
兴趣驱动的用户借阅行为分析及启发式借阅流程模型构建
2020-02-19 04:48夏小娜戚万学
图书馆理论与实践 2020年1期
夏小娜,戚万学
(曲阜师范大学 a.统计学院,b.信息科学与工程学院,c.中国教育大数据研究院)
1 前言
在互联网技术迅速发展、在线资源日趋丰富甚至膨胀的当前社会,图书馆依旧是用户学习的重要场所,是知识获取到灵感触发的驱动力。它可以提供近在眼前、分门别类的书籍陈列模式,给予读者一种沉浸知识氛围的“庄重感”和“沉甸力”,也会让读者在不由驻足、适时停留和不禁翻阅中给予书中“文字”和自身“认知”的碰撞。互联网和大数据实现了在线阅读,这是一种“快餐”方式和“碎片”模式的应用。搜索引擎实现了瞬时反馈,用户不再需要花费很多时间查阅资料或者独立思考完成一篇文档,[1]使得传统借书和读书的意识退化,传统图书馆运营模式受到了挑战。
图书馆一直作为一种公益的知识传递和存储载体而存在,信息时代的图书馆产生了大量的在线和离线数据,但这些数据并没有得到充分有效的利用。在对于教育大数据的学习行为分析论证中,很少将借阅行为纳入数据分析范畴;[2,3]许多数据挖掘算法局限在商业数据,[4-6]对于教育类数据、读者学习兴趣和认知偏好不能做到直接关联和转化。如何让图书馆产生更多有益的数据,为教育大数据的学习行为研究提供新的支持依据?能否通过概率反馈机制调优图书借阅应用服务,并做出新的决策和新的业务调整?本文以某高校某一届学生三个学年的图书借阅数据为样本,分析其阅读行为,研究读者可能的学习行为和兴趣偏好,[7,8]构建借阅流程改进方案,对后续不同分类下的图书推荐、图书兴趣引导等提供有效的建议。
2 图书借阅行为的相关研究
阅读行为涉及三个要素:读者、读本与作者,这三者之间通过需求或知识产生联系。阅读的目的、方式、习惯和倾向等会因人不同、因时有别,但阅读的过程和目标存在共性,即读者通过知识探索、发现、思考及关联等,将信息逐步内化为自我认知。借阅行为留下的数据使研究读者的学习行为有据可依。彭博通过分析读者借阅行为,提出了一种可视化方法,有助于图书馆提供面向用户的个性化服务分析;[9]严贝妮等基于十所高校图书馆的借阅数据分析读者的阅读行为,针对高校图书馆阅读推广工作提出建议;[10]艾金勇利用读者借阅数据挖掘读者借阅行为的关联规则。[11]
随着移动互联技术的发展和普及,自助借阅和在线阅读逐渐成为图书馆重要的业务推广形式,以手机、平板电脑及Kindle为载体的电子书受到读者的青睐,各种移动App收集了大量的在线数据,成为图书馆借阅行为分析的重要补充。张亚明等结合计划行为理论与移动阅读模式的经济成本因素,设计了移动阅读的用户采纳行为假设模型;[12]李琳琳从大学生移动阅读需求角度分析了高校图书馆服务向跨界整合、用户极致体验转型的策略和条件;[13]张泸月从社交网络角度研究移动阅读推广活动中读者的交互行为。[14]
3 某高校图书馆借阅数据分析
3.1 图书借阅总体情况及分析
笔者调查了某高校图书馆2013-2017年的图书借阅数据(见表1),可以看出,该馆的读者借阅次数逐年减少。表2是该馆2013-2017年的图书采编典藏情况,2013-2015年的图书订购册数较多,2016-2017两年较少;2013-2016年的馆藏数量基本稳定,2017年最少。以上数据说明该校图书借阅次数与图书订购次数之间没有直接关联。
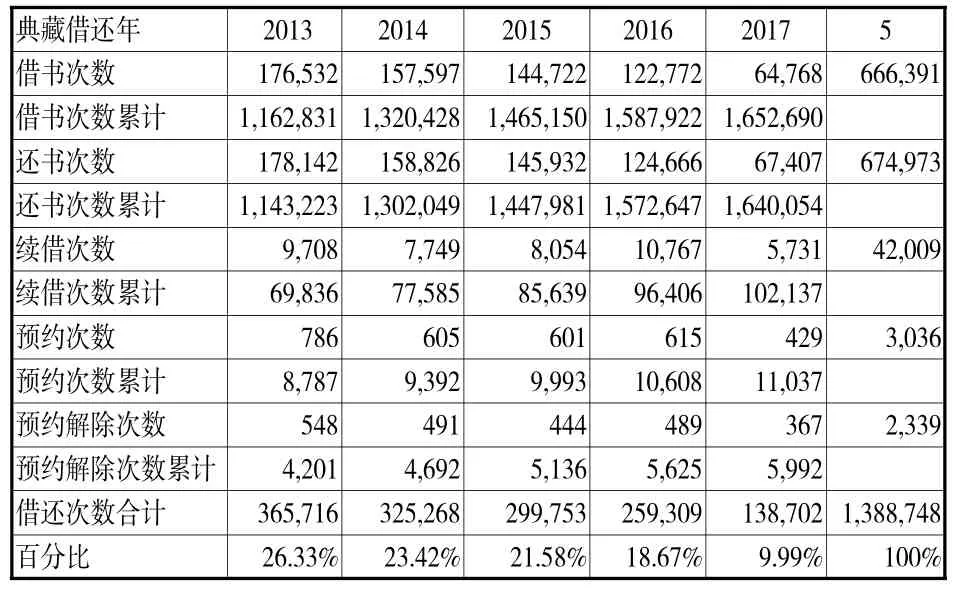
表1 2013-2017年图书借阅情况

表2 2013-2017年图书馆采编典藏情况
互联网技术革新了传统的生活学习方式,但改变不了学习行为的初衷和目的。它带来了碎片化的在线阅读和即刻搜索,但并不能带给一个人完整的知识体系和自我求知探索图谱,这一切需要读者学习行为的良性引导和逐渐积淀,需要读者在不断的探索和求索中获得,这是技术解决不了的。互联网可以改进图书管理的模式和技术实现,但替代不了图书馆的底蕴和价值,但是互联网技术支撑下的图书管理变革势在必行。
3.2 研究生借阅数据分析
本部分随机抽取了某高校2014级890名学术硕士(学制三年)和420名专业硕士(学制二至三年)为研究对象,对其2014-2017年借阅情况进行了统计(见图1、图2)。图中的折线存在相似之处,学术型硕士和专业型硕士在2014年的第四季度借阅量最高,原因是新生入学后,图书馆也增加了一批新的读者。之后,借阅数据处于波动状态,在非毕业季借阅基本平衡,在毕业季借阅次数最少。
图3是某高校2014级学术型硕士的图书借阅种类分布情况。学术型硕士借阅工业技术领域的图书次数最多,占比24.32%,且主要集中在自动化技术类、计算技术类(见图4)。这主要因为学术型硕士偏向于科学研究,需要理论深度的创新和技术广度的借鉴,而计算机科学与技术的学习是实现学科创新和研究创意的“基础科学”。

图1 2014级学术型硕士年度借阅次数

图2 2014级专业型硕士年度借阅次数
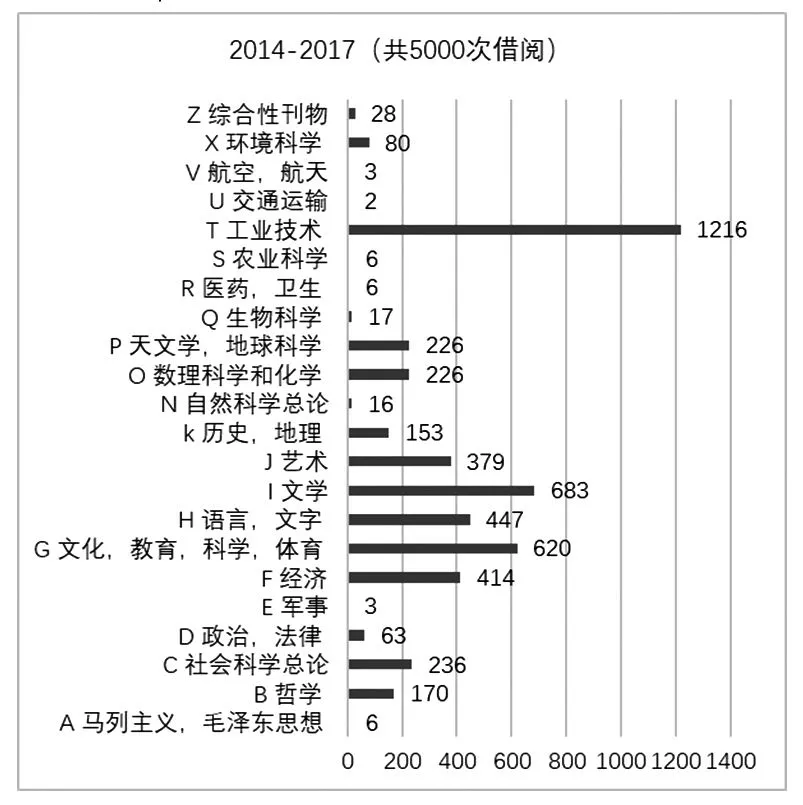
图3 2014级学术型硕士分类书籍借阅情况
图5 是某高校2014级专业型硕士的图书借阅种类分布情况,专业型硕士借阅艺术类图书次数最多,占比38.83%,其次是工业技术类,占比12.37%,而交通运输借阅次数为零,是因该校没有此类专业。艺术类包括十个子类(见图6),其中电影电视艺术、绘画、音乐的借阅次数都比较大。

图4 2014级学术型硕士T分类借阅分布
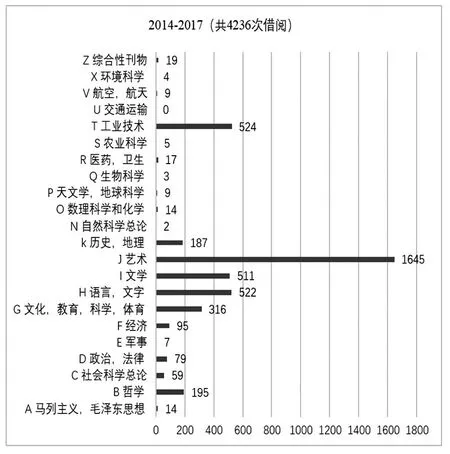
图5 2014级专业型硕士分类书籍借阅情况
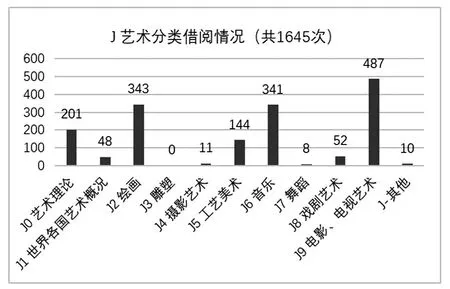
图6 2014级专业型硕士J分类借阅分布
3.3 本科生借阅数据分析
本部分以某高校2014级4,547名本科生的借阅数据为研究对象。本科学制一般为四年,故时间统计区间为2014-2018年,共产生了104,686次借阅行为(见图7)。可以看出,四个年度的借阅走向波动明显,高峰出现在大学一年级第二学期,大学二年级相对持平,大学三年级和四年级呈现下降趋势。图8为本科生借阅书籍的类型和次数,文学类书籍是大学生最喜欢借阅的书籍,共发生44,790次借阅行为,占借阅总次数的42.79%;其次是语言文字、工业技术方面。

图7 2014级本科生年度借阅数据

图8 2014级本科生分类图书借阅情况
图9 为借阅次数超过50次的文学类书籍,借阅次数位列前3名的文学书籍为“大秦帝国”(100次)、“红楼梦”(83次)和“许三观卖血记”(70次)。可以看出,中外经典文学、名著依旧是最受本科生欢迎的书籍。图10是借阅量在四年内仅为一次的文学书籍的分布情况,其中中国文学占比最大(70%)。
4 借阅行为数据驱动的问题剖析

图9 2014级本科生借阅次数超过50次的文学书
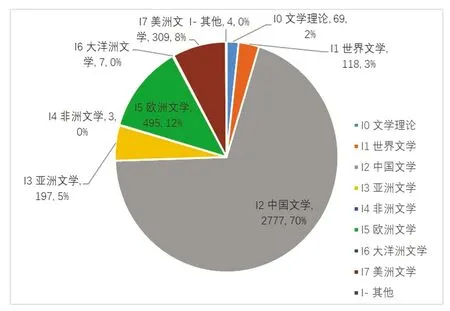
图10 2014级本科生借阅1次文学书的比重分布
(1)图书管理模式。图书馆应根据学科专业需求或典藏要求,使图书订购有据可依,并指定专门部门完成。① 图书馆每月把各个出版社的新书书目分发给相关院系负责人,征求相关人员的意见;② 高校师生自愿填写书目推荐单,图书馆定期收回;③ 从学生和教师中随机选取样本,由样本推荐书目;④图书馆借助新书推荐系统进行线上推荐。这些方式可以满足局部的借阅需求,但是忽略了借阅数据在图书订购中的引导和驱动作用。读者在借阅书籍的过程中,会产生大量的用户借阅数据,包括读者的基本信息、读者借阅书目偏好、同一专业内不同读者在专业书籍借阅中的倾向等。图书馆可以使用这些数据实现偏好推荐和启发式跟踪,这比传统离线方式的调查更具针对性和有效性。
(2)借阅业务流程。借阅流程分为“快”与“慢”两个节奏。“快”的节奏体现为读者目标性极强的情况,如读者带着书名和作者的意图走进书库,“慢”的过程有目的但并非是目标,读者更希望用“慢”节奏去发现与“目的”相关的多个知识关联体系。借阅过程是知识的探索、拼凑、关联和整合的过程,这需要在进行书籍分类的基础上,适当考虑知识的关联性和近似性,更方便读者借阅。高校图书馆除了给读者提供“借”的环境,还需要给予“阅”的条件。如一些高校把自习区与阅览室整合为一体,在书架周围放置桌椅。此外,还可以提供在线书籍检索、在线知识关联和启发式目标推荐等服务。
(3)学习行为。笔者针对学术型硕士和专业型硕士的借阅数据进行统计分析,检验这两类研究生的借阅行为是否因培养方式、教学方式、科研要求的不同而存在差异。采取双样本异方差假设检验方法,设定H0:不存在差异,H1:存在显著差异,检测发现P值>0.05(见表3),说明这两类硕士研究生的借阅行为不存在统计学差异,这与两类硕士研究生不同的培养目标是不相符的。表4为本科生书籍借阅的离散程度,结果显示方差很大,说明本科生的对分类图书借阅不具趋向性,也不具备引导效用。从2014级本科生104,686次的借阅记录中并不能够将学生的阅读行为和专业需求做到关联,对于分析不同阶段的学习行为需求与借阅书籍的关系难度较大,原因是现有的图书管理平台缺乏有效的用户画像,也缺乏相对准确完备的图书特征描述。这种情况在硕士研究生的借阅行为中也存在,没有做到学习行为、培养周期与图书借阅需求的映射。

表3 硕士研究生分类书籍借阅差异性检验
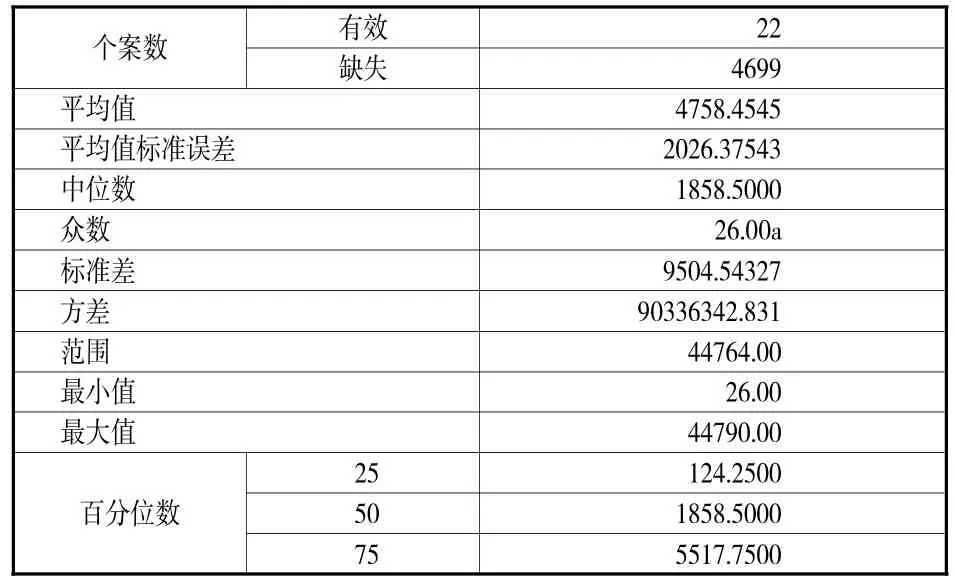
表4 本科生分类书籍借阅离散度检验
(4)数据反馈。① 图书管理系统。图书管理系统能够提供图书、读者和借阅数据,对这些数据进行统计分析,可以挖掘读者的借阅行为特征。通常意义上,图书管理系统是学校教育在线体系的一部分,它与整个学校教育所涉及的其他数据管理系统存在密切联系。② 现阶段图书借阅在服务于学科交叉方面存在不足。如教育大数据,读者会意识到教育和大数据两个议题,但是它其中关键的问题是数理统计和概率预测,只有合适的模型,才可以得到有效的结论以供参考。反馈到图书管理系统上,在与此研究方向相关的图书兴趣学习和启发式引导上,需要建立不同学科、方向、理论、技术和实验手段等关联的知识网络关联体系。③ 学生在不同学年学习的课程不同,学生的学习水平、兴趣偏好不同,学习方法也千差万别,需要考虑相同专业读者间的邻近偏好启发和学习。过滤筛选学生的学习行为和社交行为,并引入到图书推荐中,是现有图书管理系统所欠缺的。
5 启发式借阅业务模型构建
5.1 改进方案
(1)用户的“实体-关系”模型。图书管理是为用户服务的,用户需求应驱动图书业务需求,即“你需要什么,我就有什么”。图书馆应针对借阅过程的互动行为建立完备的用户“实体-关系”模型,借助用户的行为特征、在线痕迹、社交行为等,为用户兴趣和趋向提供数据分析和数据挖掘。在用户的属性特征方面纳入专业和方向,对学年和学期进行有序的阶段划分,读者的兴趣偏好不再作为读者的属性,而是作为与用户有关的实体存在。图书馆的新用户注册后,可以在第一时间标注自己的兴趣偏好。随着时间的推移,利用集成系统对用户进行兴趣偏好的分析和挖掘。图11是读者的“实体-关系”模型,右半部分是读者关系的改进,包括新属性和新参与实体的设计。区别于以往的图书馆集成系统,这里将借阅行为、专业交叉网络、学习行为和社交行为作为参与实体。

图11 读者的“实体-关系”模型
(2)学习行为、社交行为与借阅行为的融合。图书馆的用户行为一般分为学习行为和社交行为两种。这两类行为分布在不同的在线系统中,这些系统在用户登录成功之后可以提供服务。系统会保留着在线用户的行为数据,这些数据的分析结果可以阐述用户的兴趣倾向或需求目标。将图书馆集成系统与其他用户服务平台对接,实现以用户为核心的动态数据流通,可以为了解读者获取知识的习惯、兴趣爱好和推荐书籍提供有针对性的依据。如基于用户的在线选课情况的知识推荐、成绩驱动下的图书推荐等。
(3)兴趣趋向的借阅行为学习机制。如同电子商务中的物品推荐,图书推荐也是一个数据支持和算法驱动的服务。在实施中,根据用户偏好和用户不同阶段的培养方案和专业目标,预测用户的需求,并考虑用户所属专业的特点,在不同阶段推荐相应的参考书目;通过接口访问其他管理系统,获取用户的社交行为数据,挖掘用户社交行为中可能的兴趣趋向。通过合适的推荐算法驱动为每一位线上的用户提供个性化的预期借阅定制表单,当新的借阅行为发生,都会影响推荐算法的学习结果,适时调整可借阅的表单目录。倘若是一个新的用户较少次使用图书管理系统,则以他所属的专业或学期开设课程为依据提供图书推荐条件,以有效避免系统的“冷启动”问题。[15]
(4)专业关联和学科交叉网络在线绘制和借阅驱动。新技术新理论的发展使得学科的发展不是孤立的,[16]两个或者多个学科间的关联延伸出许多交叉课题,许多新问题和新需求的出现促使了多重理论和技术的融合应用。如当一个专业的用户在线访问图书馆集成系统时,在进入专业学习之前,可以了解本职专业的前驱知识和后衍课程,以及与本专业相关的其他专业的知识;在进入专业学习状态之后,也就慢慢地进入了自我发现问题和自我寻找答案的过程,查阅参考资料是其中重要的学习行为。[17]
在借阅业务建模中,在分级实现专业关联建模、方向关联建模和学科交叉网络建模的过程中,需实现这几个交叉方面的有向关联拓扑关系,每个专业下面会关联相关的基础课程和基本技能需求,课程和技能的要求会把相应的书籍纳入阅读表单,为用户提供推荐书目。图书负责人从图书分类角度将不同专业的图书进行关联,用户在系统上可以根据自己的研究方向、兴趣爱好定制自己需要的关联体系,使得借阅过程的图书推荐更具针对性和个性化。
(5)概率预测驱动的在线启发式图书推荐。通过历史数据、历史行为和阶段目标的学习和预测,实现备选项推荐等级的自动RANKING和TOP序列,为用户提供可参考的候选资源,对于图书推广和学习支持都具有重要价值。如,大量零借阅、一人次借阅和少人次借阅的书籍的价值仅通过一个读者或者闲置书架无法有效体现,即出现了“冷”借阅现象,这与书籍的推广度和认识度有直接关联。
(6)图书分类和馆藏定位。图书分类遵循规范和标准,有章可循,可根据此规范通过算法自动实现分类。基于分类,设计图书的书架定位算法,实现分类书籍在相应书架上的定位。该算法通过对图书编码特征的考察,能较为准确地完成映射位置的选择和归档。图书馆管理人员可以随时掌握每一本图书位置及典藏量。当书籍位置及存放地点变更时,可以做到批量变更,定义“图书-关系”模型,将图书所在的书库、书架、是否具备学科交叉性等作为每一本书的属性特征。通过该定位算法获取图书编码,确保与专业的映射关联,通过学科交叉性的标注,实现与专业关联和学科交叉网络的对应,图12是自助定位算法设计需要的图书实体-关系图。同样地,图书也与兴趣偏好、社交行为、学习行为和专业交叉网络的实体存在关系,可将专业码、书架和书库设置为图书的属性特征。图书自助分类和馆藏定位,可以减少图书管理人员的劳动力。通过在书库适当位置设置自助借阅机,实现图书的自助检索和借还。
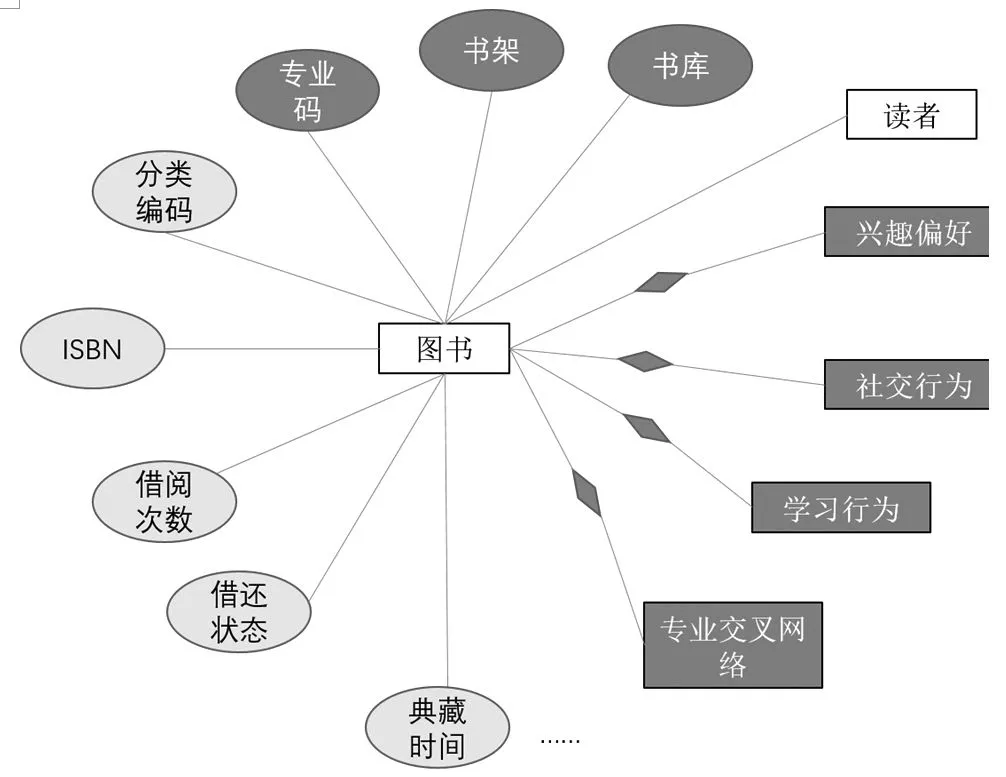
图12 图书的实体-关系图
(7)借阅大数据分析反馈。启发式借阅业务流程会产生大量的与借阅相关的数据。基于不同的目标,运用合适的数据挖掘技术,可以得到不同的数据分析结果,方便不同的系统角色参考。[18]随着业务的开展,通过平台数据的有效分析,可为师生提供有意义的反馈,从而适当调整教育教学策略,为良性引导用户的借阅行为和学习行为提供帮助,为图书管理提供有效决策。通过启发式算法的自主分析,可以实现借阅环境的动态性调整和适应性变更,以此提供更人性化的借阅服务。
5.2 模式设计
运用软件工程结构化数据流的分层设计思想描述启发式借阅流程,通过顶层设计表示启发式借阅平台的模型化架构。图13是该平台的顶层数据流图,表示了平台相关的实体,以及实体与实体、实体与平台的数据传递关系。其中,矩形表示实体,有向线表示数据流向,线上的内容为系统与实体、实体与实体间传递的数据。将兴趣偏好、社交行为、学习行为及专业关联交叉分析部分分别定义为独立的系统构件,可以实现借阅业务过程的“高内聚低耦合”系统构件特性。通过向借阅系统提供相关数据,运用启发式挖掘和分析算法得到反馈结果,驱动借阅过程。

图13 启发式图书借阅系统顶层数据流模型
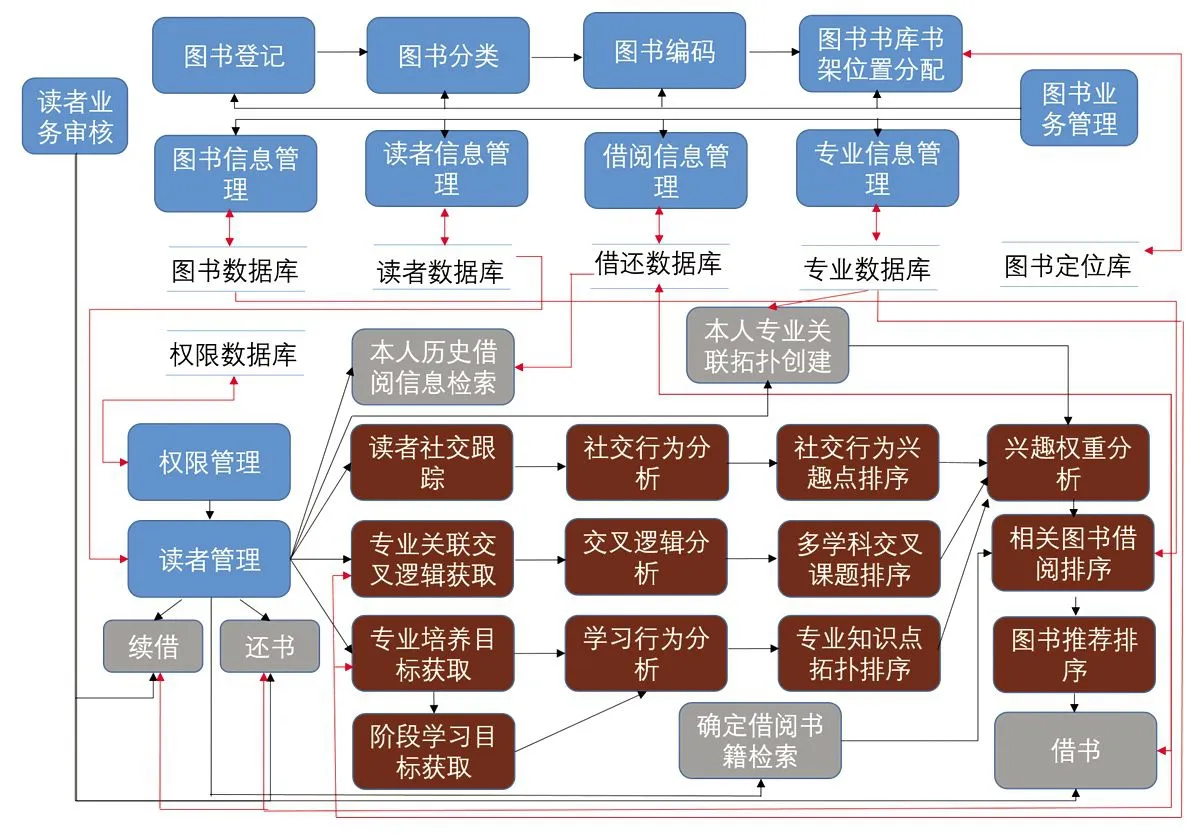
图14 启发式图书借阅系统零层数据流图功能模型
基于顶层数据流模型,遵循数据守恒的原则,对图13的“启发式图书借阅系统”进行分层设计,实现系统主干业务的零层数据流(见图14)。蓝色背景的圆角矩形表示图书管理员权限范围内的业务,棕色背景的圆角矩形表示算法驱动的业务层,该层对于系统用户是不可见的,社交行为、学习行为、专业关联交叉逻辑等数据由图13的几个子系统生成;灰色背景的圆角矩形表示提供给注册用户的业务功能。有向线上是传递的数据,图中的整体输入和输出数据与图13保持一致,经过功能点时,也将产生一定的内部新数据,并且会有相应的数据转化。通过算法驱动图书的有效推荐和借阅是该架构的创新。
猜你喜欢
公民与法治(2022年10期)2022-10-12
声屏世界(2022年13期)2022-10-08
昆明理工大学学报·社科版(2022年4期)2022-09-06
疯狂英语·新读写(2022年6期)2022-06-08
疯狂英语·读写版(2022年6期)2022-06-08
新世纪智能(数学备考)(2021年9期)2021-11-24
海峡姐妹(2020年6期)2020-07-25
当代陕西(2019年15期)2019-09-02
海峡姐妹(2018年11期)2018-12-19
当代作家(2018年11期)2018-11-27
