
基于多线程爬虫和OpenCV的人脸数据集制作方法
2020-02-22 03:09张值铭杨德刚
现代信息科技 2020年18期
张值铭 杨德刚


摘 要:深度学习的训练往往需要用到大量数据,但目前主要是以部分著名开源的数据集为主。其中开源的人脸数据集大多是基于西方人种,缺乏多样性。针对以上问题,提出一种人脸数据集制作方法,用于后续训练和研究。文章让计算机承担大部分工作,可以极大减轻人工收集制作以及筛选中耗费的时间精力,准确率高、不规范图片少,是一种可行的人脸数据集收集制作方法。
关键词:爬虫;OpenCV库;数据集;人脸;dlib库
中图分类号:TP391 文献标识码:A 文章编号:2096-4706(2020)18-0098-06
Abstract:Deep learning training often needs to use a lot of data,but at present it is mainly based on some famous open source data sets. Most of the open source face data sets are based on the Western race,and lack of diversity. In view of the above problems,a method of making face data set is proposed for subsequent training and research. In this paper,let the computer undertake most of the work,which can greatly reduce the time and energy consumed in the manual collection and production and screening,with high accuracy and less nonstandard images. It is a feasible method of face data collection and production.
Keywords:crawler;OpenCV library;datasets;face;dlib library
0 引 言
人脸数据集是一种通过仅对人物图像的面部区域进行切割形成的数据集,被广泛用于人脸识别[1],人脸生成对抗[2]等神经网络模型的训练,目前著名人脸数据集往往基于西方人种,如CelebA[3]人脸数据集等,缺乏对亚裔人种的支持,而两者人脸特征存在较大差异,不利于在亚裔人群的使用场景中对模型进行优化,因此需要进行针对性的亚裔人脸数据集制作。作者通过在学校的服务器上制作亚裔人脸数据集为后续的人脸打卡系统,宿舍人脸门禁系统等实验的研究提供基础训练数据。
传统采集数据集的方式主要为人工进行拍摄后再进行后期加工,费时费力,且数据集的容量往往不足以用于深度学习训练,因此急需一种在低人工成本的前提下,可以大量采集并且可以精确定位并裁剪人脸部分的人脸数据集收集和制作方法。
1 相关技术介绍
1.1 爬虫模块
爬虫[4]是一种按照一定目的在互联网上自动获取对应信息或资源的技术。爬虫往往伪装成正常的浏览器,并通过向目标网站发起请求,获取对应资源或信息后进行有目的的存储或分析,如搜索引擎,通过向互联网进行信息抓取提取和存储,为用户进行搜索提供便利。
本文使用的是基于Python语言的爬虫技术,Python是一种提供各类第三方工具包的高级脚本语言,其中本文用于爬虫的工具包有Requests,Beautiful Soup。Requests[5]是一种著名的开源Python HTTP第三方库,该库的优势在于遵循PEP 20开发准则,API具有较高的可读性,优雅简洁等特点,比Python自带的urllib和urllib2更灵活,使得开发人员更容易使用,Requests库可以实现对服务器发出get或者post请求以及接收响应,该库还可以通过传递请求头参数模拟浏览器,使用代理等方式來规避反爬虫策略,本文选用Requests并使用并发的方式进行爬取,可以有效地实现目的。Beautiful Soup 5[6]是一种网页解析库,该库主要用于分析网页信息,支持多种格式,如HTML,XML等,该库可以方便地将获取的网页结构化,并提供了一系列方法方便开发者方便的定位和获取目标内容。
1.2 OpenCV模块
OpenCV[7]是一种跨平台的开源的计算机视觉和图像处理库,该库由C++语言编写而成,同时提供了多种语言接口,本文使用其Python接口。该库应用领域广泛,如边缘检测,三维重建,图像分割等。其中CascadeClassifier是OpenCV中用于目标检测的级联分类器,该分类器通过使用局部二值特征(Local Binary Pattern,LBP)导入特定的分类器文件,如人脸分类器haarcascade_frontalface_alt.xml,可以实现对人脸的检测。如图1所示,其中矩形框部分为使用此分类器后标注的人脸位置。
1.3 dlib模块
dlib[8]是一种包含多种机器学习算法以及工具的开源库,该库基于C++语言编写,同样支持Python接口,该库在学术以及工业领域有着广泛的应用。该库包含如深度学习算法,多分类支持向量机[9],以及多种聚类算法等,也包含一些图像处理工具,比如常见的图像操作工具边缘查找,形态学工具等,甚至还包括一些网络方面的工具,如简单的HTTP服务器对象,以及TCP Socket API等。其中get_frontal_face_detector为dlib的人脸检测器函数,若输入图片不包含人脸则该函数返回为空。本文使用此函数进行对人脸的筛选。
2 项目分析与设计
2.1 项目分析
本项目需要实现对人物图片网站的爬取,存储到硬盘中,然后将人脸部分切割出来并保存,实现人脸数据集的制作。在此过程中最重要的目的是在保证质量和速度的前提下降低人工复检的难度,也就是使用程序处理的结果只能包含极少量的非人臉图片,因此本文必须设计筛选模块。
2.1.1 爬虫过程分析
项目首先需要实现对人物图像网站的爬取,对不同类型人群的人脸数据集制作则需要找到对应目标网站,目的在于将该网站上所有亚裔人物图像保存到硬盘中,用于后续的处理,同时由于单线程会在数据写入,数据分析,等待服务器响应等过程耗费较多时间,无法充分利用带宽,因此本文将使用多线程的方式进行爬取,爬取的速度主要取决于带宽上限。
本文以wallhavean为例,首先进行网页分析,打开wallhaven主页:https://wallhaven.cc/,搜索asian people,会跳到亚洲人物图片网页:https://wallhaven.cc/search?q=id%3A449&categories=001&purity=100&sorting=relevance&order=desc&page=2,如图2所示。
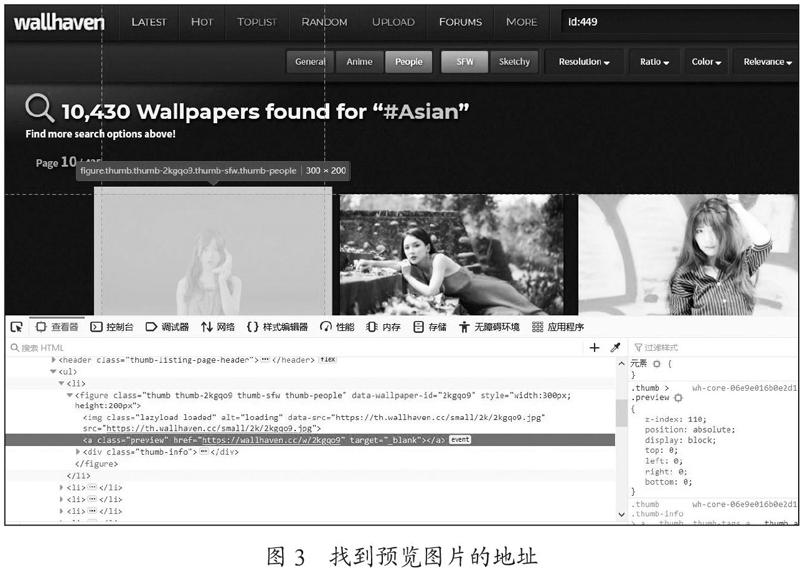
通过测试,发现其中网址中的page是对应网页编号,使用for循环即可遍历该网站所有页面,使用火狐浏览器F12开发者工具,可以定位到每个页面中图片的href属性值,如图3所示。
其网页DOM中a标签的href属性值为该图片预览图地址,打开该网址,可以发现跳转到了一个新的页面,如图4所示。
对该页面中出现的大图进行定位,发现该图的src地址为:https://w.wallhaven.cc/full/qd/wallhaven-qdr6w5.jpg,通过访问此地址,确认为最终的图片地址,只要对该地址进行请求即可完成目标图片的下载,图5为最终的高清大图。
2.1.2 人脸处理过程分析
对爬虫保存的所有人物图片进行处理,使用OpenCV的级联分类器,对保存下来的人物图片进行面部识别,并将面部进行切割保存,同时由于仅使用OpenCV在进行人脸识别时的准确率不够高,在原始图像足够多的情况下将产生大量不包含人脸部分的图片,因此使用dlib模块进行筛选,去掉不合格的部分。
2.2 项目设计
项目设计包含四个方面,第一是使用爬虫进行图像收集,第二个是人脸识别模块,使用OpenCV模块实现对人脸的裁剪,第三个是筛选模块,使用dlib模块对裁剪的图像进行筛选,去除不合格图片,最后是人工复检。具体流程如图6所示。
2.3 项目部分代码
2.3.1 爬虫部分代码
作者通过在学校实验室服务器上运行home/lab/cqnu/face/spyder.py脚本,实现对目标网站的请求与网页分析,获取目标图片的完整url地址,并以多线程的方式实现对图片的爬取,其中部分代码为:
#此函数实现对wallheaven页面的请求,通过伪装成浏览器获取页面信息
def request_url(page):
url='https://wallhaven.cc/search?q=id%3A449&categories=001&purity=100&sorting=relevance&order=desc&page={}'.format(str(page))
#此处传递不同的page参数可以实现请求不同的网页
headers = {'User-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36','Referer':url,'Host':'wallhaven.cc'}
#请求头参数,包含浏览器伪装,Referer,以及Host,其中User-Agent用于伪装成Windows系统下的谷歌浏览器,为常见的反爬虫策略
time.sleep(random.randint(1,10))#此项为程序随机休眠,为防止同一时间大量的请求被服务器认为是爬虫
r=requests.get(url,headers=headers)#向服务器发出请求
if not r.status_code==200:#此处为判断返回状态码,状态为200代表正常,非200则结束函数
print(url,'status code error ',r.status_code)
return
r.encoding='gb2312'
r_text=r.text
r.close()#结束时关闭连接
return r_text#返回网页数据
#此部分函数实现对页面的分析,定位并找到高清图片的url地址
def soup(r_text):
if not r_text:
print('soup is None')
return
#此处为判断网页数据是否为空,如果为空,则结束函数
soup=BeautifulSoup(r_text,'html.parser')#使用beautiful soup进行网页数据分析
a_list=soup.find_all('a',class_='preview')#定位该网页中缩略图的位置
md5_text_list=[]#此数组为存储缩略图url中的特征字段
md5_text=a['href'].split('/')[-1]
fullPic_url_list=[]
for a in a_list:
md5_text=a['href'].split('/')[-1]#此項为特征字段,如eodqxl,为后续构成完整高清图像url的关键
md5_text_list.append(md5_text)
#print(md5_text)
fullPic_url='https://w.wallhaven.cc/full/{}/wallhaven-{}.jpg'.format(md5_text[:2],md5_text)
#print(fullPic_url)#打印完整高清图像url,其中第一个大括号为特征字段的前两个字符,如eodqxl的前两个字符为eo
#https://w.wallhaven.cc/full/qd/wallhaven-qdr6w5.jpg
fullPic_url_list.append(fullPic_url)
#print(fullPic_url_list)#打印该页所有图像的完整url地址
#返回特征字段,作为后续保存文件的文件名,返回完整图像的url地址
return md5_text_list,fullPic_url_list
#此函数用于下载图像并保存到硬盘中
def download(file_name,fullPic_url):
#保存图片的文件夹绝对路径,若不存在则创建该文件夹
root_dir=os.path.join('home/lab/cqnu/face/data/pic')
if not os.path.exists(root_dir):
os.makedirs(root_dir)
#此项为判断文件是否存在,若存在则无需进行下面服务器请求等步骤,直接停止
file_path=os.path.join(root_dir,file_name+'.jpg')
if os.path.exists(file_path):
print('{} 已存在'.format(file_path))
return
headers={'User-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36','Host':'w.wallhaven.cc'}
r=requests.get(fullPic_url,stream=True,headers=headers)#向服务器发出请求
time.sleep(random.randint(1,10))#随机休眠
if not r.status_code==200:
print('{} is wrong!status code error {}'.format(fullPic_url,r.status_code))
return 1
#返回状态码非200则停止函数
with open(file_path,'wb') as f:
print('正在写入 :{}'.format(file_path))
for chunk in r.iter_content(chunk_size=8192):
#使用流式的方式进行下载时,将最大的字节流设置成8192,可以实现一边下载一边存储
if chunk:
f.write(chunk)
f.flush()
r.close()#关闭连接
#此函数为封装以上过程,方便后续使用多线程
def run_download(page):
r_text=request_url(page)
md5_text_list,fullPic_url_list=soup(r_text)
if not fullPic_url_list:
return
for md5_text,fullPic_url in zip(md5_text_list,fullPic_url_list):
download(md5_text,fullPic_url)
print('page %s download over'%str(page))#当每页下载完成后,打印此信息
if __name__=='__main__':
for page in range(1,435):
p=Thread(target=run_download,args=(page,))#此处为使用多线程的方式进行爬取,传入page参数即可
p.start()
2.3.2 人脸分割部分代码
编辑/home/lab/cqnu/face/detect.py脚本实现人脸检测与分割,并将分割后的人脸进行保存,其中部分代码为:
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')#加载默认人脸检测分类器
img = cv2.imread(src_img_path)#读取图片
faces = face_cascade.detectMultiScale(img,1.3,5)#获取人脸坐标位置
for (x,y,w,h) in faces:#脸部的坐标数据,包括x,y坐标以及宽高
face_result = img[y:y+h, x:x+w]#根据坐标获取人脸所在的矩形框内的像素数据
cv2.imwrite('face.jpg',face_result)#保存人脸图片
2.3.3 检测部分代码
编辑/home/lab/cqnu/face/check.py脚本实现对人脸图片的检测,并将所有不合格的图片移除。其中部分代码为:
def detect_face(img_path,detector):
img=cv2.imread(img_path)
detector = dlib.get_frontal_face_detector()#加载dlib人脸检测方法
if detector(img,0):
#此处返回一个信号
#如果检测到图片包含人脸,则返回1,不处理
return 1
else:
#否则,返回0,进行剪切操作。
return 0
def copy_remove(signal,img_path,img_name):
#此函数接收一个信号,然后进行保存或剪切操作
trash_dir='home/lab/cqnu/face/data/trash'#非人脸部分的文件夹
if not signal:
#如果是丢弃信号,则将当前图片剪切到新文件夹
dst_path=os.path.join(trash_dir,img_name)
shutil.move(img_path,dst_path)
print('{} 未检测到人脸,已剪切。'.format(img_name))#打印剪切掉的文件名
3 实验对比
如表1所示,本文在依次使用OpenCV分割和dlib筛选后,进行人工统计,人脸总数占当前总样本数的比例。
其中在仅使用OpenCV后,发现有大量非人脸部分图片,如图7所示,随后再使用dlib进行筛选,虽然筛选的同时对部分人脸图片误删除,图8为丢弃的图片,但最后剩下的人脸图片中,仅含有极少量的不合格图片,极大减轻了人工筛选的工作量,图9为最终结果,证明了本文方法可行。
4 结 论
本文基于多线程爬虫对某女性人物图片网站进行了数据收集,并对人脸部分进行了切割和筛选,最终实现了人脸数据集的制作,证明了本文的可行性。在对其他人脸数据集的制作中,唯一有区别的就是爬虫部分,需要对特定网站进行有针对性的爬虫代码编写。同时由于不同图片的大小不一,所切割的脸部大小也可能不一样,后续可以自行使用缩放算法统一人脸图片尺寸。本文的不足之处在于使用dlib进行筛选时误删了部分人脸图像,如果在总体样本较少的情况下可能会使得最终的数据集图片数量偏少,这个过程的优化有待日后做进一步研究。
参考文献:
[1] 王硕.基于神经网络的人脸识别研究 [C]//第三十四届中国(天津)2020IT、网络、信息技术、电子、仪器仪表创新学术会议论文集.天津:天津市电子学会,2020:270-272.
[2] 仝宗和,刘钊.基于深度生成对抗网络的模糊人脸增强 [J].计算机应用与软件,2020,37(9):146-151+193.
[3] 李欣,张童,厚佳琪,等.基于深度学习的多角度人脸检测方法研究 [J].计算机技术与发展,2020,30(9):12-17.
[4] 罗安然,林杉杉.基于Python的网页数据爬虫设计与数据整理 [J].电子测试,2020(19):94-95+31.
[5] 荀雪莲,姚文彬.大数据网络爬虫技术在智慧图书馆信息资源建设上的应用 [J].北华航天工业学院学报,2020,30(4):20-22.
[6] 沈承放,莫达隆.beautiful soup库在网络爬虫中的使用技巧及应用 [J].电脑知识与技术,2019,15(28):13-16.
[7] 廖周宇,王钰婷,陈科良.基于OpenCV的人脸识别算法 [J].电子技术与软件工程,2020(9):133-136.
[8] 王晓红,韩娇,李珊珊.基于人脸检测器的实时视频人脸检测与跟踪 [J].信息通信,2019(2):56-57.
[9] TAHA A,DARWISH A,HASSANIEN A E,et al. Arabian horse identification based on whale optimised multi-class support vector machine [J].International Journal of Computer Applications in Technology,2020,63(1-2):83-92.
作者簡介:张值铭(1994—),男,汉族,重庆人,硕士研究生,研究方向:机器学习、图像处理;杨德刚(1976—),男,汉族,四川内江人,教授,博士,研究方向:神经网络、图像处理。
猜你喜欢
奥秘(2021年5期)2021-06-15
现代信息科技(2021年21期)2021-05-07
计算机与网络(2020年11期)2020-07-29
中国新闻周刊(2019年38期)2019-10-28
文萃报·周五版(2019年41期)2019-09-10
智能计算机与应用(2018年5期)2018-10-20
电脑知识与技术·经验技巧(2018年1期)2018-05-30
小雪花·初中高分作文(2017年9期)2018-05-21
软件和集成电路(2016年12期)2017-02-27
米娜·女性大世界(2016年8期)2016-08-17
