
面向开源代码复用的程序比对分析方法
2020-01-16 07:32:24陈飞翔李冬梅崔晓晖
计算机工程 2020年1期
许 福,郝 亮,陈飞翔,李冬梅,崔晓晖
(北京林业大学 信息学院,北京 100083)
0 概述
开源软件复用有助于缩减开发成本,提高开发效率。目前,80%以上IT企业的主要产品复用了开源代码,仅有低于3%的企业没有使用任何开源软件[1]。截至2019年1月,GitHub上的开源项目已达1 800万个[2],OpenHub索引的代码已经超过573亿行[3],StackOverflow的软件问答数不低于1 300万条[4]。
尽管开源软件资源非常丰富,但要对其进行有效复用将存在一定难度,主要原因有两点。第一为开源许可证侵权风险。开源软件通常附带了相应的许可证限制,常见的许可证有GPL[5]、LGPL[6]、Apache 2.0[7]和BSD-2-Clause[8]等110多种[9]。这些许可证的要求不尽相同,甚至相互冲突。例如,GPL许可证强制衍生品必须公开源码,而Apache 2.0许可证则无此限制。随着开源代码复用的日益广泛,许可证侵权风险也愈发突出。2009年,微软未经许可在其WUDT工具中使用了GPL许可协议下的开源代码,遭到了开源社区的起诉[10]。2014年,Google的Android系统被诉侵权Java代码,诉讼金达88亿美元[11]。为规避许可证侵权风险,企业通常不得不耗费大量人力和资源来进行手工鉴别。第二为已复用的代码难以及时更新。开源代码复用后需要及时更新,否则可能带来安全风险。2017年,由于复用的Apache Struts2 开源组件存在漏洞,Equifax公司的1.43 亿用户信息被窃,经济损失高达35亿美元[12]。在实践中,某个开源项目的代码经常会被其他项目复用,与原生项目相比,这些衍生项目可能开发更活跃,问题修正更及时。由于欠缺针对开源生态系统的全局分析方法和工具,目前开发者只能获取到原生项目中的代码更新,难以获取到其衍生更新。此外,由于欠缺自动化的比对工具,开发者只能利用Diff[13]、Araxis Merge[14]等文本比对工具进行手工代码更新,当复用的代码来源很广时将消耗大量人力。
以上两点是影响开源代码复用的主要障碍,高效的程序比对分析技术是解决上述问题的有效途径。程序比对分析通常利用文本、语法和语义等指标计算代码相似度,据此进行分析比对。文献[15]将代码相似度分为5个等级:相似等级1中2份代码完全一样,相似等级2中除空白(含空格、回车、Tab等)与注释外,其余部分完全相同,相似等级3在等级2的基础上,2份代码的变量名、类型名不同,其他部分相同,相似等级4在等级3的基础上,改变、增加或删除少量语句,其余大部分代码相同,相似等级5中2份代码的绝大部分均不相同。其中,等级1~等级3认定为相同代码,等级4认定为高相似度代码,等级5认定为不同代码。
本文通过程序比对分析技术,以实现对海量开源代码的高效分析与检索以及代码相似度的有效判别。设计一种增量代码函数提取算法,其仅对代码快照间的增量部分进行分析,并充分利用代码快照间的高度相似性特点来有效降低代码分析整体规模。提出基于Simhash的函数指纹构造算法,将函数代码转化为函数指纹进行存储和检索,从而降低分析结果的存储空间并提高代码函数的检索效率。构建一种代码相似性判定方法,用于检索函数更新出现的位置。在此基础上,通过计算相同、相似函数数量之和占函数总数的百分比来获得2个开源工程的相似度,据此判定2个开源工程间是否存在复用关系。
1 国内外研究现状
目前的程序比对分析理论大都来自编译领域,主要采用LR(k)、LL(k)分析方法及其各种改进方法,如SLR(k)、LALR(k)和SLL(k)等[16]。这些理论和方法在编译领域的应用已比较成熟,但不能有效满足开源代码复用领域的分析需求,原因主要有以下两点:
1)缺乏高效的增量分析方法。目前的程序分析方法采用批处理模式,对程序进行完整分析。这类方法分析速度慢,难以满足海量开源代码的高效分析需求。Lucene[17]、SearchCode[18]等代码搜索引擎将代码当普通文本处理,可检索海量代码,但未利用语法结构信息,不能进行相似等级为2和3的代码比对。文献[19]设计了一种基于抽象语法树的代码增量分析方法,其分析效率较高,但分析器构建难度较大,且分析规模存在瓶颈。文献[20]将连续的源程序映射成哈希值,借助倒排索引技术[21],设计了大规模代码的增量分析算法,该算法性能较高,但是其不执行语法分析,没有充分利用语法结构信息。
2)缺乏高效的代码比对分析方法。为避免开源许可证侵权,近年来出现了一些关于许可证自动侦测方面的研究成果[22-23],其核心思路是通过扫描特征文件或关键词来判定开源许可证类型。这类方法能够自动侦测部分许可证,但存在以下局限:这些特征文件或关键词在很多开源代码中并未明确标注;开源项目通常也广泛复用了其他的开源代码[24],复用过程本身就可能存在许可证冲突。统计数据显示,高达85%的开源项目都存在不同程度的许可证侵权问题[25]。在这种情况下,即使侦测到了许可证文件或关键词,结果也不准确。Black Duck[26]和Palamida[27]公司提供开源许可证侵权检测服务,但其内部机制和算法并未公开。此外,这类商业检测服务收费不菲,很多企业难以负担。开源许可证侵权检测需要跨越项目边界对开源生态系统中的程序代码进行整体分析,据此识别出复用的代码最早来自哪个项目,继而判定其许可证类型,目前还较少有关于这方面的研究成果。
2 算法设计
本文设计一种以函数为检测单元的开源代码比对分析方法。该分析方法将开源工程视为代码文件的集合,将代码文件视为函数的集合。首先利用SVN、Git等命令行工具提取仓库代码,然后设计语法分析器,以函数为单元对代码文件进行切分,提取函数特征信息。为便于数据存储和比对分析,使用Simhash算法[28]将函数转化为函数指纹,利用函数指纹进行代码比对,确定函数的相似度关系。基于上述函数相似度计算2个工程的相似度,进而判定两者是否存在复用关系。在复用关系确立后,可通过查验工程中的“LICENSE”“readme”等文件人工判定是否存在开源许可证侵权。在已复用代码的更新检测方面,利用函数指纹找到所有初始复用项目的衍生项目,以及这些项目中的相似函数指纹,结合函数的修改时间信息即可快速找到可用的函数更新。本文方法包含以下4个步骤:
1)获取仓库代码。利用SVN、Git等命令行工具获取开源仓库代码,调用SVN Diff、Git Diff等接口获取快照(Snapshot)间的差异代码。为行文简洁,后文将上述快照间的差异代码称为“增量文本”。
2)进行完整和增量语法分析,获取函数特征信息列表。以函数为基本单位对待分析的代码进行切分,获得文件中的所有函数。设计语法分析器对代码仓库中的第1个版本快照执行完整语法分析,提取函数名、起止行号、参数和返回值等特征信息。本步骤的分析器可采用Bison、Antlr等分析器生成工具构建,此处不再赘述。对于第2个及后续的版本快照,提取快照间的增量文本,设计增量函数提取算法(见2.1节),将增量文本识别为完整、可进行语法分析的函数,提取其中的函数名、起止行号等信息。
3)计算函数指纹。利用Simhash[28]、特征信息分词赋权构造与函数代码对应的哈希值,下文将该哈希值统称为函数指纹(见2.2节)。
4)相似度计算及比对分析。基于函数指纹比对分别获得相同、相似、不同的函数个数,根据上述数据计算代码相似度,判断代码间是否存在复用关系。结合修订时间信息构建函数的“创建/引用/修改”历史序列图,据此进行开源代码许可证侵权检测及函数的更新侦测。
本文方法流程如图1所示。
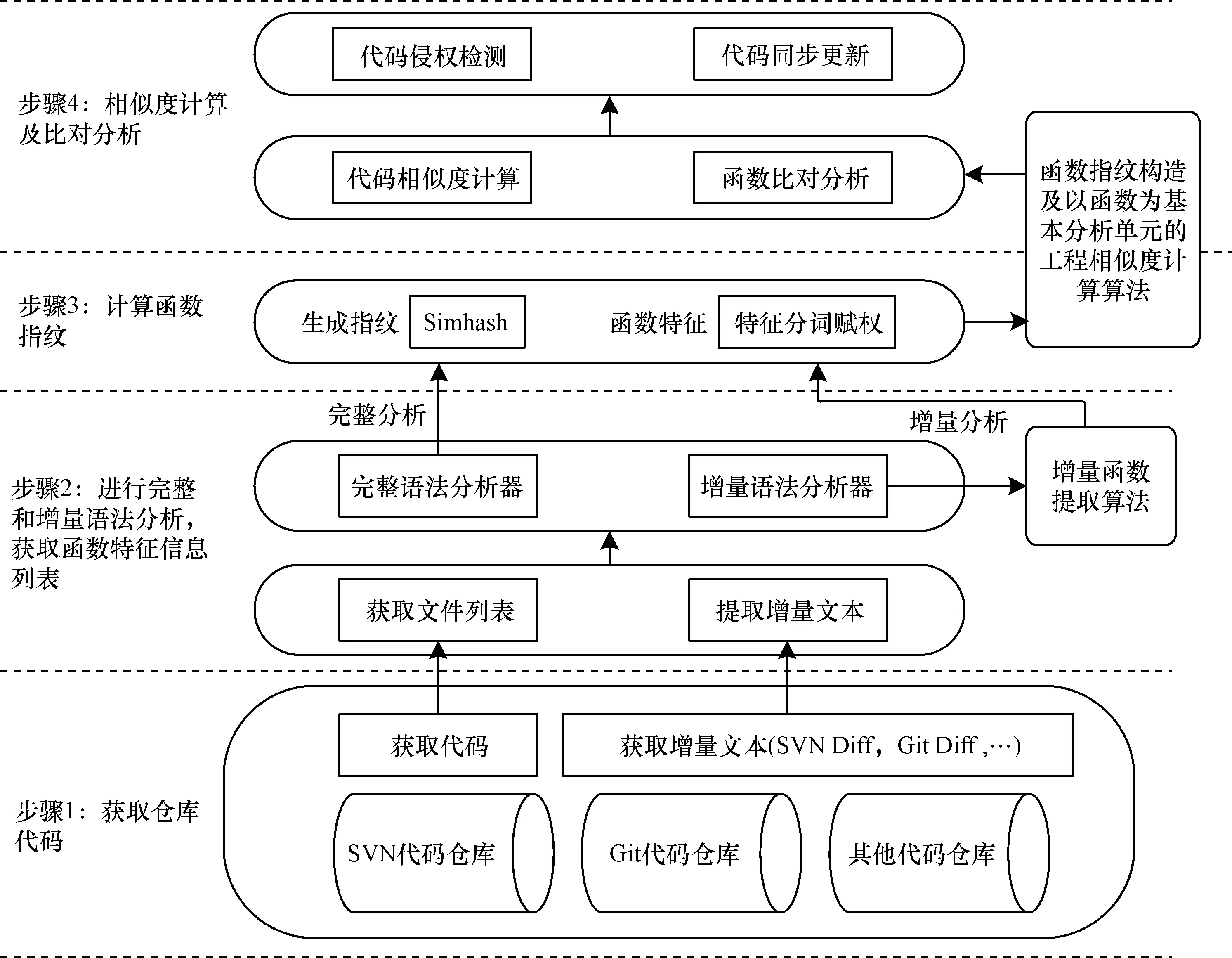
图1 以函数为检测单元的开源代码比对分析方法流程
2.1 增量函数提取算法
活跃的开源项目通常存在大量的版本快照。例如,Hibernate的快照有9万个[29],Apache Web Server的快照高达110万个[30]。开源项目普遍采用SVN 、Git等版本控制系统,为避免提交时发生冲突,通常采用小规模、频繁的代码提交模式,这意味着相邻快照间的代码差异非常小,平均相似度高达98%[31]。传统方法对代码进行完整分析,没有利用快照间的高度相似性特点,因而存在大量的冗余分析,时空效率较低。本文设计一种增量分析方法,只对快照间的修改部分(即增量文本)进行分析,与传统的完整分析相比,其具有明显的时空效率优势。本文增量函数提取算法伪代码如算法1所示。
算法1增量函数提取算法
输入已分析的快照Ns,待分析的快照Nt,快照Ns中的函数特征信息列表Fs
输出快照Nt中的函数特征信息列表Ft,每条信息包含函数名、起止行号等
1.FuncList GetFuncList ( Snapshot Ns,Snapshot Nt,FuncList Fs) {
2.使用Diff命令获得Ns、Nt快照间的增量文本(IncreText)
3.扫描IncreText,查找其中是否包含完整函数
4.根据增加、删除两类编辑操作,计算新增的函数列表(Fa)和删除的函数列表(Fd),将上述识别出的函数代码从IncreText中剔除
5.解析IncreText中剩余的代码,获得修改代码的起始行号(startL)。检查startL是否位于Fs函数中,若是,从该函数体的起始标记符所在行号开始查找,找到函数体的结束标记符所在行号,得到修改的函数列表(Fm)。
6.更新Fs中的Fm,将Fa添加到Fs,将Fd从Fs中删除
7.Ft= Fs//得到快照Nt中的函数特征信息列表Ft
8.Return Ft
9.}
在算法1中,输入参数Ns和Nt通过调用版本控制工具中的“log”命令获得,如“SVN log”“Git log”。分析第1个快照时,调用语法分析器进行完整分析,获得函数特征信息列表Fs。当分析第2个及后续的快照时,Ft可通过调用GetFuncList获得。通过遍历代码仓库中所有的版本快照,并以其作为第2个参数循环调用算法1,即可实现对整个代码仓库的遍历。
算法1中的大部分代码均直观易懂,但需要解释以下三点:
1)在第2行中,增量文本可通过调用版本控制工具中的“Diff”命令获得。例如,想要获得版本快照N1与N2间的差异信息,可调用“SVN Diff-rN1N2”或“Git DiffN1N2”获得。此外,不同版本控制工具的增量文本格式略有不同,以最常见的Unified Diff Format[32]为例,所有的修改都可以归结为添加和删除两类操作,其中,以“+++”开头表示添加行,以“---”开头表示删除行。通过解析增量文本可以定位出增加、删除的行号位置及代码块,如图 2所示。
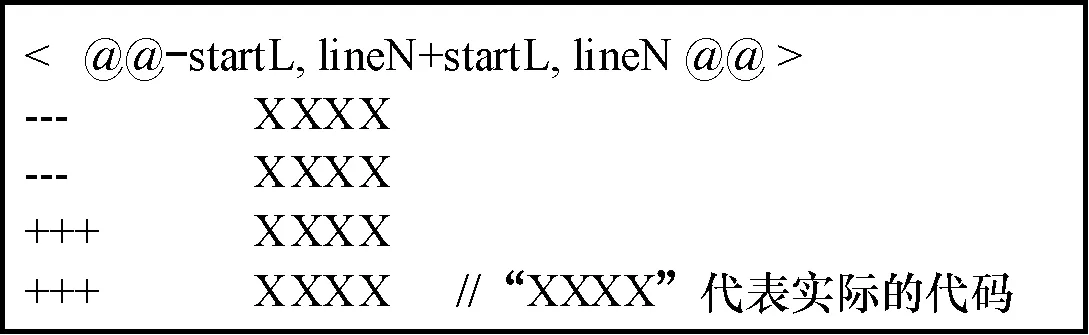
图2 增量文本格式
2)在第3行中,查找是否包含完整函数的思路如下:利用正则表达式抽取函数声明并记录下函数体起始符的位置,利用下推自动机[33]匹配与起始符对应的结束符,这样即可找到函数的起止范围。以Java语言为例,函数起始符为函数声明后的第1个“{”,函数结束符为与之配对的“}”。图 3给出了分析器识别完整函数体的语法匹配规则,根据该规则可以提取出函数名、起止行号等特征信息。

图3 函数匹配规则
3)在第5行中,根据startL查找函数体的结束标记符所在行号,可以采用与第2步中类似的下推自动机实现。
通过算法1可将增量文本转换成完整的可进行词法、语法分析的函数。
2.2 函数指纹构造与工程相似度计算
算法1提取出了每个快照中的函数特征信息,为了支持相似等级为2和3的代码比对,需要对每个函数进行词法分析,将函数转为标志符(Token)序列。为减小存储空间,方便函数比对,本文利用哈希算法将上述Token序列转为函数指纹。在哈希算法选择方面,需满足3个直观条件:1)相同的Token序列应产生相同的哈希值,不同的序列应产生不同的哈希值;2)具有较低的哈希碰撞率;3)相似的Token序列应产生相似的哈希值,以满足相似函数的判定需求。MD5、SHA256等传统哈希算法满足第1个和第2个条件,但不满足第3个条件,即使原始内容高度相似,生成的哈希值也可能差异很大。本文采用Simhash作为函数指纹构造算法,该算法是一种低碰撞率的局部敏感哈希算法[34],以往主要用于相似网页滤重。Simhash具备高容量的特征压缩,且哈希值能反映原始输入的相似性,当2个哈希值的海明距离小于等于3时表明2段代码相似。算法2给出了函数指纹构造算法的伪代码,算法3给出了以函数为基本分析单元的工程相似度计算算法的伪代码。
算法2函数指纹构造算法
输入单一函数的函数体代码F
输出函数F对应的函数指纹Fp
1.FuncFingerPrint CalFuncFingerPrint( Function F){
2.调用词法分析器,将代码转为Token序列
3.调用语法分析器获取函数特征信息
4.利用Simhash算法,结合函数特征信息计算函数指纹Fp
5.{//Simhash分为5个步骤
6.分词//对内容分词,得到特征向量
7.哈希//将每个特征向量哈希为一组固定长度的数列
8.赋权//对每个哈希值进行加权
9.合并//将上述加权哈希值合并
10.降维//将合并后的值降维,得到最终的哈希值
11.}
12.Return Fp
13.}
算法3以函数为基本分析单元的工程相似度计算算法
输入2个工程的源代码FA、FB
输出2个工程的代码相似度S
1.Similarity CalSimilarity(FA,FB){
2.sameFuncCount=0;//相同函数数目
3.similarFuncCount=0;//相似函数数目
4.differentFuncCount=0;//不同函数数目
5.调用算法2将2个工程中的函数转化为函数指纹
6.获取2个工程的函数指纹列表,分别标记为FpA、FpB
7.统计函数指纹数,分别记为sumFuncCntA、sumFuncCntB
8.遍历FpA中的每个函数指纹fa{
9.遍历FpB中的每个函数指纹fb{
10.distance = fa和fb的海明距离
11.If (distance == 0)// 相同函数
12.sameFuncCount ++
13.Else If (0 14.similarFuncCount++ 15.Else{//不同函数 16.differentFuncCount++ 17.} 18.} 19.} 20.S=(sameFuncCount+similarFuncCount)/sumFuncCntA|B 21.Return S//返回相似度 22.} 算法2的输入为单一函数的函数代码F,输出是与函数F对应的指纹信息Fp,其对Simhash算法进行了改进,首先对输入的函数代码进行词法分析,将代码块转化为Token序列(第2行),然后调用语法分析器获取函数特征信息(第3行),最后利用Simhash算法结合函数特征信息计算得到函数指纹(第4行~第11行)。Simhash算法在网页去重中得到广泛应用[35],为使该算法能够适用于程序分析的应用场景,本文在原始Simhash算法的基础上做了两点改进,如图4中加粗部分所示。 图4 原始Simhash算法优化 本文对Simhash算法的两点改进具体如下: 1)词法分析:经过词法分析将源代码转为Token序列,滤去了代码相似等级为2、3时无关项对分析结果的影响。 2)赋权:赋权是Simhash算法中的重要环节。在原始Simhash算法用于网页去重时,每个分词所赋的权值为该分词在文本中出现的频次。与网页不同,源代码均按编程语言语法编写,具备严格的结构化特征,函数名、参数、返回值能较好地体现上述结构化特征,因此,本文对该类分词加倍赋权,其他分词权值采用原始Simhash中的标准赋值策略。 算法3实现了函数相似度判定和工程相似度计算。首先,根据算法2获取2个工程的函数指纹,并统计函数数目(第5行~第7行)。以海明距离3为阈值,对函数指纹进行分类,找出相同、相似、不同的函数指纹,并统计三类函数的数目(第8行~第19行)。最后,以相同、相似函数数量之和占函数总数的百分比作为工程相似度(第20行)。需要注意的是,FA、FB包含的函数总数可能不同,因此,一次比对会获得2个相似度。 通过算法1~算法3,可获得函数指纹并进行函数指纹比对,进而实现高效的代码溯源。通过检索函数指纹,可以确定每个函数及其相似函数在整个开源生态系统中的项目、路径和版本信息,据此进行许可证侵权检测和代码同步更新。 本文设计了如下3组实验,从分析时间和工程相似度2个角度进行程序比对分析: 实验1通过对比传统完整分析与增量分析所消耗的时间,验证增量分析方法具备更快的分析速度和更小的内存空间。 实验2利用算法3对代码相似度进行判定,验证本文方法的正确性。 实验3对实验2进行扩展,验证函数溯源能力。 实验机配置:Windows 10 64 bit,内存16 GB,CPU 6核Intel(R) Core(TM) i7-8700k。 本文实验选取GitHub上的Hibernate开源项目作为分析对象。截至2019年1月9日,该项目累计储存了97 044个版本快照,其中,master分支上储存了9 430个快照。选取master分支中最近提交的11个快照进行分析,表1所示为增量分析与完整分析所消耗的时间(第1个版本快照只有完整分析时间、文件数和函数数目)。 表1 完整分析与增量分析对比 从实验数据可看出,相邻版本快照间的代码改动量很小,平均改动量约占总函数量的0.11%(增量函数数量/函数总量)。在时间对比上,增量分析相较于完整分析有明显优势,平均节约了94.85%的分析时间。此外,传统分析方法需要加载工程内的所有代码文件,而增量分析只处理增量文本,因而只需要加载少部分文件,在内存使用上也更加经济。从上述实验结果可看出,进行一次完整分析平均需加载9 227个Java文件,而使用增量分析平均只需加载约11个Java文件,约占完整分析的0.12%。综上,无论在分析效率还是在内存使用上,增量分析方法都优于传统的完整分析方法。 本实验数据源采用GitHub上2个可能存在衍生关系的开源ERP系统,即RAINFLY_ERP和MEGAGAO_ERP。通过人工查验,两者都使用了Spring+Struct2+MyBatis架构。分析结果包括两部分,第一对工程代码进行分析,从表2可以看出,2个工程的代码量类似,分别包含3 825个和4 092个函数;第二对2个工程的函数指纹进行对比分析,并计算2个工程的相似度。表3列出了相同函数、相似函数、不同函数的数量关系。 表2 2个项目的基本情况 表3 开源项目函数比对结果 从上述实验结果可看出,2个工程的相似度非常高。虽然MEGAGAO_ERP与RAINFLY_ERP在界面上风格迥异,但在函数层面它们都实现了相同的功能。比对2个工程中的函数指纹,相同函数为3 310对,相似函数为114对,不同函数分别有401个和668个。利用算法3计算可知,2个工程的相似度分别为83.7%和89.5%。 通过实验2可获得2个工程在函数层面上的相似度,以此判定两者是否存在复用关系。综合代码快照的提交时间可以获知复用方和被复用方。例如,实验中MEGAGAO_ERP的提交时间段是2016年9月24日—2018年1月23日,而RAINFLY_ERP的提交时间段在2018年2月1日—2018年2月5日,据此可认定RAINFLY_ERP是MEGAGAO_ERP的衍生项目,复用比例为89.5%。 实验2采用的分析方法可以从2个项目扩展到整个开源仓库。首先分析仓库代码,把函数转化成函数指纹并预先存储好,之后通过函数指纹可以检索出相同函数和相似函数,结合文件的更新时间信息即可构建出函数的“创建/复用/更新”时间链,借助该时间链可有效解决开源许可证侵权检测问题。 本文实验数据通过关键词检索,得到GitHub上一组使用同一框架开发的ERP系统。由于这些项目的开发语言相同,实现的功能类似,因而猜测它们之间存在复用关系。分析上述工程的源代码得到的实验数据见表4。 表4 同类开源项目的分析结果 利用实验2中复用关系的判定方法发现:在上述工程中,RAINFLY_ERP和KJF_ERP 都是MEGAGAO_ERP的衍生项目,复用比例分别为89.5%和80.2%。RAINFLY_ERP在复用MEGAGAO_ERP的基础上,对getTypeHandler等114个函数做了更新;KJF_ERP在复用MEGAGAO_ERP的基础上,对changeStatus等225个函数做了更新;deleteBatch等7个函数在2个衍生项目中都做了修改。综合上述数据可以获得所有的函数更新位置及其最新的更新时间。 以往开发者只能通过原生项目获得代码更新。利用实验3中的方法,开发者很容易找到维护更为活跃的衍生更新。例如,想要复用deleteBatch函数,首先将该函数转为函数指纹,之后通过检索该指纹找到函数的初始版本及其所有更新。在代码复用时,上述方法不仅能很快定位到函数的最早来源,还可以更快地找到可用的代码更新。 本文提出一种开源代码仓库增量分析方法,该方法充分利用代码快照间的高度相似度特点,有效缩减了分析时间和存储规模。在此基础上,利用Simhash算法将增量文本映射成函数指纹,并设计一种以函数指纹为基本单元的代码相似度比对方法,该方法可满足开源代码复用中常见的许可证侵权检测及函数更新需求。利用本文方法可对开源生态系统中的代码进行整体分析,通过构建代码索引库,建立针对开源代码复用的公共服务平台,可实现开源资源的有效复用和管理,使开发人员可以获取可用、高质量的代码,并有效规避知识产权风险,促进我国软件产业发展。下一步将结合大数据分析方法,研究如何改进代码的检索效率,以提升本文方法的代码溯源能力。
3 实验结果与分析
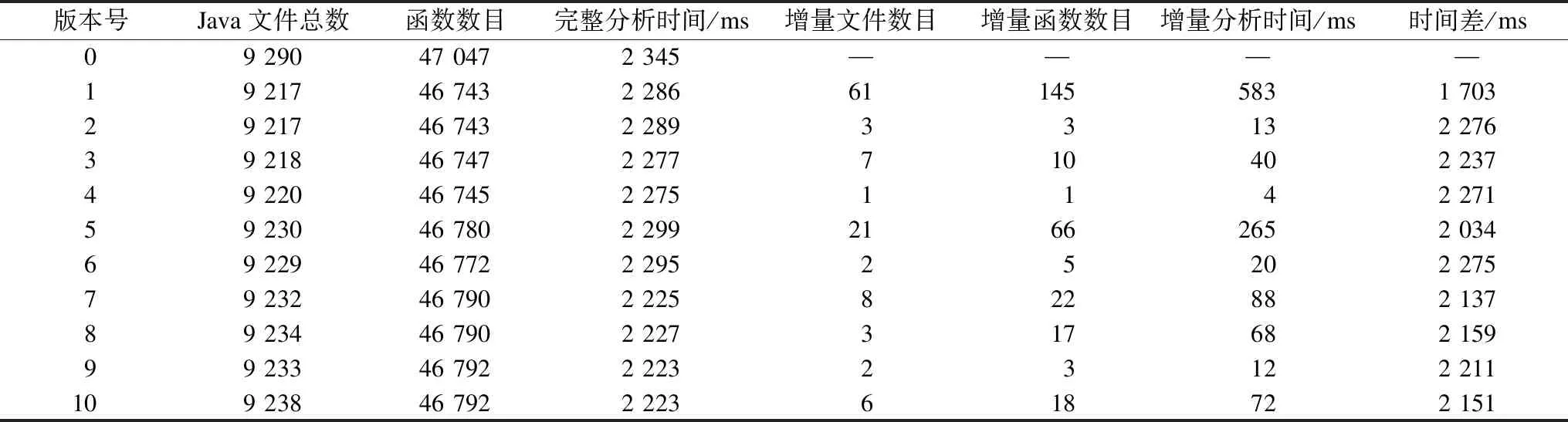
3.1 完整分析与增量分析的速度对比
3.2 工程相似度计算


3.3 复用代码更新能力验证

4 结束语
猜你喜欢
计算机仿真(2023年8期)2023-09-20 11:23:42
天津科技(2022年5期)2022-05-31 02:18:08
现代信息科技(2021年21期)2021-05-07 21:44:50
中国司法鉴定(2018年4期)2018-07-30 06:08:26
网络安全和信息化(2017年3期)2017-03-10 07:45:51
工业设计(2016年8期)2016-04-16 02:43:34
中国房地产业(2016年8期)2016-03-01 01:25:55
计算机工程(2015年8期)2015-07-03 12:20:04
网络安全和信息化(2015年11期)2015-03-17 21:54:44
发明与创新(2015年21期)2015-02-27 10:39:11
