
基于卷积神经网络的单幅图像室内物体姿态估计
2020-02-19 06:53方鹏飞刘复昌姚争为
杭州师范大学学报(自然科学版) 2020年1期
方鹏飞,刘复昌,姚争为
(杭州师范大学国际服务工程学院,浙江 杭州 311121)
场景重建一直是计算机视觉领域中非常重要的研究内容,在机器人开发、无人驾驶、智能家居以及虚拟现实等领域有着广泛的应用,姿态估计是场景重建中的重要部分.姿态估计研究内容主要包括场景中物体的旋转角度以及相对于相机的平移估计.目前一些多目标姿态估计算法需要先利用目标检测神经网络得到目标区域,然后对目标区域通过姿态估计网络进行物体姿态估计,算法不能实现端到端.本文改进目标检测算法Faster-RCNN网络模型,结合姿态估计网络模块,实现端到端室内物体的目标检测和姿态估计,算法实现了多目标分析预测,并且采用分类预测的方法进行姿态估计,相比很多回归方法,分类方法准确度更高.
1 研究现状
1.1 目标检测研究现状
深度学习方法已成为现在目标检测的主流方法,主要通过卷积神经网络将图片特征提取、特征选择和特征分类融合在一起,实现端到端训练.常用的卷积神经网络主要有LeCun等提出的LeNet-5[1]、Krizhevsky 等提出的AlexNet[2]、Simonyan等在AlexNet的基础上提出的VGG网络[3]、Szegedy 等提出的GoogleNet[4]以及He等提出的ResNet残差网络[5].目标检测网络以这些卷积网络作为图片特征的提取,以完成图片中目标的检测,算法主要有基于目标候选框的目标检测算法和基于一体化卷积网络的检测算法.基于目标候选框的目标检测算法主要有Girshick等提出的R-CNN[6]、Fast-RCNN[7],Ren S等在Fast-RCNN基础上设计了候选区域生成网络(region proposal network,RPN)并提出的Faster-RCNN网络[8],以及Lin等提出的FPN网络[9].而基于一体化卷积网络的检测算法主要有YOLO网络[10]和SSD(single shot multibox detector)网络[11].
1.2 物体姿态估计研究现状
传统的姿态估计算法是基于模型的多视角图和深度图,通过多视角图片中纹理特征和特征的深度信息来估计物体的姿态,虽然准确度较高,但是需要物体具有明显纹理特征和功耗较大的专业设备(例如深度相机、Kinect等)的支持.
基于深度学习的卷积神经网络算法是目前单目图像物体姿态估计的主流方法.Izadinia等[12]利用类似图片匹配的方法来预测物体的三维姿态,该方法准确度低、速度慢,需要大量匹配检索.Su等[13]使用ShapeNet模型[14]和PASCAL VOC数据集[15]的图片合成图片数据,使用卷积神经网络预测物体绕3个坐标轴的旋转角度,但是其预测准确度较低,鲁棒性较差.Tulsiani等[16]提出了Pool5-TNet网络,实现对物体进行旋转角度估计.上述两种算法都是用分类预测的方法预测物体旋转角度,其对于室内物体的预测准确度只有15%,而且算法无法实现多目标姿态估计.Poirson等[17]使用SSD神经网络进行物体旋转角度预测,也是采用分类的方法,网络预测速度较快,但是准确度不高.Xiang等[18]结合Fast-RCNN网络,用回归预测的方法直接预测物体绕3个坐标轴的旋转角度,相比前面方法,该算法同时实现了多目标物体的目标检测和旋转角度预测.以上算法均未能实现平移分析预测.Hueting等[19]利用CNN的分类方法预测物体相对相机的位置,但是其渲染合成的图片数据少,场景单一,结果准确度低,鲁棒性差.Xiang等[20]提出了PoseCNN神经网络,通过回归预测的方法实现了物体六维姿态估计,但是算法需要事先已知相机参数信息.
以上算法都是通过神经网络直接预测物体的姿态,而文献[21-23]则使用间接预测方法,通过神经网络回归预测物体三维包围盒顶点的二维像素坐标,再利用PnP(Perspective-n-Point)算法[24]估算出物体的六维姿态.Xiang等[20]通过卷积神经和PnP算法实现了物体姿态估计,但是算法无法进行多目标分析.Tekin等[21]对Yolo目标检测网络进行了改进,实现物体六维姿态估计,算法在LINEMOD数据集准确度高,且速度快.但是对于多目标物体(少量遮挡)的姿态估计,其准确度不高.本文参考以上方法,设计了基于卷积神经网络室内物体姿态估计神经网络,在SUNRGB-D[25]数据集上训练网络,实现室内物体的多目标检测和姿态估计.
2 基于卷积神经网络的室内物体姿态估计
本文采用two-stage目标检测网络Faster-RCNN[8]作为姿态估计网络框架,并对其结构进行了改进,修改了loss函数,增加了姿态估计项.Faster-RCNN通过RPN做了一次筛选,使得正负样本比例平衡,相比one-stage目标检测网络(Yolo[10]、SSD[11]等)准确度更高.
2.1 算法网络结构设计
算法网络结构是基于目标检测网络Faster-RCNN的网络框架,对其进行改进,增加了物体姿态估计模块.网络采用多任务训练方式,候选区域生成网络(RPN)和预测网络采用联合训练模式,实现室内物体目标检测和姿态估计端到端训练,网络结构如图1所示.首先,使用普通RGB图作为网络输入,经过卷积神经网络(CNN)提取一系列特征图,特征图通过RPN网络训练产生大量感兴趣区域(rois);再根据感兴趣区域进行下采样池化操作(RoIAlign层),池化成7×7固定大小特征图,采用Mask-RCNN[26]中RoIAlign方法(替换传统下采样RoIPooling方法),该方法解决了池化操作中两次量化造成的区域匹配不准确,提升了预测模型准确度.特征图经过两层全连接层,每个全连接层后面都使用ReLu激活函数以及Dropout,以防止网络过拟合.预测网络最后有4个预测分支,分别对应目标物体类别、边界框、平移以及旋转角度预测.本文采用直接分类预测方法[13,15-16],相比间接预测方法[19-22],可以不需要事先知道相机参数和目标三维包围盒信息,实现室内物体目标检测和姿态估计.

图1 姿态估计网络结构图Fig.1 Pose estimation network structure
2.2 损失函数
训练网络损失函数如下:
Loss=Lcls+Lbox+Lrot+Ltrans,
(1)
其中,Lcls、Lbox、Lrot和Ltrans分别为目标物体类别损失函数、边界框损失函数、平移损失函数和旋转角度损失函数.Lbox采用Faster-RCNN中的smooth L1损失函数:
Lbox=smoothL1(y-y*),
(2)
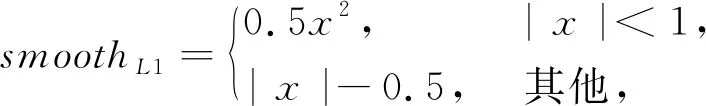
(3)
其中,y*为期望值,y为网络预测值.目标物体类别和姿态估计损失函数(Lrot和Ltrans)采用交叉熵(cross-entropy)损失函数
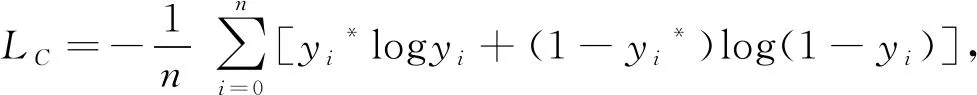
(4)
其中:yi*为期望值,yi为网络预测值,n为预测数量.
2.3 实验数据
本文训练数据集采用室内场景数据集SUNRGB-D,相比文献[19]使用OpenGL渲染的三维室内场景图片,SUNRGB-D数据集均为真实的室内场景,场景复杂,包括卧室、客厅、办公室、厨房、教室等,并且其中大部分图片均有遮挡情况,单张图片中目标物体数量多,如图2所示.相比人工合成的图片数据,使用真实场景的数据集训练网络可以使网络鲁棒性更好.本文实验RGB图共8 333张,选取室内主要家具(椅子、桌子、沙发、床以及架子)作为我们的姿态估计研究对象,数据集中这些对象主要分布在距离相机[-2.5 m, 2.5 m]×[0.5 m, 5.5 m]范围内.采用水平翻转的方法对数据集进行了数据增强.

图2 SUNRGB-D数据集室内场景图片Fig.2 SUNRGB-D dataset indoor scene
2.4 实验设置
本文实验采用端到端训练,网络对于输入的图片尺寸大小没有要求,有较好的适应性.网络反向传播时采用随机剃度下降法(stochastic gradient descent)进行权值更新,权值衰减(weight decay)大小为0.000 1,momentum系数为0.9,初始学习率lr(learning rate)为0.001,训练总迭代次数为15万次,在训练迭代8万和12万次时,分别将学习率减小1/2.实验采用GTX1080Ti显卡,显存共11 G,训练时间12 h左右.
对于物体旋转角度预测[13,15-16],假设物体沿重力方向为0°,将逆时针一周360°等分成36等份,如图3所示.相比4、8、16和24等分[13,15-16],本文算法所划分的类别更多,预测难度更大.而对于平移估计,参考文献[19]思想,将场景相对于相机位置[-2.5 m,2.5 m]×[0.5 m,5.5 m]的范围划分为10×10的网格,如图3所示,将平移估计转化成0~99的类别估计.
3 实验结果与分析
3.1 目标检测实验结果
目标检测准确度计算参考文献[6-9].先对所预测的结果进行非极大值抑制(non-maximum suppression),保留概率大于0.7的预测结果,如果预测结果与标签的IOU(intersection over union)大于0.5,且类别与标签一致,则判定为预测正确,否则为预测错误,准确度计算公式如下:
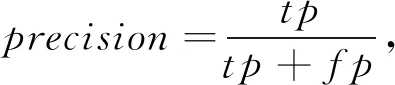
(5)
其中,tp为预测正确样本,fp为预测错误样本.
CNN卷积模块分别采用VGG16和ResNet101进行实验,并且与SSD300[17]和Yolov3[27]方法进行了对比,结果如表1所示.

表1 目标检测平均准确度mAP@0.5Tab.1 Object detection average accuracy mAP@0.5
从表1可见,相比Yolov3和SSD300方法,本算法预测大部分类别准确度较高,并且CNN网络使用ResNet101比VGG16效果好,因为ResNet101网络比VGG16网络更深、容量更大,部分效果图如图4所示.

图4 目标检测实验效果(不同类别使用不同颜色框体)Fig.4 Object detection result(different objects use different color)
3.2 姿态估计结果
3.2.1 旋转角度预测结果分析
对于旋转角度预测准确度我们采用AVP评价方法[13](角度预测正确并且类别也预测正确),并对角度误差在20°范围内的准确度进行了对比分析,结果详见表2和表3.

表2 旋转角度预测准确度(AVP)Tab.2 Rotation prediction accuracy(AVP)

表3 旋转角度误差小于20°的预测准确度(AVP)Tab.3 Prediction accuracy of rotation angle error less than 20°(AVP)
从表2可见,本文算法对于大部分物体类别的预测准确度都比文献[17]方法高很多,只有架子类别低了0.01,平均准确度最高比文献[17]方法高0.13.从表3可见,旋转角度误差小于20°的预测准确度依然要比文献[17]方法高很多,总体平均准确度最高比文献[17]方法高0.24.以上结果表明,本算法比现如今直接分类预测室内物体旋转角度方法准确度高,算法准确度得到了很大提升.使用ResNet101作为CNN网络预测结果总体比使用VGG16准确度要高,与目标检测结果一致.
3.2.2 平移预测结果分析
以无偏差的预测准确度以及一格偏差的预测准确度作为实验评价标准[19],实验结果详见表4和表5,其中文献[19]只给出了所有类别准确度的平均值,而我们给出了每一类物体预测准确度,表中Baseline是利用语义分割图和深度图方法预测的结果[19].部分效果图如图5所示.

表4 平移预测无偏差准确度Tab.4 Translation prediction accuracy

表5 平移预测一格误差准确度Tab.5 Translation prediction accuracy with one-offset

白色表示真实值,绿色表示预测正确,黄色表示一格偏差预测结果.
图5 平移预测部分实验结果
Fig.5 Partial experimental results of translation prediction
实验表明,本文算法的无偏差准确度和一格偏差准确度均高于文献[19]方法,该算法不仅实现了物体的姿态估计,还可以进行物体目标检测,实现多目标分析检测,在性能和功能上均优于文献[19].
3.3 姿态估计算法速度比较
我们对时间消耗进行了分析,本文算法总体运行速(约为15 FPS)相比SSD300算法(大约为46 FPS)略低,但是准确度却提高了很多.
4 总结和展望
本文提出并实现了使用卷积神经网络对室内物体进行姿态估计.算法对目标检测网络Faster-RCNN进行改进,通过直接分类预测的方法实现了室内物体目标检测和姿态估计.相比现有很多只能进行姿态估计的算法,本文算法还实现了室内场景图片中的目标检测,可以进行多目标分析预测.在室内场景数据集SUNRGB-D上,本文算法的目标检测准确度以及姿态估计要比现有一些算法高很多.实验使用真实室内场景图片作为实验数据,相比使用人工合成的图片,算法鲁棒性更高.本文算法是在目标检测出的区域下进行目标的姿态估计,所以姿态估计比较依赖于目标检测的准确度,如果目标准确度能够提升,那么物体的姿态估计准确度也能进一步提升.相比借助于相机参数或者物体三维包围盒信息的间接预测方法,本文算法在准确度上还有待提高.
猜你喜欢
科海故事博览·下旬刊(2022年4期)2022-05-07
北京航空航天大学学报(2021年9期)2021-11-02
学生天地(2020年3期)2020-08-25
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
汽车观察(2018年9期)2018-10-23
北京航空航天大学学报(2018年1期)2018-04-20
价值工程(2016年32期)2016-12-20
诗选刊(2015年4期)2015-10-26
