
基于R-FCN算法的糖尿病眼底病变自动诊断
2020-02-18 15:19王嘉良罗健旭邹海东
计算机工程与应用 2020年4期
王嘉良,罗健旭,刘 斌,冯 瑞,邹海东
1.华东理工大学 信息科学与工程学院,上海200237
2.上海无线电设备研究所,上海200000
3.复旦大学 计算机科学与工程学院,上海200433
4.上海市眼科医院,上海200040
1 引言
糖尿病眼底病变(Diabetic Retinopathy,DR)是一种由糖尿病引起的视网膜微血管损伤的并发症,患者若没有及时救治,会导致视力严重下降或失明。根据国际标准,通常将糖尿病眼底病变的严重程度分为五级[1]:健康、轻度、中度、重度、增殖。健康,视网膜完全正常;轻度,有少量的微血管瘤出现,但是不影响视力;中度,眼底开始出现少量的出血点,视力会受到轻微影响;重度,眼底大量出血,视力严重下降,但是还没有新生血管增殖;增殖,出现玻璃体出血,有新生血管增殖,患者可能会失明。本文的自动诊断系统分级也按如上的五级标准进行。
近年来,使用图像算法对眼底图像进行识别的研究越来越多[2-5]。随着深度学习的发展,卷积神经网络在糖尿病眼底图像的分类上也得到了较多的应用[6-8]。然而,这些研究均只能实现DR分类,未能对病变区域进行检测,即精确框选出病变区域的位置。
另外普通的卷积神经网络用于实际场景的眼底图片识别也面临着如下的问题:
(1)卷积神经网络的输入图像尺寸必须是固定的,然而现实中往往面临着不同款式的眼底相机拍出的图像格式尺寸不同的问题。
(2)医院中的实际图像不像公共数据集那样整洁,可能有病人的名字或身份id或日期打印在图像上。
针对上述问题,本文提出了基于R-FCN(Regionbased Fully Convolutional Networks)算法的糖尿病眼底病变自动诊断。R-FCN算法[9]是基于区域的目标检测卷积神经网络算法,能同时实现分类和对目标的边框回归任务。并且R-FCN算法可以接受任意尺寸的输入,不受背景杂质(打印在图像上的无关文字)影响。
本文实现的病变区域检测主要有如下三种:微血管瘤、眼底出血、玻璃体出血。微血管瘤常见于轻度患者,是指眼底上的小血斑,是非常小非常难发现的目标;眼底出血常见于中度以上的患者,是由毛细血管内膜损伤导致,虽比微血管瘤大,但也较小,不易检测;玻璃体出血,是指玻璃体上的血液渗出或积血,很容易检测到,常见于增殖阶段。
原始R-FCN算法由于只有下采样通道,即只用主干网络提取特征的最后一层卷积特征图作为RoI(Region of Interests)池化层和RPN(Region Proposal Network)网络的输入,其卷积特征图的尺寸因多次最大池化而变小,导致对小目标的检测性能降低。由于对病变区域的检测是以小目标为主,本文对原始R-FCN算法进行了一定的改进,加入了特征金字塔网络(Feature Pyramid etworks,FPN)结构[10],使主干网络拥有上采样和下采样两个分支,修改了RPN网络,升级主干网络为ResNeXt[11],增大RoI池化层的输出尺寸。改进后的R-FCN算法能准确地实现病变程度的分级和病变区域的定位。
2原型R-FCN算法
R-FCN算法是深度学习目标检测R-CNN系列中的成员,实现在一张图片上找出多个目标,并对目标精确分类和对目标位置框的精确回归。它的前代算法主要有R-CNN[12-13]算法、Fast R-CNN[14]算法和Faster R-CNN[15]算法。R-FCN算法是当前主流目标检测算法Faster R-CNN的延伸。
如图1所示,R-FCN原型主要由以下几部分组成:(1)输入;(2)提取特征的主干网络ResNet[16](Residual Networks);(3)RPN网络;(4)RoI池化层;(5)非极大值抑制[17](Non Maximum Suppression,NMS)。

图1 原始R-FCN结构图
原型R-FCN算法默认使用ResNet-101的全卷积神经网络[18]进行提取特征,去除ResNet-101原本的全连接层,保留100层卷积进行下采样,最后输出的卷积特征图分别送入RPN网络和RoI池化层。RPN网络,即区域建议网络,其功能是区分前景和背景,寻找目标的大概位置,输出目标候选框。然后,RPN输出的目标候选框和主干网络的卷积特征图同时作为RoI池化层的输入,生成位置敏感分数图(Position Sensitive Score Maps)以及位置敏感分数图上的RoI区域,池化后连接一个softmax分类层和边框回归层,对目标进行精确分类和边框回归。最后,使用NMS去除重叠度IoU较大的目标框,输出最终结果。
3 改进的R-FCN算法
改进的R-FCN算法结构图如图2所示。改进算法加入了FPN结构,升级ResNet为ResNeXt;RPN网络由单个改为5个RPN网络;主干网络到RPN网络从单通道改为5通道,到RoI池化层的输入变为4通道,位置敏感池化的输出尺寸从3×3增加到8×8。

图2 改进R-FCN结构图
3.1 FPN结构
没有FPN结构的目标检测算法有如下缺陷:低层的卷积特征图语义信息稀疏,但是目标位置信息精确(特征图分辨率大);高层的卷积特征图语义信息丰富,但是目标位置信息粗糙(特征图分辨率小)。原始R-FCN算法只使用高层的卷积特征图,不使用低层的卷积特征图,会导致小目标定位粗糙。检测小目标需要精确的位置信息,加入FPN结构可以有效地解决上述问题。
如图3所示,FPN结构添加了一个上采样分支,分别使用5个不同分辨率的卷积特征图构建了下采样的特征金字塔和上采样的特征金字塔。特征金字塔之间互相用1×1卷积连接,融合高层特征图的语义信息与低层特征图的语义信息。例如,图中特征图P2等于特征图P3与C2的1×1卷积特征图的相加之和。将特征图P2到P6进行3×3卷积得到特征图P2'到P6',特征图P2'到P6'送入RPN网络,特征图P2'到P5'送入到RoI池化层。低层的P2特征图分辨率较大,对小目标的位置信息很精确,同时P2也融入了高层卷积特征图的语义信息,使得P2目标分类信息也和高层特征图一样丰富。

图3 融入特征金字塔结构的主干网络结构图
3.2 ResNeXt
ResNeXt是ResNet的改进版。以往的卷积神经网络都是通过增加模型的深度与宽度,这样做的代价往往是参数与计算量的增加。ResNeXt提出了基数(Cardinality)的概念,将残差网络的残差块中的单分支的残差变换过程,变为多分支的残差变换过程。单个残差块结构如图4所示。
ResNeXt实现了在不增加算法复杂度的情况下,提高算法的精度。本文的主干网络使用ResNeXt-101,基数为32。
3.3 RPN网络
原始R-FCN的RPN网络的作用是尽可能地生成包含目标的候选框。在输入的卷积特征图上,以一个3×3的滑动窗口进行卷积操作,然后分别连接分类层和Anchor生成层。分类层是二分类,区分目标和背景;Anchor生成层,滑动窗口每滑动1次,产生9个Anchors,面积为1282、2562、5122和长宽比为1∶2、2∶1、1∶1的9个矩形框,经过边框精修后,变为目标候选框。

图4 ResNeXt残差块结构图
为了适应FPN的多尺度特征图输出,RPN的数量增加为5个,每个RPN产生一种面积下3个长宽比的3个Anchor,5个RPN对应的面积分别为162、322、642、1282、2562。产生小面积Anchor的RPN善于检测小目标,产生大面积Anchor的RPN善于检测大目标。最后,Proposal-Layer将5个RPN输出的结果合并。
3.4 RoI池化层
本文RoI池化层的结构与原型R-FCN基本相同,其结构图如图5所示。先将输入的卷积特征图经过1×1卷积处理成K2(C+1)通道数的特征图,即位置敏感分数图。K是设定的值,原型R-FCN取3;C是指目标的类别总数,例如本文糖尿病的分级有5个等级,则C=5,后者的+1是指背景类,即不属于任何需要识别的类别,例如眼底图片上的文字。在特征图框出RoI区域(RPN得到的目标候选框),把RoI区域分割成3×3的网格。对每一个网格的池化是分开进行且位置相关的,例如RoI左上角区域(标记1号),只在深蓝色块的左上角区域进行池化;RoI右边中间区域(标记6号),只在黄色块的右边中间区域进行池化。最后,生成得到K2(C+1)的三维矩阵,经过均值池化后,送入softmax层进行最后分类。

图5 位置敏感RoI池化
本文为提高算法的精度将K值提高到8,即位置敏感池化的输出增大到8×8。
4 实验
4.1 系统架构
原型R-FCN算法使用Caffe作为深度学习的构建平台,本文使用Tensorflow作为深度学习的构建平台重写算法。
糖尿病自动分级和病变区域诊断系统在如下的硬件环境下进行。CPU为E5-2620V4,GPU为GTXTitanXp。软件环境为Linux-Ubuntu18.04,Cuda9.0,Cudnn7.1。编程语言为C++、Python、CUDA。如图6所示,前端界面是以B/S架构的PHP网站实现,医生可以通过访问网站上传需要识别的眼底图片。然后,网站主机对GPU设备操作,使用GPU异构计算程序进行糖尿病眼底快速辅助诊断。

图6 糖尿病智能辅助诊断系统实现
分级和病变区域的检测分别在两个模型上进行,两者的预测结果会在可视化时进行合成,同时显示眼底图片的结果和眼底病变区域的定位。
4.2 数据集及训练参数
本文训练和测试的私有数据集从某眼科医院采集而来。图片有13种尺寸,以1 956×1 934居多,其余有2 592×1 944和3 058×3 000等。数据集格式为目标检测最常用的PASCAL-VOC[19],记录每个需要识别目标的类别和坐标框信息。
学习率初值是0.000 1,在前1 000次迭代线性增加到0.001,然后第1 000~80 000次迭代保持学习率0.001不变,第80 000~160 000次迭代学习率为恒定值0.000 1,第160 000~240 000次迭代学习率为恒定值0.000 01。
5 结果
基于改进的R-FCN算法分别对分级和病变区域检测进行测试。
5.1 分级模型(私有数据集)
使用某眼科医院采集的眼底图片分级数据集中的4 807张眼底图片作为训练集,3 998张眼底图片作为测试集。糖尿病的五级分别被标注为dr0、dr1、dr2、dr3、dr4,即健康、轻度、中度、重度和增殖。分别用改进的R-FCN算法、原始R-FCN算法、Faster R-CNN和VGG-16[20]进行分级结果的比较。
由表1和表2可以看出,改进R-FCN比原始R-FCN在五分类精度上有所提升,从91.82%提升到92.92%,但是由于增加了FPN,导致计算量增加,对于医生而言精度优于速度,计算速度降低的副作用还在接受范围内。Faster R-CNN略次于R-FCN。对于非目标检测的纯分类VGG-16表现较差,由于没有预处理和裁剪图像,纯分类的CNN模型难以适应任意尺寸或没有切除背景的输入图像,不能对未知尺寸的图片正确预测,除非CNN对测试数据集中的图片尺度进行多尺度训练。即使在纯分类的任务上,目标检测算法也能很好地胜任。
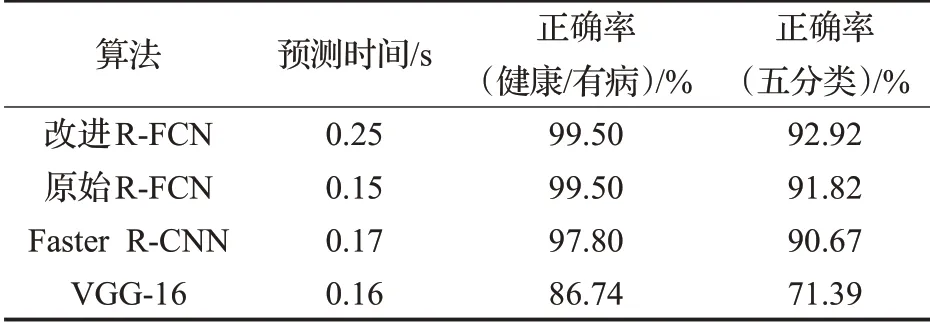
表1 分级模型正确率比较

表2 分级模型ROC比较
5.2 分级模型(公开数据集)
如表3所示,本文改进的R-FCN算法在公开Messidor数据集上也有较好的表现,并与文献[21]与文献[22]的结果进行比较,实现了高灵敏度和高特异度。灵敏度和特异度分别统计漏诊率和误诊率,灵敏度和特异度越高,漏诊率和误诊率越小。

表3 Messidor数据集ROC比较
5.3 病变区域检测模型
需要检测的病变类型有微血管瘤、眼底出血和玻璃体出血。使用450张病人标注图片作为训练集,200张病人和正常人混合图片作为测试集。由于训练集较小,使用了数据增强技术,训练算法时随机旋转和翻转图片来扩充训练集。扩充方法为旋转90°、180°、270°,以及上下翻转和水平翻转。本文使用目标检测最常用的PASCAL-VOCAP(%)评估标准来评价区域定位的准确度。每一个类都有对应的AP值,其多类平均AP为mAP(mean Average Precision)。
mAP是计算机视觉目标检测领域,统计算法的目标分类和边框回归精度的一个常用标准。AP值越大,表示算法对目标分类更准确,边框回归更精准,漏报越少,误报越少。
从表4的结果可以看出,目标检测类的算法对于病变区域的检测很有效。改进后的R-FCN在小目标检测(微血管瘤和眼底出血)明显比原始R-FCN和Faster R-CNN更优,微血管瘤AP从81.35%提升到83.68%,眼底出血AP从90.46%提升到92.28%,可见改进后的RFCN算法有效解决了微血管瘤和眼底出血的漏检问题。玻璃体出血是十分明显的大目标,基于深度学习的目标检测算法都能100%检测到。另外训练集中没有健康人的图片,而在测试集的健康人图片上,算法的病变区域检测结果为空。这说明算法准确度非常高,神经网络已经训练出正确预测病变区域的模型,不会对未经训练过的健康人眼底图像预测出病变检测。

表4 病变区域检测比较
图7~图11给出了分级模型和病变区域检测合并的结果图。

图7 健康眼底图片预测结果
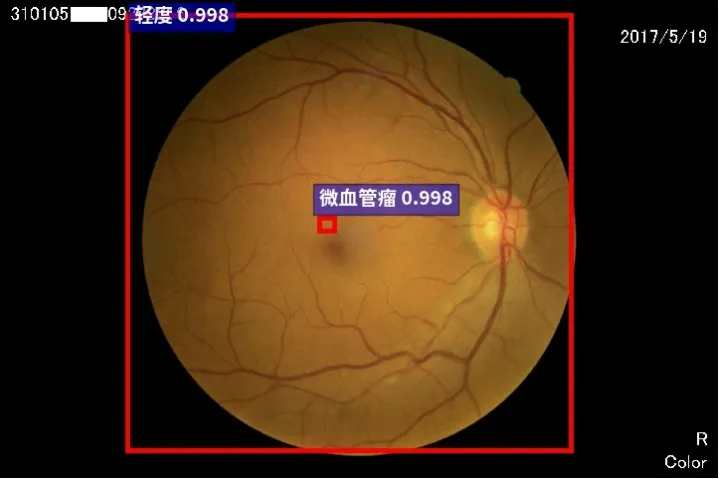
图8 轻度眼底图片预测结果
6 结论

图9 中度眼底图片预测结果

图10 重度眼底图片预测结果
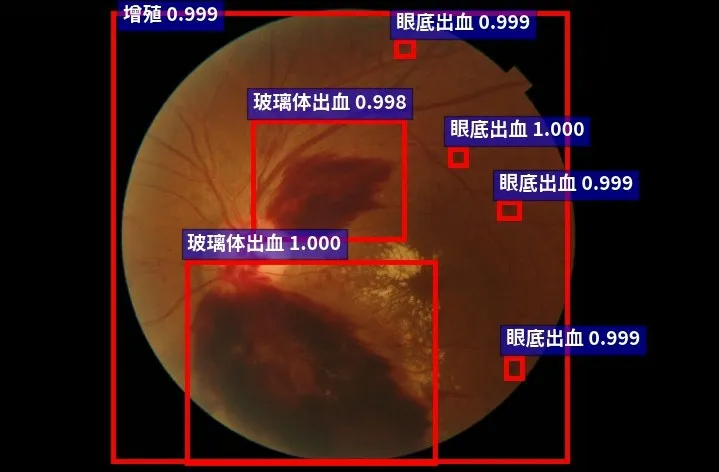
图11 增殖眼底图片预测结果
本文实现了基于深度学习的目标检测算法的糖尿病视网膜眼底病变智能辅助诊断系统。在分级系统上,针对以往纯卷积神经网络不能对未经训练过的图片尺寸进行正确分类,或不能过滤背景的缺陷,使用基于目标检测的区域卷积神经网络算法进行目标检测及分类,可以适应任意多尺度输入并过滤背景信息,并定位出眼底在图片的位置并实现分类;在病变区域检测上,加入FPN结构,并调整了算法的其他参数和结构。FPN结构的下采样(降维)和上采样(升维)的多通道结构,相比原始的下采样(降维)的单通道结构,可融合不同层次的特征图的语义信息,使低层的高分辨率特征图拥有高层的丰富语义信息,并将融合后多层的特征图同时进行识别,减少了小目标的漏检率,能比原始R-FCN算法更好地检测小目标,有效解决原始R-FCN单通道下采样结构对小目标识别能力较弱的问题。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
数学小灵通(1-2年级)(2021年4期)2021-06-09
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
北京航空航天大学学报(2018年1期)2018-04-20
初中生世界·七年级(2017年9期)2017-10-13
中国医疗保险(2017年6期)2017-07-18
中国卫生(2016年5期)2016-11-12
