
基于密度聚类和随机森林的移动应用识别技术
2020-02-18 15:17陈丹伟
计算机工程与应用 2020年4期
朱 迪,陈丹伟
南京邮电大学 计算机学院、软件学院、网络空间安全学院,南京210023
1 引言
近年来,随着智能移动终端硬件性能的大幅提升,软件功能的日益丰富,智能移动终端的使用量也在持续增长。美国调查公司IDC的统计报告显示,2016年全世界智能设备总销售量高达14亿7 060万部[1]。另一家调查公司Statista统计报告显示,截至2017年3月,Google Play中已包含280万种不同类型的应用程序[2]。如今智能移动终端已经是人们日常生活中不可或缺的工具,人们通过手机进行基本的语音通话、短信交流以及互联网相关的电子邮件、社交网络等日常的通信活动,与此同时各种基于移动设备的攻击手段应运而生,例如多年来屡见不鲜的间谍技术和获取个人定位的手段[3-5]等。
传统的攻击防范技术中,最典型的方法即从源头出发,通过识别和隔离移动终端中运行的恶意代码[6-8],减少来自网络的攻击和威胁。然而,随着网络攻击防范技术的不断提高,许多攻击手段不需要控制终端设备就可以窃取用户隐私,甚至实施定向攻击。本文主要讨论一种被动攻击方式,即攻击者通过监听和分析网络通信数据,获取用户的敏感信息。现如今大多数移动应用程序都采用SSL/TLS(Secure Sockets Layer/Transport Layer Security)协议进行数据加密,即便如此,攻击者仍然可以通过分析加密流量,间接推断用户的敏感信息,例如通过加密流量分析实现对当前网络中某个特定用户身份的识别[9]。
本文致力于通过加密流量分析,实现Android平台下移动应用程序的类型识别。一般情况下,用户根据自己的喜好安装应用程序,因此获取了用户在移动设备上安装的应用程序类型,即可间接盗取类似用户兴趣、偏好这类隐私信息[10]。这类敏感信息对广告市场调研、网络监控和管理、网络攻击防范、网络规划、流量工程等相关工作具有重要的参考价值和实际意义。
2 相关工作
近年来,国内外信息安全领域针对加密流量分类、移动应用程序类型识别等相关课题取得了诸多研究成果,这类相关算法大致可以分为基于数据包负载信息的流量分类和基于数据流通信模式的流量分类。其中,前者利用数据包IP地址、端口号以及数据包负载中的信息实现流量分析和分类[11-12],然而这类方法并不能适用于加密环境;后者仅利用数据流向、数据包长度以及某些与数据包长度相关的统计特性即可有效地实现加密流量中应用程序或流量类型的识别[13]。
文献[14]实现了一种基于802.11协议的移动应用类型识别方法。作者采集目标应用程序所产生的数据包,对原始数据进行特征提取,并用于训练应用程序识别模型,但仅对13种应用程序进行了建模。文献[15]中的实验表明,在应用程序数量增加到110种的情况下,该方法识别准确率大幅下降。
文献[16]提出了一种移动应用中用户行为类型识别算法。首先利用加密数据流中的数据包长度和数据流向等信息描述每个数据流样本,接着利用层次聚类算法(Hierarchical Clustering)对所有加密数据流进行聚类,再将聚类产生的簇标签映射到每个用户动作产生的多个流中,最后将簇标签表示的数据集作为输入,训练随机森林模型实现用户行为识别。实验表明该算法识别准确率高达95%。
文献[15]分别尝试利用支持向量机(Support Vector Machine,SVM)和随机森林(Random Forest)两种算法,实现了对Google Play中110种应用程序的识别。作者指出不同应用程序会产生相似流量模式的数据流,例如各类应用程序产生的广告数据流和相同API产生的通信数据流,这些数据流样本被视为相似干扰样本。因此,通过设置“预测概率阈值”,过滤分类模型预测概率较低的干扰样本。
事实上,训练后的分类模型对某些样本的预测概率较低,其原因除了该样本不具有较明显的类别辨识特征之外,也可能意味着算法模型训练不充分。因此,本文在文献[15]的基础上,将聚类算法和信息熵概念相结合,提出了一种聚类簇纯度分析方案过滤干扰样本,缓解由于模型训练不充分而造成的干扰样本误判的问题,提高数据集利用率。
3 Android移动应用类型识别算法
在加密环境下,可以通过对数据流通信模式的建模实现移动应用类型识别。为了克服干扰数据流的误判问题,本文在文献[15]的基础上,引入基于信息熵的聚类簇纯度分析思想,提出了一种将DBSCAN(Density-Based Spatial Clustering of Applications with Noise)密度聚类算法与随机森林算法相结合的移动应用程序识别算法。
3.1 加密数据流特征提取
3.1.1 相关概念
为了将连续的网络流量合理地离散化,文献[16]提出了突发的概念。突发(Burst)是指发送或接收的时间间隔小于某个阈值的一系列相临分组,该阈值称为突发阈值(Burst Threshold)。
文献[15]提出了数据流的概念。在一个突发中,与同一对网络四元组相关的所有分组组成一条数据流。与传输控制协议(Transmission Control Protocol,TCP)会话的不同之处在于,一个TCP会话可能会跨越多个突发,而一个数据流是在某个突发中的部分TCP会话通信内容。
文献[16]提出一条数据流可以从数据流向的角度,用三个分组时间序列来描述,分别为:(1)由数据流中流入的每个分组的长度按时间顺序排列的序列;(2)由数据流中流出的每个分组的长度按时间顺序排列的序列;(3)数据流中流入和流出的每个分组的长度按时间顺序排列的序列。
3.1.2 加密数据流的统计特征提取
加密流特征提取方法分为两大类:(1)以数据流的数据包长度时间序列作为特征;(2)计算包长度时间序列的统计量作为特征。方案一有效地体现了数据流中数据包大小随时间的变化关系,但信息单一后续分类算法难以学习;方案二通过计算包长度序列的统计量,提供了丰富的统计信息,但损失了数据流的时序信息。文献[15]提出了一种将二者相结合的特征提取方案,提取原始包长度及包长度序列统计信息共计18个特征,既保留了部分包长度时序信息,又通过统计计算丰富了特征信息。其中,9个数据包长度序列统计特征包括平均值、中位数、方差、最小值、最大值、绝对偏差、标准偏差、偏斜、峰度。另外,以10%为间隔,跳跃截取数据流的9个数据包长度作为原始包长度特征,即数据流中第10%,20%,…,90%个数据包的长度。基尼重要性(Gini Importance)是随机森林中常用的特征重要性度量指标,表示以属性a作为特征,并以该属性的取值划分的V个数据子集{D1,D2,…,DV}的纯度提升程度。通常,若某个属性的基尼重要性大于1%,则该属性能够为算法模型提供一定的有效信息[17]。图1为文献[15]中18个特征的基尼重要性分布图,可以看出76%的统计特征的基尼重要性大于1.26%,因此本文将继续采用文献[15]提出的特征提取方案。

图1 统计特征的基尼重要性分布图
加密数据流的特征提取具体分为以下步骤:
(1)将加密流量离散化为若干个突发,并对每个突发进行数据流分离,形成若干条数据流,该过程如图2所示。
(2)将每个加密流表示为3个分组时间序列。
(3)分别计算3个分组时间序列的18个特征,那么每个加密数据流样本特征维度为54。
3.2 干扰样本的过滤
如前文所述,不同移动应用可能产生相似的加密数据流,这些相似的加密流不足以区分移动应用类型,相反这些样本对后续的机器学习建模过程造成了干扰。本文提出了一种聚类簇纯度分析思想,将DBSCAN聚类算法和信息熵相结合,实现了对干扰样本的有效过滤。
3.2.1 DBSCAN密度聚类算法
DBSCAN是一种密度聚类算法,其基本思想是利用邻域参数(ε,MinPts)描述数据集样本的聚集程度。设数据集,则相关概念有:
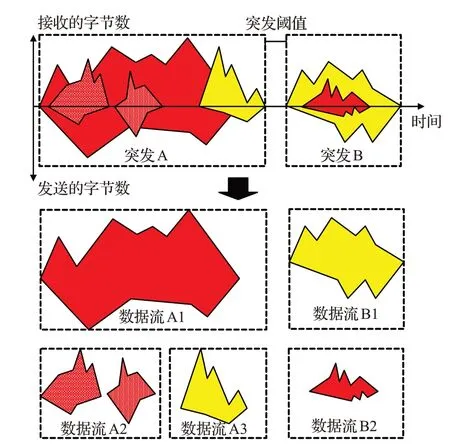
图2 连续网络流量的离散和分离过程
(1)ε-邻域:对xj∈D,由样本集D中与xj的距离不大于ε的样本所组成的集合称为ε-邻域,公式表达如下:
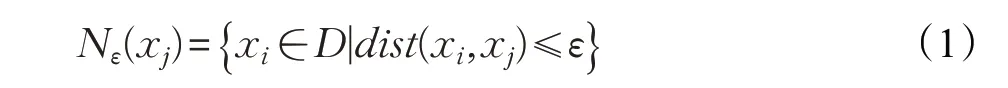
(2)核心对象(Core Object):若xj的ε-邻域至少包含MinPts个样本,那么xj是一个核心对象,即:

(3)密度直达(Directly Density-Reachable):若xj位于xi的ε-邻域中,且xi是核心对象,则称xj由xi密度直达。
(4)密度可达(Density-Reachable):对于样本序列p1,p2,…,pn,若存在p1=xi,pn=xj且pi+1由pi密度直达,则称xj由xi密度可达。
DBSCAN算法首先根据给定的邻域参数(ε,MinPts)找出全部核心对象,接着任选一个核心对象,根据密度可达原则生成聚类簇,直至所有核心对象遍历完成为止。
3.2.2 聚类簇纯度度量
信息熵(Information Entropy)是度量样本集合纯度的常用指标,本文将利用信息熵为聚类算法形成的每个聚类簇进行纯度打分。
设数据集D中共有M种不同类型的样本,聚类算法将数据集D聚合为N个簇,每个聚类簇样本集记为Di(i=1,2,…,N),随机变量Xi表示聚类簇样本集Di中样本的标签类型j=1,2,…,M)表示类型xj在Di中的出现概率。那么,聚类簇样本集Di的信息熵计算公式如下:
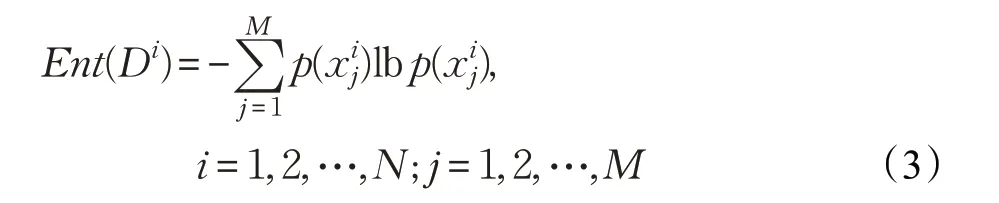
由上述信息熵计算公式可知,Ent(Di)的值越小,则聚类簇样本集Di的纯度越高。具体来说,信息熵较大的聚类簇所包含的样本所体现的通信模式是许多应用程序所共有的模式。因此,这些样本不宜用于应用程序类型识别。本文通过设置信息熵阈值,过滤信息熵超过信息熵阈值的簇中所包含的样本,从而提高后续分类算法的识别准确率。
3.3 随机森林算法
3.3.1 决策树与随机森林
随机森林算法是Bagging算法的扩展变形,该算法将决策树(Decision Tree)作为基学习器,在Bagging集成的基础上,进一步为决策树的训练过程引入了随机属性选择。对于每一个基学习器而言,属性节点的选择是决策树学习的关键,常用的划分属性优劣度量指标主要有三种:
(1)信息增益(Information Gain)
假设某离散属性a有V种取值{a1,a2,…,aV},D中所有在属性a上取值为av的样本所组成的集合,记为Dv,则信息增益定义为:
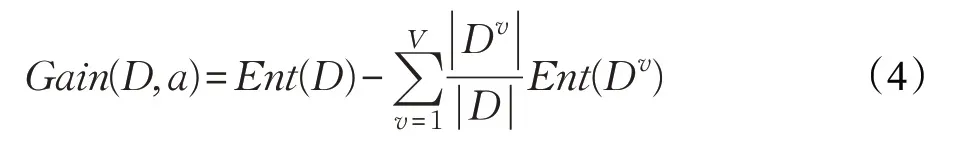
一般将信息增益最大的属性作为划分属性。
(2)增益率(Gain Ratio)
增益率计算公式为:

其中,IV(a)称为属性a的固有值(Instrinsic Value)。增益率越大意味着该属性越适宜作为划分属性。
(3)基尼指数(Gini Index)
基尼指数的计算公式为:

基尼指数较小的属性适宜作为划分属性。
3.3.2 基于随机森林的移动应用识别算法
移动终端的加密流量按产生方式可以分为交互式流量和非交式流量[15],本文主要关注加密流量中的交互式流量。现如今移动应用程序种类丰富,主要包括社交软件、购物软件、办公软件以及游戏软件等,由于移动应用的需求和功能各不相同,产生的加密数据流传输模式则有所不同。本文所采用的随机森林算法适合学习种类繁多、错综复杂的数据样本关系。随机森林算法利用多个决策树模型集成一个强学习器,由于该算法在决策树的基础上引入了随机划分属性选择,使得弱分类器具有较强的多样性,利于捕捉复杂多样的移动应用通信模式。具体算法流程结构如图3所示。

图3 算法流程结构
将经过第3.2节干扰样本过滤处理的数据集D,作为随机森林算法的输入数据,依次训练每个决策树分类模型。训练期间引入随机划分属性选择机制,即对于基决策树的每个划分属性,首先从当前节点的属性集合中随机选择一个包含k个属性的属性子集,接着在该子集中选择一个最优属性作为划分属性。在测试模型时,所有基决策树投票得出最终决策。
4 实验
4.1 实验环境及数据
实验所用的计算机操作系统为Ubuntu 14.04,CPU为i5-6500,内存16 GB,主频3.2 GHz,开发环境为Python 2.7,使用scikit-learn 0.2.0进行机器学习建模。
本文采用文献[15]中的数据集进行移动应用类型识别。该数据集包含110种Google Play中的最流行移动应用,共计131 736个数据流。该数据集具有一定的普适性和真实性,能够较好地验证本文所述方法的有效性和实用性,另一方面也可以更好地对比本文和文献[15]所述算法的识别准确率。
4.2 聚类簇纯度分析
首先,利用DBSCAN聚类算法对原始数据集进行聚类分析。为合理设置算法的ε和MinPts参数,对数据集中样本间距离进行统计分析,分析结果如图4。由图4可知,超过95%的样本与其最邻近的样本间距小于0.7,因此ε取值为0.7。

图4 样本与其最近样本距离分布图
图5为ε=0.7时,每个样本的ε-邻域所包含的样本数量。其中6.6%的样本周围的临近样本数量低于33,由于临近样本数量较少,这些样本可以视为DBSCAN聚类中的噪声样本,从而MinPts应设为33。

图5 样本的ε-邻域所包含的样本数量分布图
以ε=0.7,MinPts=33为参数进行DBSCAN密度聚类,聚类完成后计算每个聚类簇的信息熵。样本所在簇的信息熵与样本数量的关系如图6所示。

图6 聚类后样本的信息熵分布图
4.3 评价指标
对于机器学习的分类问题,常用的评价指标有准确率(Accuracy)、召回率(Recall)和精确率(Precision),具体公式如下:

其中,TP(True Positive)表示正例预测为正例的样本数;FP(False Positive)表示反例预测为正例的样本数;TN(True Negative)表示正例预测为反例的样本数;FN(False Negative)表示反例预测为反例的样本数。
4.4 实验结果
由第4.2节的聚类簇纯度分析可知,约有75%的样本其所属聚类簇的信息熵小于2.6 bit。在此基础上,本文分别设置不同熵阈值进行实验。表1为不同熵阈值下的应用识别效果。

表1 不同熵阈值的实验结果
本文提出聚类簇纯度分析思想,通过信息熵为聚类簇纯度打分,过滤信息熵较大的簇样本,提高分类准确率。随着熵阈值减小,过滤的样本数量和分类准确率逐渐增加,样本利用率逐渐降低,如图7所示。
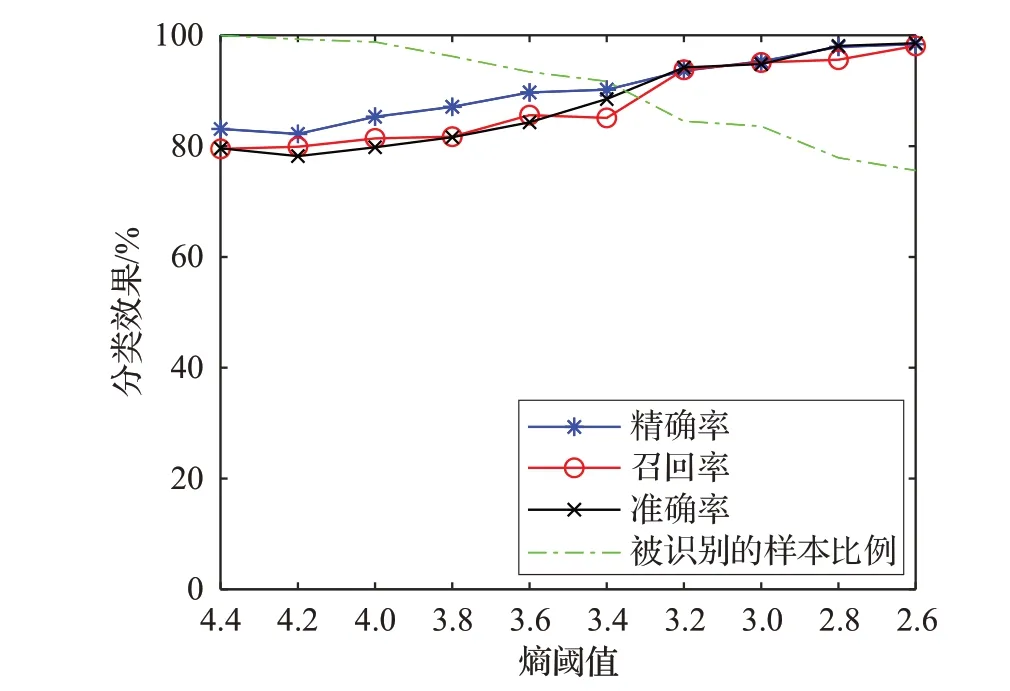
图7 应用识别效果与熵阈值的关系曲线
本文在文献[15]的基础上提出了改进。文献[15]提出的基于预测概率阈值的干扰样本过滤方法,存在干扰样本误判的问题。而本文提出的基于聚类簇信息熵阈值的样本过滤方法,降低了干扰样本的误判概率,因此过滤较少的样本即可达到较好的识别效果,提高了样本利用率。在相同样本利用率的情况下,本文方法与文献[15]应用识别效果对比如图8所示。当样本利用率大于90%时,由于两种算法均采用随机森林算法进行建模,准确率和召回率差异较小;当样本利用率小于85%时,本文方法的准确率和召回率基本稳定高于文献[15]所述方法。本文提出的基于信息熵的聚类簇纯度分析方法,减少了干扰样本的误判,从而有效地提高了样本利用率。
5 结束语

图8 两种算法的识别效果比较
本文提出了一种基于DBSCAN和随机森林的移动应用程序识别算法,提出了一种基于信息熵的聚类簇纯度分析方案,缓解了由于模型训练不充分导致的干扰样本误判问题,提高了对移动加密流量中不同应用间的相似干扰加密流的过滤效果。最后,本文通过实验与文献[15]提出的基于预测阈值和随机森林的移动应用识别方法进行对比,实验结果表明,本文方案在相同样本利用率的情况下,算法的识别准确率和召回率均优于文献[15]所述方法。
猜你喜欢
军民两用技术与产品(2022年1期)2022-06-01
汽车维修与保养(2020年10期)2021-01-22
汽车维修与保养(2020年11期)2020-06-09
电脑报(2019年12期)2019-09-10
中国计算机报(2018年30期)2018-11-12
雷达学报(2017年6期)2017-03-26
西北工业大学学报(2015年3期)2015-12-14
振动工程学报(2015年1期)2015-03-01
中国卫生(2014年7期)2014-11-10
郑州大学学报(理学版)(2014年2期)2014-03-01
