
基于参数优化的RBF神经网络结构设计算法
2020-02-27 08:46翟莹莹张恩德
东北大学学报(自然科学版) 2020年2期
翟莹莹, 左 丽, 张恩德
(东北大学 计算机科学与工程学院, 辽宁 沈阳 110169)
径向基函数(radial basis function, RBF)神经网络是一种高效的三层前馈式神经网络,其拓扑结构简单,学习速度快,理论上可以任意精度逼近任何单值连续函数[1-2],主要用于非线性系统建模与控制[3-4]、模式识别[5]和时间序列预测[6-7]等方面.由于RBF神经网络基于多变量差值理论,所有的数据均可作为隐含层节点,使得网络的泛化性能低下.因此,RBF神经网络结构设计的核心问题是在保证精度要求的情况下,提高网络的泛化性能[8].
RBF的网络结构优化是一个开放的问题,如何调整RBF网络结构是当前关注的主要问题,仍需要进一步研究.为了提升RBF神经网络的预测性能,很多学者提出了不同的改进方法[9-13].Yang等[10]应用输出敏感度方差重要性的度量方法优化RBF神经网络结构(VS-RBF),采用K-means聚类算法确定网络隐含层的节点中心,采用随机初始化函数的宽度,提高网络的自适应能力.为了提高聚类算法的有效性,本文改进K-means++聚类算法,得到MKM++算法,确定了合适的网络初始中心;考虑数据分布和缩放因子的自适应选择,采用方差度量优化法求取隐含层神经元基函数的宽度.基于上述参数的优化,本文提出一种两阶段学习的RBF神经网络结构优化方法(KV-RBF).通过仿真实验,验证了KV-RBF的准确性和有效性.
1 基于聚类算法的RBF神经网络
RBF神经网络由三层前馈神经网络构成,包括输入层、隐含层和输出层,如图1所示.设RBF网络结构为n-m-p(n为输入层节点数,m为隐含层节点数,p为输出层节点数),输入层向量为x=(x1,x2,…,xn)T,隐含层第j个节点的输出为
(1)
式中:hj(x)为径向基函数;‖·‖为欧式范数;径向基函数的中心向量为φj=(φj1,φj2,…,φjm)T;σj为第j个基函数的扩展宽度.
输出层第k个节点的输出为
(2)
式中:wki为隐含层第i个节点到输出层第k个节点的连接权重,wk0为输出层第k个节点的偏差项.输出层节点k的误差函数为
(3)
式中,yd,k为节点k的期望输出.RBF网络的总误差函数为
(4)
在RBF神经网络结构中,决定网络收敛速度的主要参数是隐含层节点中心和基函数宽度初值,合理选取这两个参数的初值能够提高收敛速度.本文采用聚类算法确定隐含层节点中心和基函数宽度.将得到的聚类中心μj(j=1,2,…,m)作为径向基函数的中心μ,径向基函数的宽度计算公式如下:
(5)
式中:dmax为所有中心的最大距离.
使用最小二乘法求RBF神经网络的权值参数.式(2)可以写成矩阵形式:
Y=Hw.
(6)
w=(w1,w2,…,wm)T.
用H的伪逆H†=(HTH)-1HT求得
w=H†Y.
(7)
该方法中径向基函数的中心和宽度可以在RBF神经网络训练前求出,训练中只需要求出隐含层输出矩阵的伪逆φ†,通过式(7)求出输出层和隐含层的权值.
基于聚类算法的RBF神经网络存在如下问题:算法对聚类初始条件敏感,初始中心选择不恰当会使聚类效果很差;宽度求取过程未考虑数据样本的分布.这种不稳定性是RBF神经网络实际应用中最大的瓶颈,因此,本文提出了基于参数优化的RBF算法,以改进算法的上述缺陷.
2 参数优化的RBF算法
2.1 K-means++算法
K-means++聚类算法是一种非监督学习方法.在样本中选取k个数据点作为初始聚类中心,形成k个分组;重复分配,更新分组,直到聚类中心的变化值在指定误差范围内,其算法步骤如下:
①随机选取整个样本数据集中的k个数作为初始聚类中心;
②计算样本点与聚类中心的欧氏距离,按照最小距离原则分配到最邻近聚类;
③用每个聚类中样本均值作为新聚类中心;
④重复步骤②和③,直到聚类中心变化值小于指定的误差;
⑤结束,得到k个聚类中心.
K-means++选择中心点依赖于前面选取的初始中心点,而随机选取初始中心点导致了算法的不稳定.K-means++并没有克服对离群点的敏感性,离群点的存在仍然使最终聚类中心偏离真正的中心点;算法往往选择离群点和边缘点作为下一个初始中心点,使得聚类性能下降.
2.2 改进的K-means++算法(MKM++)
为了克服K-means++算法的聚类缺陷,引入MMOD(mountain method based outlier detection)算法[14].基于数据密度优化的MMOD算法很好地计算衡量了每个样本的密度,将其引入到K-means++算法中,用密度最大的样本代替K-means++算法随机选择的样本,作为第一个初始中心点,减弱对初始中心点的敏感性,即本文提出的MKM++算法.
MMOD算法采用样本点的数据密度估计方法,区分正常数据点与离群数据点的数据密度,其数据密度计算公式为
(8)
式中:k为近邻点数量;d(p,xi)为数据点p到xi的距离;δk(xi)为数据点xi到其第k个近邻点的欧式距离,是局部尺度化参数;KNN(p)为数据点p的k近邻集合.离群度,即数据点的离群程度,取值区间为0~1.对于聚类内部的点,假设p的k近邻属于同一个类,则δk(xi)>d(p,xi),M(p)的值会比较大;在p的k近邻集合中,数据点越靠近中心,密度越大.
为了保证聚类效果,使用传统欧式距离与数据密度的乘积优化K-means++算法的初始中心点选取策略,在满足初始中心点应当尽可能远的前提下,选择密度大的点作为下一个初始中心点,即基于距离尽可能远、密度尽可能大的原则选择其余的初始中心点.
2.3 RBF径向基函数宽度的选取
基于样本数据的聚类中心μ={μ1,μ2,…,μm},根据每个中心的数据密度分布来分配相应的缩放因子,使得每个中心的宽度体现其数据的空间分布.类簇样本分布不同,相同宽度或者相邻两个中心点的距离无法反映簇内中心点的稠密情况;因此,宽度的选择应该考虑到每个类簇之间的距离和簇内样本的分布密度.
以每个聚类中心和其他聚类中心的距离的平均值作为距离基数:
(9)
方差代表样本分布的稠密程度,将每个聚类看作一个数据集,求得每个聚类的方差Si:
(10)
式中:size(Ci)为属于聚类中心μi的样本数;Ci为子样本;dist(x,μi)为欧式距离.该中心宽度的缩放因子εi:
(11)
根据式(10)和式(11),得到每个中心宽度:
σi=εi·meanD(μi) .
(12)
当类内分布稠密(类内方差Si比较小)时,缩放因子也会变小,宽度也会减小;同理,当类内数据分布比较稀疏(类内方差Si比较大)时,缩放因子则会变大,宽度就会适当扩大,此时,RBF神经网络的选择性则会减小.
2.4 基于参数优化的RBF算法
根据上述分析得到基于参数优化的RBF神经网络结构算法KV-RBF:首先,由MKM++求取RBF神经网络隐节点的中心;然后,采用基于方差的宽度求取算法求得RBF每个核函数的宽度;最后,采用最小二乘法求隐含层和输出层的权重.算法实现步骤如下:
①采用MKM++算法求得RBF神经网络隐节点的k个聚类中心;
②使用式(9)计算每个聚类中心和其他聚类中心的距离的平均值;
③使用式(10)计算每个聚类的类内方差Si;
④使用式(11)计算缩放因子εi;
⑤使用式(12)求得该核函数的宽度σi,求出RBF神经网络对应中心的宽度;
⑥基于中心Ci和宽度σi,应用最小二乘法求得隐含层与输出层的权值参数,训练模型.
3 仿真实验
3.1 MKM++算法实验
在聚类算法对比实验中,用平方误差来度量不同算法的聚类效果.其计算公式为
(13)
式中:E是数据集中所有对象的误差平方和;p是空间中的点,表示给定的数据对象;μi是聚类中心.
选取UCI开源的数据集,该数据集是5 000个矢量合成的二维数据,由15个重叠程度不相同的高斯集群组成.进行10次模拟实验,得到两个算法的平方误差如图2所示.
由图2可知,K-means++平方误差值大多为1013数量级,而MKM++大多数为1012数量级.经过多次实验图像分析可以得出以下经验:误差值为1012数量级的都能正确找到聚类中心,而误差为1013数量级时,出现1个中心的聚类错误.MKM++在稳定性和准确率上均比K-means++有一定的提升.
本文采用如下指标评定聚类效果:
①JC系数(Jaccard coefficient):
(14)
②FMI指数(Fowlkes and Mallows index):
(15)
③RI指数(Rand index):
(16)
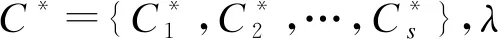
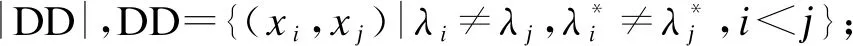
a+b+c+d=m(m-1)/2.
上述指标度量结果均在[0,1]内,值越大,聚类越好.
对开源数据集中的5个数据集Iris,seeds,Pima Indians(P-I),wine,new-thyroid(n-th)进行30次模拟实验,使用上述指标进行K-means++(K-M)和MKM++算法性能对比,实验结果如表1所示.
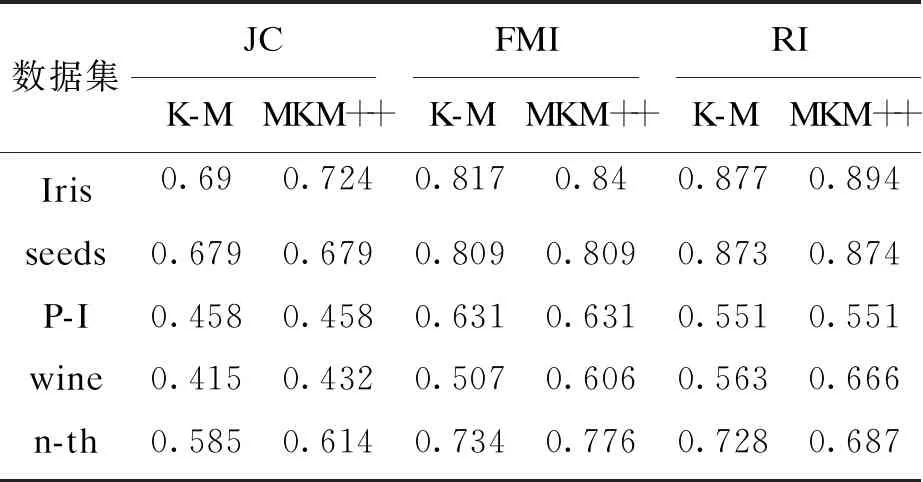
表1 聚类评价指标对比Table 1 Comparison of clustering evaluation indexes
由表1可知,在Iris数据集中指标提升比较明显;而在seeds数据集中JC系数和FMI指数提升较少,但RI指数还是略有提升.P-I数据集的指标没有变化,但n-th数据集3个指标提升明显.因此,MKM++优于K-means++算法.
3.2 基于参数优化的RBF对比实验
选取一维非线性函数:
y=1+(x+5x2)sin(-2x2),x∈[-4,4] ,
(17)
随机产生201个数据(取值区间为[-4,4])的样本.分别用传统RBF,VS-RBF[10]和本文的KV-RBF算法对上述离散样本进行模拟,实验结果如图3所示.
由图3可知,KV-RBF算法优于RBF及VS-RBF算法;RBF和VS-RBF算法在中心点个数不足时很难达到理想的拟合效果,为了规避聚类带来的不稳定性,对比不同算法的均方误差,如图4所示.
KV-RBF算法的均方误差小于RBF和VS-RBF算法,应用改进的K-means++方法后,能够提高模型的稳定性.
为了分析KV-RBF算法的有效性,选取二维三角函数:
y=cos(2πk1x1+2πk2x2)sin(2πk2x2) .
(18)
式中:y为期望输出;k1=0.05,k2=0.02;输出样本满足0 由图6可知,KV-RBF算法对函数的拟合误差在0.03范围内,误差曲面比较平坦,具有很强的泛化性能. 图7为基于KV-RBF算法的网络隐含层节点数量的动态变化.可以看出,随着训练时间的增加,隐含层神经元个数也在逐渐增加,该网络能够很好地自适应调整结构. 对UCI开源数据集中的Boston housing,CCPP,Pollutant concentration进行实验分析.随机抽取每个数据集的3/4作为训练样本,剩下1/4样本用于测试.分别采用传统RBF算法和KV-RBF算法进行对比,为了避免聚类的随机性,隐含层中心的数量从20到80递增,得到的不同数据集的均方误差变化如图8所示. 由图8可知,RBF神经网络的均方误差随着核函数聚类中心数量的增加而递减,符合RBF神经网络的原理.KV-RBF算法的均方误差要小于传统RBF算法.在Boston housing数据集中,KV-RBF算法优于传统RBF算法,只有个别情况出现了均方误差比传统RBF算法大的现象;而对于CCPP数据集,KV-RBF算法的精度明显提高,误差降低了1左右.由于Pollutant concentration数据集中的数据有较强的离散性,而CCPP数据集中的数据具有连续性,且RBF核函数是基于欧式 距离的,处理离散性数据时均方误差会随着数据的波动而波动;因此,Pollutant concentration的均方误差抖动比较明显,而CCPP基本上很稳定.由前述可知,基于参数优化的KV-RBF算法提升了网络的预测性能. 1) 基于KV-RBF算法的神经网络找到的聚类中心更稳定,并根据不同的数据集自适应调整隐含层的节点数. 2) 参数优化后的RBF网络具有较好的非线性逼近能力和收敛速度;本文提出的基于KV-RBF算法的神经网络表现出较好的训练结果和测试结果,说明其具有较好的泛化性能.4 结 论
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
计算机应用与软件(2021年7期)2021-07-16
中国传媒大学学报(自然科学版)(2021年5期)2021-02-24
计算机技术与发展(2020年8期)2020-08-12
电脑报(2020年12期)2020-06-30
电脑报(2019年4期)2019-09-10
互联网天地(2016年1期)2016-05-04
大众摄影(2015年9期)2015-09-06
人生十六七(2015年5期)2015-02-28
销售与市场·管理版(2009年21期)2009-09-03
