
基于Scrapy的分布式网页及文件爬虫应用的研究
2020-03-02 01:14张捷郝建维李欢欢
科技创新导报 2020年21期
张捷 郝建维 李欢欢
摘 要:随着移动互联网、大数据以及人工智能时代的到来,数据在整个互联网体系中的地位显得越来越重要,而数据体量的大小对大数据的分析以及人工智能的最终学习成果也有着深刻影响。但是目前的现状是,全世界范围内的大多数企业都深陷数据不完善或者数据体量太小的窘境,尤其对新创企业和小微型企业来说,这个已经成为了它们生存和发展的桎梏。因此,能够从无时无刻抓取大量数据的爬虫就显得尤为必要,故而我们深入地研究网络爬虫是非常有必要的。本文将会通过基于twisted的异步爬虫框架Scrapy,对网络爬虫进行研究,并实现抓取互联网页数据以及文件文本数据的分布式策略。
关键词:Scrapy Python 爬虫 分布式 文件 网页
中图分类号:TP391.3 文献标识码:A 文章编号:1674-098X(2020)07(c)-0149-05
Abstract: With the advent of the mobile Internet, big data and artificial intelligence era, the status of data in the entire Internet system is becoming more and more important, and the amount of data has a profound impact on the analysis of big data and the final learning results of artificial intelligence. However, the current status quo is that most companies around the world are deeply mired in data imperfections or too small data volume, especially for new ventures and small and micro enterprises, which have become their survival and development. Therefore, it is especially necessary to be able to crawl large amounts of data from time to time, so it is very necessary for us to study web crawlers in depth. This article will explore the layer web crawler through the twisted asynchronous crawler framework Scrapy, and implement the strategy of crawling Internet page data and file text data.
Key Words: Scrapy;Python;Crawler;Distributed;File;WebPage
1 引言
隨着互联网在人类经济社会中的应用日益广泛,其所涵盖的信息规模呈指数增长,信息的形式和分布具有多样化、全球化特征。专业化的信息获取和加工需求,正面临着巨大的挑战。如何获取互联网中的有效信息?这就促进了“爬虫”技术的飞速发展。
传统的爬虫对于网页内容信息的关注远远大于其他形式的存储的信息。然而,互联网作为人类巨大的数据宝库,并不仅仅只存有网页内容信息,还存在极其庞大的各种各样格式的文件信息。
本文将以Scrapy为框架,对以文件和网页进行抓取并进行内容解析的分布式爬虫进行研究和设计。
2 网络爬虫
网络爬虫,是一种按照一定的规则,自动地抓取互联网信息的程序或者脚本。网络爬虫一般从一个url开始,通过获取网页内容,并识别网页上的其它url,放入url队列中,再不断地从队列中获取url重复上述过程,直至url集合为空。
对于爬虫的分类,我们可以从爬虫面向的对象和url入队方式的不同,分为以下四种。
(1)通用网络爬虫,又称为全网爬虫,一般搜索引擎采用这种类别的爬虫。通用爬虫可以以一定数量的种子url开始,对整个互联网的网络信息进行采集,供搜索引擎使用。这类爬虫的爬取范围和数量巨大,对速度和存储有着很高的要求。基于这两点要求,通用爬虫一般会采取一定的策略,常见策略有:广度优先策略和深度优先策略。
①广度优先策略:其基本原理是按照深度由小到大的顺序,依次访问url,直到没有url可以访问为止。爬虫在访问一条分支后返回到最后url的上一级搜索其它url,直至所有的url访问完毕。这种策略一般使用于垂直搜索。
②深度优先策略:这种策略将所有url划分为多层,当同一层的链接访问完毕后才深入到下层链接进行访问,直到所有的链接访问完毕。这种策略对爬虫访问的深度能够很好控制,防止爬虫进入过深的分支。
(2)聚焦网络爬虫,又叫定向爬虫,是指有选择性地爬取指定内容或特定链接的网络爬虫。聚焦网络爬虫引入了评分模块,针对网页内容或链接信息对其进行评分,不同的评分,访问的优先级也不同。
(3)增量式网络爬虫是指只爬取新产生的或发生内容改变的网页的爬虫,对已经爬取的并且没有内容变化的网页不进行采集。
(4)深层网络爬虫一般是指爬取深层网络页面的网络爬虫。深层网络页面是相对于能够任意访问的表层网络页面而言的,一般类似于用户需要登录或需要提交关键字才能访问的页面,我们就称之为深层网络页面。
3 Scrapy原理介绍
Scrapy是Python开发的一个以twisted异步网络通信为核心的网络爬虫框架。因为其灵活性和易扩展性让Scrapy广为人们使用,且用途非常广泛,可以用于数据挖掘、监测和自动化测试等。
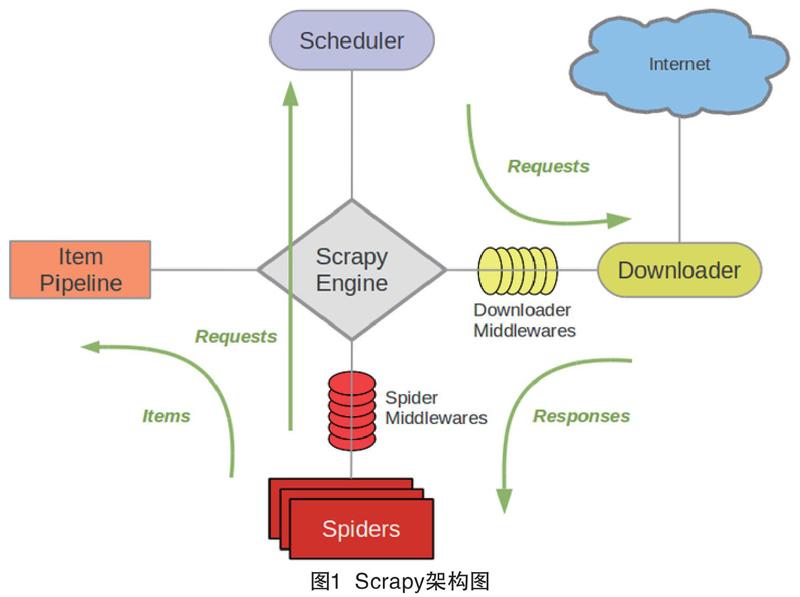
Scrapy的总体架构可以分为以下部分:
(1)引擎(Engine),主要负责Spider、Downloader、Itempiplien以及Scheduler之间通信,信号和数据传递。
(2)调度器(Scheduler),接收Engine传递过来的Request请求,将请求整理,入队,并且在Engine需要Request的时候,将Request传递给Engine。
(3)下载器(Downloader),下载Engine推送的Request,并将下载好的Response返回给Engine。
(4)爬虫(Spiders),接收Engine推送的Response,解析Reponse内容,并根据内容获取Item需要的数据,并且提取页面相关链接,重新生成Request推送给Engine,由Engine交由Scheduler。
(5)项目管道(Pipeline),负责处理爬蟲从网页中抽取的实体,并对实体进行业务操作。
(6)下载器中间件(Downloader Middewares),介于Engine和Downloader之间,主要处理两者之间的请求和响应。
(7)爬虫中间件(Spiders Middewares),介于Engine和Spider之间,主要工作是处理Spider的响应输入和请求输出。
(8)调度器中间件(Scheduler Middewares),介于Scrapy引擎和调度之间的中间件,处理从Scrapy引擎发送到调度的请求和响应。
5种核心组件极其中间键通过异步网络进行通信,各自完成自己的功能而不依赖于其他组件的装填。正是这种通过异步网络通信的低耦合架构,让Scrapy在解析url,下载内容,实体处理上有着非常高的效率。
4 分布式网页及文件爬虫解决方案
虽然异步网络通信架构使Scrapy能在短时间访问大量的链接,但是相较于互联网庞大的数据体量而言,还是显得力不从心。于是我们考虑设计分布式的爬虫架构来满足现在的互联网的需求。
我们可以使用Scrapy-Redis组件来扩展Scrapy,Scrapy-Redis 是为了更方便地实现 Scrapy 分布式爬取而提供的一些以 Redis 为基础的组件。然而Scrapy-Redis对Redis去重队列的策略仍存在着一些弊端,导致队列无限地增长。如何优化Scrapy-Redis,并实现网页和文件的爬取将是接下来的主要内容。
4.1 Scrapy-Redis的去重优化
Scrapy去重在配置文件中去重是默认开启, 主要通过RFPDupeFilter类进行去重,通过查看RFPDupeFilter类源码,可看到去重的核心是request_seen方法,其代码如下:
def request_seen(self, request)
fp = request_fingerprint(request)
added = self.server.sadd(self.key, fp)
return not added
其中request_fingerprint方法对requset进行sha1加密,将加密过后的密文存储到Redis的dupefilter去重队列中,当Spider之后每次获取网页上连接生成request后,再一次通过requset进行加密,并与dupefilter队列中的数据进行比较,如果发现有重复数据,则当前request不进入Scheduler的url队列中。然而,dupefilter队列会随着访问的链接增长而持续增长,这样就会消耗大量的内存资源和比较request的时间资源。
Bloom filter 是由 Howard Bloom 在1970年提出的二进制向量数据结构,它具有很好的空间和时间效率,被用来检测一个元素是不是集合中的一个成员。如果检测结果为是,该元素不一定在集合中;但如果检测结果为否,该元素一定不在集合中。因此Bloom filter具有100%的召回率。利用Bloolm的特性,我们可以优化scrapy的去重队列。
通过重写request_seen()方法,使用Redis的Bloolm类对入队过程进行改写,Bloolm filter的特性快速的判断request是否存在,如果存在,则不将request放入url队列。通过重写后代码如下:
def request_seen(self, request):
fp = request_fingerprint(request)
if self.bf.isContains(fp): # 如果已经存在
return True
else:
self.bf.insert(fp)
return False
至此,我们通过Bloolm filter改写后的去重组件,能够极大地提升我们的去重效率和内存资源。
4.2 网页和文件的策略
4.2.1 网页爬虫策略
Scrapy爬取数据过程可以分为定义实体(Item)、抽取内容(Spider),存储实体(Pipeline)三个部分,通过这三个部分,能够快速地实现一个网页爬虫,这也是Scrapy框架流行的重要原因。
(1)Item是保存爬取到的数据容器,使用方法和Python字典类似。根据从网页上获取到的数据对Item进行统一建模。从而在Item中定义相应的字段field。示例代码如下:
class CrawlerItem(scrapy.Item):
#标题
title = scrapy.Field();
#内容
content = scrapy.Field();
#链接
hrefs = scrapy.Field();
#url
url = scrapy.Field();
(2)Sprider的parse方法是抽取内容的主要方法,Spider类必须继承scrapy-redis. spiders.RedisSpider类以实现分布式采集,Spider采集过程是,首先从Redis的start_url中读取种子url,由Download下载返回response,Engine会将response传递给spider的parse方法,由parse方法对reponse进行处理,并返回request生成器和item生成器。抽取页面内容时,可以使用xpath模块。Scrapy内置对xpath支持,能够快速地提取页面内容。代码如下:
def parse(self, response):
url = response.url;
item = CrawlerItem();
item['title'] = response.xpath(
'//head/title/text()').extract();
item['content'] =self._get_content(
response.body.decode(response.encoding))
item['url'] = response.url;
item['hrefs'] = self._get_href(response);
yield item;
for href in item['hrefs']:
yield Request(url= href,
callback=self.parse);
(3)Pipeline是數据存储的管道,parse提取的Item由Enginec传递给Pipeline,调用Pipeline的process_item方法对Item进行存储操作,示例如下:。
def process_item(self, item, spider);
#处理数据
logger.info(item['url']+' has crawled');
通过这三个部分的简单实现,一个能够爬取网页的标题,内容,页面链接以及当前页面的通用型网页爬虫产生了。常见的互联网页面就可以通过该爬虫进行采集。
4.2.2 文件爬虫策略
文件爬虫的策略整个流程与与网页爬虫的策略相似,而且Scrapy支持FTP形式的文件爬虫,但是Scrapy的FTP并不能对整个文件节点的文件进行下载,只能手动地推送文件的url,对该url的单个文件进行下载。而我们希望通过配置FTP的根节点,来采集整个FTP节点的所有文件,并解析文件内容。我们对原Scrapy的FTP爬虫框架进行优化,以支持FTP节点的整体下载。
Scrapy主要通过FTPDownloadHandler类对文件进行下载,该类中由download_request方法生成FTP连接生成器对象,gotClient方法通过生成器对象来获取FTP的客户端,并通过_build_response私有方法下载文件,如果文件出现错误,则由_failed方法返回错误内容。
gotClient方法只能下载文件,如果url为文件夹路径,则会返回错误信息。gotClient源码如下:
def gotClient(self, client, request, filepath):
self.client = client
protocol = ReceivedDataProtocol
(request.meta.get("ftp_local_filename"))
return client.retrieveFile(filepath, protocol)
.addCallbacks(callback=self._build_response,
callbackArgs=(request, protocol),
errback=self._failed,
errbackArgs=(request,))
通过集成FTPDownloadHandler类,重写gotClient方法,我们可以实现当url为文件夹路径时,获取该路径下的文件名,并将文件名放入response中返回,交由spider处理,当url为文件路径时,下载文件,返回response。另外,通过对response.meta.file_type进行设置,当url为文件夹时设置为dir,为文件时设置为file来判别url的类型。实现代码如下:
def gotClient(self, client, request, filepath):
self.client = client
protocol = ReceivedDataProtocol(request.meta.get("ftp_local_filename"))
if (not 'file_type' in request.meta) or ('dir' in request.meta['file_type']):
return client.list(filepath, protocol)\
.addCallbacks(callback=self._build_response,
callbackArgs=(request, protocol),
errback=self._failed,
errbackArgs=(request,))
else:
return client.retrieveFile(filepath, protocol)\
.addCallbacks(callback=self._build_response,
callbackArgs=(request, protocol),
errback=self._failed,
errbackArgs=(request,))
Spider獲取到reponse后,判断response.meta.file_type,如果为dir,则解析reponse的文件名,并生成相应的url,包装成Request放入Scheduler的url队列;如果为file,则抽取相应内容,存储实体。spider代码如下:
def parse(self, response):
item = CrawlerItem();
url = response.url;
ftp_user = response.meta['ftp_user'];
ftp_password = response.meta['ftp_password'];
#当文件为文件夹或者file_type 为None时,获取当前文件夹下的所有文档及文件夹
if (not 'file_type' in response.meta) or ('dir' in response.meta['file_type']):
content = response.body.decode('latin-1')
line = content.split('\r\n');
re_fileName = re.compile('[^\s]+', re.I)
for files in line:
#判断目录
#通过空格分隔信息
infos = re_fileName.findall(files);
if not infos:
continue;
file_name = infos[-1];
if '
req = Request( url = url+'/'+file_name,meta={'file_type':'dir','ftp_user':ftp_user,'ftp_password':ftp_password},callback=self.parse,dont_filter=True);
else:
req = Request( url = url+'/'+file_name,meta={'file_type':'file','ftp_user':ftp_user,'ftp_password':ftp_password},callback=self.parse);
yield req;
logger.debug(response.body.decode('gbk')+' has puted in quee');
else:
util = FileUtil();
file_name = url.split('/')[-1];
item['content'] =util.get_content(file_name,response.body);
url = parse.unquote(url);
title = url.split('/')[-1];
item['title'] = title.encode(encoding='latin-1').decode('gbk');
item['url'] = url;
yield item;
至此,一个FTP节点爬虫就实现了,我们可以通过配置根节点url到start_url队列中,来采集整个FTP节点的文件内容。
5 结语
Scrapy虽然有着扩展性好。易于开发的特点,但是单节点的爬取方式已经不能适应信息指数式增长大数据时代,而集成了scrapy-redis组件的Scrapy虽然能够分布式部署,但是内存会持续消耗,并且速度也会逐渐降低。
优化后的scrapy-redis,大大降低了内存使用量,在速度上也有所提升。另外,文件节点整体爬取的问题也得到了有效的解决,能够满足现有互联网信息爬取的大部分需求。
参考文献
[1] 李光敏,李平,汪聪.基于Scrapy的分布式数据采集与分析——以知乎话题为例[J].湖北师范大学学报:自然科学版,2019,39(3):1-7.
[2] 华云彬,匡芳君.基于Scrapy框架的分布式网络爬虫的研究与实现[J].智能计算机与应用,2018,8(5):46-50.
[3] 陶兴海.基于Scrapy框架的分布式网络爬虫实现[J].电子技术与软件工程,2017(11):23.
[4] 李代祎,谢丽艳,钱慎一,等.基于Scrapy的分布式爬虫系统的设计与实现[J].湖北民族学院学报:自然科学版,2017,35(3):317-322.
[5] 舒德华.基于Scrapy爬取电商平台数据及自动问答系统的构建[D].武汉:华中师范大学,2016.
[6] 樊宇豪.基于Scrapy的分布式网络爬虫系统设计与实现[D].成都:电子科技大学,2018.
[7] 李代祎,谢丽艳,钱慎一,等.基于Scrapy的分布式爬虫系统的设计与实现[J].湖北民族学院学报(自然科学版),2017,35(3):317-322.
[8] 张靖宇,梁久祯.中文网页分布式并行索引的设计与实现[J].微计算机信息,2010,26(15):127-128,191.
猜你喜欢
房地产导刊(2022年10期)2022-10-18
现代信息科技(2021年21期)2021-05-07
电子制作(2018年10期)2018-08-04
电子测试(2018年1期)2018-04-18
电子制作(2017年2期)2017-05-17
电子制作(2017年9期)2017-04-17
电子测试(2015年18期)2016-01-14
雷达与对抗(2015年3期)2015-12-09
计算机与网络(2014年7期)2014-03-25
自动化博览(2014年12期)2014-02-28
