
一种基于NLq损失的Softmax分类模型改进
2020-01-26 05:49罗光华
电脑知识与技术 2020年34期
罗光华

摘 要:对Softmax回归分类模型,使用基于变形q阶对数的NLq损失代替常用的交叉熵损失。通过实验证明,在使用较小的训练集时,以NLq为损失的Softmax分类模型具有更高的正確率和更好的泛化能力。
关键词:NLq损失;交叉熵;Softmax分类;加权
中图分类号: TP181 文献标识码:A
文章编号:1009-3044(2020)34-0228-02
Abstract:The NLq loss based on modified q-order logarithm is proposed . It is used to replace the CrossEntropy loss in softmax regression classification model. The experimental results show that the softmax classification model with NLq loss has higher accuracy and better generalization ability in smaller training sets.
Key words: NLq loss; CrossEntropy; Softmax classification;weighted
1 引言
在有监督学习中,损失函数用来衡量预测值与真实值之间的差异,通过使损失代价函数最小化,到达优化预测模型的目的。不同的损失函数会影响预测模型的参数值进而影响预测正确率。交叉熵(CrossEntropy)损失是多分类任务中Softmax回归分类的损失函数,也是分类模型下的负对数似然损失,该损失基于最大似然估计法,主要在训练数据较大情形下表现良好,但在小数据集下则未必[1,2]。目前,使用变形q阶对数进行模型参数估计已经被证明具有一定的稳健性[3,4],因此可在此基础上对交叉熵损失进行扩展,建立负q阶似然损失函数(NLq)用于Softmax分类,并与使用传统交叉熵损失的Softmax分类模型进行比较分析。
2 使用交叉熵损失Softmax分类
4 实验与结果
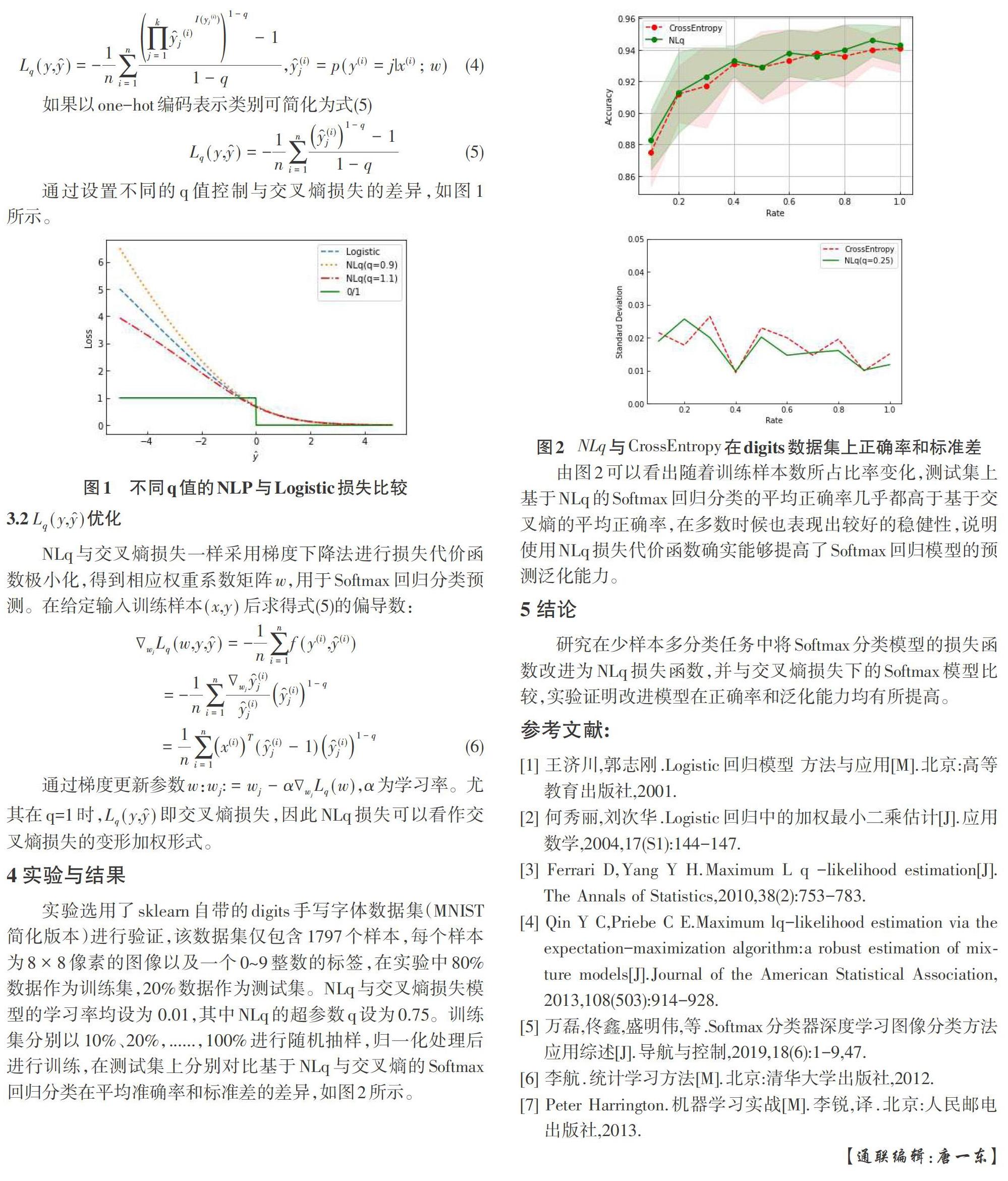
实验选用了sklearn自带的digits手写字体数据集(MNIST简化版本)进行验证,该数据集仅包含1797个样本,每个样本为[8×8]像素的图像以及一个0~9整数的标签,在实验中80%数据作为训练集,20%数据作为测试集。NLq与交叉熵损失模型的学习率均设为 0.01,其中NLq的超参数q设为0.75。训练集分别以10%、20%,......,100%进行随机抽样,归一化处理后进行训练,在测试集上分别对比基于NLq与交叉熵的Softmax回归分类在平均准确率和标准差的差异,如图2所示。
由图2可以看出随着训练样本数所占比率变化,测试集上基于NLq的Softmax回归分类的平均正确率几乎都高于基于交叉熵的平均正确率,在多数时候也表现出较好的稳健性,说明使用NLq损失代价函数确实能够提高了Softmax回归模型的预测泛化能力。
5 结论
研究在少样本多分类任务中将Softmax分类模型的损失函数改进为NLq损失函数,并与交叉熵损失下的Softmax模型比较,实验证明改进模型在正确率和泛化能力均有所提高。
参考文献:
[1] 王济川,郭志刚.Logistic回归模型 方法与应用[M].北京:高等教育出版社,2001.
[2] 何秀丽,刘次华.Logistic回归中的加权最小二乘估计[J].应用数学,2004,17(S1):144-147.
[3] Ferrari D,Yang Y H.Maximum L q -likelihood estimation[J].The Annals of Statistics,2010,38(2):753-783.
[4] Qin Y C,Priebe C E.Maximum lq-likelihood estimation via the expectation-maximization algorithm:a robust estimation of mixture models[J].Journal of the American Statistical Association,2013,108(503):914-928.
[5] 万磊,佟鑫,盛明伟,等.Softmax分类器深度学习图像分类方法应用综述[J].导航与控制,2019,18(6):1-9,47.
[6] 李航.统计学习方法[M].北京:清华大学出版社,2012.
[7] Peter Harrington.机器学习实战[M].李锐,译.北京:人民邮电出版社,2013.
【通联编辑:唐一东】
