
基于规则的推荐算法分析和实现
2020-02-04 06:33段继光李建俊仇宾
电子技术与软件工程 2020年21期
段继光 李建俊 仇宾
(河北师范大学附属民族学院 河北省石家庄市 050091)
随着互联网技术突飞猛进的发展和智能终端的广泛普及,信息数据爆炸式增长。面对海量的信息数据,用户无法有效从中获取自己真正需要的信息,产生了所谓的信息超载(information overload)问题[1]。
推荐系统是一种可用来解决信息超载问题的技术方法。与搜索引擎一样,推荐系统也是一种帮助用户查找有用信息的工具。但是推荐系统和搜索引擎又有所不同,搜索引擎实现了用户有明确目的时的主动查找需求,而推荐系统可以在用户没有明确目的的时候帮助他们发现感兴趣的新内容[2]。
推荐系统可以应用到许多互联网应用中,比如基于位置信息的在线购物系统中,由于系统中的商品很多,有效地推荐用户可能感兴趣的、并位于特定位置范围内的商品,是实用且有价值的系统功能。推荐功能可帮助用户高效地查找其感兴趣的商品,提升系统的使用体验和用户黏性,使系统产生更好的效益。
1 推荐系统
推荐系统通过分析用户行为记录,对用户兴趣进行建模,然后主动给用户推荐可以满足其兴趣和需求的信息。推荐系统由用户建模、推荐对象建模、推荐算法三个功能模块组成。
推荐系统的三个功能模块中,核心部分是推荐算法。当前,推荐算法主要分为:基于关联规则的推荐(Association Rule-based Recommendation)、基于内容的推荐(Contentbased Recommendation)、协同过滤推荐(Collaborative Filtering Recommendation)、基于效用推荐(Utility-based Recommendation)、基于知识推荐(Knowledge-based Recommendation)、组合推荐等(Hybrid Recommendation)[3]。
2 基于关联规则的推荐算法
基于关联规则的推荐算法,是依据特定关联规则(数据之间隐含的关联性),在系统中查找符合关联规则的项目,并通过特定指标(置信度)对找到的结果项目进行排序,生成推荐结果推送给用户。
基于关联规则的推荐算法的主要操作过程:
(1)利用关联规则挖掘算法,在系统中查找关联规则,这些关联规则需要满足支持度和置信度阈值要求,我们将找到的关联规则集合记为R。关联规则挖掘算法主要有如下几种:FP-tree、DHP、Apriori、Apriori Tid 等算法。
(2)在集合R 中,使用迭代遍历查找被用户支持的关联规则,我们将其记为R1。所谓被用户支持的关联规则,指的是在规则前边的项目集,是用户曾访问(这里的访问是指浏览、添加购物车、下单购买等操作)过的项目集。
(3)查找那些用户没有访问过,但是被关联规则R1 预测到的项目,这些项目组成的集合记为P。
(4)对集合P 中的项目,根据它们在关联规则R1 中置信度值的大小,将这些项目排序,排名靠前的项目作为算法执行结果。需要特别说明的是,如果出现某个项目被若干个规则同时预测到,就从中选取具有最大置信度的规则为依据,进行排序,生成推荐结果。

图1:Apriori 算法伪码

图2:Apriori 算法Java 模拟程序代码
2.1 关联规则
我们将数据之间的隐含关联性关系称为关联规则。关联规则的定义如下:
设数据项(Item)的集合为I ={i1,i2,is,...,im},事务(Transaction)的集合为T = {t1,t2,t3,…,tm},而且事务集合T 中的任一个事务ti,均为数据项集合I 的一个子集。
关联规则可以用(1)式形式化表示:
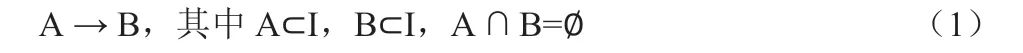
在(1)式中,集合A 和B 为数据项集合I 的非空子集,称为项目集(Item Set),其中集合A 是规则前件,集合B 是规则后件,分别简称为前件和后件。
我们通过某个消费者在线商城购物为例分析:假设用户将牛奶、咖啡、糖三种商品加入购物车并下单购买,那么集合{牛奶,咖啡,糖}就构成了一个事务,在线商城系统中的所有商品组成的集合就是数据项集。而“牛奶→咖啡,糖”就是一个关联规则,规则的前件集合A 为{牛奶},后件集合B 为{咖啡,糖},为简便书写,可以将关联规则中事务的花括号略去不写。
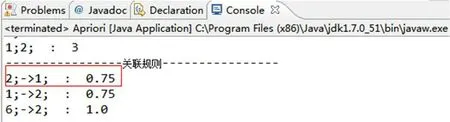
图3:Apriori 算法模拟程序运行结果
2.2 支持度和置信度
我们怎样对关联规则进行评价和衡量呢?通常使用下列两个重要指标:支持度(Support)和置信度(Confidence)。
2.2.1 支持度
针对关联规则 A → B,其支持度是指在事务集合T 中数据项A和B 同时出现的概率,形式化定义如(2)式所示:

若支持度值越大,表示规则左右两个事务同时发生的几率大;相反,支持度值越小,表示规则左右两个事务同时发生的几率小。若支持度的值很小,表示此关联规则基本不成立。
2.2.2 置信度
针对关联规则 A → B,其置信度是指在事务集合T 中,如果A出现,B 也同时出现的概率,形式化定义如(3)所示:

如果置信度值越大,此关联规则就越可能成立;反之,表明此关联规则成立的可能性就越小。也就是说,置信度的值与关联规则成立的可能性大小成正比。
假定系统最小支持度是30%,最小置信度是70%,我们可从中找到下面的关联规则:
r=咖啡→牛奶,
通过分析,可知关联规则r 的支持度为:Support(r)=3/6=50% ,大于最小支持度阈值30%;置信度为:Confidence(r)=3/4=75%,比最小置信度阈值70%大,故可得r 是成立的。
3 Apriori算法
通过前文分析,已知确定一条关联规则的途径。但是我们需要找到系统中全部的关联规则,怎样实现这个目标?对此,我们通过利用Apriori 算法加以实现。Apriori 算法主要包括两个步骤:
(1)通过迭代遍历,查找到事务数据库中的全部频繁项集,即支持度比系统设定的支持度阈值大于或等于的项目集;
(2)利用第一步操作中得到的频繁项集,构造得到符合系统最小置信度阈值要求的关联规则。
Apriori 算法的伪码如图1所示。
Apriori 算法中的两个主要操作步骤通常被称作连接和剪枝,其具体操作过程如下:
3.1 连接
此操作是指为了找到频繁k 项集。具体步骤是:根据系统设定的最小支持度阈值,首先在1 项候选集C1中,将所有小于最小支持度阈值的项集删除掉,就得到1 项频繁项集L1。然后将L1自身连接,生成的集合为两项候选集C2,同理,删除掉C2中小于最小支持度的项集,就得到两项频繁项集L2。以此类推,可以通过将Lk-1和L1链接,生成候选集Ck,然后删除Ck中低于最小支持度阈值的元素,得到频繁k 项集Lk。这一步操作中,主要操作是频繁项集的连接,因此简称为连接。
3.2 剪枝
因为候选集Ck是频繁集Lk的超集,所以不能确定候选集Ck中的哪些元素是频繁的,哪些不是频繁的。对此,扫描候选集Ck中的元素,将元素的支持度和支持度阈值比较,来判断元素是否为频繁的。为了降低复杂度,我们可以对候选集Ck进行剪枝压缩处理。通过Apriori 性质可知:频繁项集的任一非空子集都是频繁的。所以在扫描过程中,若发现候选频繁项集的某个非空子集不是频繁的,就可以确定该候选频繁项集肯定就不是频繁的,进而从Ck中删除掉这个频繁项集,实现对候选集Ck的压缩,提高了处理效率。
通过连接和剪枝两个操作,就可以得到系统中所有的频繁项集。对每一个频繁项集l 的非空子集s,若满足下式:

可得到关联规则:s →(l-s)。
4 基于Apriori算法推荐功能模拟实现
通过前面对Apriori 算法的分析,编写了该算法的Java 模拟程序,程序部分代码如图2所示。
运行结果如图3所示。
在图3 中,程序运行结果中包含2;->1;:0.75 的信息,置信度为0.75,大于0.7 的置信度阈值,表明关联规则“咖啡→牛奶”是有效的,即若用户的历史行为中包含咖啡商品的话,就向其推荐牛奶商品,这和本文前面的分析是一致的。
5 结论
本文简要讨论了推荐系统,和基于规则的推荐算法Apriori 算法,并模拟实现该算法。但如果要在实际环境中使用,还存在下列两个问题:
(1)如何在实际在线购物系统中添加本文中讨论的推荐系统功能?对此,我们可以将推荐系统功能实现为在线购物系统的一个后台模块,通过用户在系统中浏览记录、历史订单等行为记录进行建模,利用算法挖掘关联规则。当用户在访问购物系统时,读取用户的历史行为涉及到的商品数据,再去检索关联规则中是否包含以当前商品为某条关联规则前件的记录,若包含,则把关联规则后件对应的商品推荐给用户。
(2)推荐功能模块性能问题?通过前面对Apriori 算法执行过程分析,可知Apriori 算法的复杂度比较高,面对大数据环境下的关联规则挖掘,实现高效的性能,也是需要进一步思考解决的问题。
猜你喜欢
中国交通信息化(2022年10期)2022-11-17
核科学与工程(2021年4期)2022-01-12
河南水利年鉴(2020年0期)2020-06-09
计算机应用(2018年5期)2018-07-25
轴承(2015年2期)2015-07-25
计算机工程(2014年6期)2014-02-28
长春大学学报(2013年8期)2013-06-21
电讯技术(2011年11期)2011-04-02
中南民族大学学报(自然科学版)(2011年2期)2011-02-07
网络安全与数据管理(2010年1期)2010-05-18
