
一种可实现高精度时间同步的数据传输方法
2020-02-19 11:26:38杨冯帆常劲帆
计算机工程 2020年2期
杨冯帆,常劲帆,王 铮
(1.中国科学院高能物理研究所 核探测与核电子学国家重点实验室,北京 100049;2.中国科学院大学 物理科学学院,北京 100049)
0 概述
高海拔宇宙线观测站(Large High Altitude Air Shower Observatory,LHAASO)是在我国四川稻城平均海拔4 410 m地区建设的以宇宙线观测研究为核心目标的重大科技基础设施[1],是“十二五”国家重大科技基础设施项目之一。该项目的科学目标是探索高能宇宙线起源并开展相关的高能辐射、天体演化甚至暗物质分布等基础科学研究[2]。KM2A探测器阵列是LHAASO的主体阵列之一,包括5 242个电磁粒子探测器(Electromagnetic particle Detectors,ED)和1 171个缪子探测器(Muon Detectors,MD)。ED按15 m间隔,MD按30 m间隔,平均分布在1.3 km2的野外区域。
在大面积的天体物理实验中,前端电子学需要测量宇宙线次级粒子击中不同探测器间相对时间差优于1 ns,并将数字化后的数据可靠地送往数据获取中心。为此,本文提出一种可实现高精度时间同步的数据传输方法,将数据传输和时钟传输链路复用,以满足KM2A读出电子学系统对于数据传输可靠性和时间同步精度的高要求。
1 KM2A电子学设计方案
KM2A读出电子学采用无全局硬件触发的前端数字化方案,PMT产生的信号通过短电缆送入电子学[3],如图1所示。ED单通道平均事例率2 kHz,事例数据宽度176 bit,每个探测器所需传输带宽为352 kb/s[4];MD单通道事例数据宽度216 bit,平均事例率10 kHz,除此之外,每秒还需上传一个8 KB的波形包,所以每个MD探测器所需的平均传输带宽为2.2 Mb/s[5]。

图1 KM2A电子学布局方案
目前实现大范围时钟分配系统的方法大体分为基于无线电波[6]、基于专用链路和基于以太网,如表1所示。基于无线电波能达到纳秒量级的授时精度[7],基于专用链路可以实现亚纳秒量级的授时精度[8],但是两者的实现成本过高,不适合大规模使用。LHAASO实验采用由CERN开发的WR(White Rabbit)高精度时钟同步协议(WRPTP)。WRPTP协议能够通过光纤网络实现支持范围达数百平方千米、最大节点数量过万的高精度时钟分配系统,授时精度达到亚纳秒量级[9]。
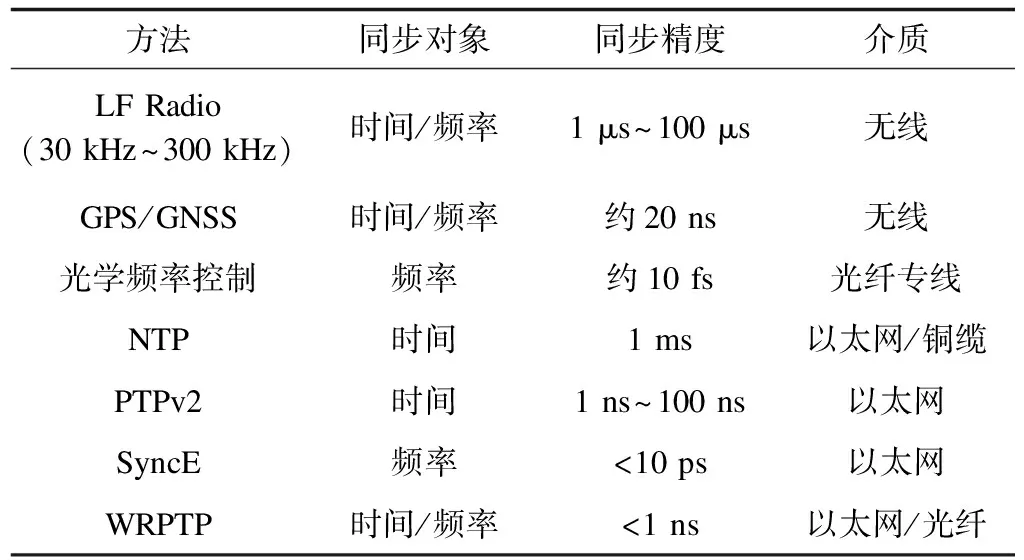
表1 时钟分配系统的主要实现方法
WR技术是基于同步以太网来实现分布式高精度时间同步,因此每个前端读出的电子学板数据可以通过WR网络进行传输。显然,数据传输和时钟传输链路复用降低了系统复杂度、系统建设及维护成本,提高了可靠性,从成本角度来讲是较经济实用的设计方案。
由于WR时钟同步技术只是通过标准以太网来传输时钟同步协议,在数据传输方面,根据OSI的7层协议体系结构,WR实现了千兆以太网物理层和链路层,通过WR时钟同步网络进行数据传输,还需要高层协议配合工作。本文采用基于TCP/IP的以太网传输方案,通过TCP协议[10]采取多重机制确保数据传输的可靠性,同时其通用性也易于后端的数据获取,满足LHAASO工程的需求。利用FPGA实现TCP/IP协议栈的第一种方法是在FPGA内集成软核,如在WCDA子系统中使用此方法[11];第二种方法是用硬件描述语言HDL编写,但是算法复杂且常见IP核均为收费,如日本高能加速器研究机构KEK设计的以太网协议栈SiTCP[12]。考虑到KM2A有近7 000个节点,因此数据传输部分不能占据FPGA内部过多的逻辑资源,可将WR时钟同步逻辑和探测器数据的处理、打包和传输逻辑集成在一片FPGA内,若更换层次较高的FPGA会增加电子学的成本,给项目带来额外支出。若利用硬件描述语言进行开发,则具有资源利用少、可移植性强、便于扩展和维护的优点,因此本文使用硬件描述语言开发协议栈。
2 WR时钟同步技术
IEEE-1588协议又称PTP协议,旨在实现微秒到亚纳秒的同步准确度。2008年,IEEE推出了修订版本,即PTPv2。PTPv2采用定时链路与数据链路复用的方式,提高链路利用率。同时,其也是一种主从结构的时钟同步系统,即同步过程中需要先选定一个主站,然后从站的本地时钟根据收到的主站同步报文计算时间延迟,同步过程[13]如图2所示。

图2 PTPv2同步报文交换过程
PTPv2同步报文交换过程具体如下:
1)t1时刻,主站发送Sync报文到从站,从站记录收到该报文的t2时刻。
2)主站将时间戳t1嵌入Follow_up报文中,并发送至从站。
3)从站发送Delay_Req报文至主站,并记录发送时刻t3。
4)主站记录收到Delay_Req报文的时刻t4,并将其嵌入Delay_Resp报文,发送至从站。
从站根据这4个时间戳计算出链路传输延时和主从时钟的偏差,对本地时钟进行补偿。链路往返延迟为:
dround_trip=(t4-t1)-(t3-t2)
(1)
假设链路完全对称,即主到从t-ms和从到主t-sm时间相等,则单向的传输延时为:
(2)
主从时钟的偏差为:
(3)
然而PTPv2仍然存在一些限制,影响其授时精度:
1)主从时间差受限于时间戳的精度,以千兆以太网为例,其时钟频率为125 MHz,时间戳精度只能达到8 ns。
2)主从站的时钟为单独运行,各自振荡器存在一定偏差,因此需要增加发送同步报文的频率,以便及时进行补偿,但是这会给通信带来负荷。
3)PTPv2将链路等效为对称链路,而实际链路中存在诸多不对称性,影响同步效果。
CERN的工程师们提出了完全兼容PTPv2协议的WRPTP协议,通过增加物理层对同步以太网的支持、时钟相位测量和WR同步链路模型解决以上问题。
2.1 同步以太网
对于标准以太网,各节点均对等且独立运行,而对于同步以太网,各节点构成一个树形的时钟网络拓扑结构,如图3所示[14]。树形网络的根节点作为整个网络的频率源,子节点通过数据时钟恢复(Clock and Data Recovery,CDR)技术,从根节点发送过来的数据流中恢复出同频时钟,使得整个网络所有设备的频率均与根节点保持同步。

图3 标准以太网和同步以太网拓扑结构
2.2 数字双混频鉴相器
图4为WR数字双混频鉴相器工作原理[14],clkA和clkB分别代表本地时钟和数据流中的恢复时钟,它们之间的频率相同但相位有差异。

图4 数字双混频鉴相器工作原理
为测量相位差,引入外部锁相环产生的辅助时钟信号fPLL,该时钟信号与被测信号clkA和clkB有较小的差异:
(4)
通过测量D触发器输出信号的相位差就可计算出被测信号的相位差:
(5)
其中,pDMTD是D触发器输出信号的相位差,即被测相位差的时间分辨提高至N+1倍。
2.3 WR同步链路模型
WR技术采用单光纤复用方法进行传输,WR同步链路模型[14]包括主设备(Master)、光纤链路(Link)和从设备(Slave),如图5所示。链路总延时包括主从设备的发送延时ΔTXM、ΔTXS和接收延时ΔRXM、ΔRXS,光纤链路的传输延时为δMS、δSM。

图5 WR同步链路模型
光纤对不同波长光的折射率不同,导致δMS和δSM有差异,WR定义光纤不对称系数α描述δMS和δSM的关系:
(6)
根据相对标定法确定ΔTXM、ΔTXS、ΔRXM、ΔRXS和α值,在实际应用时无需再次标定。由WR标定手册[15]的公式推导可知,WR技术能实现标定后的设备优于1 ns的同步准确度[16]。
3 WR时钟同步网络
WR时钟同步网络由时钟频率源、WR交换网和授时节点三部分组成,采用树形拓扑结构[14](如图6所示),其中,时钟频率源为根节点,授时节点为叶节点。
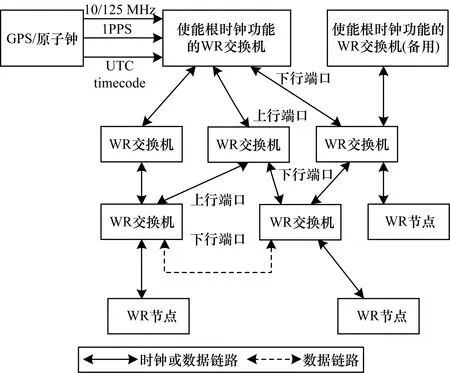
图6 WR时钟同步网络的拓扑结构
WR交换网由若干WR交换机(WR Switch,WRS)组成,每台WRS共有18个端口,分为两类:端口1为上行端口,端口2~18为下行端口。WRS可以根据具体应用的需求,通过上行端口与上级WR交换机级联,实现与上级WRS同步,通过下行端口对下级设备进行授时。时钟频率源由GPS授时设备、原子钟和具有使能根时钟功能的WRS组成,借助GPS和原子钟、WRS与UTC进行时间同步,即整个时钟网络的节点可以获得绝对时间。对于无需绝对时间或是同步精度不高的应用,可以省略这两部分。
授时节点是时钟分配系统的授时终端,能够从WR时钟网络内部获得高精度的同步时钟。在大型物理实验中,前端电子学还要完成对探测器信号的读取、配置等功能。WR虽然提供板卡来完成高精度时钟的同步功能,但是会增加电子学的成本。因此,LHAASO KM2A采取将WR逻辑和用户逻辑集成在同一片FPGA的方法,降低了大规模使用WR设备时的开销。在数据传输方面,WR技术仅支持千兆以太网物理层和链路层,其他高层协议需用户自行开发。因此,本文在WR的基础上开发了一套利用硬件描述编写的TCP/IP协议栈,实现数据网络与时钟网络的复用。
4 基于WRPC的TCP/IP协议栈
在网络所使用的各种协议中经常提及的TCP/IP不一定单指这两个协议,而表示整个因特网使用的TCP/IP协议族[17]。在通常情况下,TCP/IP被认为是一个4层协议系统,包括链路层、网络层、运输层和应用层[10],如图7所示。TCP/IP是一个开放性的通信协议规范,即使计算机之间有不同的物理特性或运行着不同的操作系统,也可以通过此协议来完成数据交换。

图7 TCP/IP协议族的层次结构
标准TCP/IP协议栈内容复杂,因为任何一个终端要与其他节点在各种各样的网络形式中通信,都需要不同的控制协议。但是对于LHAASO实验,每个电子学板具有独立的IP地址,通过WR交换机进行连接,形成一个封闭的本地网络,其网络形式比较简单。数据传输的目的主要是将每个电子学板的数据高效可靠地传输给后端DAQ系统,数据网络不需要过多的控制协议,因此可简化协议栈。本文设计精简了标准协议栈,只保留和PC通过Socket通信所必备的协议。
图8为基于WRPC(WR PTP Core)的TCP/IP协议栈框图,包括协议栈主体部分、WRPC和接口逻辑。协议栈主体是整个传输系统中最重要的组成部分,其控制电子学插件和DAQ系统的通信。接口逻辑完成协议栈和WRPC之间的数据转换宽度。
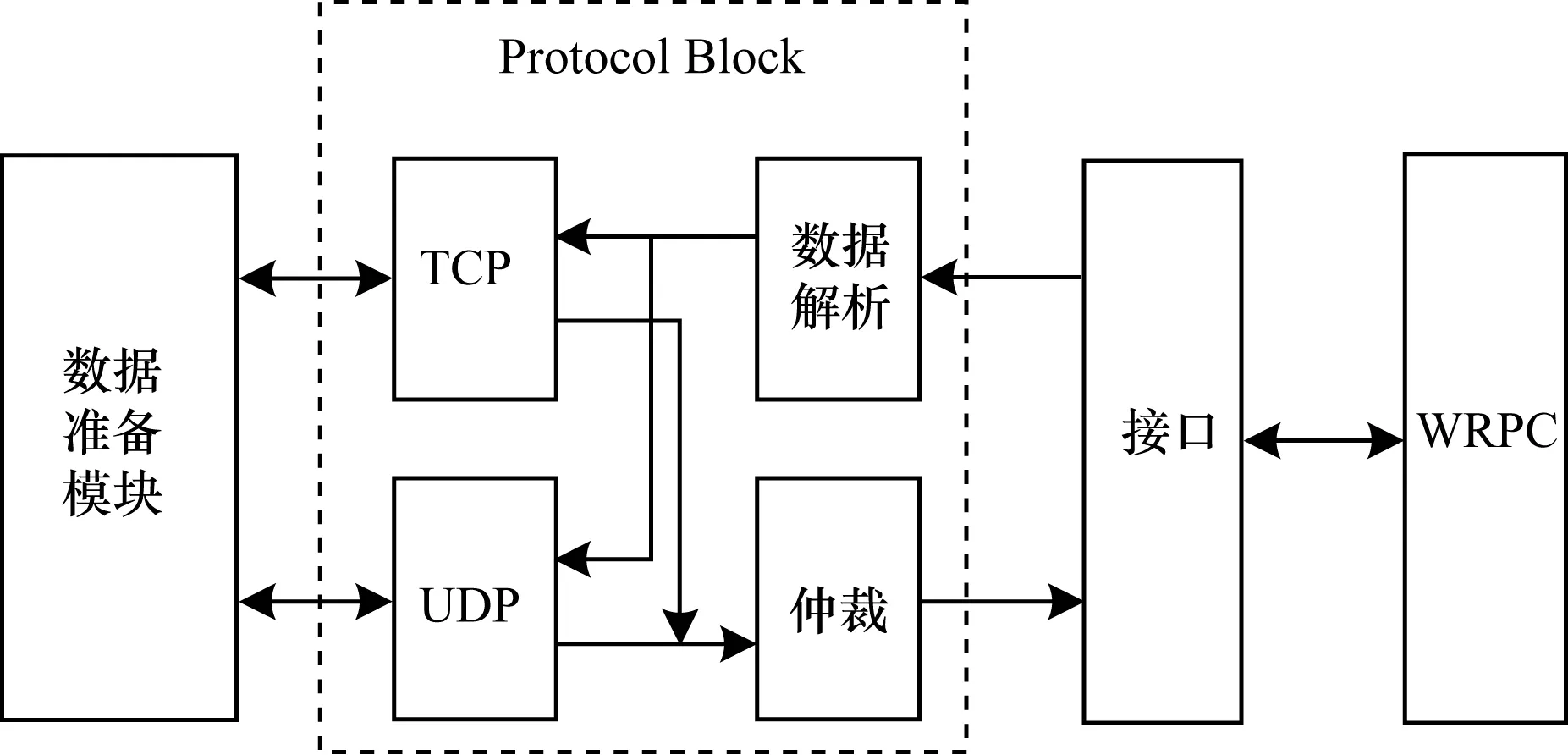
图8 基于WRPC的TCP/IP协议栈框图
4.1 数据解析(Parser)模块
Parser模块需要根据RFC 894[18]的规定解析收到的以太网帧,并按照协议类型字段,将解析出的各字段递交到其他协议模块中。在数据格式解析过程中,需要检查帧的合法性,计算IP、TCP和UDP协议的校验和。此外,Parser需记录每条链路两个端点的相关信息(如表2所示),并将这些信息送往其他协议模块进行后续处理。

表2 Parser模块需解析的链路参数
4.2 TCP模块
TCP[19]模块是协议栈中最重要的模块,图9为TCP模块的逻辑框图,由TCP_FSM、TCP_TXBUF、TCP_RXBUF和Packet Generator 4个子模块构成。
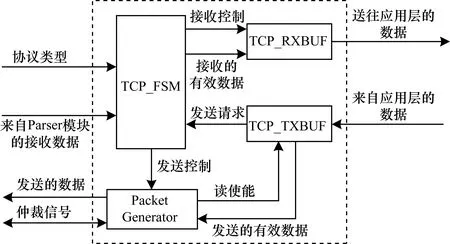
图9 TCP模块逻辑框图
TCP_FSM是TCP模块的核心内容,是一个状态机,完成TCP的状态转换逻辑。图10为TCP/IP协议栈的状态转换图,工作在服务器模式,连接的建立与释放、拥塞控制、数据校验等功能均在此模块控制下完成。在经过Parser模块解析后,将协议类型为TCP的数据发送到该模块,其中只有MAC地址、IP地址、TCP端口号及校验和正确的报文,TCP_FSM模块才进行下一步的解析工作,例如检查标志位(RX_TCP_FLAGS)、确认本报文的含义等。在每次发送一个包后,计时器开启,当ACK收取超时时,TCP_FSM启动自动重传操作;同样,在收到3个相同的ACK时,重传逻辑也会开始工作。
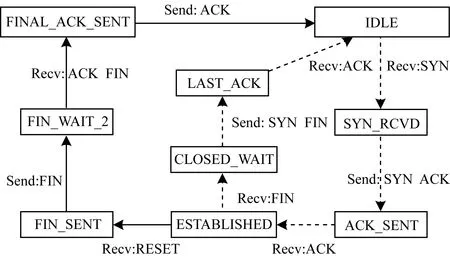
图10 TCP FSM状态转换
TCP_TXBUF的本质为一块RAM,用来缓存本地应用层发送的数据,配置为16 KB、32 KB、64 KB。在CONNECTED_FLAG信号置1时,应用层向缓存内写数据。当缓存满时,外部电路在128个时钟内停止写操作。当缓存内的数据长度超过最大报文长度(Maximum Segment Size,MSS)或是200 μs内没有再向缓存内写数据时,TCP_TXBUF会向TCP_FSM提出发送请求。发送数据的长度取决于接收窗口的大小、MSS和缓存内数据量的最小值。
Packet Generator在收到TCP_FSM的使能信号后,先将Parser[18]模块发送的链路信息锁存,之后按照RFC 894的要求组装以太网帧,添加TCP、IP、Ethernet的各级首部,计算协议首部中校验和字段的内容,并根据仲裁结果发送数据。
TCP_RXBUF模块用于存储经过校验后由其他设备发向本节点的数据,可配置为8 KB、16 KB、32 KB。当缓存非空时,外部电路可以读取缓存内的数据。
对于TCP模块,只有在计算TCP首部的校验和字段时,需要对有效载荷部分进行操作,在组装协议首部时并不会使用其余各层协议的数据。因此,为避免大量数据在组包时移动对协议栈实时性带来影响[20],采取有效载荷和协议首部分别组装的方法,即Packet Generator仅用来组装各级协议的首部,有效载荷缓存在TCP_TXBUF内,在确定发送数据量后,TCP_TXBUF会先计算此部分数据的校验和,之后将有效载荷的长度和校验和发送给Packet Generator,用于TCP首部的组装。
4.3 UDP模块
UDP[21]模块完成UDP协议的功能,图11为UDP模块的系统框图。Parser模块将解析后带有UDP标记的报文输入该模块,进行报文校验。当应用层有数据发送时,将数据封装成UDP用户数据报文。

图11 UDP模块系统框图
本文设计由于面向高能物理实验,为方便配置指令的传输,需简化电子学上电时的寄存器配置方式。配置指令采用UDP协议发送[12],使探测器数据和配置指令相分离。具体的组包格式如图12所示,PC将配置指令按照要求的格式打包发送至协议栈,在Parser模块解析完毕且验证格式正确后,Configuration_Parser对指令含义进行分析,确定PC端所要求执行的操作。操作执行完毕后生成ACK数据,将其封装为UDP格式的报文返回至PC,PC收到报文后即可确认此条指令已发送成功。由于UDP是不可靠的运输层协议,节点发送的确认报文通过UDP传输,也有丢失的可能性,因此PC端应增加计时器,当接收回馈超时后启动指令重传操作。UDP模块为可选模块,在FPGA资源紧张的情况下,可删除UDP模块,仅保留TCP模块并将其作为数据传输通道。
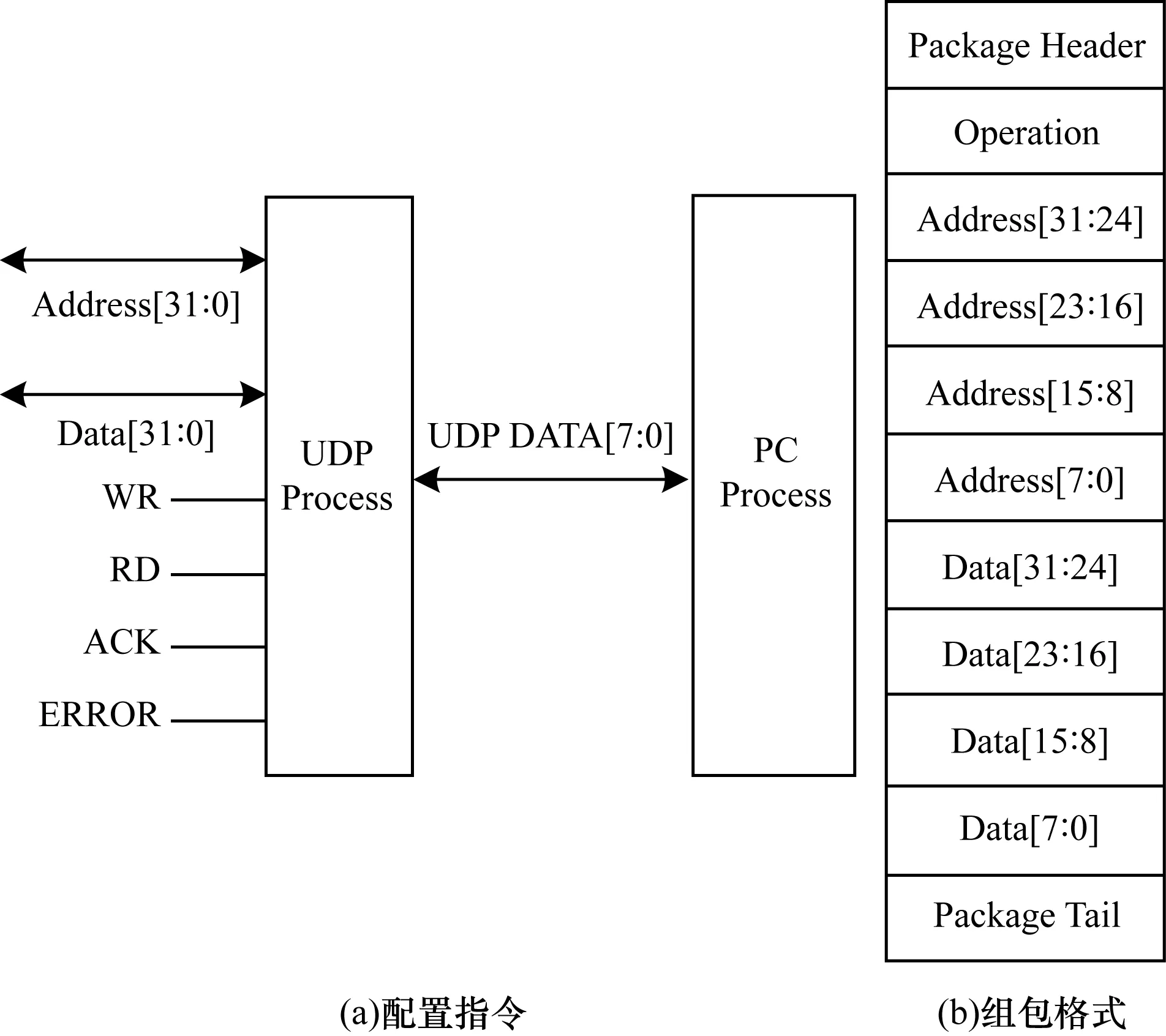
图12 配置指令的组包格式
为避免模块间的冲突,当TCP和UDP同时请求发送数据时,由仲裁模块确定优先工作的模块。
4.4 WRPC实现
时钟同步功能由固件中的WRPC实现[13],此外WRPC也兼容1000Base-Lx数据传输标准,用户定义模块可以通过WR Fabric[22]接口发送和接收以太网帧。WRPC还实现了部分网络层协议,如ARP、ICMP、IGMP[23]。每个时钟周期,WRPC以16 bit传输数据,而协议栈模块以8 bit传输数据,因此需要在协议栈模块与WRPC之间增加一级FIFO进行宽度转换[22],即为图8中的Interface部分。WRPC收到数据后计算FCS,然后通过FPGA的GTP接口发送至WR网络。
5 测试结果
5.1 测试平台搭建
为测试TCP/IP带宽,在实验室内搭建如图13所示的测试平台。

图13 实验室测试平台
ED读出电子学通过四台级联的WRS连接PC。TCP/IP测试程序运行在ED读出电子学插件上,插件和PC分别作为TCP的服务器和客户端。电子学板上只有一片Xilinx Spartan6-100T FPGA,测试逻辑的主时钟为125 MHz。设置TCP/IP协议栈的发送缓存为16 KB,接收缓存是2 KB。测试数据为32 bit循环累加数,上位机通过调整累加间隔,改变测试板上传的数据量。上位机程序运行在CentOS 7系统中,需发送累加间隔指令,读取Socket并检查收到的数据。此外,上位机还需每秒钟统计协议栈的发送带宽,当有错误发生时,log文件会输出错误信息。在该测试中的最大报文长度为1 460 Byte的TCP报文。
5.2 带宽测试
图14为TCP/IP协议栈性能测试结果,目前测试得到的平均速率约为477.9 Mb/s。对于ED探测器,平均数据率为352 kb/s,MD探测器读出电子学平均数据量约为2.2 Mb/s,TCP/IP协议栈传输速率满足项目需求。

图14 ED测试插件向PC发送的数据量随时间的变化情况
图15表示当数据以最大速率传输时,ED电子学插件与WRS1的秒脉冲(Pulse Per Second,PPS)信号偏差的分布。由于PPS信号由WR设备的本地时钟驱动计数器产生,因此可用WR设备PPS信号前沿代表其本地时钟的前沿,即PPS信号的偏差可以用来表示WR设备间的同步精度[14]。由图15可知,测试期间PPS偏差的均方根(Root Mean Square,RMS)值为19.48 ps,满足阵列同步精度RMS小于500 ps的要求,说明数据传输对于WR的时钟同步没有影响。

图15 ED读出电子学插件与WRS1的PPS偏差
5.3 资源利用率测试
表3为基于WRPC的TCP/IP协议栈固件消耗的部分资源,综合软件为Xilinx ISE14.4,具有大量的资源集成用户自定义逻辑。

表3 基于WRPC的TCP/IP协议栈固件资源利用情况
6 结束语
本文以LHAASO KM2A实验为背景,借助WR技术和TCP/IP协议栈,实现高精度时间同步的数据传输方法。TCP/IP协议栈在简化原有协议栈的控制协议且仅保留PC通信协议的基础上,无需增加额外硬件,即可实现高效可靠的数据传输和高精度时钟同步,降低了系统复杂度、系统建设和维护成本,并提高了可靠性。测试结果表明,平均数据传输速率可达477.9 Mb/s,并未影响WR同步精度,满足LHAASO KM2A读出电子学系统对数据传输速率和时钟同步的要求。该方案完全由硬件描述语言开发,可方便地扩展到其他多节点且具有时钟同步需求的电子学应用中,但目前协议栈的数据传输能力仅达千兆以太网上限的一半,因此提升协议栈带宽将是下一步工作的重点。
猜你喜欢
汽车电器(2022年9期)2022-11-07 02:16:24
量子电子学报(2022年2期)2022-04-16 09:40:02
量子电子学报(2022年1期)2022-02-25 02:05:12
量子电子学报(2021年5期)2021-10-23 06:24:08
量子电子学报(2021年2期)2021-04-24 09:42:00
装备制造技术(2020年1期)2020-12-25 05:18:20
铁道通信信号(2020年4期)2020-09-21 09:15:24
中国外汇(2019年11期)2019-08-27 02:06:30
电子制作(2017年24期)2017-02-02 07:14:44
铁道通信信号(2016年8期)2016-06-01 12:10:21
