
基于增强语义与多注意力机制学习的深度相关跟踪
2020-02-19 11:27周双双宋慧慧张开华樊佳庆
计算机工程 2020年2期
周双双,宋慧慧,张开华,樊佳庆
(1.南京信息工程大学 自动化学院,南京 210044; 2.江苏省大数据分析技术重点实验室,南京 210044)
0 概述
视觉跟踪是计算机视觉中的基本问题,被广泛应用于人体运动分析、视频监控、自动驾驶等领域。虽然目前已有许多方法[1-3]被提出用于解决视觉跟踪问题,但由于形变、遮挡、快速运动等因素的影响,稳健的视觉跟踪系统仍然难以实现。
近年来,相关滤波器被广泛应用于视觉跟踪。文献[4]将自适应相关滤波器应用于目标跟踪,利用单通道灰色特征使算法实时速度超过600帧/s。文献[5]提出一种基于双步相关滤波的目标跟踪算法,在提高目标跟踪精度的同时保证了跟踪速度,该算法具有较强的鲁棒性,同时能解决目标遮挡时目标模板被污染的问题。文献[6]提出一种利用最大间隔相关滤波的目标跟踪算法,通过最大分类间隔增强相关滤波器的判别性,将相似背景作为负样本对模型进行更新来提高跟踪的鲁棒性。文献[7]提出一种基于低秩重检测的多特征时空上下文跟踪方法,利用有效的矩阵分解方式对历史跟踪信息进行低秩表达,并将其引入在线重检测器,解决了跟踪失败后的重定位问题。文献[8]设计核化相关滤波器(Kernelized Correlation Filter,KCF),通过将多通道的HOG特征代替灰度特征,并添加余弦窗口抑制边界效应。文献[9]通过增加一个尺度的回归实现了精确的尺度估计。文献[10]在滤波器上结合空间正则化,使学习的滤波器权重集中在目标对象的中心部分以解决边界效应,但是速度只有4帧/s,很难应用到实际场景中。
目前,已有较多研究结合了相关滤波和深度特征。文献[11]在文献[10]基础上利用CNN深度特征,但其利用相关滤波将特征提取与跟踪器训练等隔离开,无法从端到端训练中受益。文献[12]采用全局颜色直方图特征和局部HOG特征实现了判别相关滤波器(Discriminant Correlation Filter,DCF)跟踪的融合特征。文献[13]利用图像分块逐一检测的方法设计重新检测模块,避免出现跟踪漂移现象,但分块检测使运算时间成本增加。文献[14]通过稀疏的模型更新策略减少了更新的参数,但速度上表现一般。文献[15]利用大规模数据集离线训练设计前后帧特征相似性匹配的深度卷积网络,虽然速度上能达到实时,但精度表现一般。尽管目前基于相关滤波器的跟踪器有很多改进方法,也在精度和速度上得到提升,但面对遮挡和运动模糊等情况,仍未有较好的解决方案。
文献[16]提出的可判别相关滤波器网络(Discriminant Correlation Filter Network,DCFNet)虽然通过添加余弦窗有所改进,但仍受到边界效应的影响,并且其在遮挡和运动模糊情况下目标容易发生域漂移。针对上述问题,本文采用多注意力机制自适应选择重要目标特征信息进行学习,设计RACFNet网络结构。通过由编码器和解码器组成的EDNet网络获取高级语义信息,并将其融合到原始低级特征中,以弥补单一低级特征表达力的不足。同时,根据解码器作用的域独立重构约束,利用编码器中学习到的高级语义特征鲁棒处理目标漂移情况。
1 RACFNet网络
与传统DCF方法不同,本文分析DCF封闭解的求解方案,挖掘网络以端到端方式学习最适合DCF跟踪的特征,而无需手工干扰。将DCF视为文献[15]在孪生网络中添加的特殊相关滤波器层,提出RACFNet网络的体系结构,其整体框架如图1所示,其中包含卷积层、编码器和解码器结构层。在离线训练过程中,卷积层、编码器和解码器构成特定的特征提取器ψ,相关滤波器层则通过将网络输出定义为目标位置的概率图来有效地完成在线学习和跟踪。由于相关滤波器层的推导仍然在傅里叶频域中进行,因此保留DCF的效率特性。
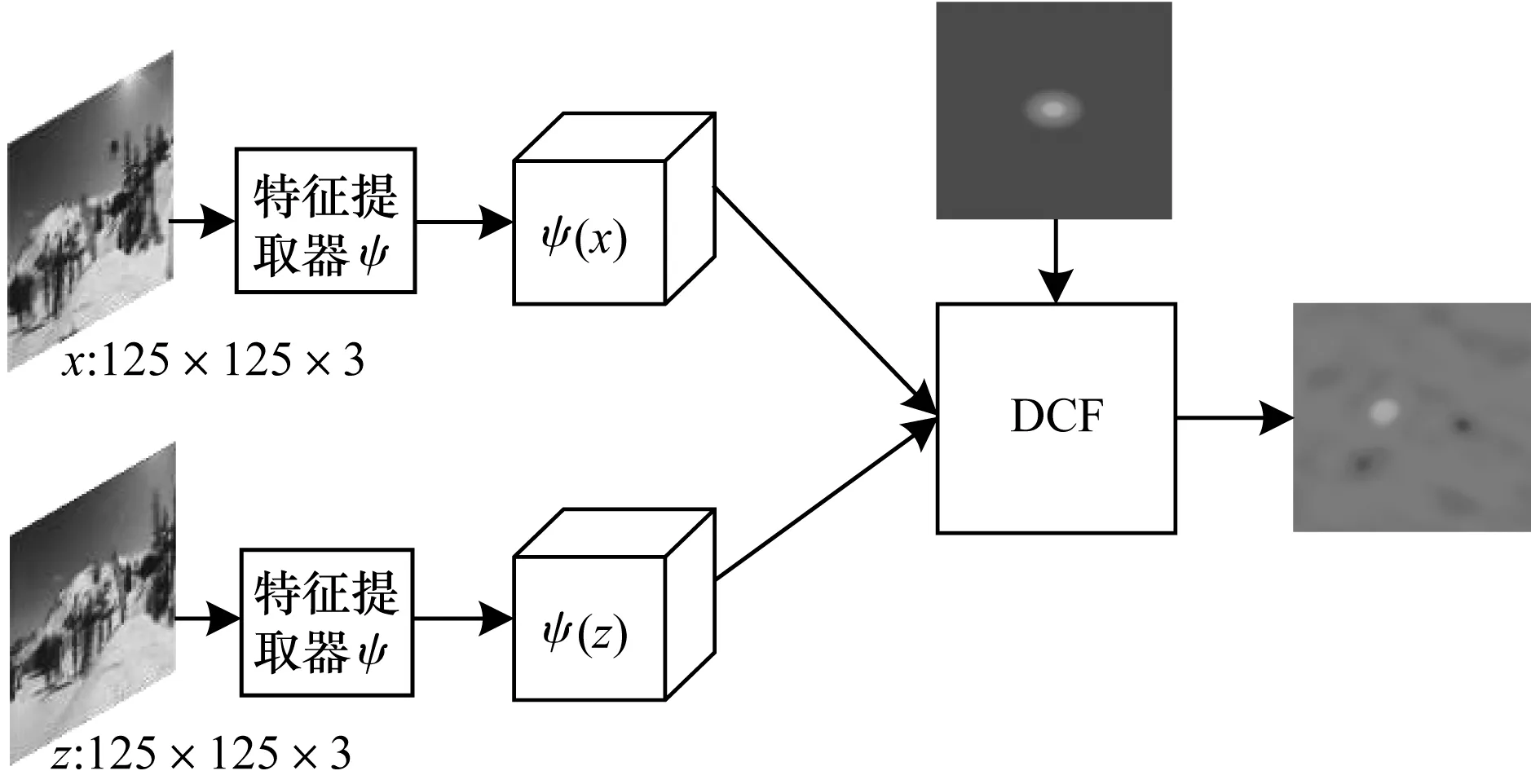
图1 RACFNet网络框架
1.1 网络结构
本文设计一个基于增强语义与多注意力机制学习的深度相关跟踪算法,其特征提取框架如图2所示,其不同于图3所示的EDNet结构只含卷积Conv1和Conv2的浅层特征,本文加入编码器和解码器结构提取高级语义特征,结合浅层特征得到融合特征F。图4所示为通道注意力机制结构。F跳跃连接通道注意力机制构成的通道残差注意力机制,输出特征为F1,表示在不同的通道位置上进行加权。图5所示为空间注意力机制结构,其中,F1跳跃连接空间注意力机制构成的空间残差注意力机制,是对通道注意力学习的补充,提高了对空间上下文信息的有效利用。此外,浅层特征中包含Conv1和Conv2卷积层,采用96个3×3×3滤波器,并且在滤波器后使用缩放指数线性单元(Scaled Exponential Linear Unit,SELU),该激活函数对网络具有自归一化功能。最后采用32个96×3×3滤波器,在滤波器后使用局部响应归一化函数(Local Response Normalization,LRN)对局部神经元的活动创建竞争机制,使响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强模型泛化能力。

图2 特征提取器ψ结构

图3 EDNet网络结构

图4 通道注意力机制结构

图5 空间注意力机制结构
1.2 可判别相关滤波器

(1)
在式(1)中,wl是相关滤波器参数w的通道l层,表示循环相关,正则项λ≥0,目的是优化如式(2)所示。
(2)
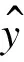
在检测进程中,需要裁剪搜索的图像块在新的帧中特征ψ(z),通过搜索相关响应图m最大值来估计转换,如式(3)所示。
(3)
在离线训练的大规模数据集上,本文方法保留了DCF性能的优越性,离线训练为在线DCF跟踪提供了特定功能特征提取器。
在线模型的更新中,在线跟踪将更新滤波器参数w,优化式(1)问题以增量模式表示,如式(4)所示。
(4)
其中,参数μt≥0,表示对样本xt的影响。由式(2)中的封闭解形式可以拓展到时间序列,如式(5)所示。
(5)
1.3 EDNet高级语义特征
高级语义特征由编码器和解码器结构提取得到,命名为EDNet,该结构中存在池化层,这样会丢失图像信息和降低图像分辨率且是不可逆的操作,结构中的上采样可以弥补一些图像的信息,但是补充的信息不够完全,因此,还需要与分辨率高的图像相互连接,在图像卷积的同时增加填充使输入输出尺寸相同,随着卷积次数的增多,提取的特征也更加有效,而比普通的编码器和解码器的特殊之处,采用上采样并且直接复制浅层信息的方法,无需裁剪,独特的通道层的设计使前后层信息融合从而弥补单一特征的不足,使特征表现得更鲁棒。
EDNet网络框架属于轻量级网络,如图3所示,其中左半分支输入原图经过6次卷积(3×3)、2次池化层(5×5)下采样,原图125×125×3经过前半分支操作后变为5×5×64,通过后半分支采用4次卷积、2次反卷积上采样,后半分支设计将前半分支特征图和对称的后半分支上采样的特征图级联,然后直接128通道经过卷积(3×3)将通道降到32,减少信息的冗余,使高级语义特征更加显著,最后经过上采样和卷积的操作使图像恢复到输入图像的大小。EDNet网络关注更多的高层信息,并还原原图的底层空间结构信息,进一步增强了浅层特征的语义信息,这种增强语义信息的方法有助于目标跟踪的特征稳健性表达。
1.4 通道注意力机制
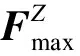
(6)
1.5 空间注意力机制
本文通过使用最大池化和平均池化操作得到特征图的空间信息,其体现信息突出的部分,是对通道注意力图的补充。空间注意力机制沿通道轴应用最大池化和平均池化操作,并将它们相连接以生成有效的特征表达。
MZ1(F1)=F1⊗σ(f3×3([MaxPool(F1);
AvgPool(F1)]))
(7)
其中,σ表示为Sigmoid函数,f3×3表示为一个卷积核尺寸大小为3×3的卷积操作。F1跳跃连接MZ1(F1)形成空间残差注意力机制。
1.6 算法实现
本文设计是在DCFNet的基础上引入高级语义特征和浅层特征的有效结合,算法主要分为3个阶段:
1)训练阶段:输入样本,在当前的帧中确定搜索区域;初始化特征提取器参数,构造均方误差损失,通过梯度下降学习特征提取器的参数,将搜索区域通过提取器提取特征;计算特征的自相关性,通过岭回归学习到滤波器模板。
2)检测阶段:新的一帧根据上一帧的目标位置确定搜索区域,通过特征提取器提取特征,计算搜索区域特征;将其特征与滤波器模板相关操作,输出响应值中最大值就是目标的最新位置。
3)模型更新阶段:每帧都对目标滤波器模板学习更新。
2 实验结果与分析
实验平台是Ubuntu16.04系统下PyTorch0.4.0,所有实验都在配置为Inter Core i7-8700k 3.70 GHz CPU、GTX1080Ti GPU的计算机上完成的。本文使用文献[18]数据集裁剪出尺寸为125×125像素的546 315个视频帧作为离线训练数据,采用动量为0.9的随机梯度下降最优化网络并设置离线学习率l为10-5,权重衰减γ为5×10-5,训练周期约为20个周期且每次小批量训练样本数为16。对于相关滤波层超参数,采用固定在线学习率μt为0.008,正则化λ为10-4,插值因子为0.01,最后为了解决尺度变换问题,在搜索图像上采用5个不同的尺度缩放因子s,{ds|d=1.031,s=-2,-1,0,1,2}去搜索图像,其中d是尺度步长。
在OTB-2013[19]和OTB-2015[20]公共标准数据集上进行实验评估,并以距离精确度(Distance Precision,DP)、成功率(Success Rate,SR)和中心位置误差(Center Location Error,CLE)作为评估标准。
1)精确度:跟踪目标框的中心坐标和真实值的中心坐标的欧式距离小于一定阈值(实验中设置为20)的帧数占全部帧数的比例。
2)成功率:跟踪目标的边界框和标准目标边界框的重叠率超过一定阈值(实验中设置为0.5)的帧数占视频总帧数的比例。成功率越高,跟踪效果越好,计算公式为(Sg∩Sp)/(Sg∪Sp),其中,Sg、Sp分别为真实和预测的目标框面积。
数据集图片中均包含光照变化、平面外旋转、尺度变化、遮挡、形变、运动模糊、快速运动、平面内旋转、超出视野、背景混乱、低分辨率等因素的干扰。视觉跟踪遵循OTB规则,并根据成功率结果进行评估。
2.1 基于OTB2013的实验结果对比
在OTB2013的公共数据集上进行评测,将本文的跟踪器RACFNet与3个先进的跟踪器DeepSRDCF[11]、SiamFC3S[15]、DCFNet[16]进行一次通过型(One Pass Evaluation,OPE)成功率对比,实验结果如图6所示。可以看出,本文算法的成功率为67.3%,排名第一,DCFNet跟踪器成功率值为62.2%,本文算法提高了5.1个百分点,在本测试集上本文算法跟踪速度达到92.7帧/s,可见加入的高级语义特征、通道残差注意力机制和空间残差注意力机制使跟踪效果得到显著提高。
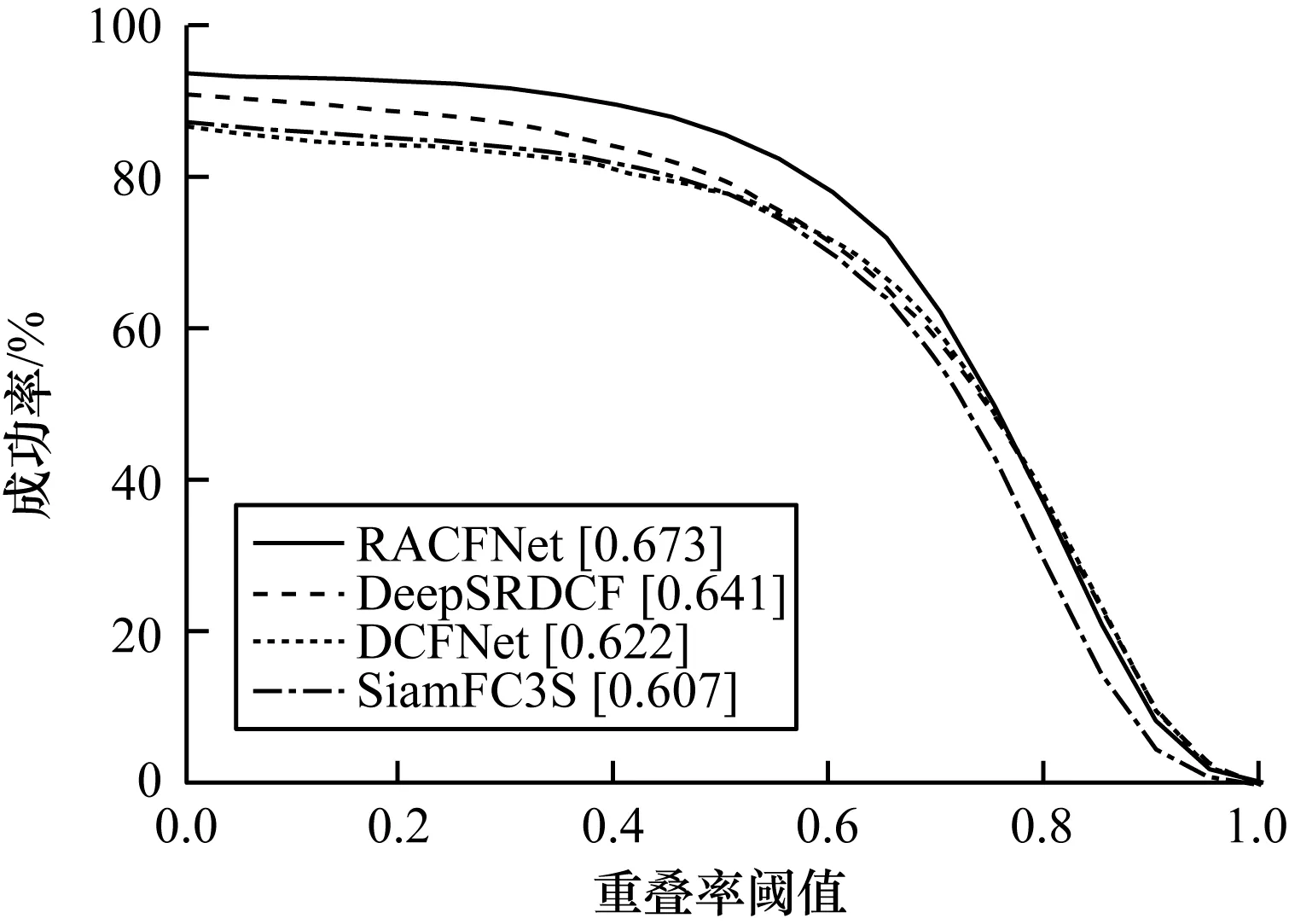
图6 在OTB2013数据集上的成功率对比
2.2 基于OTB2015的实验结果对比
分别选取100个OTB2015标准数据集,将本文方法与DCFNet、CREST[21]和SiamFC3S 3个跟踪器进行成功率对比,实验结果如图7所示。可以看出,本文算法在测试视频上鲁棒性能最好,平均成功率为64.2%,其次是CREST,成功率为62.3%。本文算法在高级语义特征中加入了通道和空间残差注意力,针对特征通道信息分布和空间特征的分布分别进行加权,表达出重要信息特征,较基准DCFNet跟踪成功率58%提高了6.2个百分点,在OTB2015数据集上跟踪速度达到92帧/s,表现得更鲁棒。
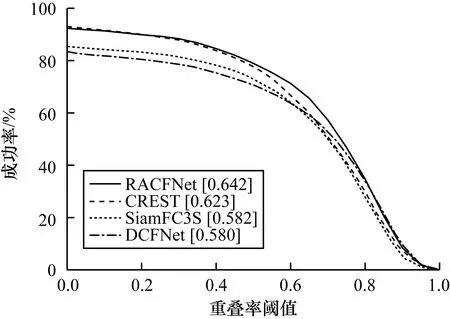
图7 在OTB2015数据集上的成功率对比
2.3 基于不同视频的实验结果对比
基于OTB2015数据集上,使用不同视频对本文RACFNet跟踪器进行性能评测。表1显示了不同算法的目标跟踪结果,可以看出,本文算法在7组测试视频上精确度、成功率、中心位置误差整体表现最佳,本文算法成功率平均值为89.7%,相对基准DCFNet的成功率平均值76.2%,提高了13.5个百分点,中心位置误差平均值减少了26.66,跟踪目标准确性提升。
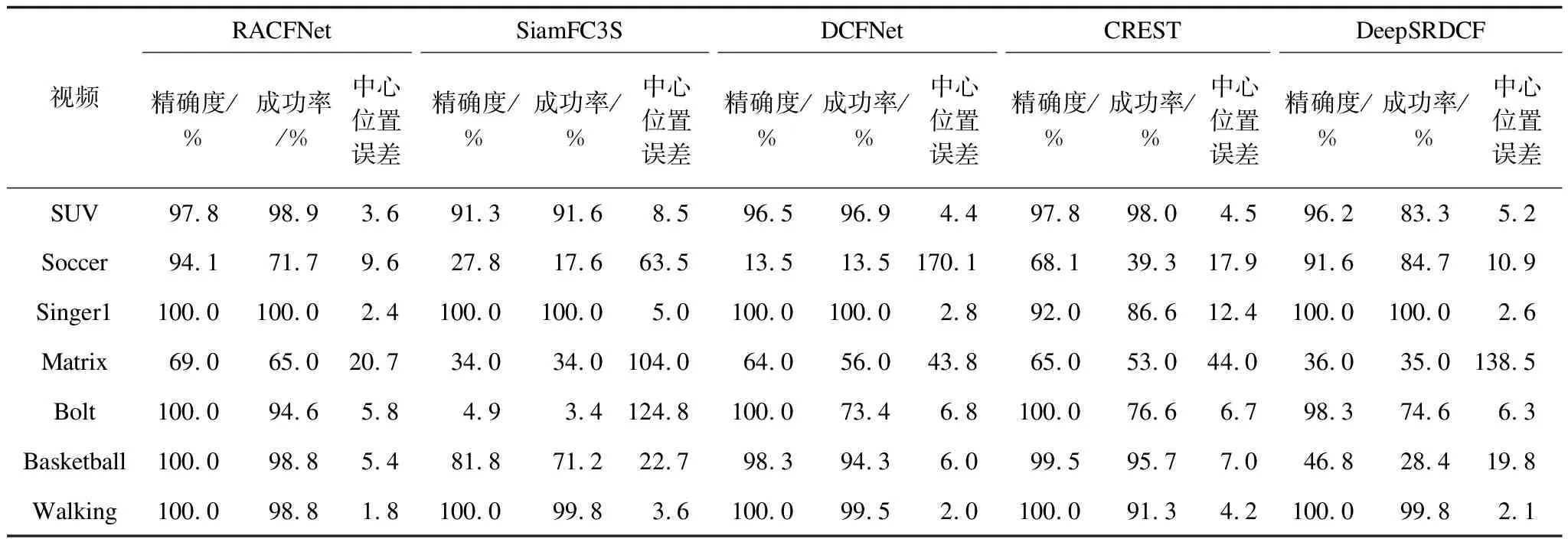
表1 针对不同视频的目标跟踪性能对比
2.4 不同干扰下的实验结果对比
表2显示了不同算法在不同干扰因素下的目标跟踪结果。可以看出,在精确率和成功率方面,本文算法在5种算法中综合表现最好,除了运动模糊和低分辨率情况下成功率值排名第二,其他成功率值均排名第一。而在运动模糊方面,从精确率的比较可以看出,本文算法比基准DCFNet算法提高了16.5个百分点。从上述实验结果可以看出,本文算法通过加入高级语义特征和通道与空间残差注意力机制,在面对不同干扰环境时较其他算法鲁棒性更强。
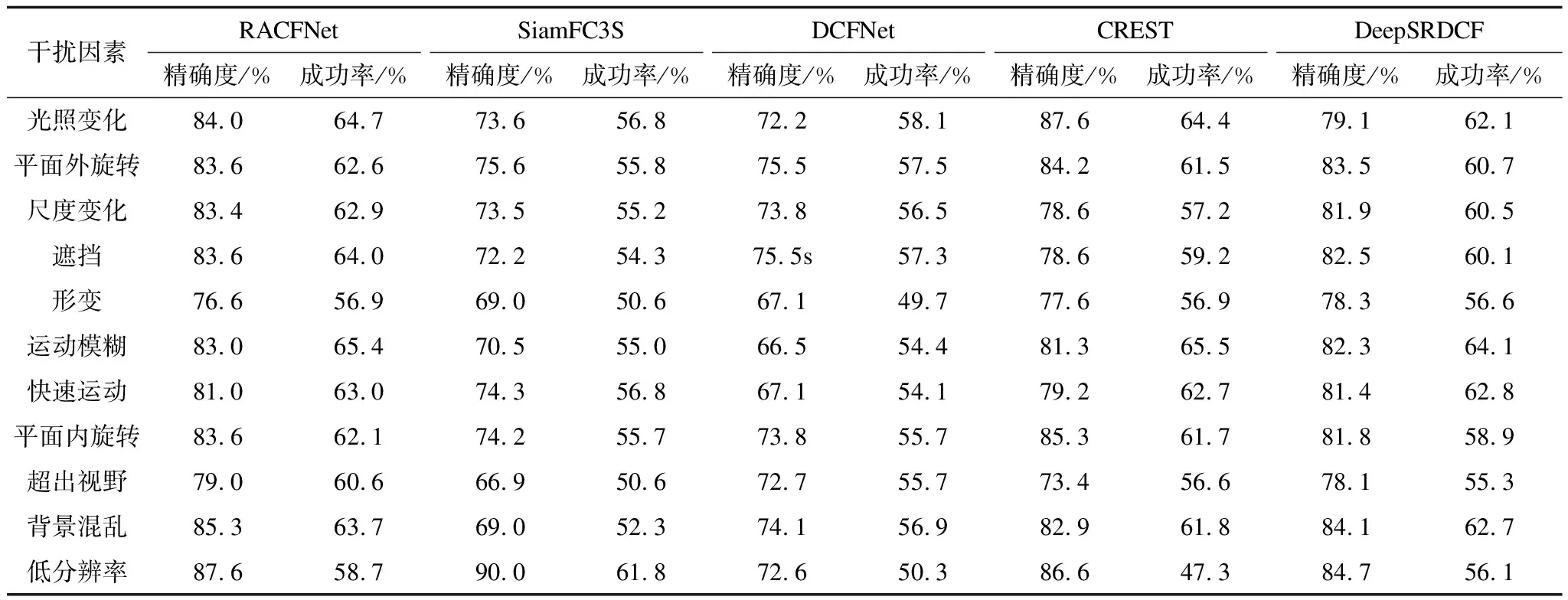
表2 不同干扰下的目标跟踪结果对比
2.5 跟踪速度对比
表3列出不同算法在部分视频跟踪速度结果,本文算法RACFNet在7组视频中表现得最好,以SUV视频为例,本文算法设计的端到端轻量级相关滤波网络结构,算法运行时间少,平均速度达到97.2帧/s,SiamFC3S采用离线训练相似匹配的网络,计算量低,平均速度为86.2帧/s,以上算法均能达到实时,具有实际场景的迁移应用价值,但SiamFC3S精度表现一般,SRDCF[10]通过空间正则化来抑制边界效应的影响。这样增加了参数量,平均速度为3.2帧/s,DeepSRDCF[11]在SRDCF的基础上采用了深度的特征,这样特征提取也损耗时间,跟踪平均速度为0.2帧/s,不能满足实时性,难以应用于实际场景。
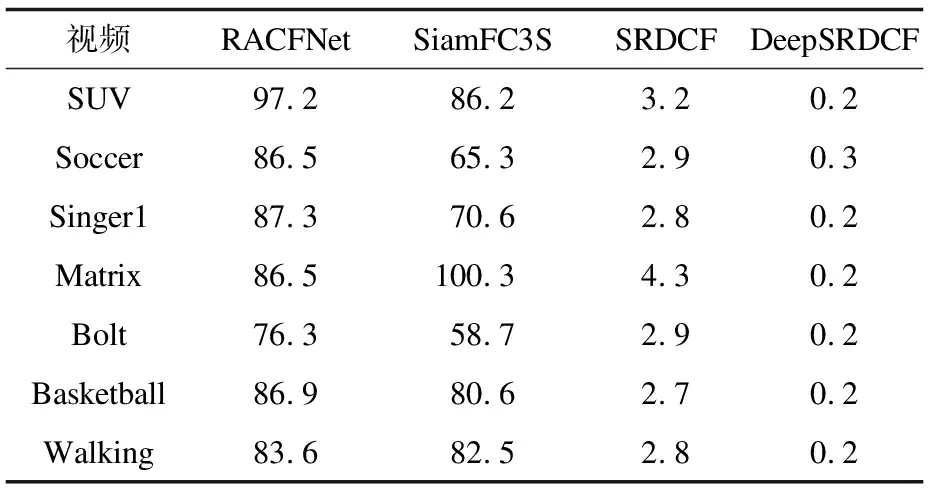
表3 针对不同视频的跟踪速度对比
3 结束语
本文在DCFNet的基础上设计RACFNet网络结构。由EDNet网络得到高级语义信息并作为原低级信息的补充,分别利用通道和空间残差注意力机制自适应选择重要目标进行特征学习,从而减小边界效应的影响,去除冗余的特征信息。在DCFNet中采用低级特征同时结合高级语义信息,体现出目标的高层和底层空间信息,并且使浅层特征的语义信息得到增强。实验结果表明,RACFNet的OPE成功率较DCFNet提高6.2个百分点,在满足跟踪高精度要求的同时,平均速度达到92帧/s,符合实时性要求。下一步将优化本文设计,提高其在目标形变和超出视野干扰下的跟踪性能。
猜你喜欢
当代水产(2022年6期)2022-06-29
中国生殖健康(2020年8期)2021-01-18
开放教育研究(2020年2期)2020-03-31
电子制作(2019年11期)2019-07-04
中国生殖健康(2018年3期)2018-11-06
电子制作(2018年16期)2018-09-26
中国修辞(2017年0期)2017-01-31
系统工程与电子技术(2016年7期)2016-08-21
中国社会历史评论(2016年2期)2016-06-27
长江学术(2016年4期)2016-03-11
