
基于自适应学习率的运动目标高效检测算法
2020-02-11 06:57:46郝晓丽牛保宁吕进来
电子科技大学学报 2020年1期
郝晓丽,刘 伟,牛保宁,吕进来
(太原理工大学信息与计算机学院 山西 晋中 030600)
运动目标检测能够识别目标运动所引起的帧间差异,是计算机视觉研究的一个重要分支[1]。运动目标检测的核心是快速、完整地获取视频图像中的运动物体。快速性要求获取运动目标时,保持算法的低复杂度,实现实时检测。完整性不仅要保证所获取目标轮廓的完整性,更强调充分、完整地获取运动目标的内部信息。
为了快速获取目标,人们通常采用帧间差分法和基于Vibe的背景建模法[2]。帧间差分法依据相邻帧间的图像差异获取目标,该方法计算简单、实时性强。但由于帧间图像同一位置的灰度值非常相近,容易导致空洞现象,使得运动目标的内部信息提取不完整。而基于Vibe的背景建模则是将当前帧的像素值与其邻域N个样本集建立起的背景模型进行比较,通过设定阈值将该像素点判定为前景或背景,该方法运算速率快,易于实现。但由于受限于基于少量样本建立的背景模型,当样本趋于无穷大时才能准确描述场景,在实际场景的应用中,当发生瞬时的光线突变时,背景模型来不及更新,容易将前景误判为背景,产生“空洞”现象。针对此问题,文献[3]采用膨胀、腐蚀形态学方法填充运动目标内部细小的空洞,解决了部分“空洞”现象;但由于像素点的扩充及消除,使得图像中连通区域的大小发生改变,很难得到完整且面积接近真实目标的检测结果。文献[4]在传统三帧差分基础上,运用Canny算子扩充图像边缘,减弱了“空洞”现象,但对于运动过快的物体,由于相邻帧间差异过大,易产生“重影”。而文献[5]通过HSV颜色空间和Vibe算法的结合实现运动目标内部信息的检测。
为了保证所获取目标的完整性,通常采用背景差分法[6]和LK光流法[7],LK光流法通过各个像素的矢量特征对视频图像进行动态分析,从而得到完整目标,但其计算量过大,导致实时性和可用性差。背景差分根据当前帧与背景模型之间的差异,构建各像素点的高斯模型,通过目标像素与高斯模型的匹配,以获取运动目标。此方法通过建立稳定的背景模型来保证获取目标内部信息的完整性[8]。建立背景模型的方法有均值背景建模[9]、CodeBook背景建模[10]、单高斯背景建模[11]等。但上述方法所建立的背景模型仅适用于单一场景,在复杂背景下由于背景像素点与噪音的干扰,易造成目标信息的丢失及误判。而基于混合高斯建模的背景差分法[12]以不断更新背景模型的方式实现运动目标的完整提取,但在学习过程中,高斯模型的更新多采用固定速率,忽略了在不同阶段的背景建模中,其更新速率应存在差异的事实。若仅以固定的更新速率完成背景模型的更新,易造成算法复杂度增加,实时性受到影响。针对实时性差等问题,文献[13]运用帧间差分实时性好的优势,来提高混合高斯建模的运算速度,但由于模型的更新速率无法适应背景信息的变化,使得算法对动态背景的适应性减弱;同时在物体运动缓慢或过快时,易造成像素点重叠较多或位置区域变化过大,若延用传统相邻帧间差分方式,会造成目标信息的丢失或“重影”。
运用深度学习的方法实现运动目标检测是近几年的研究热点。如文献[14]提出了基于Faster RCNN的行人检测方法,利用CNN提取图像特征,通过聚类和构建区域建议网络(RPN)提取可能含有行人的区域,再利用检测网络对目标区域进行判别和分类,从而得到运动目标。它提高了目标检测的准确度及速度,但会对一些形似目标的静止物体产生虚警与误判。
因此,目前的运动目标检测算法主要存在两方面的问题:1)当存在背景动态变化、噪声干扰及物体运动缓慢时,目标图像中对比度低的部分区域易被误判为背景,导致内部信息无法完整获取,易产生“空洞”问题;2)在物体快速运动时,由于边缘像素的位置发生较大变化,在差分运算时运动目标的轮廓易产生“重影”及边缘缺失的现象。
针对上述问题,本文提出了基于自适应学习率高斯建模的改进三帧差分算法,主要提出了两点改进:1)鉴于三帧差分实时性强的优势,为保证快速且尽可能完整地获取目标轮廓,采用任意帧间差分法,使差分结果不仅包括相邻帧间的差分信息,还包括跨帧差分的目标信息,以此增加差分图像所包含的边缘信息,防止由于像素点获取过多所造成的“重影”;2)鉴于混合高斯背景建模具有完整提取目标信息、抗干扰能力强的优势,为弥补三帧差分法极易带来的“空洞”问题,提出基于自适应学习率的混合高斯背景建模法对目标的内部信息进行提取,通过背景模型的自适应修正,实现目标内部信息的充分获取,提高目标检测的完整性。
1 基于自适应学习率高斯建模的改进三帧差分法
为了快速、完整地从视频序列中获取运动目标,本节分别就目标检测中的混合高斯背景建模[15]以及三帧差分法[16]提出改进。
1.1 基于自适应学习率的混合高斯背景建模
混合高斯建模运用不断更新的背景模型,通过像素点与背景模型的匹配,实现像素点的准确分类,然而,由于现实场景环境复杂,易出现光照突变、物体遮挡等情况,若采用固定的模型更新速率,导致背景模型的更新速度无法适应背景信息的变化,易造成“鬼影”及误检现象。因此,为了解决上述问题,本文引入“自适应学习率”的概念,设计并实现基于自适应学习率的混合高斯背景建模,针对不同帧设定与之相适应的学习率,以达到背景模型不断更新的目的。
1.1.1 问题与解决思路
为了更好地消除动态环境对目标获取的影响,本文采用一种模型更新速率不断调整的混合高斯背景建模法,通过设定帧数阈值TH,将背景建模划分为两个阶段,当帧数小于阈值TH时,背景模型处于创建初期,为消除物体由静止到运动造成的“鬼影”,需要通过较快的更新速度,增加高斯模型的权重及均值,以加速背景更新。当帧数大于阈值TH时,背景模型中的干扰信息得到去除,为避免将静止或运动缓慢的目标吸收为背景的一部分,以目标像素及相邻8像素在当前帧与背景模型中的差异度为依据调整学习率,实现背景模型的自适应修正,保证模型对动态环境的适应性。
1.1.2 高斯模型的更新
在模型创建之初,往往存在由静止到运动的目标,若学习率 α取值过小,由于模型更新速度不及时,易出现“鬼影”现象;在模型中的干扰因素去除之后,若 α取值过大,容易将运动缓慢的目标判断为背景,出现误检。因此,本文设定帧阈值,针对阈值之前视频帧,以较快的、逐渐递减的学习率更新背景模型,消除由于目标运动造成的“鬼影”;针对阈值之后的视频帧,减慢更新速度,并依据检测效果对学习率进行调整,保证模型的可靠性,以防止过度更新造成的目标丢失。学习率的设置为:
式中,α为学习率; λ1,λ2为常数;f为帧数;ΔD为目标像素与相邻8像素在当前帧与背景模型中的差值,TH为帧数阈值,参考量 ΔD为:
式中,I(x+i,y+j)为目标图像像素点;B(x+i,y+j)为背景模型像素点。
根据上述公式,在背景模型创建之初,模型的学习率随着帧数f的增加不断降低,但仍保持较高的更新速率,可以充分消除背景模型中的干扰信息。当帧数f大于阈值后,以目标像素及相邻8像素在当前帧与背景模型中的差异度为依据调整学习率,充分、及时地反映目标像素的变化,从而调整背景模型的更新速度。
当f≤TH时,随着帧数的增加,学习率逐渐递减,模型更新速度由快减慢,通常 α为 [0.03,0.06]时模型的更新效果最优,即的取值应为[ 0.03,0.06]。当f>TH时,以目标图像及相邻像素点在当前帧与背景模型中的差值作为模型学习率修正的参考量,只需依据差异程度对学习率进行调整即可,即学习率随着差值的减小而降低,从而保证所获模型的可靠性,减少误检现象。
式(1)中,λ2(1−exp(−ΔD2))应满足而即可得 λ1的取值范围据此可得同时,阈值TH满足求解其值为因其为整数,取18。
因此,基于自适应学习率的混合高斯建模即可消除初始时期背景建模中的干扰因素,又能保证后续背景模型更新的可靠性。
1.2 基于边缘提取的三帧差分改进算法
1.2.1 问题与解决思路
基于自适应学习率的混合高斯背景建模通过设定不同的学习率,使得所获目标更加完整,并通过自适应学习率加速背景模型的迭代速度,加快了目标检测速度。但由于目标边缘的位置不断变化,使得像素点获取不完整,目标边缘缺失的问题仍然存在,且由于混合高斯建模的复杂性,算法复杂度依然较高。为解决算法实时性差的问题,本文运用三帧差分实现快速提取目标轮廓。然而在目标运动过快时,由于边缘像素的位置发生较大变化,仅采用传统相邻帧间差分的方式,检测出的运动目标轮廓易存在“重影”及边缘缺失的现象。因此,本文提出改进的三帧差分方式,将相邻帧间差分的方式改变为任意帧间差分法,增加差分图像所包含的边缘信息,消除“重影”。但其边缘信息仍存在缺失的状况,为解决此问题,本文借鉴Canny算子能够有效读取强边缘和弱边缘、抑制噪声[17]的优势,运用其填充目标边缘信息,进一步完善目标轮廓。
1.2.2 基于边缘提取的三帧差分改进算法
本文采用任意帧间差分的方式,使差分结果充分包含视频图像中由于物体运动所体现出的差异,一定程度上增加目标的轮廓信息,避免目标快速运动时由于边缘像素提取过多造成的“重影”问题,从而降低了边缘像素点的误检率。其次,针对三帧差分中目标边缘不连续的问题,引入Canny算子,将其所提取的目标轮廓与三帧差分结果融合,以此作为改进后的三帧差分结果的边缘补充,使得物体的边缘更加完整、连续、平滑。
算法描述如下:
1)图像的预处理。对视频图像进行中值滤波处理,减少噪声干扰,并提取三帧连续图像Ik−2、Ik−1、Ik。
2)设定差分图像。将Ik−1与Ik−2差分得到Dk1,Ik与Ik−1差分得到Dk2,Ik与Ik−2差分得到Dk3,使得差分图像充分包含由于目标运动所造成的像素差异,以此增加目标信息,精确目标边缘,减少由于像素点获取过多造成的“重影”问题。
3)运用自适应阈值T实现差分图像的二值化:
4)为使目标边缘更完整、平滑,从以下4个方面补充边缘像素点:
①运用Canny算子提取三帧图像的边缘信息,由于获取的目标边缘范围较大,为更加精确目标边缘,将三帧边缘图像“与”运算得到图像C。
②由于二值图像Rk3为跨帧差分结果,虽然其所包含的目标信息最为丰富,但差分固有特性易导致边缘不连续、缺失的问题。运用RC=Rk3orC进一步补充边缘像素点,提升目标边缘的完整度。
③运用RR=Rk1orRk2一定程度上弥补由于物体运动缓慢所造成的空洞问题,避免漏检。
④为过滤掉冗余像素点,将边缘检测与改进三帧差分算法所识别出的目标边缘区域进行像素点匹配,确定两者相交的区域FD,该区域即为FD=RC and RR,FD为运动目标。
为了直观地表明本文所提出的基于边缘提取的三帧差分改进算法与传统三帧差分的不同,选用CAVIAR测试集中的两个视频作为测试数据,视频均为静态背景下的单运动目标,帧速率为25帧/s,且视频中目标所运动的距离相同,其中图1a中的第一幅图运动目标为行走状态,相同运动距离所得视频帧数为83帧,即帧间差异较小,第二幅图运动目标为奔跑状态,相同运动距离所得视频帧数为45帧,即帧间差异较大。选择视频中第30帧图像,用本文算法与传统的三帧差分算法分别进行检测,检测结果如图1所示。
由上图可知,在目标运动缓慢时,传统的三帧差分算法由于相邻帧间重叠区域较大,同一位置的像素点未发生明显变化,导致目标内部产生空洞且边缘信息缺失,而本文的改进算法较大程度地获取了目标的轮廓信息,并在一定程度上解决了目标空洞的问题;在目标快速运动时,传统的三帧差分算法由于相邻帧间差异过大,使得边缘像素点在差分运算时产生重影,且空洞及边缘不连续的现象仍然存在,而本文的改进算法有效解决了目标边缘的“重影”问题,在充分提取目标边缘的同时有效改善了目标内部信息获取不完整的问题。
1.3 基于自适应学习率高斯建模的改进三帧差分算法
基于自适应学习率的混合高斯建模提高了运动目标的完整性,有效抑制了动态环境对目标检测的影响,提高了目标检测的准确率,但其算法复杂度高,且获取的目标边缘缺失、间断。而基于边缘提取的三帧差分改进算法实时性强,能充分获取目标轮廓,但由于相邻帧的重叠区域较大,“空洞”现象较为严重。因此,本文结合两种算法的优势,提出基于自适应学习率高斯背景建模的改进三帧差分算法,在对前景图像完整提取的同时,提高了算法的运行速度。图2为算法的模块图。
2 实验分析与验证
为对本文算法进行验证,采用配置为corei5-8300H,内存为8 GB,显卡为MX150,硬盘容量为256 G的Windows操作平台,并在matlab2014b中实现本文算法。本实验的视频数据选自CAVIAR测试集与IBM公开视频集。
2.1 自适应学习率对混合高斯背景建模的影响
为了验证自适应学习率的混合高斯建模算法能完整提取运动目标,将该算法分别与文献[12]及文献[15]进行比较,其中文献[12]采用固定学习率的混合高斯建模,文献[15]将传统混合高斯模型与三帧差分结合,运用3种算法分别对第40帧视频图像中的运动目标进行检测。图3为检测结果对比图,图3a为视频图像,图3b、3c、3d分别为运用文献[12]、文献[15]和本文方法进行目标检测的结果。图3b中采用固定学习率的混合高斯建模进行目标检测,在物体缓慢运动时,过快的高斯模型更新导致部分目标信息丢失;图3c中通过混合高斯与三帧差分的结合,所得目标轮廓较为完整,但仍有部分目标信息无法获取;本文算法采用自适应学习率进行混合高斯建模,提取的目标特征完整,且边缘清晰,基本避免了信息丢失及边缘间断的问题。
为了更直观地表明视频帧数、自适应学习率、运动目标完整性之间的关系,本文针对CAVIAR数据集中运动物体突然进入的视频进行检测,检测中学习率自适应调整的过程如图4a所示。由图中可以看出,在背景模型创建之初,为消除“鬼影”,需采用较快的学习率更新背景模型,但随着背景模型的逐步稳定,模型的学习率不断降低;当背景模型中的干扰因素去除之后,模型的学习率自适应更新并减慢更新速度。图4b反映了在不同学习率下所提取的目标像素点占总目标像素点的比例,得出所获目标的完整度与学习率之间的关系。
为了进一步验证自适应学习率对混合高斯背景建模检测准确率的影响,将本文算法与上述算法对同一视频图像进行处理,分析三者所得目标的完整度,统计结果如图5所示。
由图5可知,相同目标的视频图像中,采用本算法所检测到的目标像素大于文献[12]及文献[15],因此基于自适应学习率的混合高斯背景建模所提取的运动目标的完整度更高,即检测准确率高于其他算法,相比文献[12],本文算法的目标完整度提高了38.56%,相比文献[15],本文算法的目标完整度提高了15.31%。
综上所述,本文提出的基于自适应学习率的混合高斯建模,提高了算法的检测准确率,使目标的完整度得到提升。
2.2 验证基于边缘提取的三帧差分改进算法
为了验证本文提出的基于边缘提取的三帧差分改进算法能有效提取目标边缘,将该算法分别与文献[3]、文献[4]进行比较,其中,文献[3]将三帧差分与数学形态性结合,文献[4]将传统三帧差分和边缘检测结合,分别将3种算法用于第35帧视频图像中的运动目标检测。图6为检测结果对比图,图6a为视频图像,图6b、6c、6d分别为运用文献[3]、文献[4]和本文方法进行目标检测的结果。
可以看出,图6b所得边缘信息在经过形态学处理后背景噪音基本消除,但目标轮廓的呈现仍有欠缺;图6c在边缘清晰度上较6b有所提升,但由于相邻帧的差分方式,目标边缘的像素点获取过多,存在“重影”现象;图6d采用本文算法,所得目标边缘平滑且连续,在保证轮廓信息准确性的同时完整性也有所提升。
2.3 多场景验证
为了充分验证本文算法的优越性,选用IBM数据集中不同背景下的多目标视频作为测试数据,其中视频1用于静态背景的运动目标检测,视频2用于动态背景的运动目标检测。分别运用文献[9]、文献[5]、文献[14]中的算法及本文算法对视频数据进行处理,并对实验结果进行分析。其中,文献[9]采用均值背景建模与三帧差分相结合的方式,文献[5]结合颜色特征与Vibe背景建模,文献[14]采用Faster-RCNN神经网络检测运动目标。
2.3.1 静态背景的目标检测
实验选用静态背景的视频图像对运动目标进行检测。将其中第25帧作为检测数据,实验结果如图7所示,在静态背景下对多个运动目标进行检测,文献[9]由于采用均值背景建模,基本提取了运动目标的轮廓信息,但由于对光照变化敏感,目标的内部信息没有完整获取,存在漏检现象。文献[5]所得目标图像较为完整,但干扰像素点较多,存在误检目标,且目标边缘间断。文献[14]采用Faster-RCNN神经网络,获取了大部分运动目标,但对距离远、目标小的物体无法准确检测,且存在误检现象。本文算法基本提取了图像中所包含的运动目标,过滤了图像中的背景噪声,使得边缘信息连续、平滑,避免了文献[9]算法的“空洞”问题以及文献[5]算法与文献[14]的误检现象。
2.3.2 动态背景的运动目标检测
当运动目标处于动态环境,背景信息会不断变化,易对目标检测的准确性造成影响,因此本实验选用动态背景视频(晃动的灯)中第35帧图像进行检测。实验结果如图8所示,文献[9]所提算法对环境光照变化和背景的多模态性比较敏感,目标图像只获取了部分目标信息,“空洞”现象严重,且存在背景像素的干扰(晃动的灯)。文献[5]所得目标图像较文献[9]更为完整,消除了部分干扰信息,但受限于Vibe建立的样本集数量,因此目标内部仍存在“空洞”,同时目标的边缘信息缺失。文献[14]采用Faster-RCNN神经网络,较为准确地检测到了运动目标,但其所获得的目标范围较大,且过于依赖网络训练样本的数量,准确率的波动性较大。本文算法完整地提取了运动目标,边缘信息连续、平滑,并有效地抑制了动态背景对检测准确性的影响。
为了进一步验证本文所提算法在运动目标检测中的可行性,选择查全率(Recall)、查准率(Precision)及F-Measure(FM)3个标准作为目标检测结果的评价指标,F-Measure为查全率与查准率的加权调和平均,其值越大代表算法越可靠:
式中,TP为正确检测的运动目标数;FN为未被检测出的运动目标数;FP为误检的运动目标数。
分别采用3种算法对视频1及视频2中前30帧图像进行检测,以5帧为间隔,获取不同帧数下各算法的查全率、查准率及FM值,并求取平均值,结果如表1所示。可知,文献[9]采用均值背景建模的检测方法,通过多帧的平均值构建背景模型,运算速度快,但易受光照和复杂背景的影响,“漏检”与“误检”目标较多,其查全率与查准率为三者最低。文献[5]中检测算法采用基于Vibe的背景建模,对动态环境有一定的抗干扰能力,运算效率高,因此查全率较文献[9]算法有所提高,但受光照变换的影响,运动目标未能全部提取,存在漏检现象,且目标信息获取不完整。文献[14]采用的Faster-RCNN神经网络具有较高的检测准确率,且实时性好,但其在复杂环境中无法对较小的运动目标有效检测,因此查全率较低。本文算法采用混合高斯背景建模,对动态环境适应性强,能准确检测运动目标,在提升查全率的同时保证较高的查准率,并根据FM值进一步表明本文算法更为可靠。
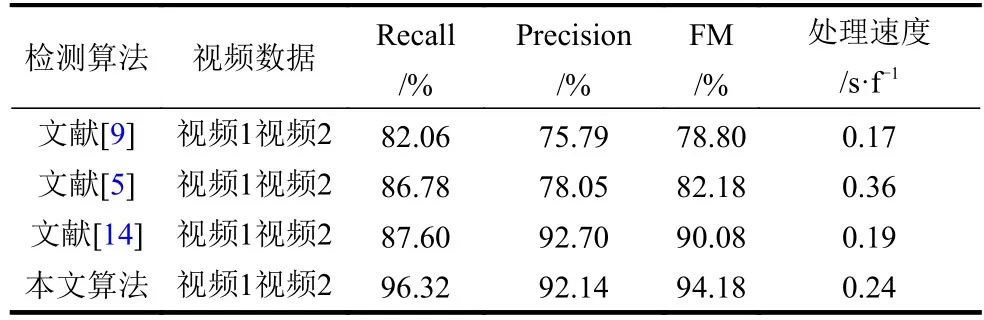
表1 算法评价结果
3 结 束 语
本文为了提高运动目标检测算法在动态背景中检测的完整性及快速性,提出一种改进的基于自适应学习率高斯建模的改进三帧差分算法。针对目标检测过程中背景变换及像素点获取不完整所导致目标内部信息缺失的问题,采用基于自适应学习率的混合高斯背景建模,加快高斯模型的迭代速度,实现背景模型的自适应更新。考虑到基于自适应学习率的混合高斯背景建模算法复杂度仍然较高,且存在边缘不连续的缺陷,提出基于边缘提取的三帧差分改进算法,将采用任意帧间差分法的三帧差分与边缘图像结合,获取更为完整的目标轮廓,并将结果作为基于自适应学习率的混合高斯背景建模算法的补充。本文算法结合了混合高斯建模,能完整地提取目标内部信息,抗干扰能力强,能快速提取目标轮廓、实时性高。实验结果表明,本文算法可以有效地消除动态背景及光照变换造成的干扰,在复杂环境中仍可以完整提取目标。
猜你喜欢
数学小灵通(1-2年级)(2024年4期)2024-05-14 09:30:52
新世纪智能(数学备考)(2021年5期)2021-07-28 06:19:46
小学生学习指导(低年级)(2019年6期)2019-07-22 03:33:10
通信产业报(2016年44期)2017-03-13 08:41:45
信息安全研究(2015年3期)2015-02-28 20:17:57
四川师范大学学报(自然科学版)(2015年2期)2015-02-28 14:07:36
太空探索(2014年1期)2014-07-10 13:41:50
四川生理科学杂志(2014年2期)2014-02-28 14:09:20
雕塑(1999年2期)1999-06-28 05:01:42
雕塑(1996年2期)1996-07-13 03:19:02
