
基于决策树的堆芯物理参数预测研究
2020-02-25 05:48:24周剑东谢金森曾文杰陈珍平赵鹏程刘紫静
原子能科学技术 2020年2期
周剑东,谢金森,*,曾文杰,于 涛,陈珍平,赵鹏程,谢 芹,刘紫静,谢 超
(1.南华大学 核科学技术学院,湖南 衡阳 421001;2.湖南省数字化反应堆工程技术研究中心,湖南 衡阳 421001)
随着反应堆中子输运和扩散方程计算方法的改进,以及计算机性能的提升,反应堆核设计方法也在不断发展,以达到更高的设计精度要求[1],如直接基于栅元尺度进行堆芯一步法输运计算。然而,在现有的大型计算机水平下,由于计算耗费仍较大,目前工程领域核设计采用的仍是基于组件均匀化计算与堆芯扩散计算的两步法。从计算时间的角度看,依据现有的计算方法及硬件条件,单个组件的一次输运计算所需的时间已可控制在s到min量级[2]。但在面对堆芯优化设计问题时,随着组件设计变量及目标函数数量的增加,及进一步的输运-燃耗计算等问题相互耦合,问题的难度也会呈指数增长,堆芯方案搜索的规模将达到成千上万,堆芯优化设计过程所需的计算时间也会急速增加。Cadenas等[3]使用CASMO-4/SIMULATE-3评估单个设计组件是否满足运行要求需要5~6 h;而使用DRAGON-4/DONJON-4[4-5]程序对1个组件-堆芯方案的计算时间约6.53 h;若上述计算采用蒙特卡罗程序,计算时间则更长。因此,在工程实际堆芯设计中,更多的是凭借设计人员的经验与物理理论,先预设少量方案再进行逐个计算及人工筛选。
本文提出利用数据挖掘技术,通过组件自变量快速预测堆芯的物理参数,实现方案的快速筛选,提高堆芯设计效率。数据挖掘技术首先对不同算法的训练集训练效果进行评估,挑选合适的数据挖掘算法,再基于C4.5模型对自变量与堆芯参数做关联分析,最后利用不同算法建立的模型对测试集进行快速预测堆芯参数并评价其精度。
1 数据挖掘算法
数据挖掘[5]是在海量数据中发现知识、规律、新模式、新关系的过程,这个过程可是全自动的,也可是半自动的。简而言之,数据挖掘就是从大量数据中提取或“挖掘”知识[6]。它的基本任务[7]包括:分类与预测、聚类分析、关联规则、时序模式、偏差检测、智能推荐等。它的目标[7]包括:基于其他属性的值来预测特定属性的值、对数据中潜在联系的模式进行概括与导出。决策树是机器学习中的1个树状预测模型,对训练样本数据集进行挖掘后会产生1棵如二叉树或多叉树的结构,其内部节点表示在1个属性上的测试,而叶子节点代表最终的类别结果[8]。在解决分类问题方面,除了决策树算法以外还有贝叶斯分类(BC)、人工神经网络算法(ANN)、K近邻算法(K-NN)、支持向量机算法(SVM)等[9]可应用于该领域。决策树算法相较于ANN和SVM在实现方式上更简单,模型更直观,速度更快;相较于K-NN,决策树算法能解决多元分类问题[9]。
本文使用的算法有C4.5、RepTree、Random Forest、Random Tree。以上4种算法都是基于构建决策树来对数据进行分类分析,各算法处理数据的类型、建模机制的选取、决策树构建方法、分类规则表达方式[10]等方面的不同导致各有优缺点,表1列出本文所使用4类算法的特点。

表1 算法特点Table 1 Algorithm feature
2 数据样本构建
2.1 自变量选取
影响反应堆核设计参数的因素主要有燃料富集度、可燃毒物、燃料组件排布等。随着燃料富集度的提升,初始反应性越大,对于反应性的控制越会带来巨大的困难,并且在寿期末会出现燃耗亏损[11],即当燃料富集度大于某个值时,寿期末燃耗不会继续呈线性增加,而会小于该结果;可燃毒物在展平堆芯功率的同时,也可能导致寿期亏损即反应性惩罚,其中包括毒物基体中硼与钆等核素及子代同位素的残留吸收、包壳等结构物的吸收以及毒物棒的挤水效应[12]。因此本文选取燃料富集度、可燃毒物的类型与含量这3类设计变量作为自变量。参考现有的压水堆燃料组件设计区间[13],本文选取了富集度在1.8%~5.0%区间的5种不同燃料开展研究,可燃毒物采用Gd2O3+UO2,Gd2O3的质量分数为9%与12%,单一组件内含可燃毒物的燃料棒为0、4、8、12根,如表2所列,可组合35种不同的燃料组件。
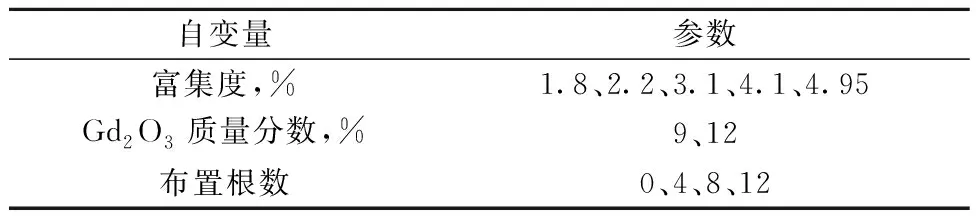
表2 燃料组件自变量Table 2 Independent variable of fuel assembly
本文以国内某核电厂首炉堆芯装料布置为参考,针对表2所列燃料组件进行计算。堆芯燃料分3区布置,分别用A、B、C表示,具体布置如图1所示。依据以上自变量,可生成的堆芯方案数量为353=42 875。为降低样本量,减少不必要的计算及节约时间成本,根据该核电厂首炉堆芯方案,约束A区的燃料富集度最小,C区燃料富集度最大,B区燃料富集度介于A、C区之间,由此可将组件按富集度分为10种不同的情况,而每种富集度的Gd含量及布置有7种。在上述约束下,堆芯方案数量降至73×10=3 430。

图1 1/4堆芯布置Fig.1 Quarter core layout
2.2 目标函数选取
通过DRAGON/DONJON[4-5]程序系统做两步法组件-堆芯输运燃耗计算所得参数作为数据挖掘所需的数据集。参考核电厂首炉堆芯核设计报告,选取keff在寿期内的不均匀系数偏差(KUCD)、寿期内的径向功率不均匀系数偏差(RPNCD)、寿期内的径向中子通量不均匀系数偏差(RFNCD)、堆芯寿期(CL)作为目标函数,用于快速评估燃料组件设计方案。其中,KUCD用以表征堆芯在寿期内反应性波动偏离范围,RPNCD和RFNCD表征堆芯功率与中子通量的不均匀性。假定以上4个目标函数需满足以下限制条件:
1) KUCD
(1)
其中:keff,max、keff,av分别为寿期内keff的最大值与平均值;下标target为设计目标值。
2) RPNCD
(2)
其中,Pmax、Pav分别为寿期内功率密度的最大值与平均值。
3) RFNCD
(3)
其中,φmax、φav分别为寿期内中子通量的最大值与平均值。
4) CL
CL≥CLtarget
(4)
其中,CL为以等效满功率天(EFPD)为单位的堆芯循环长度。
以等权重的方式整合以上4类目标函数并用目标函数符合度[14](CPF)来统一表示,因此CPF的可能取值为0~4。若CPF=4,则代表该堆芯方案满足所有的核设计要求,即可认定此类燃料组件在堆芯排布方案中是“好的”;若CPF<4则可认为方案为“坏的”。
3 结果分析
3.1 算法分析
将所有案例随机分为两部分,即训练集和测试集,每组1 715个案例。通过C4.5、RepTree、Random Tree及Random Forest算法对训练集进行分类回归分析,并在训练过程中随机挑选该数据集中10个案例做交叉验证[15],并评估其预测精度。
通过对训练集构建训练模型,C4.5生成叶子节点数102个,RepTree生成的叶子节点数为133个,Random Forest则生成了100棵决策树,Random Tree生成的叶子节点数为949个。结果表明C4.5算法对整体预测精度最高,Random Tree最低,而对构建模型历时最短的是Random Tree,耗时最长的是Random Forest,将各算法对CPF各值的预测精度的平均值作为该算法的整体精度,其结果列于表3。基于数据挖掘构建混淆矩阵(图2),矩阵每列代表CPF的预测值,每行则代表CPF的实际值,由此可知,对角线的值越大即算法构建模型越精确。由图2可知,C4.5对训练集的预测精度要优于其他算法的。

表3 各算法的预测精度Table 3 Prediction accuracy of each algorithm
鉴于对CPF的定义,CPF=4为筛选的临界点,即筛选出所有满足设计要求的堆芯方案,各算法的预测精度列于表4。TP Rate为真正率,即被模型预测为CPF=4的样本比率,TP Rate=CPF为4预测结果数除以CPF实际为4的结果数。同理,FP Rate为假正率,即模型预测不为4的样本比率,FP Rate=被预测不为4的样本数除以实际不为4的样本数。Precision即精确度,代表着被模型正确预测的样本数与所有被预测为4的样本数的比率。由表4可知,Random Forest的预测精度最高,其次是C4.5。

a——C4.5;b——RepTree;c——Random Forest;d——Random Tree图2 各算法的混淆矩阵Fig.2 Confusion matrix of each algorithm
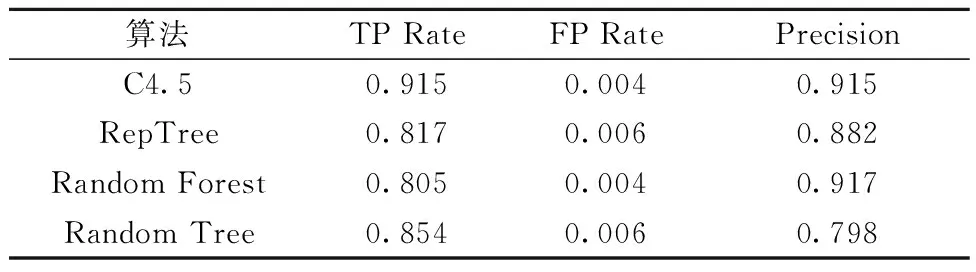
表4 各算法对CPF=4的预测精度Table 4 Prediction accuracy of each algorithm for CPF=4
3.2 关联分析
鉴于3.1节分析可知,C4.5对整体CPF的值预测精度最高,因此,本节采用C4.5算法对各个自变量做关联分析。通过对数据进行格式转换、数据清洗等预处理操作,调整自变量即选取不同的特征量以得出CPF的预测精度来关联分析,具体精度列于表5。
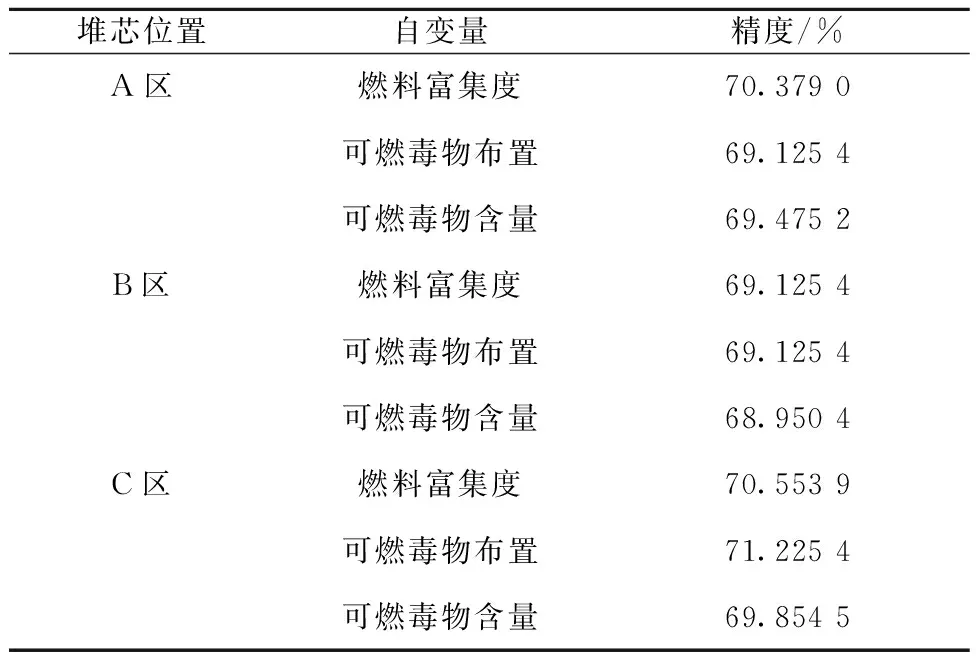
表5 各自变量对CPF预测精度Table 5 Accuracy of CPF prediction for each independent variable
由表5可知,对于A区,燃料富集度对CPF的值影响最大,可燃毒物布置对CPF值的影响较小,又因在设计时A区燃料富集度相较于B区、C区燃料的会更低,相较于可燃毒物布置及含量,A区燃料富集度对堆芯通量、功率的影响更大。以此类推,B区由于富集度的增加,该区组件对堆芯的整体影响则来源于该区组件燃料富集度以及可燃毒物的布置方式。随着富集度的继续增加,C区组件可燃毒物布置对堆芯的CPF值的影响相较于其余两个自变量更大,富集度越高,就越依赖于可燃毒物的布置来展平堆芯的通量及功率分布。整体上,C区燃料组件的重要性要高于A区和B区的,即C区对于堆芯整体的不均匀性贡献更大。
3.3 预测分析
提取测试集中的1 715个案例,将这1 715个案例放入4种算法基于训练集生成的模型进行快速计算并比较。CPF=4时预测案例数与预测案例数中实际案例数比较列于表6,表7列出CPF=4的预测完备性。由表6与表7可知,4个算法在对测试集1 715个案例的筛选与预测均在0.9 s以内完成;并在1 715个案例中,实际CPF=4的总案例数为51个,基于C4.5与Random Forest算法的预测完备性最高,均达到了0.98,但在这两个算法中,Random Forest预测精度高于C4.5,而Random Forest所需时间大于C4.5。

表6 预测案例数与预测案例数中实际案例数比较Table 6 Number of actual case in number of predicted case and number of predicted case

表7 预测完备性Table 7 Predictive completeness
4 结语
堆芯燃料组件排布方案与燃料组件的选择是反应堆核设计的重要内容,在一定的堆芯排布方案约束假设下,针对大量可能的燃料组件设计进行筛选是一项复杂、耗时的工作。利用大量已有的堆芯设计方案数据,通过数据挖掘技术,可实现对新燃料组件在堆芯的物理性能及对堆芯核设计参数影响的快速评价,这对于堆芯、燃料组件方案搜索与优化具有很强的实际意义。
本文以某核电厂首炉堆芯方案为参考,以燃料富集度、可燃毒物布置、可燃毒物含量3个为自变量,应用C4.5、RepTree、Random Forest及Random Tree算法,运用数据挖掘技术构建的模型对测试集燃料组件方案进行快速预测,所需时间均在0.9 s以内,且C4.5对训练集的预测精度最高。随后C4.5对自变量与目标函数进行关联分析,得出A区的燃料富集度与C区的燃料富集度和可燃毒物布置相较于其他自变量对结果影响更大。Random Forest与C4.5对满足堆芯要求的预测完备性较高,而Random Forest的预测精度最高。尽管Random Forest预测时间相较于其他3种算法较长,但是该算法的预测所耗时间可接受。以上工作对反应堆堆芯参数的快速计算提供新的可能,可大幅提升方案搜索的效率。同时,数据挖掘的技术可充分利用现有反应堆核设计的数据资源,实现核能领域大数据的应用。
猜你喜欢
大众投资指南(2021年35期)2021-02-16 01:06:26
小哥白尼(趣味科学)(2020年7期)2020-05-22 06:48:38
中学生数理化·八年级物理人教版(2019年5期)2019-06-25 00:59:00
辐射防护通讯(2019年3期)2019-04-26 05:16:12
电力与能源(2017年6期)2017-05-14 06:19:37
核技术(2016年4期)2016-08-22 09:05:32
当代化工研究(2016年2期)2016-03-20 16:21:23
信息通信技术(2015年6期)2015-12-26 01:16:46
核科学与工程(2015年3期)2015-09-26 11:58:19
自动化博览(2014年10期)2014-02-28 22:33:53
