
融入逻辑关系的项目调度遗传算法
2020-01-16 08:24:34宋元斌李云祥
计算机工程 2020年1期
刘 尧,宋元斌,李云祥
(上海交通大学 船舶海洋与建筑工程学院,上海 200240)
0 概述
随着工程项目规模的不断扩大,解决施工进度计划的快速编制问题变得越发重要。施工进度计划的快速编制主要包括两项关键技术,即施工顺序的表述模型和与之对应的求解算法。施工顺序知识用于推导进度计划编制中施工活动的先后顺序,为工程模型到数学模型的转换提供依据;调度模型的求解是一种典型的NP难问题,根据不同的调度模型有不同的求解方法。
复杂施工排序方案中的表述问题主要分为两类。第一类为施工活动的时间顺序表述问题,主要用于推理进度计划中的施工活动先后顺序。文献[1]用时间区间描述活动的持续状态,并定义了2个时间区间之间的13种关系。后续研究者在其基础上扩展引入了最大时间间隔[2]、负时间间隔[3]和时间约束柔性[4]等概念,解决了施工活动顺序表达上的大部分难题。第二类为施工计划中的逻辑关系表述问题,即施工活动与时间关系间的逻辑关系,许多学者对其进行了研究。文献[5]使用Disjoint描述2个时间关系之间存在“Or”逻辑关系。文献[6]用包含(→)、等价(↔)和异或(⊗)3个逻辑运算符来描述逻辑关系。文献[7]提出活动之间的互斥和共存关系,用以描述备择施工方案之间的关系。
研究者在调度模型的算法设计中,会依据时间约束[8]、资源约束[9]等条件改进算法,也会直接使用调度工具[10]进行求解。文献[11]在电网规划上使用布尔变量来简单表示区域电网投运与否的状态,从而计算电网的最小成本。文献[12]将传统遗传算法与模拟退火算法相结合来解决Web服务组合质量优化问题。文献[13]用改进的遗传算法对BP神经网络的初始权重进行赋值,用以加快神经网络的收敛速率。上述规划模型采用互相独立的布尔变量表示简单逻辑关系进行遗传算法的改进设计,均未解决复杂逻辑关系的计算难题。
求解调度模型主要分为精确式算法和启发式算法。精确式算法受线性规划求解器容许决策变量数目的限制,在求解中小规模的调度问题时具有速度快、结果精确的优点,但在求解带有大量逻辑关系的超大型复杂调度模型时,却表现出时间效率低下的问题,不能满足一些规模庞大的优化调度问题求解需求。启发式算法主要用于快速有效地求解大规模问题的较优解。因此,采用启发式算法求解带有较多逻辑关系的复杂调度问题是合理的选择。
遗传算法是一种经典的启发式算法,被广泛应用于工程计划,如施工项目[14]、流水作业[15]、高速公路建设[16]等。为了满足特定领域的需求,研究者也会对遗传算法进行相应改进。文献[17]通过改进交叉算子,解决了含有多个目标的最优化模型求解问题。文献[18]在处理装配式建筑构件运输问题上,加入运输节点的权重计算,加快种群的收敛速度。由于上述算法没有考虑工程模型中的备择和依存关系,因此难以描述复杂调度模型中的逻辑关系。
本文基于文献[6]的逻辑运算符,增加了逻辑符XOR、XNOR和IF-THEN来表示活动之间和时间关系之间的逻辑关系,编程实现复杂调度模型到混合整数规划模型[19]的自动转换,并提出一种解决该问题的改进遗传算法,采取基于工程逻辑关系布尔变量划分的顺序编码方式,将染色体划分为独立变量和半独立变量编码基因段,从而解决带有大量依赖逻辑关系的调度模型求解问题。
1 调度模型中逻辑关系的表述
本节在探究时间关系之间的互斥(XOR)与共存(XNOR)逻辑关系基础上,提出用“IF-THEN”表示活动或时间关系之间存在的依赖逻辑关系,同时探究将其转化进入混合整数线性规划的数学理论方法。文中符号说明如表1所示。

表1 符号定义说明
为说明包含时间关系的逻辑关系,本文引入布尔决策变量ER(i,j)用以描述时间关系之间的逻辑关系,下标中R表示该变量为时间关系的布尔变量,(i,j)表示此为描述活动i和活动j的时间关系。如果一个时间关系R(i,j)被选择执行,则对应的决策变量ER(i,j)被赋值为1,否则赋值为0。

(1)
逻辑关系的线性约束表达如表2所示。
表2 逻辑关系与线性约束的关系
Table 2 Relationship between logical relations and linear constraints

逻辑关系线性约束活动i与j为互斥关系Ei + Ej = 1活动i与j为共存关系Ei = Ej活动i与j为依赖关系Ei ≤ Ej活动i与时间关系R(j,k)为互斥关系Ei + ER(j,k) = 1活动i与时间关系R(j,k)为共存关系Ei = ER(j,k)活动i与时间关系R(j,k)为依赖关系Ei ≤ ER(j,k)时间关系R(i,j)与R(k,l)为互斥关系ER(i,j) + ER(k,l) = 1时间关系R(i,j)与R(k,l)为共存关系ER(i,j) = ER(k,l)时间关系R(i,j)与R(k,l)为依赖关系ER(i,j) ≤ ER(k,l)
2 复杂调度模型的建立与求解
为克服精确式算法求解带有大量逻辑关系的超大型工程存在的不足,本文设计了基于布尔变量划分的顺序编码方式,在遗传算法中对违反约束规则的个体进行了修正。
2.1 调度模型
施工调度计划最主要的任务之一是确定最短工期下的施工排序方案。本文的调度模型优化目标使项目结束时间FP最小。计算工期的混合整数线性规划模型如下:
目标函数如式(2)所示。
MinZ=FP
(2)
约束条件如式(3)~式(17)所示。
a′×Si-a′×Sj+Di+L(i,j)≤0
∀R(i,j),1≤i≤n,1≤j≤n
(3)
a′×Si-a′×Sj+EAi×Di+L(i,j)≤0
∀R(i,j),1≤i≤n,1≤j≤n
(4)
a′×Si-a′×Sj+Di+L(i,j)-M(1-ER(i,j))≤0
∀R(i,j),1≤i≤n,1≤j≤n
(5)
a′×Si-a′×Sj+EiA×Di+L(i,j)-
M(1-ER(i,j))≤0,∀R(i,j),1≤i,j≤n
(6)
Si≥0,i=1,2,…,n
(7)
Si+Di≤Fp,i=1,2,…,n
(8)
Ei+Ej=1,iXORj
∀i,j,1≤i≤n,1≤j≤n
(9)
Ei=Ej,iXNORj,∀i,j,1≤i≤n,1≤j≤n
(10)
ER(i,j)+ER(k,l)=1,R(i,j) XORR(k,l)
∀R(i,j),R(k,l),1≤i,j,k,l≤n
(11)
ER(i,j)=ER(k,l),R(i,j) XNORR(k,l)
∀R(i,j),R(k,l),1≤i,j,k,l≤n
(12)
Ei≤Ej,IFiTHENj
∀i,j,1≤i≤n,1≤j≤n
(13)
Ei≤ER(k,l),IFiTHENR(k,l)
∀i,1≤i≤n,1≤k,l≤n
(14)
ER(k,l)≤Ej,IFR(k,l) THENj
∀i,1≤k,l≤n,1≤j≤n
(15)
ER(i,j)≤ER(k,l),IFR(i,j) THENR(k,l)
∀i,j,1≤i,j,k,l≤n
(16)
Ei,Ej,ER(i,j),ER(k,l)∈{0,1}
(17)
目标函数是项目工期的最小化,式(3)是2个确定执行的活动之间的时间关系约束的一般形式,式(4)~式(6)是活动时间关系的逻辑表示,式(7)限定了所有活动的开始时间均大于等于0,式(8)则限定所有活动必须在工期之内完成,式(9)~式(16)是2个备择活动或备择时间关系之间的逻辑关系表达式,式(17)定义各决策变量为布尔变量。
2.2 遗传算法求解
基于布尔变量划分的顺序编码方式,本节提出一种遗传算法,将染色体分为独立变量和半独立变量编码基因段,以原调度模型中的最短工期的倒数为适应度函数,进行最优解的搜索,编程实现带有较多逻辑关系调度模型的启发式求解。该算法借鉴动态规划的思想[20-22],采用单点交叉与变异,存储了父代种群运算结果,将新生成的子代与父代进行比对,相同编码即可采用同样的适应度运算结果,有效提高了遗传算法的运算效率。在遗传操作后进行冲突检测,消除由于种群初始化、交叉和变异操作生成的违反约束规则的个体。
2.2.1 布尔变量的顺序编码
在解决传统调度优化问题的大多数遗传算法中,染色体编码中的各个基因相互独立,迭代过程中各基因取值不受其他基因取值的影响,但式(13)~式(16)表明决策变量Ei及ER(i,j)之间存在依赖关系。为描述该依赖关系,本文在基因链编码设计中加入半独立变量。
在本文模型中所有布尔变量共分为3类:独立变量,半独立变量和派生变量。独立变量指在众多变量中不受其他变量取值影响的变量,半独立变量指在其他变量确定后仍有一定取值范围的变量,派生变量指在独立变量和半独立变量确定后取值就确定的变量。
本文算法采用基于布尔变量划分的顺序编码方式,将整个编码区域分为独立变量区域(I区)和半独立变量区域(II区)。
1)布尔变量编码规则
在遗传算法的改进过程中,为了保证后续进行遗传编码的冲突检测和修正,确保新产生的染色体的有效性,设计编码规则如下:
(1)在约束中被运算的次数多的布尔变量优先编码并赋值。
(2)在运算次数相同的条件下,模型中原始序号靠前的布尔变量优先编码并赋值。
(3)等式约束条件分别对应一对独立变量与派生变量,不等式中对应的约束条件Ei≤Ej中,Ei优先考虑是否为独立变量。
假定模型中有n个独立变量(Ii表示第i个独立变量),m个半独立变量(Sj表示第j个半独立变量),基于布尔变量划分的顺序编码方式将染色体编码基因链分成I区编码区和II区编码区,如图1所示。

图1 染色体编码基因链
在包含n个变量的等式或不等式中,总会存在一个独立变量和派生变量,其余变量为半独立变量。
在该编码原则下,II区编码基因改变对其他基因位的影响程度将呈降序排列,后续冲突检测中对II区编码自前向后依据约束规则进行修改,这样可以确保修改后的染色体仍然是有效的个体,同时也可保证对染色体编码影响最大的编码改动最小,尽量保持原编码的有效性。该编码以线性时间检测修改染色体,相对于算法适应度线性规划求解部分的速度影响可以忽略不计。
2)编码规则示例
为形象化展示本文算法染色体顺序编码规则,本节以一个项目调度算例来说明,图2为该工程算例调度网络。

图2 包含时间关系和逻辑关系的工程算例
本算例包含互斥、共存和依赖逻辑关系,式(18)~式(20)表示3个互斥逻辑关系,式(21)~式(23)表示3个共存逻辑关系,式(24)表示一个依赖逻辑关系。
E2+E5=1
(18)
ER(2,3)+ER(3,2)=1
(19)
ER(3,4)+ER(4,3)=1
(20)
ER(2,3)=ER(3,4)
(21)
ER(3,2)=ER(4,3)
(22)
E5=E6
(23)
E6≤E7
(24)
为了求出最少个数的独立变量,设目标函数为:
∀i,R(j,k),1≤i,j,k≤n
(25)
计算求出一组符合本文算例布尔变量的可行解为:独立变量E5和ER(2,3),派生变量E2、E6、ER(3,2)、ER(3,4)和ER(4,3),半独立变量E7。根据基于布尔变量划分的顺序编码方式和变量编码赋值规则,算例的染色体编码基因链如图3所示。
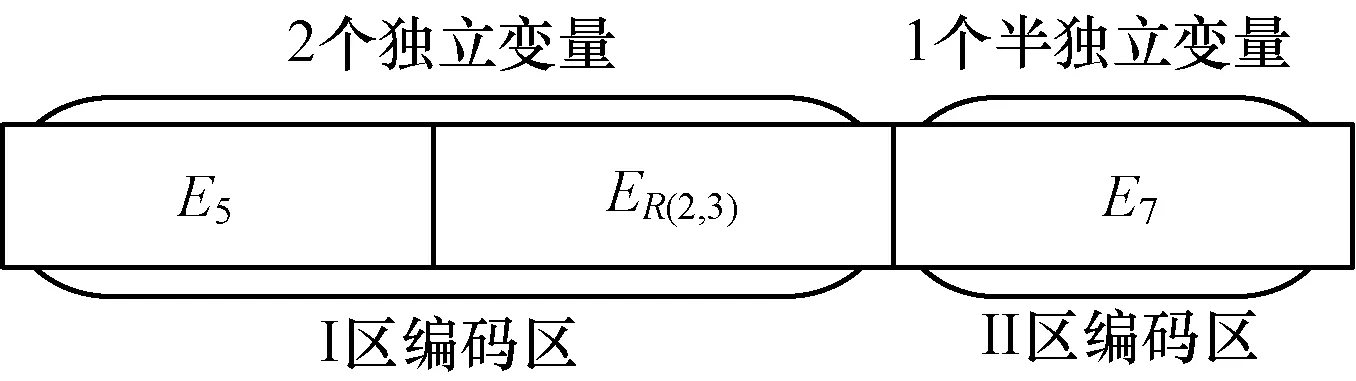
图3 算例中染色体编码基因链
2.2.2 遗传算子
本文针对施工活动和时间关系间存在的大量逻辑关系,采用了独立变量和半独立变量的顺序编码机制。
1)算子的选择
调度模型的目标是最小化项目工期,求解过程需要最小化适配值,在选择过程中将使用轮盘赌的选择操作,因此,采用项目总工期的倒数作为适配值。令f(i)表示个体的适配值,在总数为λ的种群(POP)中个体生存概率为:
(26)
2)交叉算子
本文采用编码基因链单点交叉,即各对应编码基因段分别交叉的方式对个体进行交叉操作。
3)变异算子
本文采用编码基因链基本点位变异。
2.2.3 冲突检测与消除
传统遗传算法采用2种方法求解染色体中存在互相约束的基因编码问题:
方法1在编码时剔除掉能够根据其他编码推理得到的变量编码,之后在适应度计算时再对被剔除编码进行计算,得到适合该染色体的最佳适应度值和染色体编码。
方法2在遗传操作之后检测染色体编码中是否存在冲突的基因编码,如果存在则将该染色体舍去或者设置染色体适应度值为极低。
在大型复杂施工项目中,II区编码数量较大,方法1虽然可以降低迭代次数,但每一代种群的求解效率将极低。方法2会产生大量不可行的染色体编码,导致算法收敛过快,因此,需要设置比较大的种群数量来保证种群在整个迭代过程中的多样性,在工程规模较大时,求解效率无法令人满意。
本文算法在进行适应度计算之前,依据I区独立变量和II区其他半独立变量的约束不等式进行反馈修正II区基因段,消除违反约束条件的个体。在冲突检测之后,染色体编码的I区独立编码部分不受影响,保留原染色体的I区编码的有效性,II区编码的修改程度依次降低。该修正使II区部分无效的编码变为有效,同时也保留了有效的编码区域。
2.2.4 调度问题的遗传算法描述
采用本文遗传算法计算最短工期的流程如图4所示。

图4 遗传算法计算最短工期的流程
Fig.4 Flowchart of genetic algorithm calculating the shortest construction period
本文遗传算法的具体实现步骤如下:
步骤1根据布尔变量顺序编码机制,对调度模型中的独立变量和半独立变量进行顺序编码,并随机产生初始种群POP,种群规模为pop,当前代数为GEN=0。
步骤2计算种群中的个体适配值。
步骤3GEN=GEN+1。
步骤4根据交叉概率参数Pc,选出参与遗传操作的子种群POPope,每个个体的染色体由独立变量基因段和半独立变量基因段构成。
步骤5采用各对应编码基因段分别交叉的方式对POPope中个体进行交叉操作,得到子代种群CHI。
步骤6根据变异规则和概率Pm对子代种群CHI中个体的每个基因段进行变异操作。
步骤7将CHI中基因段组合成个体,计算其中个体的适配值。
步骤8POP=POP∪CHI。
步骤9通过选择操作从POP中选出λ个个体作为下一代的种群。
步骤10检测II编码区,依据I编码区独立变量的约束规则进行修正。
步骤11如果GEN≥Gmax,终止算法,否则转步骤3。
3 算例仿真
本文在MATLAB(R2015b)下,分别编写了精确算法与遗传算法的求解方法。精确解将使用线性求解规划器计算得到模型的最短工期解,用于验证遗传算法的结果正确性。遗传算法的主要参数如表3所示。

表3 遗传算法参数设置
某后张预应力桥梁采用平衡悬臂法进行施工,2个移动平台用来支撑在建设过程中桥墩两侧的桥梁分段,桥梁结构呈中跨对称结构。平衡悬臂结构从中间桥墩向两边施工的过程中,为保持桥梁结构的稳定,在任何时候都必须保证桥梁结构两边的浇筑分段数量之差不大于1 。由于左右平衡悬臂结构的对称性,本文只研究左边结构的施工过程,用于测试调度模型和算法的实用性。本工程共包含25个施工活动,调度网络如图5所示。
图5 案例调度网络
通过模型转换引擎,生成混合整数规划模型为:
MinZ=Fp
(27)
其约束条件为:
S1+20≤S2
(28)
S1+20≤S3
(29)
S2+1-(1-ER(2,3))×M≤S3
(30)
S3+1-(1-ER(3,2))×M≤S2
(31)
S2+1≤S4
(32)
S3+1≤S5
(33)
S4+9≤S6
(34)
S5+9≤S6
(35)
S6+1≤S7
(36)
S7+44≤S8
(37)
S7+44≤S9
(38)
S8+1≤S10
(39)
S9+1≤S11
(40)
S10+9≤S12
(41)
S11+9≤S12
(42)
S12+1≤S13
(43)
S12+1≤S14
(44)
S12+1≤S21
(45)
S13+E13≤S15
(46)
S14+E14≤S16
(47)
S15+E13≤S16
(48)
S15+E13≤S19
(49)
S16-(1-E14)×M+9≤S17
(50)
S16+9≤S23
(51)
S17+E14-(1-E14)×M≤S18
(52)
S18+E14-(1-E14)×M≤S19
(53)
S19+1≤S20
(54)
S20+9×E20≤S23
(55)
S21+1≤S22
(56)
S22+9≤S23
(57)
S23+1≤S24
(58)
S24+1≤S25
(59)
ER(2,3)+ER(3,2)=1
(60)
E13+E14=1
(61)
E13≤E20
(62)
E14≤E20
(63)
ER(2,3),ER(3,2),E13,E14,E20∈{0,1}
(64)
Si+Di≤PF,i=1,2,…,n
(65)
Si≥0,i=1,2,…,n
(66)
当采用精确算法求解时,计算得出该案例的最短工期为110天。在调度模型中备择活动和时间关系被选择的情况为E13=1,E14=0,ER(2,3)=1,ER(3,2)=0,ER20=1。
采用遗传算法求解的结果如图6所示。由于本案例活动数较少,包含的逻辑关系也较少,在迭代到12代时,整个种群平均天数已经达到最短工期,种群天数已经趋于收敛。计算得到的最短工期仍为110天,案例中布尔变量的计算结果和精确解相同。
在共228个活动的调度模型中采用遗传算法求解,可以发现在遗传代数迭代到45代时,整个种群平均适配天数已经趋于收敛,可得最小工期为689天,和精确解结果相同。
为验证设计的遗传算法适用于带有大量逻辑关系的超大型复杂调度模型,本文通过增加逻辑关系的数量和项目规模的来验证遗传算法收敛效果。分别在活动数为500、1 000、2 000的模拟工程仿真中对比精确解、传统遗传算法和本文算法的求解效率,其中,传统遗传算法A编码部分将只考虑独立变量,传统遗传算法B将在进行遗传操作之后对所得染色体进行有效性分析,如果染色体无效将会选择新的父染色体进行交叉变异操作,计算结果取3次测试平均值并取整,结果如表4所示。

表4 模拟案例中的求解效率对比
由表4可以看出,虽然精确解对中小规模的调度模型求解速率确实较快,但是随着工程规模的扩大,求解效率逐渐弱于本文算法。传统遗传算法A受大型工程中约束关系过多的影响,求解速度极慢,无法在有效时间内求解;传统遗传算法B对大型工程求解过程中出现交叉变异操作产生的有效染色体概率极低的情况,种群进化速度缓慢,收敛速度降低,在长时间内无法得到收敛结果。
4 结束语
本文在互斥与共存逻辑关系的基础上引入IF-THEN来进一步描述依赖关系,讨论3种逻辑关系之间的内在联系,探索更为底层的逻辑关系表述方法。在此基础上,扩展调度模型到混合整数规划模型的转换规则,并分析逻辑关系的计算规则,实现模型间的自动转换。通过对模型中的逻辑关系变量进行分段编码,在变异操作后加入冲突检测环节,消除由种群初始化与遗传操作产生的违反约束个体。编程实现本文算法的自动求解,并与精确算法进行对比,仿真结果表明,随着工程规模的扩大,该算法能有效缩短求解工期的时间。下一步将探究染色体编码中的层级划分概念,通过改进遗传算子,在保证近似解合理的情况下提高算法效率。
猜你喜欢
今日农业(2022年15期)2022-09-20 06:54:16
科学之谜(2019年3期)2019-03-28 10:29:44
科学之谜(2018年8期)2018-09-29 11:06:46
红土地(2018年7期)2018-09-26 03:07:38
石油地球物理勘探(2017年2期)2017-11-23 06:02:04
中央民族大学学报(自然科学版)(2017年1期)2017-06-11 07:13:32
统计与决策(2017年2期)2017-03-20 15:25:24
恋爱婚姻家庭·养生版(2016年9期)2016-09-07 11:25:01
智能系统学报(2015年4期)2015-12-27 09:38:39
中央民族大学学报(自然科学版)(2015年2期)2015-06-09 08:45:16
