
大数据背景下微博舆情文本关联度分析与设计
2020-02-22 01:28程子文曾豪姜斌陈国俊王莺
现代信息科技 2020年18期
程子文 曾豪 姜斌 陈国俊 王莺
摘 要:为了深入分析大数据背景下微博舆情文本关联度,探索和分析用户微博发帖时话题及其情感态度,有效提高应对突发网络事件的处理效率并显著减少调查的时间。首先采用词频分析的方法实现对微博发帖用户评论内容的整体认识;然后利用朴素贝叶斯算法对评论文本信息的特征结构、语义内容进行自动分析,进而通过云端情感词典进行筛选遍历比对计算权重;最后对帖子文本进行情感倾向分析,得到微博文本情感倾向的分析情况。
关键词:大数据;微博舆情;情感分析;文本关联度;Java
中图分类号:TP391.1 文献标识码:A 文章编号:2096-4706(2020)18-0115-04
Abstract:In order to deeply analyze the relevance of microblog public opinion text under the background of big data,explore and analyze the topic and emotional attitude of users when posting on microblog,effectively improve the processing efficiency of dealing with network incidents and significantly reduce the investigation time. Firstly,the word frequency analysis method is used to realize the overall understanding of the users comments on microblog posts;then use the Naive Bayes algorithm to automatically analyze the feature structure and semantic content of the review text information,and then use the cloud sentiment dictionary to filter and traverse to calculate the weight. Finally,analyze the sentiment tendency of the post text to get the analysis of the sentiment tendency of the microblog text.
Keywords:big data;microblog public opinion;sentiment analysis;text relevance;Java
0 引 言
二十一世纪是大数据的时代,对大数据的理解在于对数据的发现以及理解信息与信息之间的关系。近年来,互联网中社交媒体信息量迅速增长,人们以往参与社会事件的形式已经从走访申诉向着网络发表言论转变[1]。面对快速增长的微博信息量,如何及时、全面、精准地分析微博舆论的热点话题,如何利用好这些网络事件文本数据,是微博舆情分析过程中所需要解决的首要问题[2]。
本课题来源于无锡太湖学院江苏省物联网重点实验室相关科研项目延伸,课题获批为江苏省高等学校大学生创新创业训练计划一般项目。本团队成员是主要是物联网工程学院的学生,主持人及组员已经在前期较为系统的学习过Python编程技术和数据库方面的课程知识。本文借助上述技术,对微博舆情分析的相关技术进行研究,结合微博的特点,设计微博舆情文本关联度分析系统的解决方案,并最终加以实现。
1 大数据背景下微博舆情情感分析算法需求分析
1.1 理论需求分析
通过对网络事件情感分析算法的设计内容、实现功能、操作难度以及配置情况进行研究。针对情感分析文本需求,开发出的整合算法加载模拟系统,该系统分为前台与后台。从前台数据保存的数据库中取值,通过分类算法以及遍历计算权重,就可以得出对应的情感倾向分析结果。通过对关键词搜索,可以对所有帖子情况进行遍历,计算出文中相关联的情感分析情况,得出分析结论。
1.2 算法需求分析
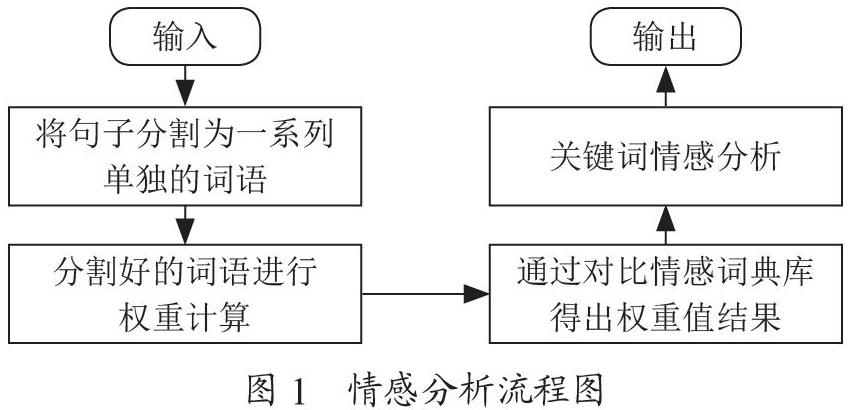
情感分析需要对文本内容的各个单独词语进行拆分,随后需要对拆分好的词语进行情感词典的匹配以获取权重值,接着进入设定好的逻辑进行总体文本的情感计算,这样可以计算得出情感倾向比例。如图1所示,完成情感分析需要四个步骤:
(1)用算法将输入的文本分割为一個个单独的词语;
(2)需要能够逐个筛选情感词语的情感词典库,并且对不同的情感词语设定不同的权重值,这可以有效地提高分析结果的精准度;
(3)需要详细的情感权重计算逻辑,对不同词语做出不同情况的计算处理,通过对每个词语的计算可以得出总体情感权重结果,能够体现正面、负面以及中性情感;
(4)对关键词的分析,需要对分割出的词语进行分类,对经过处理的分类算法进行词语分析,取出能够代表文本的关键词,最终输出分析结果。
2 微博舆情情感分析算法设计
2.1 算法接入平台模块设计
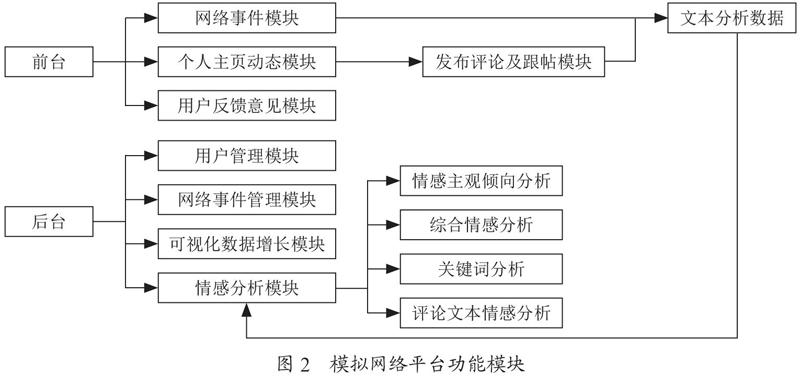
微博舆情情感计算方法研究的算法是否有效需要部署到项目中才得到能验证,所以需要建立模拟网络平台,其基础功能有前台用户模拟发帖评论及跟帖操作、后台系统模拟发布网络事件。模拟的网络平台模块如图2所示。系统开发用到了AJAX,该技术可以将对应的数据内容传入用户管理以及等级管理,极大地提高了操作效率。
2.2 算法总体设计
通过需求分析可知,算法需具备拆分文本、权重匹配、权重计算、关键词分析等功能。所以本课题开发的整个算法,应由多种方法及算法组成。将这些算法整合到一起,可以完整的实现对网络事件的情感计算分析,最终将算法加载至设计出的模拟平台进行实现、测试与优化。
2.2.1 拆分词语算法设计
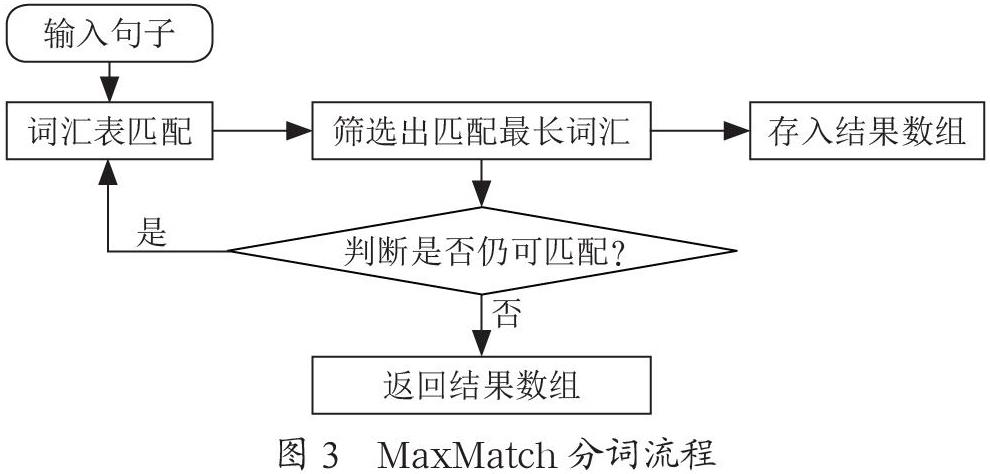
在对中文文本进行分析时较为有效的算法为MaxMatch文本匹配算法,该算法在大多数应用到中文词语分割时都有不错的表现,所以国内词语分割技术大多采用该算法。计算结果得出的数组,就是该文本信息所拆分下来的词语集合,将这些词语进行权重计算,可以得出相应的情感倾向结果[3]。MaxMatch的方法原理流程如图3所示。
2.2.2 事件词语情感权重设计
拆分后的词语需要进行权重计算,可采用情感词典分类方法进行情感分析。原理为:构建好数据情感词典(本次开发采用百度AI情感词典),通过发送请求可以将所拆分的词语发送云端进行分析字符串匹配,同时对反馈过来的词语进行权重分析,从而得出正面、负面及中性词语信息。总体规则如图4所示。
其中具体对情感词典字符串匹配的规则逻辑如图5所示,对所抽取的词语进行分析后,计算权重信息,从而得出正面、负面以及中性词语[4]。
通过导入情感词典中的向量词组,逐个遍历对比匹配词典库中对应的词语,且其中每个词语所在情感词典库中匹配的权重值都有特定的值。检测到词语为否定词、消极词时,需要进一步检测该词语的前一词语,当前一词语为否定词时,记+1,为程度副词时,乘前一词语的权重值,为其他词语时,减去该权重值;检测到词语为积极词语时,需要检测出前后词语,如果前一词语为否定词或前后词语为消极词,记为-1,如果前一词语为程度副词时,需要乘该词的权重,如果该词语为其他,则加上该权重;检测到该词语为否定词语时,直接记-1处理。最终将权重值输出,可以区分正面、负面以及中性情感。
2.2.3 关键词算法设计
计算出段落粒度的文本数据,本课题开发采取朴素贝叶斯分类器,由于其包含的算法众多,这里选用贝叶斯方法。在对短文本数据分析时,用它可以得到较为精准的分析结果。
贝叶斯定理,朴素贝叶斯的核心算法如下:
P(A|B)时已知B发生后A的条件概率,反之P(B|A)相同原理,P(A)为A的先验概率或者边缘概率,同理P(B)亦如此。贝叶斯定理可以理解为:后验概率=(相似度*先验概率)/标准化常量。
在套用该算法后,将其应用至贝叶斯分类中,它对所处理的文本内容,可以作为一个数组进行处理,即设e={e1,e2,e3,……,en},将集合D定义为D={d1,d2,d3,……, dn},计算出P(d1|e),P(d2|e),……,P(dn|e)。分类出的结果即为拆分后的词语信息。
2.2.4 综合检索数据情感分析设计
本课题采用的MaxMatch分词算法、情感词典权重方法应用后,仅能实现对一组数据的文本情感分析,本课题拟突破的研究为:对检索某一事件后引发的多记录数据,综合分析这些帖子的文本内容。应用以上算法后,加以改造设计出逻辑构造,如图6所示。
对搜索出的多条数据进行判断,将每条数据进行权重计算,同时需要计算出各文本数量比例,通过该比例乘情感权重分析结果,即可得出该记录的情感分析比例[5]。将这些数据的结果加在一起,就可得出对这一检索事件的综合情感分析。
3 大数据背景下微博舆情情感计算方法研究实现
3.1 微博舆情情感分析文本数据存取
微博舆情情感文本分析需要将分析的文本数据存入本地数据表中,首先将发布的网络事件文本内容存入t_new表中,将用户评论文本信息存入t_comment表中。对某一事件的评论搜索可以进行模糊查找,查找出所有记录,并将对应的记录信息提取出来进行情感文本分析。
情感计算分析的实现先后顺序分为:文本拆分词语,词语在情感词典中的权重匹配,多词语的权重逻辑计算,关键词算法分析。该流程即先实现将网络事件文本拆分为一个个单独的词语;其次将这些词语传入情感词典中匹配获取权重值信息;然后将整体文本分割的词语进行权重逻辑计算,即可计算出情感倾向值;最后对关键词进行分析,在词语拆分后调用朴素贝叶斯算法计算出结果。
3.2 网络事件拆分词语实现
使用MaxMatch文本匹配算法进行文本词语的拆分,由于算法为基层算法,输出的结果一般作为参数传入其他方法中,所以在前端无须显示[6]。算法执行出的结果以JSON形式输出,所以需要将其内容转换为HashMap格式,取出其中包含拆分词语的“items”字段。同理继续转换为HashMap格式,继续取出items中的“item”字段,拼接加入list數组中。
3.3 情感词典获取权重实现
将拆分好的词语进行情感词典的数据匹配,每一个词语在情感词典中都可以对应上各自的权重值,将这些权重值结合起来传入逻辑代码中,即可计算出情感倾向。
3.4 情感文本倾向分析实现
成功获取词语的权重值后,需要对总体文本的全部词语进行逻辑运算,即权重值计算得出结果,利用上文已经得出结果的文本分割词语方法以及权重值设定,进一步进行逻辑处理操作。对发布的网络事件帖子可以进行情感倾向分析,计算出权重值比例,设定为积极情感占比以及消极情感占比,然后通过算法计算出分析后的精确率,如图7所示。
4 结 论
微博是网络舆情发生和传播的重要场域,对微博进行舆情分析具有极为重要的意义。本文利用微博平台中的舆情数据,通过相关算法进行文本关联度研究,以情感词典计算情感倾向分析,以情感词典暂时处于主导地位为依据,将微博舆情的传播控制在情感理论的框架中,实现社会和谐稳定。
参考文献:
[1] 王晓晨,关硕,于文博,等.体育赛事网络舆情的传播特征研究——基于2019年女排世界杯的文本情感分析 [J].成都体育学院学报,2020,46(5):74-81.
[2] 陈炳丰.面向文本数据的情感计算研究 [D].广州:广东工业大学,2019.
[3] 谢泽澄.基于深度学习的文本识别与文档切分的研究和应用 [D].广州:华南理工大学,2019.
[4] 曾江峰.基于深度学习的文本情感计算研究 [D].武汉:华中科技大学,2019.
[5] 徐康.基于主题模型的文本情感和话题建模的研究 [D].南京:东南大学,2017.
[6] 任巨伟,杨亮,吴晓芳,等.基于情感常识的微博事件公众情感趋势预测 [J].中文信息学报,2017,31(2):169-178.
作者简介:程子文(1998—),男,汉族,江西九江人,本科在读,研究方向:物联网工程;曾豪(1997—),男,汉族,河南邓州人,本科在读,研究方向:通信工程;姜斌(1997—),男,汉族,江苏盐城人,本科在读,研究方向:计算机科学与技术;陈国俊(1978—),男,汉族,江苏无锡人,副教授,计算机科学专业硕士,研究方向:人工智能、量子通信、物联网技术;王莺(1987—),女,汉族,江苏金坛人,讲师,软件工程硕士,研究方向:大数据分析、算法设计、图像处理。
猜你喜欢
物联网技术(2016年11期)2017-01-12
电子技术与软件工程(2016年22期)2016-12-26
预测(2016年5期)2016-12-26
科技视界(2016年20期)2016-09-29
电脑知识与技术(2016年5期)2016-04-14
