
5G核心网UPF硬件加速技术
2020-02-22 12:25王立文王友祥唐雄燕杨文聪张雪贝李沸乐
移动通信 2020年1期
王立文 王友祥 唐雄燕 杨文聪 张雪贝 李沸乐

【摘 要】5GC通過NFV技术在通用硬件上实现网元功能,具有资源灵活共享等优点,但是5G的uRLLC、eMBB等应用有超低时延、高带宽等要求,对核心网UPF的转发时延、带宽、抖动、丢包率等性能提出了更高要求。将部分业务处理卸载到适合大规模转发和并行计算的硬件加速卡,可提供更好的转发特性,总结并分析了UPF的转发流程,并对当前的硬件加速技术和加速方案进行介绍,提出了目前UPF硬件加速技术中存在的问题,最后对UPF硬件加速研究方向和思路进行展望。
【关键词】5G核心网;用户面;硬件加速技术;可编程逻辑门阵列
doi:10.3969/j.issn.1006-1010.2020.01.004 中图分类号:TN919.8
文献标志码:A 文章编号:1006-1010(2020)01-0019-05
引用格式:王立文,王友祥,唐雄燕,等. 5G核心网UPF硬件加速技术[J]. 移动通信, 2020,44(1): 19-23.
0 引言
通过使用X86等通用性COTS硬件以及虚拟化技术来承载网络功能的软件处理,可以使网络设备功能不再依赖于专用硬件,资源可以充分灵活共享,实现新业务的快速开发和上线,并基于实际业务需求进行自动部署、弹性伸缩、故障隔离和自愈等。然而,面向5G网络应用时[1],5G uRLLC超低时延和eMBB高带宽等要求,对核心网转发面网元处理时延、带宽、抖动和丢包率等性能提出了更高要求[2]。CPU架构适合逻辑复杂计算,优势不在于处理大量并行简单业务,硬件加速卡可以在空间上分离处理逻辑,从而达到更快的处理速度,本文接下来将对5G核心网UPF硬件加速技术进行研究。
1 UPF功能
1.1 UPF网元
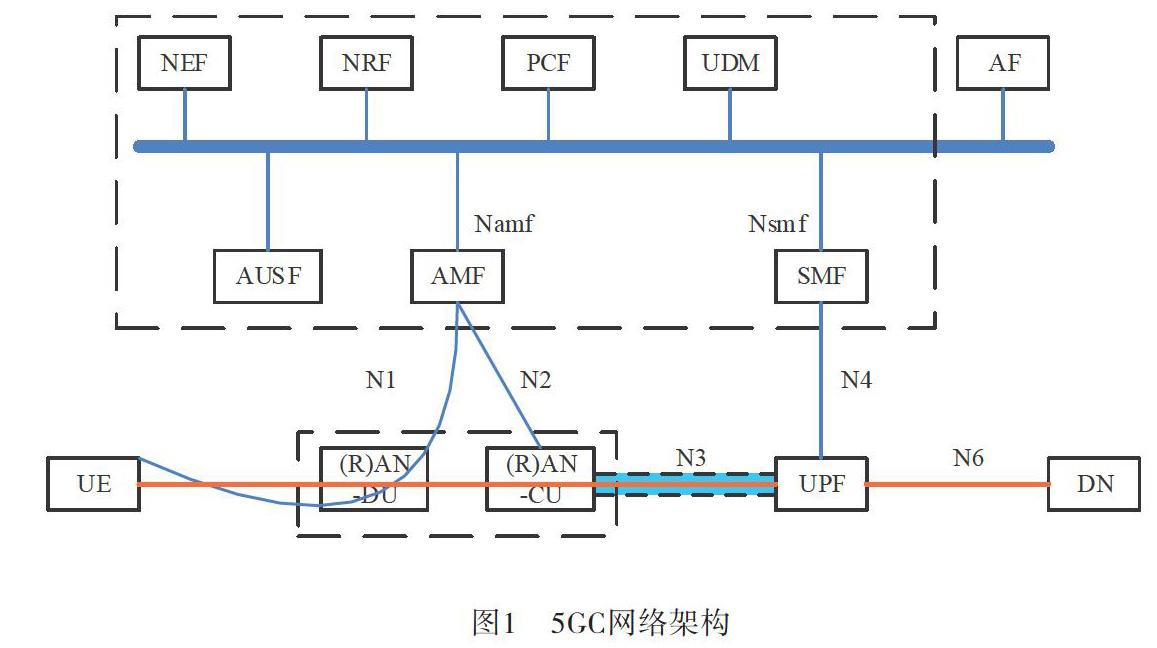
5G核心网进行了颠覆性设计,如图1所示,通过基于服务的架构、切片、控制面和用户面分离等,结合云化技术,实现网络的定制化、开放化、服务化,支持大流量、大连接和低时延的万物互联需求[3]。
UPF承担着5G核心网的用户面功能,其核心功能是系统内外移动性锚点和分组路由和转发将流量路由到数据网络,如图1所示,上行链路用户数据从UE发出后经过无线信道传输到基站,基站将用户数据封装到GTP-U报文中通过N3接口发送UPF,UPF从GTP-U净荷中得到UE发出的用户数据,根据路由转发,通过N6发送到DN,下行链路反之。为了实现对用户数据的控制与管理功能,UPF还支持与数据网络互连的外部PDU会话点、数据包检查和用户平面部分的策略规则实施、上行链路分类器,分支点以支持多宿主PDU会话、用户平面的QoS处理、下行链路分组缓冲和下行链路数据通知触发等功能。
1.2 UPF的转发流程
如图2所示,UPF的转发流程包含LINK、IP FWD、Security、GTP、Rule Lookup、DPI、QoS、Charging等模块。
LINK和IP FWD模块实现网络报文收发、OVS等,支持MAC、IPv4/v6、Tunnel、MPLS、ACL、IP组播等基本的网络报文转发功能,逻辑功能相对简单,与交换机、路由器的实现原理相似。
Security模块实现包校验、DDOS、Anti-spoofing、APN ACL等安全防护功能,用于对报文有效性和安全性进行检查,不符合要求的数据包丢包处理。
GTP模块与基站之间建立GTP隧道,实现了GTP信令处理、GTP报文加封装/解封装等功能。
DPI需要根据协议识别库对数据流进行业务分析。设备协议识别库需要根据现网业务发展状况及时更新,且分析逻辑较为复杂。
QoS模块根据网络报文的分类结果,将归属于不同种类用户和业务的网络报文进行差异化处理,包含Car、Remark、Shaping等功能,保证在有限的硬件资源条件下,为高优先级的网络报文提供更快、更可靠的转发服务。
Charging模块根据网络报文的分类结果进行统计计费,包含CG计费、AAA计费、OCS计费等,统计维度和粒度受业务影响,灵活多变。
DPI用于对网络报文分类,QoS和Charging是利用分类的结果对报文进行相应处理。DPI过程复杂,计算量大,非常消耗CPU资源,该过程可被称为慢进程。而网络报文往往是多个报文组成一条流完成数据的传输,如HTTP等。组成同一条流的报文具有相同的源IP、目的IP、协议类型、源端口、目的端口等N元组信息,因此通过DPI对一条流中的部分报文处理后得到该流报文的分类后,就可以通过判断报文中的N元组是否属于该流得到该报文的分类,无需再进行DPI处理,直接就可以根据流的分类信息进行QoS和Charging等处理,该过程可被称为快进程。Rule lookup模块在DPI模块之前判断网络报文是否可以通过快进程处理,可以通过快进程处理的转入快进程处理,不能通过快进程处理的会转到慢进程。
LINK、IP FWD、Security、GTP、Rule lookup、QoS等模块逻辑相对简单,适合通过硬件芯片加速。Charging模块为了实现灵活的计费维度和粒度,逻辑较复杂,且有新的业务和计费需求时,可能还需要对原来的计费逻辑进行修改才能满足需求,因此可以通过硬件芯片加速实现,但是逻辑需要改变时,难度和成本也会增大,因此需要根据实际需求和场景评估是否有必要。DPI模块逻辑复杂且协议多变,还涉及到正则表达式和字符串检索等,通过硬件芯片实现的技术尚不成熟,目前还主要是在CPU中通过软件实现。
2 加速方案
2.1 硬件加速芯片
目前可用于硬件加速的芯片有FPGA、GPU、NPU、ASIC、SoC、TCAM、网络流处理器/可编程交换芯片等,其中GPU主要实现浮点运算和视频数据的处理,本文不做讨论,其他几种芯片均可用于网络报文转发加速。
网络处理器NPU提供一定的转发规则可配置能力,通过对数据报文转发处理主要过程的固化,实现高性能数据转发,主要面向大容量数据协议转发处理类型的专用处理器,一般应用在高端路由设备中[4]。UPF可采用NPU方案实现高吞吐转发。
ASIC芯片将成熟稳定的算法类应用按需定制,量产后在成本、功耗和开发难度上具有绝对优势,但是不支持重用,降低了灵活性。
片上系统SoC包含完整的硬件系统和嵌入式软件,具有可编程、可升级、支持热补丁等特点,可运用在网络加速与计算加速中,如GTP、H-QoS、转发、IPSec、DPI、Charging等。
TCAM是一种三态内容寻址存储器[5],可以对表项进行并行匹配命中,主要用于快速查找ACL、路由等表项,但是TCAM尽可以实现快速命中表项,往往需要其他芯片配合根据命中情况执行某些动作才能实现对报文的业务处理。
网络流处理器/可编程交换芯片是近年新兴起的一种特殊的硬件加速芯片,在传统交换芯片的基础上支持可编程,其原理是多个TCAM与动作处理单元组成的流水线并行处理,利用可编程机制控制报文根据命中表项的情况实现转发、丢弃、重新进入流水线等动作,兼顾了高性能与灵活性,比较有代表性的是barefoot的P4交换芯片和博通的Jericho芯片。
可编程逻辑门阵列FPGA的性价比介于通用处理器和ASIC之间,其突出的软件灵活加载可重用特性,使得其在加速领域适应性很广,主要缺点是开发门槛高、难度大,主要由两大厂商Intel和Xilinx提供。
可编程逻辑门阵列FPGA[6]的性价比介于通用处理器和ASIC之间,支持重新加载软件实现不同的加速功能。另外随着FPGA的处理能力越来越高,一块FPGA可以被配置为多块功能单元,并通过SRIOV方式提供给多个上层业务来使用。目前FPGA在加速领域适应性很广,主要缺点是开发门槛高、难度大,主要由两大厂商Intel和Xilinx提供。FPGA通常使用PCIE接口与通用处理器组成异构系统,实现加速功能。
UPF硬件加速中芯片的选型需要根据应用需求,从性价比、可维护性等多个角度来评估选择,也可以根据需要卸载的业务特点,选择一种或者多种类型芯片共同完成硬件加速功能。
2.2 智能网卡
早期的网卡仅实现数据链路层和物理层的功能,但随着链路带宽的增长,现代网卡硬件中普遍卸载了部分传输层、路由层的处理逻辑(如校验和计算、传输层分片重组等),来减轻CPU的处理负担。
目前业界普遍的百G级带宽、微秒级延时的高性能网络设施,需要协议栈具备极高的处理速度,因此将协议栈的处理卸载(offload)到网卡ASIC芯片上实现是目前普遍采用的方式。但是不断变化的应用场景对网络协议栈功能的新需求又层出不穷,在此背景下,智能网卡技术得到了广泛发展[7]。智能网卡同时具备高性能及可编程的能力,既能处理高速的网络数据流,又能对网卡进行编程实现定制化的处理逻辑。
现在典型的智能网卡有两种实现方式,一种是采用可编程门阵列FPGA实现,另一种是采用专用的NP实现。这两种方式各有优缺点,在性能方面,通过直接烧写硬件逻辑的基于FPGA的智能网卡性能更高;而NP则采用多核的方式来加速整个网卡的处理能力,但其每个核的处理能力与通用CPU性能相比并无特别优势,因此对于单一网络流的处理性能较低;在可编程性方面,基于FPGA的智能网卡可编程性相对较低,开发难度也较大。而NP则具备较高的可编程性,几乎和通用CPU相当的表达能力,可实现灵活的处理逻辑。
2.3 硬件加速卡与业务卸载
将UPF中业务功能模块卸载到硬件加速卡,可以实现UPF转发加速。而硬件加速卡与智能网卡实现原理相似,区别是智能网卡是相对更标准化的加速卡,不仅仅针对UPF,智能网卡厂家通常会采用可以适应更多场景加速的方案,而UPF硬件加速卡是针对UPF的业务流程,根据业务需要和芯片特性、成本等因素综合考虑设计实现的。
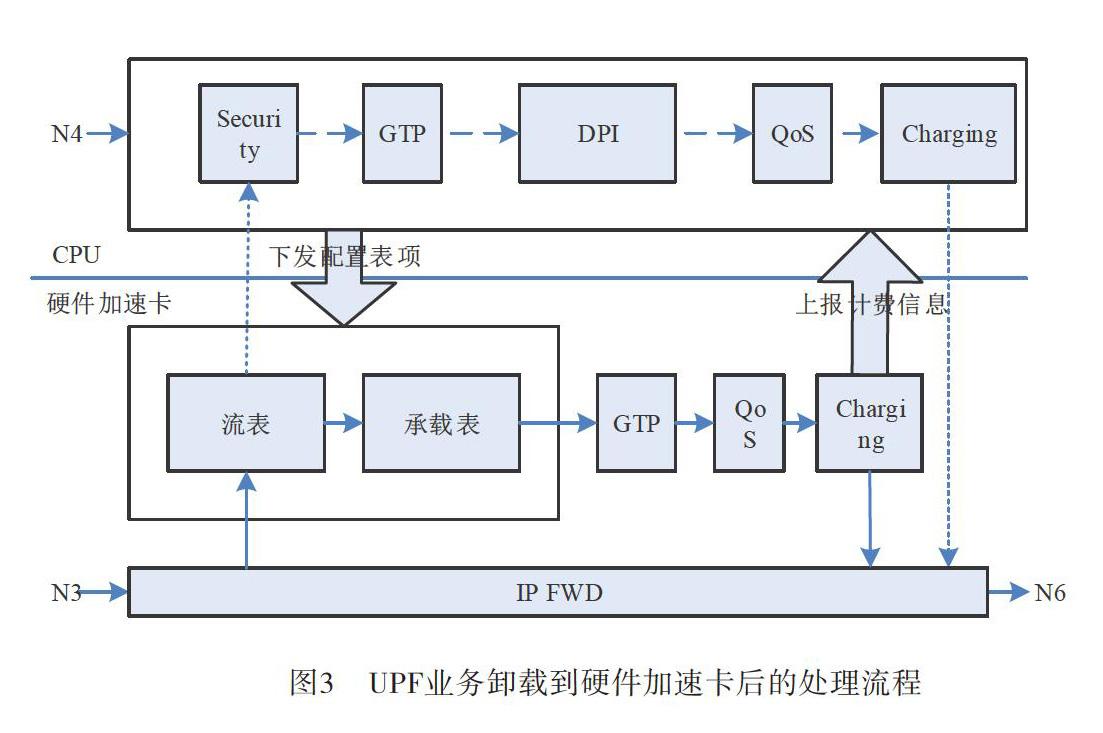
因为硬件加速卡针对UPF业务流程定制化设计,因此不同厂家的硬件加速卡方案也不同,主流方案是将UPF快进程业务卸载到硬件加速卡,由CPU完成慢进程中的DPI等处理流程,如图3所示。
硬件加速卡接收到数据流后,提取N元组在流表中查询判断是否存在匹配的表项,如果不匹配则将报文上送CPU,由CPU对该报文进行慢进程处理,经过安全、GTP、DPI等处理后,判断该数据流是否需要卸载,若需要卸载则生成流表下发到硬件加速卡。后续数据包进入硬件加速卡后,会命中流表中的表项,进而再通过承载表找到该流的QoS、Charging等规则,由硬件加速卡完成数据包的快进程转发。
在UPF的转发流量中,视频流占据主要部分且比例还在不断提升。对于视频流这种长连接数据流,仅在连接建立之初有少量的报文上送CPU进行慢进程处理,后续大量的数据包都会在硬件加速卡中完成快进程转发。根据EPC话务模型硬件加速卡可以处理数据包中的70%以上,因此可以很大程度上降低CPU的负载,提高UPF的转发性能,且像视频流这种越长的流效果越明显。
3 问题与展望
虽然硬件加速可以为UPF带来高性能、低时延等优良性能指标,但是同时也引入了新的问题。
如图4所示,对于CPU+普通网卡、CPU+智能网卡、CPU+硬件加速卡等不同的UPF形态方案,从普通网卡到智能网卡再到硬件加速卡可以承载的UPF业务越来越多,因此CPU负载也越来越小,但是同时硬件加速卡的定制化程度也越高,导致CPU与网卡之间的API接口數量几十上百倍的增加。
CPU与硬件加速卡之间繁多的API接口也意味着各厂家之间难以协调出统一标准的API接口。没有标准化的抽象接口,那么每个硬件厂家的加速卡就必须使用特定的加速驱动,也只兼容同厂家的UPF业务软件,因此硬件加速卡与UPF网元软件必须捆绑到一起运行工作。这与5GC的NFV方案是相悖的[8]。
因此若要使硬件加速卡可以与通用服务器构成的资源池兼容,需要标准化API接口和扩展MANO。
当前业务加速硬件需要与上层应用绑定,这就成了专用硬件,因此通用性是必须要考虑的,这就涉及到加速卡的解耦,也是加速资源池化的基础。加速卡解耦方案大致分为两种,一种是软硬解耦,即标准化硬件加速卡的硬件设计方案,由网元软件厂家下发硬件加速卡的逻辑固件;另一种是软软解耦,即硬件加速卡自带业务逻辑固件,网元软件厂家与硬件加速卡驱动之间制订标准化的API。软硬解耦方案限制了硬件设计,容易僵化,不利于硬件加速卡技术的发展,也没法兼顾目前的基于FPGA或者NP等不同硬件芯片的硬件加速卡方案。软软解耦方案可以使硬件加速卡选用各种硬件芯片方案,在设计上具有很大的灵活性,其难点在于繁多的API接口的标准化,这可以借鉴普通网卡的策略,先制订最基本功能的标准API,难以统一的个性API作为扩展特性由各厂家自由发挥,网元软件厂家保证在基本功能基础上可以完成UPF的功能,根据需要有选择的适配硬件加速卡的扩展特性,从而实现更好的性能。
硬件加速卡资源池化后的使用可以分为感知、分配、调度、释放等四个阶段[9]。感知需要云平台对硬件类型进行识别,分配需要VNFM和NFVO支持网元对加速硬件资源请求的解析,调度需要云平台进行加速资源的监控和部署,释放则需要云平台对加速硬件资源进行重新编程。这些都需要对MANO进行扩展。
4 结束语
本文总结并分析UPF的转发流程、对当前的硬件加速技术和加速方案进行介绍,提出目前UPF硬件加速技术中存在的没有标准化、没有资源池化的问题,在下一步工作中需要标准化硬件加速卡驱动与CPU之间的API接口、扩展MANO支持硬件加速卡的发现与管理。
参考文献:
[1] 肖清华. 蓄势待发、万物互连的5G技术[J]. 移动通信, 2015,39(1): 33-36.
[2] 张轶,侯雪颖,夏亮,等. 5G系统用户面时延浅析[C]//5G网络创新研讨会(2018)论文集. 广州: 移动通信杂志社, 2018.
[3] 王志勤,余泉,潘振岗,等. 5G架构、技术与发展方式探析[J]. 电子产品世界, 2016(1): 14-17.
[4] 谭章熹,林闯,任丰源,等. 网络处理器的分析与研究[J]. 软件学报, 2003(2): 96-110.
[5] V C Ravikumar, R N Mahapatra. TCAM architecture for IP lookup using prefix properties[J]. IEEE Micro, 2004,24(2): 60-69.
[6] 褚振勇. FPGA设计及应用[M]. 西安: 西安电子科技大学出版社, 2006.
[7] D Cerovic, V DPiccolo, A Amamou, et al. Data Plane Offloading on a High-Speed Parallel Processing Architecture[C]//2018 IEEE 11th International Conference on Cloud Computing (CLOUD). IEEE, 2018.
[8] 赵明宇,严学强. SDN和NFV在5G移动通信网络架构中的应用研究[J]. 移动通信, 2015,39(14): 66-70.
[9] 杨经纬,马凯,龙翔. 面向集群环境的虚拟化GPU计算平台[J]. 北京航空航天大学学报, 2016,42(11): 2340-2348.
作者简介
王立文(orcid.org/0000-0003-3748-4697):博士毕业于北京交通大学,现任职于中国联合网络通信有限公司网络技术研究院,主要从事无线核心网相关技术研究及标准化工作。
王友祥:高级工程师,博士,现任职于中国联合网络通信有限公司网络技术研究院,主要从事5G新技术研究及试验工作。
唐雄燕:博士,教授级高级工程师,中国联合网络通信有限公司网络技术研究院首席科学家,中国联通智能网络中心总架构师,“新世纪百千万人才工程”国家级人选,兼任北京邮电大学兼职教授、博士生导师,工业和信息化部通信科技委委员,中国通信学会信息通信网络技术委员会副主任,中国通信标准化协会物联网技术委员会副主席,中国光学工程学会光通信与信息网络专家委员会主任,中国互联网协会标准工作委员会副主任,主要研究方向为宽带通信、互联网/物联网、新一代网络等,主持了企业许多重大技术工作,还担任过多个国家級科研课题的负责人。
猜你喜欢
科技与创新(2023年17期)2023-09-17
汽车电器(2022年9期)2022-11-07
铁道通信信号(2020年4期)2020-09-21
工业经济论坛(2020年6期)2020-04-13
中国外汇(2019年11期)2019-08-27
网络安全和信息化(2019年1期)2019-02-15
汽车观察(2018年12期)2018-12-26
汽车观察(2018年10期)2018-11-06
铁道通信信号(2016年8期)2016-06-01
现代制造技术与装备(2015年4期)2015-12-23
