
基于大数据建模网络的客户满意度研究
2020-02-04 02:04姜群
电子技术与软件工程 2020年20期
姜群
(中国移动通信集团云南有限公司 云南省昆明市)
在通信企业中,体验满意度评价体系通常包含网络、服务和业务三方面。基于统计分析,用户最关注网络因素,建立主观网络满意度调研结果和客观指标间的对应模型,能够更有针对性和更有效的指导业务主管部门采取更加合理的网络优化措施。
网络监控和日常维护业务质量指标繁多,暂无较为有效手段分析各类与用户感知体验强相关的指标。导致基于部分指标异常的网络优化措施落地后,用户满意度并没有显著改善。为此,开展了大数据建模网络满意度应用研究,研究关注调研问卷设计与分析、主客观关联建模与满意预测的解决方案。
1 大数据建模网络满意度整体方案
1.1 调研设计与分析
调研设计包括问卷内容制定、抽样方法、样本数量、调研客群和调研方式等内容。按场景划分调研用户群,将用户打分和场景对应客观体验指标关联分析,运用数据挖掘技术分离出客观样本,引入聚类、单变量异常检测、局部异常因子、离群点检测等关键技术,剔除与网络体验客观指标不一致的无效样本,对样本分布、与友商的对比和满意度与提及率的关联进行分析,进行有效的调研和获取合格的样本数据,提高训练集样本质量,提升模型预测性能。
1.2 建模与满意度预测
通过将主观调研样本数据与体现用户网络体验的客观数据相关联,引入IV(信息价值增益)算法,对建模候选指标集实施特征工程,识别预测性能好的关键指标,剔除相关性低的指标,减少干扰因素,进行建模和模型调优,实现对全量用户的满意预测和特征指标识别。
2 调研设计与分析
2.1 调研问卷设计
2.1.1 问卷设计原则
问卷设计确保最佳访问效果,访问时长控制在3 分钟内;满意度指标在问卷中采取十分制进行询问,语音贴合客户受访习惯;结构化与非结构化问题相结合,给被访者以表达空间[1]。
2.1.2 测评维度与重点
从网络、服务、业务等维度建立多层级的指标体系,用于推荐、中立、贬损原因归类,见图1。
2.2 样本数量要求
根据科克伦在抽样技术中关于样本容量的定理:“唯一完全精确的样本是普查,随机样本并不精确,必定会产生抽样误差[2]。”随机样本容量越大,精确度越高,抽样误差越小。每次抽样最少样本数量3 万份,其中,模型训练2 万份,模型校验1 万份;最优样本数量5 万份,其中模型训练3 万份,模型校验2 万份。
3 大数据建模与满意度预测
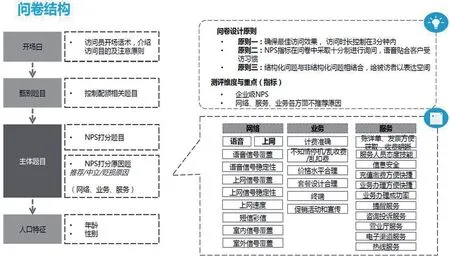
图1:问卷结构

图2:特征工程增强
3.1 客观数据准备
客观数据由网络指标体系构成,数据准备主要包括:
自然日单用户级的粒度数据,SEQ(网络性能管理)平台PSPU(每用户每业务)探针话单XDR 数据、无线MR(Measurement Report)/CHR 数据、B 域(Business Support System);
数据累积要比调研提前1-4 周开始。且累积周期要和调研周期保持基本一致。因调研时用户反馈的一般都是1-4 周前的使用感受;
对用户级数据清洗和预处理。含空值替换、删除重复值和异常值、指标转换、指标间关联及降维处理等;
引入IV 算法,对建模候选指标集实施特征工程,识别预测性能好的关键指标,剔除相关性低的指标,减少干扰因素,提升模型预测性能,见图2。
3.2 大数据建模与预测
预测潜在不满意用户,需要使用到预测类相关大数据挖掘算法,该模型采用了二分类预测算法来实现[3]。通过对常见的逻辑回归分类算法尝试对比,选择在随机森林(多个决策树)算法的基础上增强和优化,得到最适合本场景的二分类预测算法,采用二分类随机森林建模结合机器学习技术,专注贬损预测[4]。主要过程如下:
3.2.1 样本分区
避免出现过拟合的现象,采用了对训练模型的数据源进行划分。一部分用于建模,一部分用于评估模型的方法来验证模型结果是否具备普遍适用性。一般情况下,参与模型训练的数据占整体数据集的70%以上。

图3:大数据建模指标集

图4:五轮建模调优
3.2.2 样本平衡
在建模过程中,调研样本中正样本(不满意)的数量占比30%,少于负样本(满意),为了提高不平衡数据分类的准确率,通过抽样与欠抽样用于样本平衡。
3.2.3 特征分析与选择
TMF(TeleManagement Forum)建议了使用阶段各类业务的KQI 体验点和体验指标,包括了覆盖、语音和上网三个方面指标。
为提高模型准确性,减少模型过拟合的风险,加快训练速度,方便数据可视化和增强模型的可解释性,特征选择是文章研究的关键。研究主要针对上网和语音场景划分指标集,指标集映射支撑不同场景,并根据IV 算法,制定出参与建模的强相关指标和重要性指数,最终实现270 个场景化指标精准汇聚及建模,见图3。
3.2.4 效果评估
经过五轮的大数据建模持续调优,模型查准率保持在68%,查全率提升到75%,超过60%的平均水平,见图4。为进一步扩大研究成效,校准实验数据,大数据建模网络满意度模型在昆明手机上网和VOLTE 语音业务中试行,实现核心网、SP、终端、小区等网络端到端贬损问题定位整治和客户感知精准修复。经过为期一年的运行后,对收集到的客户体验和调研数据进行分析,贬损客户数减少15%,客户体验KQI 指标显著改善,网络满意度领先度(客户调研满意度表现值领先友商水平)0.9,较模型部署应用前提升1.9,取得了较为明显的成效。在云南移动的实践应用,为全国其他省公司以及其他行业提供了可借鉴的理论和实践案例。
4 结论
通过大数据建模,建立主观网络满意度调研结果和客观指标间的对应模型,识别潜在不满意用户,再将用户聚集到问题小区和网元,能够更有针对性和更有效的指导采取合理的网络调整和优化措施,确保最终网络满意的提升。
猜你喜欢
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
人大建设(2019年2期)2019-07-13
人大建设(2018年10期)2018-12-07
电子制作(2018年17期)2018-09-28
知识经济·中国直销(2018年8期)2018-08-23
通信电源技术(2018年5期)2018-08-23
红土地(2016年9期)2016-05-17
中国老区建设(2016年1期)2016-02-28
现代防御技术(2014年6期)2014-02-28
网吧世界(2009年1期)2009-02-26
