以及输出输入的形式变化状况的拓展与完善,将此项标准与分词系统的系统清晰度、模块化、结构简洁性与系统完备性进行直接连接处理,并不断进行提高与改进,使其能够较好地适应中文字段信息的处理应用问题。
在分词系统的可移植性中,综合考虑系统移动性能,简化应用系统从本机环境转移至另一种系统环境中的转移步骤,并对其进行系统修正,使其能够更好地适应转移环境,同时增强系统的转移器调制能力,能够使系统仅需简便操作便可完成对整体系统的转移。综上进行综合系统设计,在完善系统结构的基础上,提高系统整体切分能力,为系统歧义字段切分奠定基础。
3 实验研究
3.1 实验目的
为了检测本文基于知识图谱的自然语言中歧义字段切分系统设计的切分效果,与传统自然语言中歧义字段切分系统进行了对比。
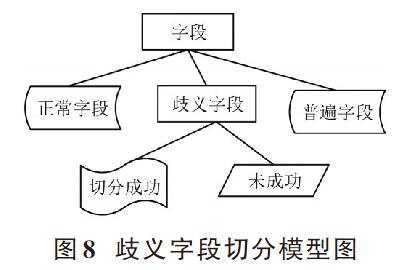
3.2 歧义字段切分模型建立
针对自然语言中的字段存在模式对歧义字段进行分类与切分处理,并进行歧义字段切分模型的建立,歧义字段切分模型图如图8所示。
根据上述建立的模型,进行实验参数的设定:
1) 测试系统为专业词测试系统和歧义测试系统;
2) 选取相同中文字段;
3) 采取权值加重法,选用标准精度的分词设备;
4) 语言环境固定;
5) 独立系统自动进行分词。
3.3 实验结果与分析
根据上述切分模型进行对比实验,将本文基于知识图谱的自然语言中歧义字段切分系统的切分效果与传统自然语言中歧义字段切分系统的切分效果进行对比,得到的切分准确度对比图与相同时间内切分效率对比图如图9,图10所示。
对比图9,图10可知,在相同的参数条件下,本文系统切分的准确度随时间不断增长,且增长幅度较大,相同时间内,对于歧义字段切分的数量较多,系统工作效率较高。而传统系统切分的准确度虽然随时间增长,但增长幅度较小,且一直低于本文系统,在相同工作时间内,对于歧义字段的切分数量较少,切分效果较差,工作效率较低。
本文系统大幅度提高了对自然语言中歧义字段的切分准确率,能够较为清晰地分辨歧义字段与正常字段,保证系统的正常工作,提高中文信息的处理能力,在一定程度上缩减了系统的切分时间,提高了系统的工作效率,满足使用者对于系统自动分词的需求,具有较为强大的系统工作能力。
4 结 语
本文在传统设计的基础上设计了一种基于知识图谱的自然语言歧义字段切分系统,相对于传统系统,本文系统设计对于自然语言中歧义字段的切分准确度更高,能够更好地提供歧义字段信息,及時避免分词错误,较大程度上减少了歧义字段的切分时间,进而提高了整体系统的工作效率,同时为中文处理系统提供更加强大的切分系统支撑,进一步满足用户对于歧义字段切分的较高要求,具有更为广泛的市场前景与可推广性。
参考文献
[1] 邱均平,方国平.基于知识图谱的中外自然语言处理研究的对比分析[J].数据分析与知识发现,2018,30(12):51?61.
[2] 任函,孙为.知识图谱在智能教学系统中的应用[J].开封教育学院学报,2017,37(6):171?173.
[3] 蒋锴,钱夔,郑玄.基于知识图谱的军事信息搜索技术架构[J].指挥信息系统与技术,2016,7(1):47?52.
[4] 时雨,古天龙,宾辰忠,等.基于知识图谱的旅游景点问答系统[J].桂林电子科技大学学报,2018(4):296?302.
[5] 赵维平,孙宁,杨晓春,等.基于知识图谱的东方音乐可视化教育研究与应用[J].计算机工程与科学, 2018, 40(z1):56?62.
[6] 郑逢斌,付征叶,乔保军,等.HENU汉语自动分词系统中歧义字段消除算法[J].河南大学学报(自然版),2019,34(4):49?52.
[7] 张培颖,李村合.一种改进的上下文相关的歧义字段切分算法[J].计算机系统应用,2018,15(5):46?48.
[8] 张培颖,李村合.基于知识库的交集型歧义字段切分系统[J].计算机系统应用,2016,15(8):42?43.
[9] 张利,张立勇,张晓淼,等.基于改进BP网络的中文歧义字段分词方法研究[J].大连理工大学学报,2017,47(1):131?135.
[10] 张严虎,潘璐璐,彭子平,等.基于规则挖掘和Na?ve Bayes方法的组合型歧义字段切分[J].计算机应用,2018,28(7):1686?1688.
[11] 申琳.中文分词算法及改进研究[J].电脑知识与技术,2017(11):199?200.
[12] 胡阿明,王卫东.中文分词歧义识别算法的优化[J].现代电子技术,2012,35(8):107?109.
[13] 曲维光,吉根林,穗志方,等.基于语境信息的组合型分词歧义消解方法[J].计算机工程,2016,32(17):74?76.
[14] 秦锦玉,翟洁,陈程,等.基于知识图谱的可视化技术研究[J].电子设计工程,2018,26(14):1?5.
作者简介:杨 凡(1981—),男,湖北襄阳人,硕士,讲师,研究方向为数据挖掘和云计算。
任 丹(1976—),女,湖北襄阳人,讲师,研究方向为数据挖掘、计算机图形学。
猜你喜欢
航海(2017年1期)2017-02-16
智富时代(2016年12期)2016-12-01
智富时代(2016年12期)2016-12-01
中国远程教育(2016年9期)2016-11-19
数字技术与应用(2016年9期)2016-11-09
科技视界(2016年22期)2016-10-18
中国教育信息化·基础教育(2016年9期)2016-10-18
电脑知识与技术(2016年14期)2016-06-30
电脑知识与技术(2016年2期)2016-03-22
科技视界(2015年25期)2015-09-01
