
一种基于连接关键词的实用化可搜索加密方案
2020-02-19 11:26骆云鹏朱旎彤毛慈伟程晋雪许春根
计算机工程 2020年2期
骆云鹏,朱旎彤,毛慈伟,程晋雪,许春根
(南京理工大学 理学院,南京 210094)
0 概述
云存储技术能为数据提供巨大的存储空间,且其使用较为便捷,因此,得到了研究人员的广泛关注。然而,云数据通常以明文形式存储,因此,其安全性难以得到保证。近年来,云数据泄露事件不断发生,其中多数是由于黑客的非法入侵和云端服务器管理员的不当操作而导致。例如,2011年Sony公司被黑客入侵导致上亿用户资料外泄。
为了更好地解决海量数据的安全存储与检索问题,可搜索加密技术[1]应运而生,其目标是在不影响数据检索功能的前提下,保护用户外包数据的安全性与查询隐私。可搜索加密技术的基本应用过程为:用户加密自己的数据并上传到远程服务器,在需要检索文件时提交其关键词的陷门给服务器,随后服务器使用陷门检索到密文并返回给用户,整个过程中服务器将不会获取关于密文与其关键词的任何信息。
可搜索加密能够很好地保护用户外包数据的机密性,同时使得加密数据的高效搜索成为可能,即具有很好的扩展性。文献[2-3]提出对称可搜索加密方案并进行进一步完善。文献[4]提出基于公钥的可搜索加密协议,其利用基于身份的加密设计了公钥可搜索加密方案。公钥可搜索加密方案允许多个用户利用公钥进行加密,仅拥有相应私钥的用户才可以搜索加密的数据。文献[5-6]利用双线性对分别构造了基于连接关键词的可搜索加密方案BLL和RT,2种方案的特点都是关键词陷门大小固定,但是判断每个文档时都需要计算2次双线性对。文献[7]提出了在非结构文本上的基于连接关键词的可搜索加密方案FK,其在搜索加密文档时无需指定关键词的位置。为了更接近实际中的搜索情况,文献[8]利用词典和关键词间的编辑距离,提出了一个基于模糊关键词的可搜索加密方案,其在关键词拼写错误或格式不一致的情况下也能搜索出正确的密文。此外,文献[9-10]提出了其他具有特殊功能的基于多关键词的可搜索加密方案,扩展了多关键词可搜索加密的应用范围。
本文提出一种基于连接关键词的可搜索加密方案,并通过Java编程语言实现该方案,以验证其加密性能。
1 基础知识
1.1 双线性映射
设p为素数,令G1、G2是p阶循环群,若映射e:G1×G1→G2满足以下性质,则称e为一个双线性映射:

2)非退化性(non-degenerate):如果P是G1的生成元,则e(P,P)是G2的生成元。
3)可计算性(computable):对于任意的P,Q∈G1,存在多项式时间算法计算e(P,Q)。
1.2 方案的困难性假设

Pr[A(P,xP,x2P,…,xqP)=e(P,P)1/x]≥ε
2 基于连接关键词的可搜索加密方案
2.1 系统描述

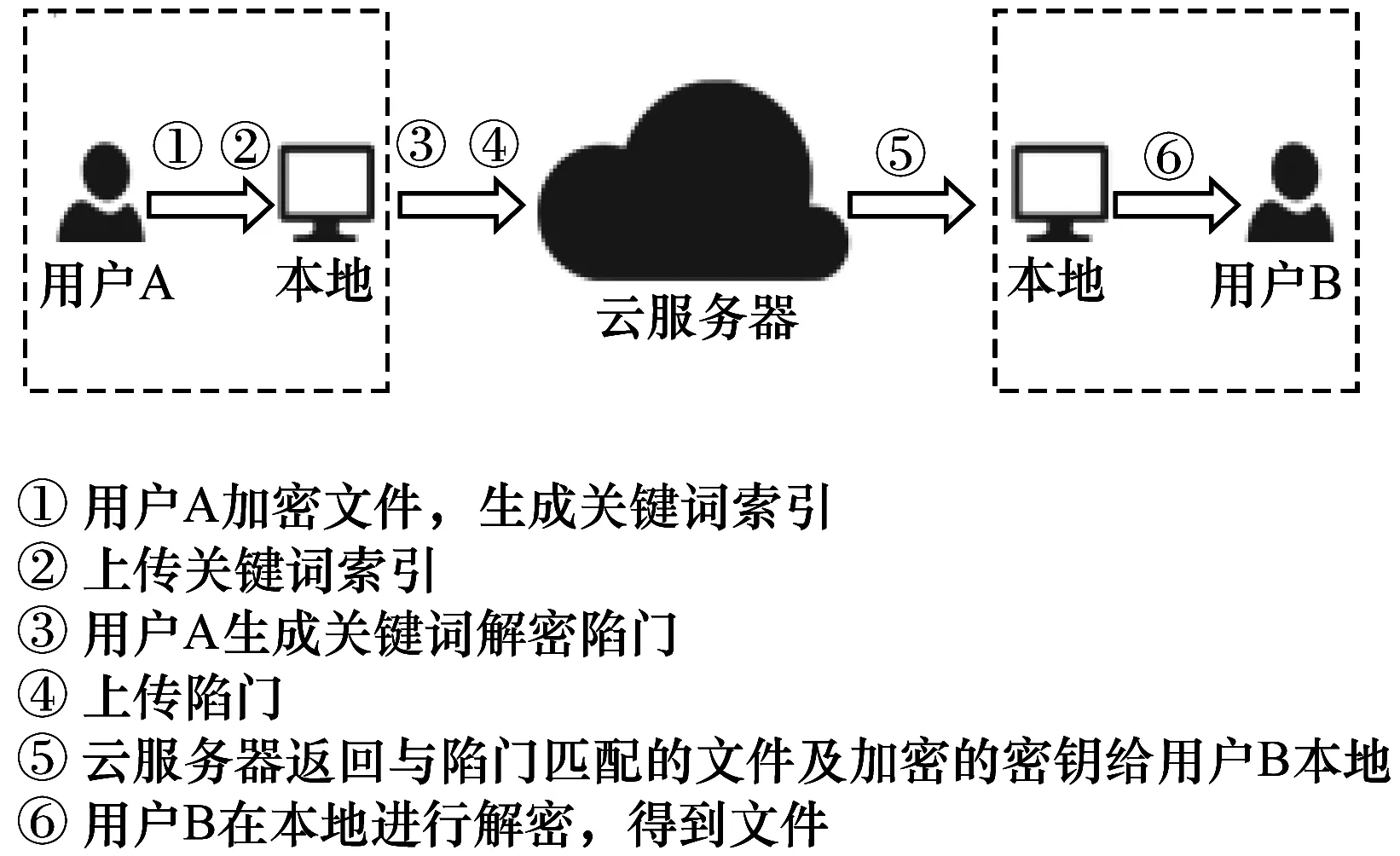
图1 可搜索加密方案应用过程
2.2 算法定义
基于连接关键词的可搜索加密方案由以下6个多项式时间算法组成:
KeyGen(1k):为概率算法,输入安全参数k,生成一个公私钥对(Apub,Apriv)。
Encrypt(Apub,D):为用户执行的加密算法,输入公钥Apub和文件M,输出密文C。
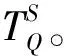


2.3 安全性模型
初始化利用KeyGen(1k)算法产生私钥Apriv并将其发送给攻击者。
阶段1适应性询问阶段:



挑战攻击者向挑战者提交挑战文件D0=(M0,H0)和D1=(M1,H1)。其限制为:在阶段1中,D0和D1在搜索陷门询问阶段未被询问,且Qi与H0和H1的匹配情况在解密陷门询问阶段未被询问,同时
猜测攻击者输出b′∈{0,1},当b′=b时,攻击者获胜。
本文定义攻击者A在攻击基于连接关键词的可搜索加密模型时的优势为:
Advε,A(1k)=|Pr[b=b′]-1/2|
3 算法构造
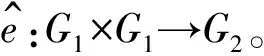


(1)
如果式(1)等式成立,则输出Yes;否则,输出No。

(2)
如果式(2)等式成立,则输出E,Enc(sk,PB);否则,输出⊥。
式(1)的数学证明如下:
如果WIi=Ωi,有:
式(2)的数学证明如下,有:
如果WIi=Ωi,有:

H3(M‖B1‖B2‖…‖Bm,sk)=r0
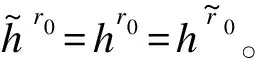
4 安全性分析
本文通过建立一个随机预言机模型[13]进行选择密文攻击,采用规约化思想将安全性问题规约为求解q-BDH问题,以证明本文方案具有选择密文攻击下的密文不可区分性(IND-CCA)。挑战者通过预言机得到的密文D0和D1不会泄露文件0和文件1是否包含相同关键词,即敌手无法通过获得的陷门查询到含相同关键词的其他文件。
定理1如果q-BDH问题在群G1难解,则本文可搜索加密方案具有选择密文攻击下的密文不可区分性(IND-CCA)。
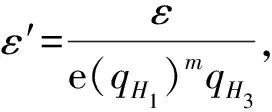
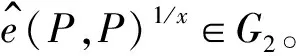

H1查询敌手A向随机预言机H1发出查询请求,为了响应这个请求,B初始化一个空的三元组
1)如果查询Wi出现在H1表中,B回复H1(Wi)=hi。
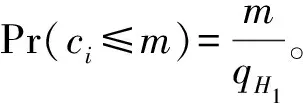
3)如果ci>m,B选择一个随机数hi∈{0,1}lb p,否则,hi=βci。
4)B将
H2查询敌手A向随机预言机H2发出查询请求,为了响应这个请求,B需要初始化一个空的二元组
1)如果查询gi出现在H2表中,B回复H2(gi)=γi。
2)否则,B随机生成一个γi∈{0,1}lb p,并将
H3查询敌手A向随机预言机H3发出查询请求。为了响应这个请求,B初始化一个空的多元组
1)如果查询Mi‖Bi,1‖Bi,2‖…‖Bi,m和ski已经出现在H2表中,B回复H3(Mi‖Bi,1‖Bi,2‖…‖Bi,m,ski)=roi。

表1 Hash算法说明
挑战者与攻击者之间的攻击游戏如下:
阶段1A提出查询qi,且qi是以下查询中的一种:
1)ST查询:当A发起Qi=(Ii,1,Ii,2,…,Ii,ti,Ωi,1,Ωi,2,…,Ωi.ti)查询搜索陷门,B进行如下操作:
(1)B模拟H1查询获得hi,j,hi,j=H1(Ωi,j),找到<Ωi,j,hi,j,ci,j>对应表中的多元组,如果∀j,ci,j=Ii,j,则B失败,即不能找到含相同关键词的组。
(2)否则,B定义Ji=sIi,1+sIi,2+…+sIi,ti+hi,1+…+hi,ti=Γix+Δi,其中,Γi=αIi,1+αIi,2+…+αIi,ti,Δi=-(βIi,1+βIi,2+…+βIi,ti)+(hi,1+hi,2+…+hi,ti)。
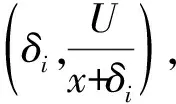
2)DT查询:当A发起Qi=(Ii,1,Ii,2,…,Ii,ti,Ωi,1,Ωi,2,…,Ωi.ti)查询解密陷门,B进行如下操作:
(1)B模拟H1查询获得hi,j,hi,j=H1(Ωi,j),找到<Ωi,j,hi,j,ci,j>对应表中的多元组,如果∀j,ci,j=Ii,j,则B失败,即不能找到含相同关键词的组。
(2)否则,B定义Ji=SIi,1+SIi,2+…+SIi,ti+hi,1+hi,2+…+hi,ti=Γix+Δi,其中,Γi=αIi,1+αIi,2+…+αIi,ti,Δi=-(βIi,1+βIi,2+…+βIi,ti)+(hi,1+hi,2+…+hi,ti)。

挑战者A输出2个文件D0=(M0,H0)和D1=(M1,H1),并发送给B。B进行如下操作:
1)B执行上述算法,通过回复H1查询来获得hi,j,hi,j=H1(Wi,j),i∈{0,1},1≤j≤m。将
2)B取i=0或1,使得∀j,ci,j=j。
阶段2B重复阶段1的操作获得它所输入关键词的陷门,其中有一个限制为:C未被询问过,即未对D0和D1进行过陷门查询和解密查询。
最终,A会给出判断结果,表明B给出的挑战C是否为D0或D1的密文。
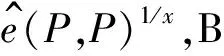
5 应用方案
根据算法过程,本文实现了服务器与客户端一对多的交互型可搜索加密云存储系统[14],将可搜索加密方案划分到服务器和客户端2个部分,通过交互实现文件的存取和共享[15]。
5.1 控制台算法的分析与实现
为进行算法效率测试,需实现一个控制台算法,从而避免在真实场景下网络与文件的读写影响算法的实际运行时间。本文借助Java的JPBC库来实现控制台算法[16],工具函数的说明如下:
1)字符串处理函数:算法在具体描述中,关键词以比特串形式存在,因此,需要将关键词编码成比特串。本文编码方案先取出字符串中每个字符的Ascii码,将其转化为8位比特串,将每个字符串的比特串拼接得到字符串的比特串标识,上述过程可逆。
2)哈希函数选择:算法中需要H1、H2、H33个哈希函数,程序选择MD5消息摘要算法作为H1、H3,SHA1数字签名算法作为H2。H3的输入由比特串和对称加密密钥的比特串拼接构成。
参数设置:有限域的阶数为512比特位,群的阶数为128比特位。
控制台算法运行结果如图2所示。其中,H2=S说明STrapdoor匹配成功,origin_sk=get_sk表明DTrapdoor匹配成功并解密出正确密钥。
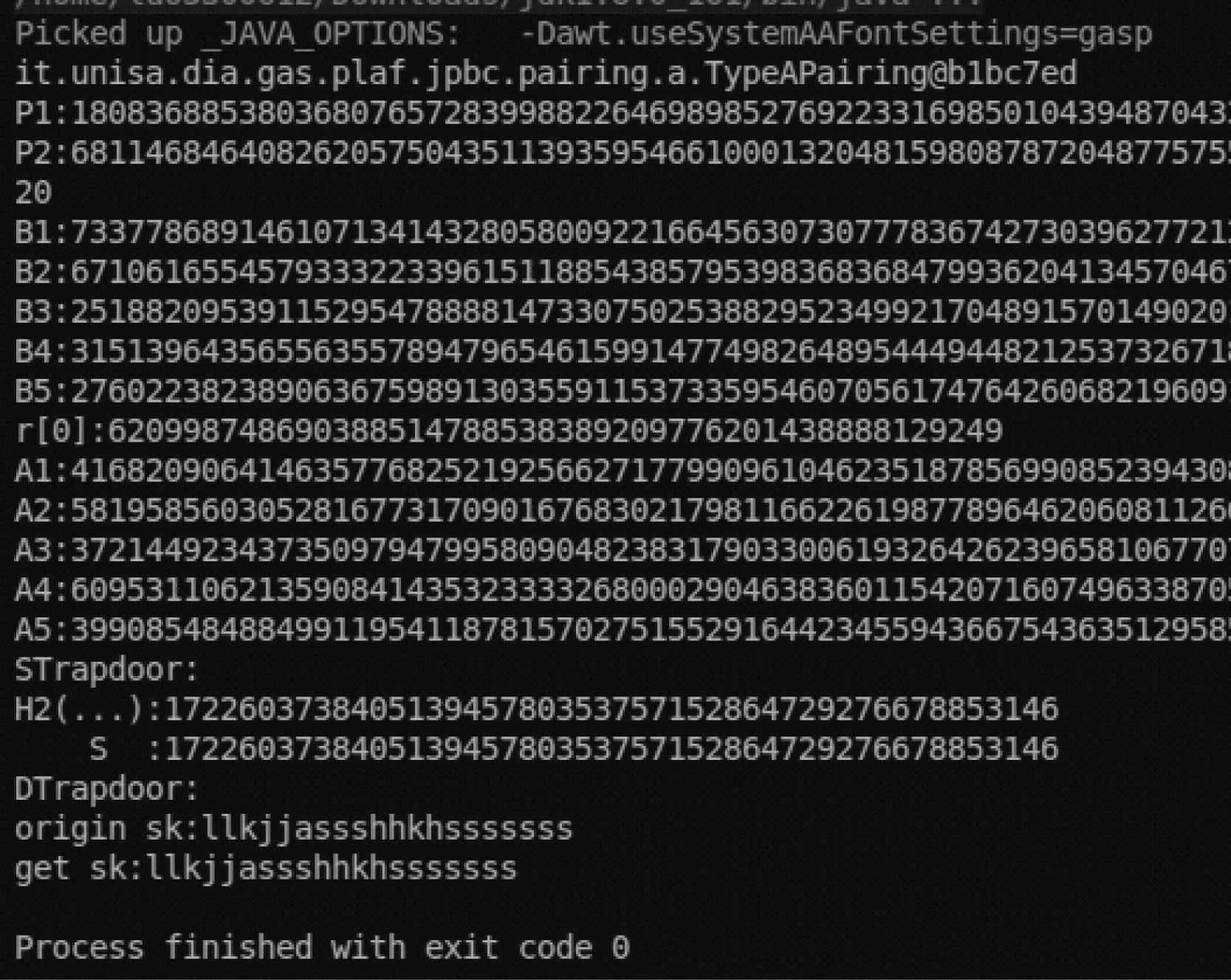
图2 控制台算法运行结果
5.2 服务器-客户端的分析与实现
将可搜索加密方案分离到服务器与客户端2个部分[17],服务器交互界面如图3所示,客户端工具界面如图4所示。
图3 服务器交互界面

图4 客户端工具界面
方案步骤说明如下:
1)文件的加密方式:采用AES128加密算法进行加密。
2)代数结构与元素的存储方式:不同于控制台程序,服务端和客户端不再共享变量,因此,所有的群元素、群结构需要编码成某种形式并传送给服务器,本文将群元素编码成byte数组进行传输,将群结构以Java配置文件.properties形式存取。
3)本地索引:算法本身能够实现连接查询,但是需要用户自行记忆关键词在文件中的位置,这对用户不够友好,因此,通过生成本地关键词索引,实现用户本地的预查询,这样可以避免记忆关键词位置,同时也可以实现否定查询。
4)密钥封装:由于用户无需记忆AES128的密钥,因此为了简化程序过程,通过群元素生成AES128密钥,这样避免了将密钥编码成椭圆曲线上的点的繁琐步骤,同时对安全性没有任何影响。
5)密钥存储:自存自取的文件密钥均存储在本地,本地工具默认对不同文件使用不同的密钥,保证某个用户分享文件后,分享对象不会获得解密该用户所有文件的能力。
6)一对多分享设计:在本文算法步骤中,同时分享文件给多个用户是不冲突的,通过输入其他用户的公钥集合,程序针对每个公钥生成一个私钥,从而方便一对多的分享过程,且相比于单一分享模式,一对多分享需要的额外存储空间可以忽略不计。
7)文件存取等步骤的简化:用户查询到的文件和公钥一般是多个,本文方案能够对多个文件同时进行解密而非逐个解密,对公钥集合进行统一上传而无需逐个上传。
5.3 效率分析
本节分析方案的效率,用m、P、E、H和n分别代表关键词个数、一次双线性运算的复杂度、一次指数运算的复杂度、哈希运算和其他运算,p代表Zp的阶数。本文方案与其他方案进行效率比较[18],结果如表2所示。算法运行环境是Linux deepin15.5,Intel(R)Core(TM)i7-7700HQ,8 GB内存,语言为Java 8。

表2 各加密方案的效率对比
由于文件及其索引均以密文形式存储在云端,因此文件与文件之间、索引与索引之间都具有不可区分性,无法进行排序,这使得在陷门匹配的过程中,陷门需要通过顺序查找与所有文件索引一一匹配,算法复杂度为O(n),其中,每一步都包含了2次双线性配对。在效率分析时,本文不再考虑文件加密、密钥生成、密钥解密、文件解密过程中所消耗的时间,原因是它们的时间相比于陷门匹配可忽略不计。
针对不同的关键词个数,分别比较本文方案和基于PEKS的连接关键词方案(简称PEKS方案)在密文生成、陷门生成和单个文件匹配上的时间,结果如图5~图7所示。在图7中,worst是最长匹配时间,即全部关键词匹配成功的时间,best是最短匹配时间,即在第一个关键词就匹配失败的时间,average是平均匹配时间。可以看出,本文方案与对比方案在密文生成上的效率相当,而在陷门生成和文件匹配时,由于对比方案以及多数方案[4,19]中采用决策树来实现连接关键词搜索,需要生成多个陷门并进行多次匹配,因此所需时间随着关键词个数的增多而显著提高,而本文方案仅需单陷门单次匹配,因此,其陷门生成和匹配时间复杂度与关键词无关,由结果可见,本文方案在保证密文生成效率的同时,大幅提高了连接关键词的搜索效率。
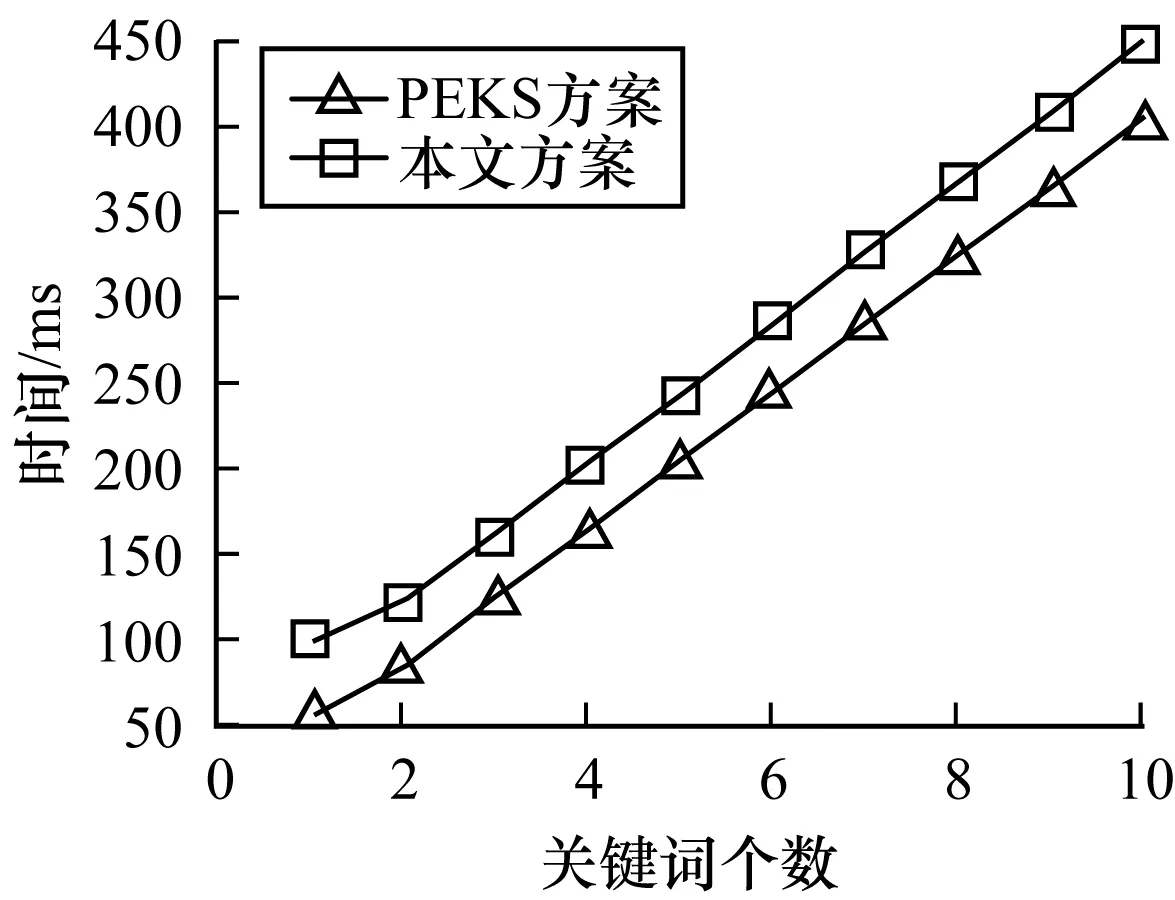
图5 2种方案密文生成效率对比
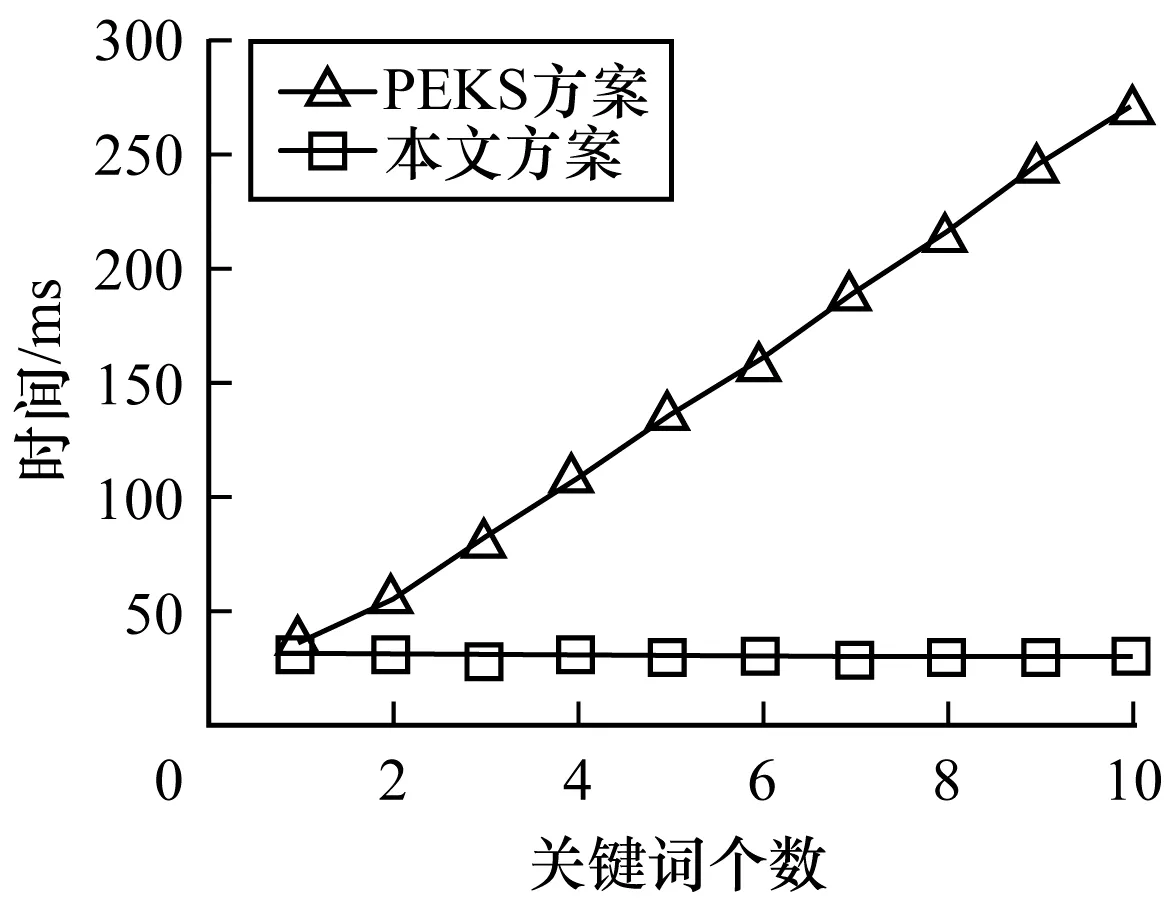
图6 2种方案陷门生成效率对比

图7 2种方案单个文件匹配效率对比
6 结束语
本文提出一种基于连接关键词的可搜索加密方案,安全性证明结果显示,破译该方案的难度高于求解BDH问题。考虑到记忆关键词位置时存在一定难度,本文制作一个索引作为单关键词文件并加密上传,用户可通过解密获得关键词位置信息,方便其进行文件查询。此外,该方案在不泄露私钥的前提下可以完成与他人的文件共享。但是,本文方案中多个关键词使用单个陷门,下一步将针对方案中可能存在的哈希碰撞问题进行研究并提出解决方案。
猜你喜欢
黑龙江大学自然科学学报(2022年1期)2022-03-29
故事作文·低年级(2022年1期)2022-02-03
计算机仿真(2021年10期)2021-11-19
阅读(快乐英语高年级)(2021年4期)2021-07-11
少先队活动(2020年9期)2020-12-17
北京电子科技学院学报(2020年2期)2020-11-20
阅读(快乐英语高年级)(2020年10期)2020-01-08
小型微型计算机系统(2018年9期)2018-10-26
信息安全研究(2018年1期)2018-02-07
通信技术(2016年10期)2016-11-12
