
使用最大后验方法的资源缺乏关键词识别
2020-01-16 05:56韩博
电子技术与软件工程 2019年21期
文/韩博
1 引言
关键词识别技术是随着语音识别技术的不断发展进步而发展起来的。随着语音技术的不断发展,人们在语音学、语言学上都积累了大量的知识,关键词识别才从语音识别中分离了出来,并应用在不同于语音识别的领域。由于语音识别有着更高的准确率,所以在有着丰富资源而可以运行语音识别的一些语言中,关键词识别通常是在经过语音识别的结果上进行的。即,使用语音识别器将音频语句转换为文本,然后利用文本检索技术找出关键词的位置,返回相关语音段。利用关键词识别,可以实现信息的快速检索,在商业领域的语音内容分析以及国家安全监控中都有广泛的用途。
2 关键词识别系统及模型训练流程
在与内容无关的关键词识别系统中,采用HMM算法的实现结构如图1所示。该解码器由关键词模型和垃圾模型的并行网络组成。其中,关键词模型由关键词语音训练而成,垃圾模型由不包含关键词的语音训练而成。在解码阶段,关键词模型和垃圾模型构成一个自由循环网络,然后使用自动语音识别器检测测试语句中的关键词。
在语音识别中,声学模型被用来将波形文件中的声音序列映射为音素或其他组成语音的语言学单元。因此,在基于HMM的关键词识别中,声学模型也是必不可少的部分。一个经过良好训练的关键词模型能够精确匹配相关的关键词同时拒绝其他的关键词和垃圾语音,本文使用目前主流的高斯混合模型(Gaussian Mixture Model, GMM)-HMM作为声学模型。
在参考说话人识别的策略时,首先需要利用所有待识别关键词来训练一个UBM,然后采用自适应的方法得到每个关键词的模型,从而获得一个相对稳健的模型。模型的训练具体流程如下:
(1)采用所有关键词的语音数据训练一个GMM模型表示的UBM;
(2)将这个UBM的GMM克隆到每个关键词的每个状态上作为其初始模型;
(3)用各关键词自身的语音数据,采用MAP算法更新每个关键词的GMM参数;
(4)用大量的背景语音数据,采用前向-后向算法训练垃圾模型;
(5) 将所有的关键词模型及垃圾模型拼成一个如图1所示的解码网络用于关键词识别。
2.1 UBM训练
在UBM训练阶段,通常使用最大似然(Maximum Likelihood, ML)作为评价准则来得到作为UBM的GMM模型。该模型由权重,均值和协方差矩阵参数描述,表示为:
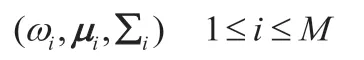
M代表高斯元素的数量。在ML准则下,期望最大化 (Expectation Maximization, EM) 算法被用来迭代估计模型参数,得到更新的模型,第k+1次迭代更新公式如下:

等式左边分别代表更新后的权重,均值和协方差矩阵,N代表总的语音帧数,cink表示第k次迭代中第i个高斯在第n个语音帧中所占的比例,又称为高斯占有率。其计算公式如下:

Nik代表在第k次迭代中属于第i个高斯的语音帧数,该值由第i个高斯在所有语音帧中的高斯占有率求和得到,公式如下:

2.2 MAP方法
在通过EM算法获得UBM模型之后,将这个模型克隆到关键词的各个状态中作为其初始模板,然后采用前后向算法来更新各关键词的模型参数。对于模型参数的更新策略,我们采用文中介绍的前向后向MAP算法重新估计模型参数,公式(4)为其更新公式。该公式中更新的参数描述了第s个HMM状态的第i个GMM分量。其中,csink表示第k次迭代中第s个HMM状态的第i个GMM分量在第n帧中所占的比例,其表达式如下:
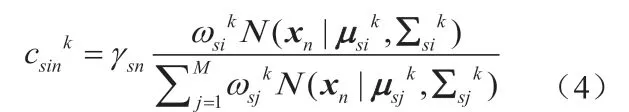
一般应用中,MAP算法仅使用一次迭代即可。在本文中对该算法使用了多次迭代方法以提高系统性能。
3 实验结果及分析
实验使用藏语数据集。训练集和测试集包含大约1小时的语音。类似于汉语,藏语也是单音节的语言,有许多的同音异体字。本实验选择了18个短语作为关键词,每个关键词的样本数量在15到30之间变化,关键词的长度在300到1000毫秒之间。
本文使用F1作为评价准则,它是召回率(Recall)和准确率(Acc)的折衷,定义为:

其中:

#hits表示系统正确识别的单词数,#keyword代表测试集中包含的单词数,#recall代表系统返回的所有单词数。

图1:关键词识别系统结构图

图2:迭代次数对F1的影响
3.1 特征提取
本文使用了两种参数进行实验性能的对比:43维的传统声学参数(39维的PLPs和4维音高参数)和BN特征。
3.1.1 传统声学特征
本文提取声学特征的步骤如下:首先,使用隐马尔科夫模型工具包提取PLP特征。语音信号经去直流、预加重(因子为0.97),经由帧宽20ms,帧移10ms的汉明窗抽取PLP,并用话音激活检测去除非语音帧。最后经倒谱均值方差规整处理后的0~12维PLPs及其一阶、二阶差分构成最终评测系统的39维PLPs。然后,使用语音信号的工具包提取音高特征。最后,将这些特征组合成43维的声学特征。
3.1.2 BN特征提取
由于缺乏标注的语音,本实验采用跨语种的训练方法,使用中文语料训练的一个BN声学模型来提取藏语语料的BN特征。BN声学模型的训练方法如下:首先,使用1000小时的中文语料建立一个基线GMM-HMM。该GMM-HMM包含6004个绑定状态,每个状态的GMM包含60个高斯;然后,使用该GMM-HMM解码训练语料获得训练BN神经网络的标注;最后,训练一个内容相关的5隐层BN神经网络以获取BN特征。类似于输入特征,BN层的节点数被设为43,其余隐层为2048。输入特征由11帧PLP特征串联而成,由此确定输入节点数为473。输出层节点数与绑定状态数一致。训练时首先是常规的预训练以生成RBM,然后采用标准的误差反向传播(Back Propagation, BP)算法微调整个网络参数。在BP过程中,mini-batch参数设为1024。BN网络收敛之后,BN层的线性输出即为BN特征。
3.2 实验结果
本文进行了三组实验:第一组实验比较在BN特征下,两种不同的建模方法对关键词识别系统的性能影响,第一种方法是直接使用关键词样本应用前向后向算法训练关键词对应的HMM模型,第二种采用的是本文推荐的先训练一个UBM模型,然后再通过MAP算法更新关键词模型参数的方法。第二组实验研究了MAP的不同迭代次数对系统性能的影响。第三组实验研究了在MAP方法中使用不同特征对系统性能的影响。这三组实验均在HMM框架下运行。
其中,本实验研究使用MAP方法时关键词模型不同迭代次数对系统的性能的影响,实验结果如图2所示。随着迭代次数的不断增加,系统性能也不断提升。迭代15次之后F1曲线比较平缓。
4 结束语
本文研究了基于HMM的关键词识别,提出了采用说话人识别中广泛应用的MAP方法解决关键词样本数量不足的问题。实验结果显示使用该方法能够大幅提升系统性能。本文还研究了使用跨语种的BN网络提取的BN特征作为输入来替代传统的PLP参数,在藏语的测试数据库上取得了明显的性能提升。
猜你喜欢
家庭影院技术(2020年6期)2020-07-27
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
小学生学习指导(低年级)(2019年6期)2019-07-22
电子制作(2019年9期)2019-05-30
家庭影院技术(2019年1期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
小说界(2018年5期)2018-11-26
家庭影院技术(2018年10期)2018-11-02
四川师范大学学报(自然科学版)(2015年2期)2015-02-28
