
面向汉语学习者的作文自动评分系统设计与实现
2020-02-04 06:33张恒源李大卫安佳宁刘洋
电子技术与软件工程 2020年21期
张恒源 李大卫 安佳宁 刘洋
(北京语言大学信息科学学院 北京市 100083)
1 引言
从语言学习的角度来说,写作能力既是培养学生综合语言能力的重要指标,又是评估语言应用水平的首要标准。在采访了50 余名北京语言大学预科学院的留学生,以及负责预科学院C1 班教学任务的教师之后,我们了解到目前教师与学生对于实现针对汉语学习者的作文自动评分系统的期盼。受访的50 余名留学生中,80%都希望系统能够给出对于自身词汇运用水平的判断,能够显示出作文中存在的词汇、语法错误,并且能够在错误位置返回相应的正确用法及其具体含义等。而对于负责汉语教学的教师来说,则更倾向于参考系统针对文章中的错误给出的批注解释和修改意见,以及综合全文给出的整体反馈。同时,在经过市场调研后,我们发现目前市面上并没有一个专门针对汉语学习者的作文评分系统,“In 课堂”针对中文目语者的中文作文进行打分,批改网针对英语学习者的英文作文评分,而在针对非汉语母语者的作文评分上市场仍空白。因此,我们的作品旨在帮助广大汉语学习者评测自身作文水平,提升写作能力,从而更好地促进汉语学习。
2 系统的设计与实现
本文系统设计的思路图如图1所示。
2.1 各功能的设计与实现
2.1.1 数据集
如表1所示,本文采用的数据集由北京语言大学智能语言学习课题组所提供,数据中的样本包含文章题目,文章内容,文章得分三个字段。
2.1.2 原文点评
本文调用智能语言学习课题组的改错API,然后把API 的返回结果作为原文点评的内容,包括错词的个数,错词的高亮显示,错词的修改建议。
2.1.3 词汇拓展
在获取到用户文章中的错误词语后,本文使用程序自动在汉语大词典中检索这些词语,提取这些词语的用法、释义、例句、词性并且我们将例句分好词,释义英文化,错词高亮显示来方便留学生学习,以此来作为词汇拓展。
2.1.4 词汇水平指标
本文遍历文章的所有词然后统计各个词汇等级的词数,这里的词汇等级本文以HSK(汉语水平考试)等级为标准。对于一篇文章,若等级为 i 的词共有 xi个,则通过以下公式计算词汇水平指标Mw:
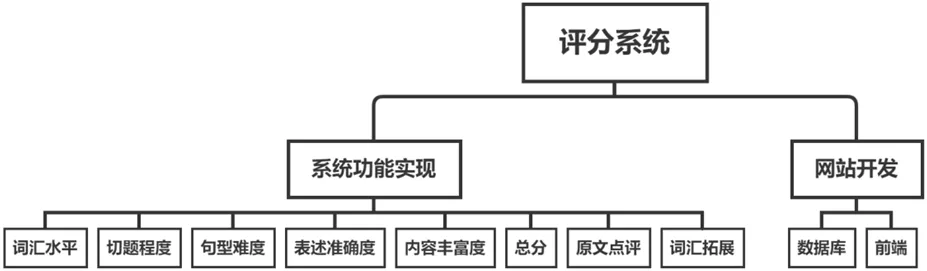
图1:系统设计思路图

其中k 表示词汇等级的总数,pi表示文章中等级为i 的词所占的比例。
2.1.5 切题程度指标
切题程度指的是作者写作的文章是否与题目所设定的主题相符。为了衡量切题程度,本文提出了三种模型来计算文章与题目之间的相似性。
(1)数据预处理。图2 展示了本文数据集中各个分数段的分布情况,根据评分规则,以及数据集各个分数段数据的分布,本文认为80 分以上的作文在切题方面为满分,作为正样,Label 标为1.0,同时选取一些作文并随机放上与之不相干的题目作为负样本,认为其切题分数为0 分,Label 标为0.0,以此来构建研究切题程度指标的数据集,表2 给出了本文切题指标数据集的几个例子。将此数据集随机打乱并划分为训练集,验证集和测试集,其中训练集为3200 条,验证集为500 条,测试集为544 条。
(2)模型一。
考虑到文章与题目之间长度差异较大,本文首先提取文章中的主题词,然后比较这些主题词与题目之间的相似性。
在进行前期的相关调研之后,了解到用来提取文章关键词的主流方法[4]有TextRank,TF-IDF,LDA,LSA 等。由于是要与文章题目进行相似度匹配,考虑到TextRank 和TF-IDF 只能从文章里存在的词提取关键词,其用来解决相似度问题的表现会比LDA,LSA等主题模型的效果差;此外,由于LSA 模型的运行速度较慢,每次有新的文章进入都需要重新训练,所以最后决定基于LDA 模型来解决主题词的提取问题。
为了训练LDA[3]模型,我们使用了HSK 作文语料。我们使用的HSK 作文语料中包含29 个不同的题目,每个题目下有若干篇文章。部分题目所包含的篇章数如表3所示。

表1:数据集示例

表2:切题指标数据集
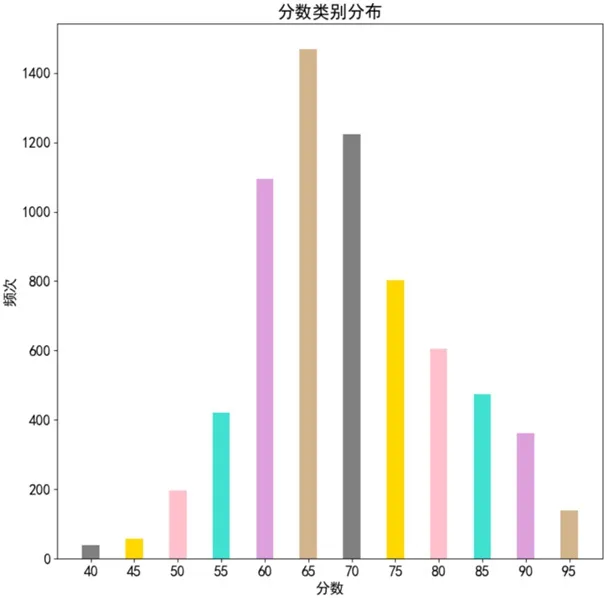
图2:各个分数段的分布
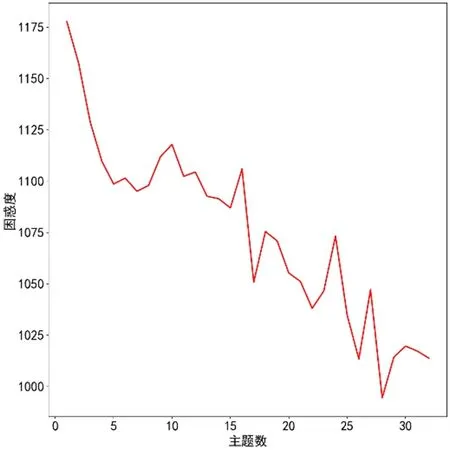
图3:困惑度与主题数关系
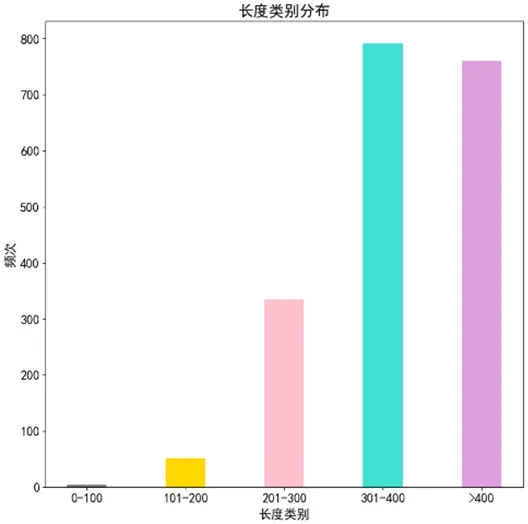
图4:长度类别分布
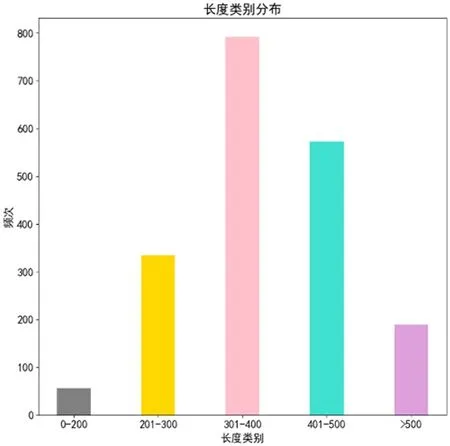
图5:长度类别分布
在训练LDA 模型时,根据LDA 模型主题数和困惑度的关系[5]来确定主题数目。
根据如图3所示困惑度和主题数之间的关系,可以发现主题数在28 附近困惑度达到不错的表现,所以最终本文将主题数定为28。
使用LDA 获得文章的主题词后,本文获取每个主题词对应的词向量。这里使用的词向量是使用fasttext 的预训练词向量 。随后,将这些词向量加和求平均以获取篇章向量。类似地,获取题目中每个词的词向量,并使用加和求平均的方式获取题目向量。最后,计算篇章向量和题目向量之间的余弦相似度[6],获取切题程度指标,公式如下:

其中wtitle为各个题目词的词向量,n 为题目切分出的词数,wLDA为各个文章关键词的词向量,m 为LDA 确定的主题词数,t为题目向量表示,d 为文章向量表示,score 为最终的切题程度分数。
(3)模型二。
同样,用每个样本题目词向量(word2vec)加和平均的结果和文章关键词向量(LDA 提取)加和平均的结果,将其拼接起来通过一个全连接层和sigmoid 层,损失函数为交叉熵,然后以此结构训练模型,公式如下:

其中dtd 为t;d 通过全连接层得到的标量。
(4)模型三。
本文在模型二的基础上进行了改进,将每个句子通过BERT[7]获得每个词的词向量表示,再把句子中各个词向量加和求平均获得句向量表示,然后将题目的句向量和文章的句向量依次通过一个LSTM[8],取最后一个隐藏层的输出依次通过全连接层和sigmoid 层,训练过程中损失函数为交叉熵。

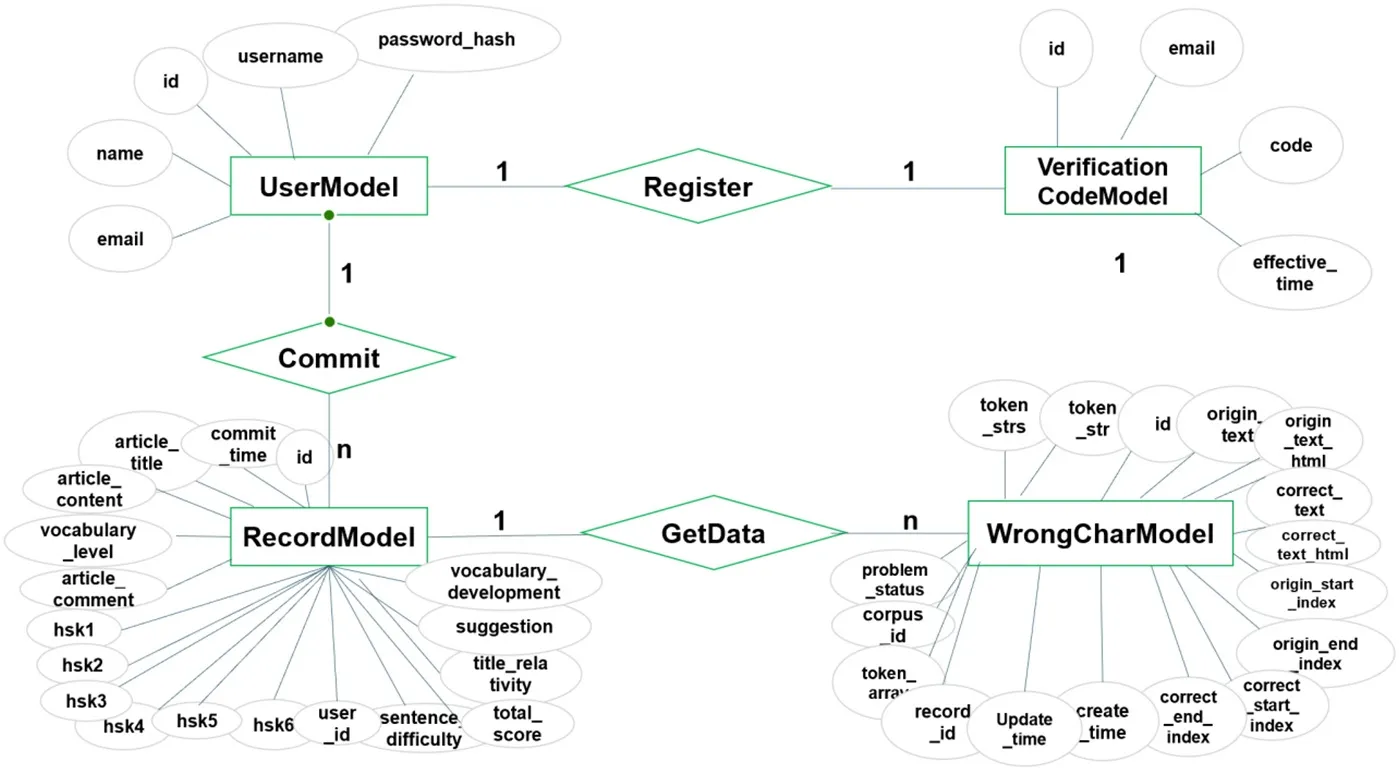
图6:E-R 图模型
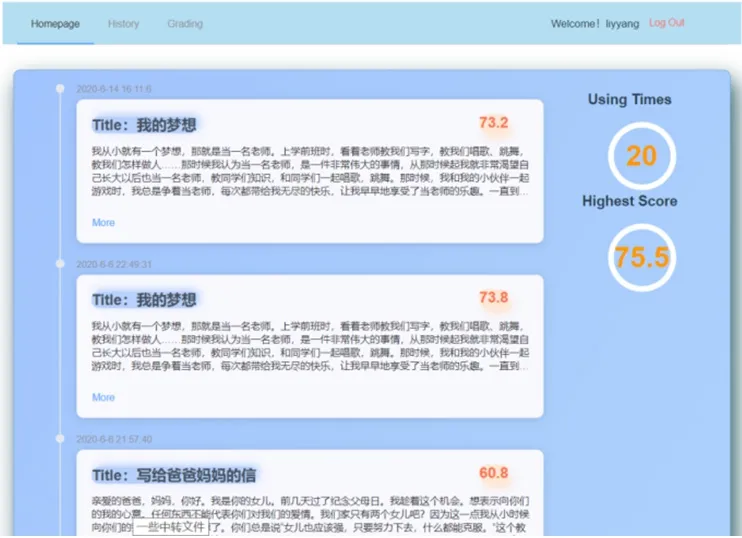
图7:用户主页界面
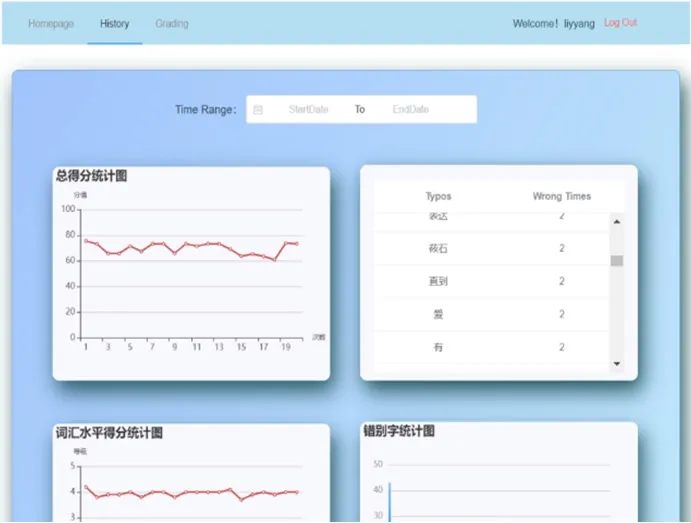
图8:历史记录界面

其中wij为文章第i 句的第j 个词通过BERT 后的词向量,ni为文章第ii 句的总词数,s0为题目句向量,si为文章内容第i 句的句向量,th为各个句向量依次通过LSTM 之后最后一个隐藏层的输出。
(5)三种模型的评估。
综合三种模型测试结果得出表4。
通过表4 可以看出,在切题情况下,模型一输出的平均值为0.5390,不切题情况下的平均值为0.4841;模型二在切题情况下,输出的平均值为0.5190,不切题情况下的平均值为0.4802;模型三在切题情况下,模型输出的平均值为0.6833,不切题情况下的平均值为0.3689,且模型三在不切题的情况下,其切题指标的最小值更接近于0,可见模型三在三种模型当中表现最佳。
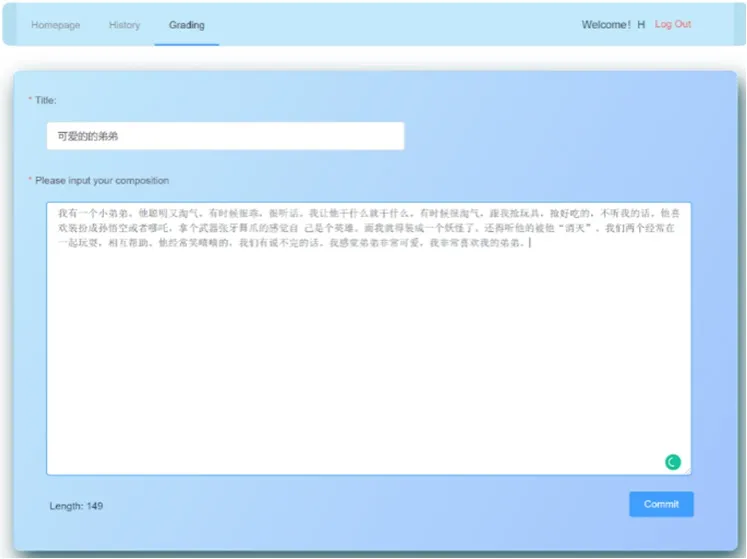
图9:新建评分界面
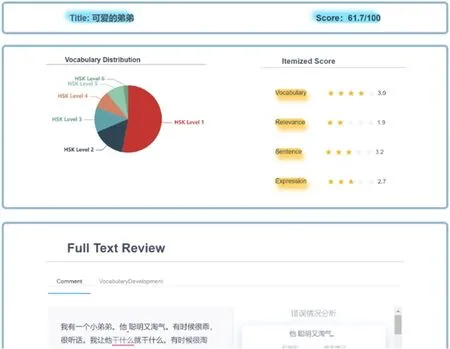
图10:评分结果界面
2.1.6 句型难度指标
本文选择Stanford 开源的句法分析器 来进行句法分析,因为它以权威的宾州树库作为分析器的训练数据,并且能提供多样化的分析输出形式,而且支持多平台并封装了多种常用的语言接口,包括该项目的开发语言Python。
本文先在分词后的文章的基础上,利用Stanford 开源的句法分析器来得出文章的句法树,在参考相关文献之后,以句法树的高度,文章的连接词密度(连接词词数/总词数)和文章里每个句子的平均长度来得出句型难度指标。
2.1.7 表达准确度指标
本文通过文章中错误词语的数量来定义表述准确度。在对文章进行错误修改后,将错误词语数占文章词语总数的比例作为表述准确度。
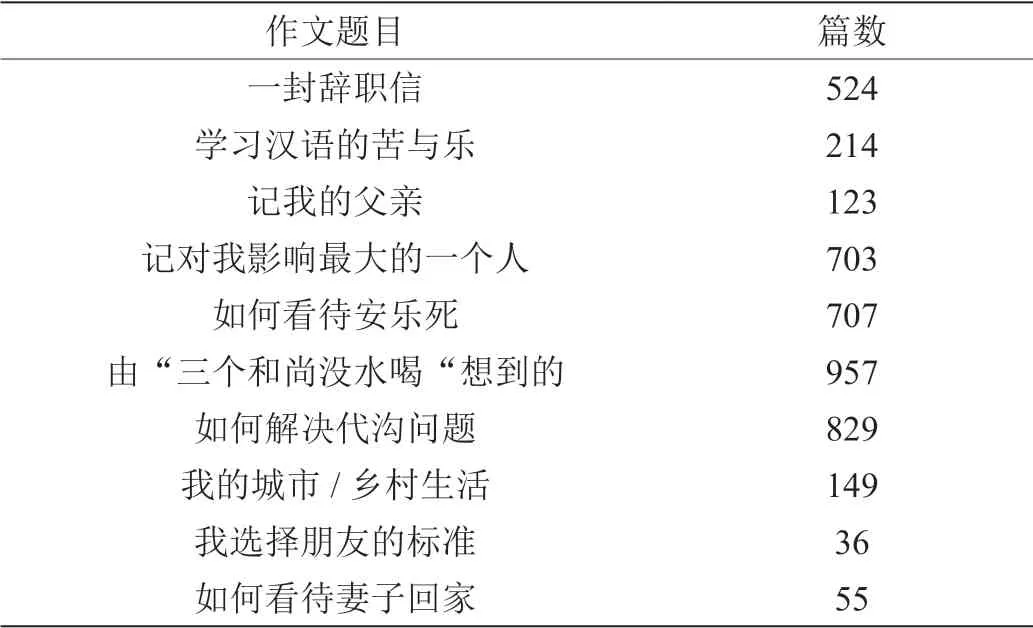
表3:部分题目包含篇章数
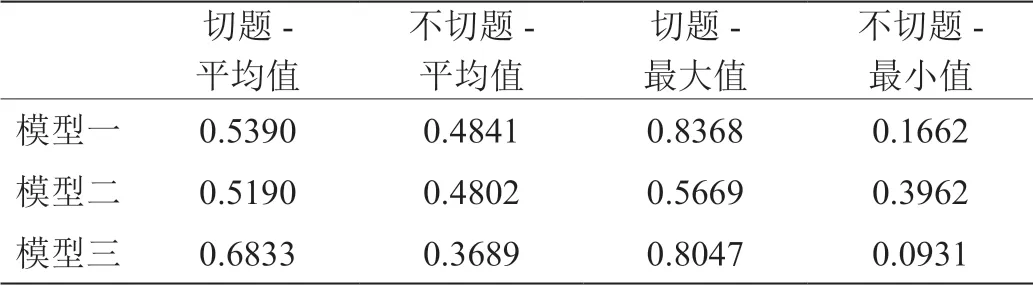
表4:三种模型测试结果
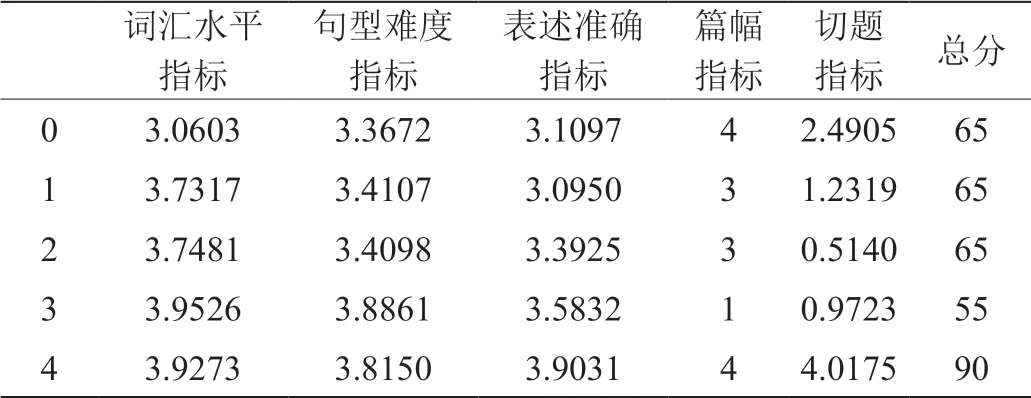
表5:更新后数据集
2.1.8 内容丰富度指标
本文根据文章的篇幅长度来得出内容丰富度指标(满分5 分)。初期定义字符数在0-100 之间的文章该指标得分为1,101-200 得分为2,201-300 得分为3,301-400 得分为4,>400 得分为5,以此规则得到数据集中样本的分布如图4。观察数据以后,发现该规则得出来的分布并不服从正态分布,且0-100 和101-200 的样本数量较少,所以本文将这两类合并成一类,制定新的规则为,0-200 为1 分,201-300 为2 分,301-400 为3 分,401-500 为4 分,>500 为5 分,该规则对应的分布如图5。
2.1.9 总分
文章总分使用上述5 个指标拟合得出。因为文章的每个指标都和文章的总分成正相关,所以本文使用非负约束的Lasso 回归来拟合总分分数。先把train数据集下的每篇文章的各个指标的分数得出,然后与其相应的人工标注的总分对应,得出的数据集如表5所示。
本文以1600 条数据作为训练集,344 条数据作为测试集,经过迭代之后得到函数的weights 和bias。在测试集中的准确率目前为0.4125(预测分值与正确分值的差值绝对值如果小于2,则认为预测正确)。
2.2 数据库设计
本文采用ORM(Object-relationalmapping)技术来操作数据库,使用SQLALCHEMY 框架。本文首先设计了E-R 图模型,如图6所示。
基于E-R 图模型,设计对应Flask 框架下的映射表。
2.3 前端设计
首先,在理清各界面的跳转逻辑之后,前端人员根据之前对用户功能的设想,以手绘的方式对网站进行了原型设计。
通过绘制原型图,前端人员对系统的样式设计有了大体思路和初步方向,之后便正式开始了Web 前端的构建。本文选用Vue.js渐进式框架,其优势在于,除具备页面渲染、表单处理提交、管理DOM 结点等基础功能之外,还支持组件化开发,极大程度地方便在编程中实现代码的复用,以及快速扩展新的功能组件和新的页面。
在项目的后续开发中,本文引入了Element-UI 组件库,运用组件库中的组件实现了各界面的初始功能。
对于后端返回的数据,本文选用Echarts 图表库绘制图表,对项目数据进行可视化处理,使得留学生能够直观地了解到自身写作水平,从而能够更有针对性地提高自身写作能力。
在对界面的初始功能及逻辑关系进行充分测试、确认各界面的跳转及交互均可准确快速的进行之后,前端人员结合产品自身特点,利用绘图软件,为初始界面和登录、注册界面分别设计了背景图。
之后,前端人员对各界面的样式和布局进行了进一步地渲染及美化。
考虑到系统目标受众中文水平可能参差不齐,本文在系统的后续完善阶段还新增了语言切换功能,使用户可以实现中英文一键切换,从而根据自身的语言能力更好地使用系统,增强了用户的体验感。
前端设计的最终结果展示如图7-图10所示。
3 结语
随着我国综合国力的提升,来华留学生的数量与日俱增。本文针对汉语学习者设计并实现了一个作文评分系统,通过词汇水平、切题程度、句型难度和表达准确度四个指标来得出文章总分,并对文章中的错误进行批改,给出词汇拓展。本系统不仅可以应用于留学生的自学提高,也可为对外汉语教师的教学提供方便。未来还需进一步地提取出更多指标来优化系统的评分表现。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
中华胰腺病杂志(2021年1期)2021-02-26
山东医药(2020年34期)2020-12-09
中华胰腺病杂志(2019年4期)2019-08-29
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
中华胰腺病杂志(2012年3期)2012-11-07
对联(2011年18期)2011-09-19
对联(2011年8期)2011-09-18
