
不同的K-means聚类算法比较研究
2020-02-04 06:33袁健斌樊宇翊伍兴国
电子技术与软件工程 2020年21期
袁健斌 樊宇翊 伍兴国
(1.东莞职业技术学院 广东省东莞市 523808 2.怀化学院 湖南省怀化市 418000)
1 引言
聚类分析作为一种无监督的机器算法,其中将大量的数据分类为在数据对象之间具有相似性的聚类,在探索性数据分析中是一种非常实用的工具,因此研究人员使用它作为分析大型数据的宝贵工具。聚类相当于分组技术:其目的在于使得组与组之间有较大的差异,而每组内部之中差异较小。目前已经设计了不同技术的各种聚类算法,并将其成功应用于各种数据挖掘问题。这些聚类算法会产生高效和高质量的类簇,聚类结果主要取决这几个因素;相似度、初始点和算法的不同选择。
2 相似度的选择
聚类分析的目的在于将相似的数据点尽可能地分为一个类,而将差异较大的点尽量分开,那么如何度量两个数据点的相似度就显得尤为重要。目前相似度的计算主要通过距离和相似系数来进行,需要注意的是,根据距离来聚类一般是绝对聚类,而根据相似系数来聚类一般是相对聚类。如同分析客户偏好一样,如果根据偏好的大小来分析,一般按绝对值来聚类,可以采用距离的方式,而根据偏好的比例来分析,一般是按照相对值来分析,即采用相似系数来聚类。
2.1 基于距离的度量
一般地,计算两点的距离是最为常见的相似度度量方法,通常假设数据空间上的点(a,b)之间的相似度为Sim(a,b),如果数据点(a,b)的距离为(a,b),则可以采用Sim(a,b)=1/(1+d(a,b))得到它们之间相似度,如果两点距离d(a,b)=0,则两点相似度Sim(a,b)=1。两点距离d(a,b)的值较大,那么它们的相似度就小。常用的距离度量方式如下:
(1)欧氏距离:在数学上是通过计算多维空间上两点的距离。如果两个点的绝对值比较接近,那么两点距离较短,两个点的相似度就越高。
(2)其他距离:在数学上,除了欧氏距离外,还存在着其他的度量方式。如曼哈顿距离,其计算公式为:如果把欧氏距离看成是空间两个点的直线距离,那么曼哈顿距离可以理解为空间两个点的折线距离。另外还有切比雪夫距离,也称为最大距离,其计算公式为:很明显这些距离的度量更容易受到量纲的影响,因此在实际运用中并不多见。
2.2 基于相似系数的度量
我们之所以将基于相似系数的聚类称为相对聚类,这是因为将某个样本点各个维度的数据放大或者缩小m 倍,并不会改变他们之间的距离,即d(ma,b)=d(a,b),这一等式在基于距离聚类时并不成立,因为距离聚类是依据样本点的数据绝对大小进行的。即使对样本点的数据进行标准化,也是依据某个维度进行标准化,选择的是某个维度上的均值和方差,在数据表上表现为纵向的处理。而基于相似系数的聚类是某个数据点在不同维度上进行的,统计的是这个数据点的均值和方差(在不同维度上),在数据表上表现为横向的处理,两者存在本质的区别。常见的基于相似系数的度量方式有:夹角余弦相似度和Pearson 相关系数。事实上,可以证明两者是等价的。这种度量方式着重各个维度上相对值,而非绝对值,因此在分析用户习惯、行为和偏好上非常有用。到底选择哪种度量方式,要依据业务目标来定,而不是玩一种数学游戏。
3 初始点的选择
在K-means 聚类算法还需指定聚类数和初始点,初始点也称为中心点或质心(centroid)。传统的K-means 算法假定质心的初始数量是事先已知的,这种对簇数的依赖以及质心的初始选择会影响算法的性能和准确性。如果初始点的选择不恰当,将会导致聚类的结果是局部最优,而这样的局部最优解可能存在很多个。一般常用的确定初始中心点方法如下:
3.1 随机选取
最简单的方法是随机选择K 个点作为初始的类簇中心点,有时候可能选取的点较为接近,因此该方法在有些情况下的效果较差。聚类的结果与初始的类簇中心点有关,而初始点选择具有随机性,因此每次聚类的结果也初始中心点的不同而大相径庭。
3.2 选择远距离点
选取距离尽量远的K 个样本点作为初始的类簇中心点:随机选取第一个样本c1作为第一个中心点,遍历所有样本选取离c1最远的样本c2为第二个中心点,以此类推,选出K 个初始中心点,其中心思想为使得初始的聚类中心之间相互距离尽可能远。
3.3 预处理
先对数据用层次聚类算法或者Canopy 算法进行聚类,得到K个簇之后,从K 个类簇别中分别随机选取K 个点,该点可以是该类簇的中心点,或者是距类簇中心点(均值)最近的那个点,来作为K-means 的初始聚类中心点。
3.4 抽样法
这种方法是对数据按照某种抽样形式进行,常见的有等距抽样、分层抽样等。如等距抽样是指定将观察值1、1 + K,1 + 2K,...分配给第一组,将观察值2、2 + K,2 + 2K,...分配给第二组,依此类推来形成K 个分区或者群组。这K 个组的均值或中位数将用作初始的类簇中心点。也可以将数据划分为K 个几乎相等的分区。即将第一个到第N / K 个观察值分配给第一组,将第二个N / K 观察值分配给第二组,依此类推。这K 个组的均值或中位数将用作初始的类簇中心点。也可以提供了一个初始分组变量,按该变量划分数据集为K 个组,那么这K 个组的均值或中位数将用作初始类簇的中心点。
由于中心点用均值来代表,容易受到“噪声”(奇异点、离群点)干扰,影响聚类的结果,因此提出了K-中心点聚类算法(K-mediods),它不是采用该类簇内样本的均值来计算,而是从聚类的样本点中选取一个,使得在该类簇内其余样本点到这个样本点距离之和最小,并将这个样本点定义为类簇的中心点。这样即使当聚类的样本点中有“噪声”时,也不会受到噪声异常维度的干扰,这样所得质点和实际质点位置偏差不大,从而使类簇发生“畸变”的可能性不大。这种方法改善了 K-means 对“噪声”的敏感,但是计算复杂度上升。
4 K-means聚类算法的思想
B.MacQueen 首先提出了K-means 聚类算法,作为一种经典的聚类算法,目前已有许多应用。K-means 算法的核心思想是将数据分为多个类,使得每个聚类中的数据与类簇中心之间的距离之和最小。K-means 算法是一种基于点的快速迭代聚类算法,最初将类簇中心放置在任意位置开始,然后在每一步迭代过程中,通过移动类簇中心以最大程度地减少聚类错误。该方法的主要缺点在于其对类簇中心初始位置的敏感性。因此,为了K-means 算法能够获得接近最佳的解决方案,可能需要运行多次,而每次运行的类簇中心的初始位置将有所不同。
在给定的观测数据集(x1,x2,…,xn),每一个观测值是一个d 维的实数向量,K-Means 算法是将这些数据集划分为指定的K 个集合{S1,S1,…,Sk},这里的K<n。极小化以下目标函数:
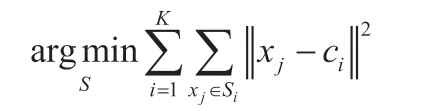
这里的ci是集合Si的中心,一般定义为均值。它的具体算法如下:
(1)从n 个数据对象中选择K 个对象作为初始类簇中心。
(2)根据每个类簇对象的中心,计算出每个对象与中心对象之间的距离,根据最小距离重新分类对象。
(3)重新计算每个类簇的中心点。
(4)计算目标函数,如果满足一定条件,则算法终止;
如果不满足条件,则返回到步骤(2)。
由于K-Means 的吸引力在于其简单性和局部最小收敛性,但它却具有诸如以下的主要缺点:它在计算上的伸缩性比较差,这意味着它可能收敛较慢,并且在完成每次迭代所需的时间方面伸缩性很差,可能需要运行时间较长。
5 不同算法比较
随着计算能力的增长,大型数据集的出现也随之增长,K-means聚类在很多研究领域的分析和数据挖掘进行数据探索非常有用。首先,其易实现、计算效率和低内存消耗使K-means 聚类技术非常流行。与其他聚类技术相比,如连接模型,如层次聚类方法等,这类算法的优点在于可以在数据中搜索未知数量的聚类,但由于是基于相异度矩阵(存储n 个对象两两之间的近似性,表现形式是一个n*n 维的矩阵),计算成本非常高。当然也还包括期望最大化算法和密度模型等分布模型等聚类算法。K-means 聚类的一个次要目标是降低数据的复杂度。最后,K-means 聚类算法作为计算成本更高的算法(机器学习中的学习向量量化和混合高斯模型)的初始步骤,以数据的近似分类作为起点,并降低了数据集中存在的噪声。
通常并不存在绝对的优良聚类算法,这是因为聚类算法的性能依赖于数据集的特征(样本容量和变量个数),因此很多学者建议在给定的数据集上尝试不同的聚类算法,以便获得更优的聚类结果。K-means 聚类可以看作是将整个空间分割成子空间单元,因此类簇又定义为子空间。对于每两个中心点,假设有一条线来连接它们。那么对这条连线的中点做垂线,这条垂线依赖于维度,它有可能是一条直线,或者是一个平面,也或者是一个超平面,把整个空间分为两个独立的子空间。因此,聚类的本质是将整个空间划分为K 个子空间,那么ci本质上是所有子空间所包含元素的中心点。本节将简要剖析三种不同的K-means 算法:Forgy / Lloyd 算法,MacQueen 算法和Hartigan&Wong 算法,来分析简单但功能强大的K-means 聚类技术。
5.1 Forgy / Lloyd算法
Lloyd 算法(1957年)和Forgy 的算法(1965年)都是批量算法中心模型。这个中心是指一个类的几何中心,一般认为是一个类的平均值,这种批量算法是很适合于分析大型数据集。这是因为增量式的K-means 算法需要为每一个案例存储子空间类别,当一个案例被处理时,需要对这两个子空间重新计算中心位置,这样的计算在大型数据集上代价是比较昂贵。Lloyd算法与Forgy算法的区别在于:Lloyd 算法考虑的数据是离散的,而Forgy 算法考虑数据是连续的,除此以外,它们的程序完全相同。在所有算法中,这两者是最简单和最容易实现的。对于含有n 个案例集,聚类算法就是要找到K 个中心位置,使得下面的目标函数达到极小值:
其中ρ(x)为概率密度函数,d 为距离函数。需要注意的是:如果概率密度函数ρ(x)是未知的,那么需要从数据中大致推断出来。
Lloyd 算法的第一步是选择和确认K 个初始中心。可以通过先验经验知识来指定它们,也可以通过数据集的随机选择。一旦选择了初始中心点,就会进行以下两步迭代:第一步,每个案例根据度量距离的远近将其分配到某一个子空间,所有分配到这个子空间的点都视作这个子空间的一部分。第二步是利用子空间内部这些点上的数据来计算新的中心值以便更新中心位置。这两步迭代是重复,在研究者决定的容忍度标准内,中心点位置几乎没有变化,或直到没有案例变化为止。Lloyd 算法伪代码如下:
1-确定聚类的个数K
2-选择和确定要使用的距离度量
3-选择和确定初始中心点的方法
4-确定初始中心点
5-当d(xij,ci)>阈值时
a.对于所有的i 点
i.根据距离将第i 个点分配到最近的类别
b.重新计算中心值
5.2 MacQueen算法
MacQueen 算法(1967年)是一种迭代算法(增量)算法。与Forgy/Lloyd 算法的主要区别是:当每个点改变子空间时,受影响的两个子空间的中心点都会重新计算,并且完整循环一次后,需再次计算每个子空间的中心点。而在首次循环遍历时,中心点是与Forgy/Lloyd 算法的初始化是相同的。当依次遍历每一个点时,如果它离它当前所属子空间的中心点是最近的,那么不做任何改变。如果它与另一个子空间的中心是最近的,那么它将会被重新分配到另一个子空间去,这时旧的和新的子空间都重新计算中心位置。总的来说,当样本进行一次循环时,Forgy/Lloyd 算法的每一个子空间的中心位置是不变的,MacQueen 算法则不断变化子空间的中心位置。而当样本遍历结束后,两个算法都需要重新再次计算每个子空间的中心位置。显然,MacQueen 算法的效率要高Forgy/Lloyd 算法,因为它更新子空间中心点的频率更高,而且通常还需要进行一次完整的遍历以便它是收敛的。MacQueen 算法伪代码如下:
1-确定聚类的个数K
2-选择和确定要使用的距离度量
3-选择和确定初始中心点的方法
4-确定初始中心点
5-当d(xij,ci)>阈值时
a.对于
i.根据距离将第i 个点分配到最接近的群组,
ii.重新计算两个受影响类的中心点
b.重新计算所有类的中心值
5.3 Hartigan&Wong算法
该算法划分数据空间是基于局部最优的组内误差平方和(SSE)。对于某个数据点,即使它目前属于最接近中心点的子空间,它仍然可能将一个数据点分配到另一个子空间去,因为这样做可以使得各个类簇的总和达到最小化。该算法初始化为与Forgy/Lloyd 算法的方式相同,即将其分配到离它们最近中心点的子空间去,而中心点以该组数据点的平均值计算。该算法的迭代过程如下:如果中心点已经在最后一步更新,对于子空间的每个数据点,计算当前子空间的包含数据点的平方和(SSE1,假设子空间号i=1),再将这个数据点移到另外一个子空间去,计算这个子空间的包含这个数据点的平方和(SSE2,对所有i ≠1),如果某一个子空间的SSE2 小于等于当前的类簇(SSE1),那么就将这个数据点分配到新的子空间去。其数学表达式如下:
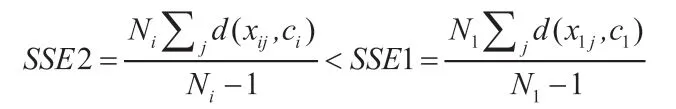
循环往复,直到没有数据点变换子空间为止。Hartigan 和Wong 算法伪代码如下:
1-确定聚类的个数K
2-选择和确定要使用的距离度量
3-选择和确定初始中心点的方法
4-确定初始中心点
5-将案件分配到最近的中心点
6-计算子空间的中心点
7-对于第j <= nb 个子空间,如果中心点j 最后更新一次迭代
a.计算子空间的SSE1
b.对于这个子空间的每一个i 数据点
i.将这个数据点移到新的子空间t,计算这个子空间SSE2(t!=j);
ii.如果SSE2< SSE1,则将改变这个数据点的子空间。否则保持不变。
猜你喜欢
上海文化(文化研究)(2022年3期)2022-06-28
数学年刊A辑(中文版)(2022年4期)2022-02-16
电脑报(2020年12期)2020-06-30
数学年刊A辑(中文版)(2019年3期)2019-10-08
电脑报(2019年4期)2019-09-10
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
中国学术期刊文摘(2016年1期)2016-02-13
少儿美术·书法版(2016年1期)2016-02-06
电子设计工程(2015年6期)2015-02-27
