
基于OpenCV的图形识别系统设计
2020-01-16 05:56刘军伟
电子技术与软件工程 2019年21期
文/刘军伟
近年来,智能识别成为各领域的焦点,众多行业都采用新型的识别系统对图形、图像进行有效识别,一方面提升行业工作的效率;另一方面提升信息在互联网环境中的安全防护程度。计算机和互联网技术的发展,尤其是计算机视觉技术的快速革新,推动智能识别系统在供给端逐步深入研发。而当前计算机领域用于图形、图像识别研究的主要有C或C++语言、Matlab和Python软件工具等,基于这些编程语言和软件工具,才开发出了OpenCV这一具有非常强大兼容性的计算机视觉库。文章基于OpenCV对图形进行颜色、形状轮廓的识别研究,并结合试验流程分步骤设计图形识别系统,从而形成一套完整的图形识别方式,以便用于实际生产与生活当中,让技术服务于生产与生活。
1 OpenCV与图形识别
OpenCV全称是Open Source Computer Vision Library(开源计算机视觉库),是基于BSD许可而发行的一种跨平台计算机视觉库,它可以在诸多计算机操作系统上得以运行,如用户较多的Windows和OS系统,同时还提供了多语言的借口,可以在不同的软件上提取运行,如 Python、Ruby、MATLAB ,避免了软件工具的大空间、运行慢的弊端,真正实现了图形、图像处理的高效化和轻量化。之所以OpenCV可以具有如此强大的功能,是因为OpenCV由众多C函数和少部分C++构成,包括了近三百个C函数跨平台的中高层API,最重要的是它既具有独立的视觉库,又可以加载其他外部视觉库,从而保证了OpenCV在强大的函数算法下能够实现对图形、图像的高水平处理。
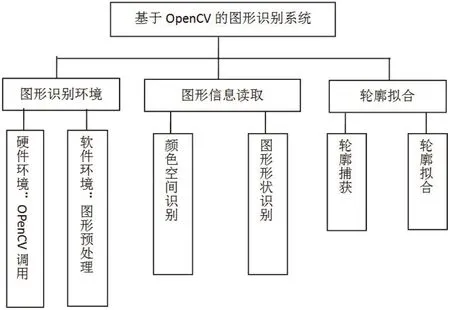
图1:图形识别系统框架设计
如今的社会到处充斥着各类字符、图形、图像信息,对这些庞杂的信息进行有效识别,从而可以对信息进行分类、存储、管理和应用,因而,基于快速发展的计算机视觉技术对图形识别进行深入研究已成为计算机智能识别中的一个分支,对简单图形的有效是被是智能识别的基础,也是关键。对于图形的识别研究已经有相当长的一段历史,从第一台计算机诞生起,人们便赋予了其基本的图形识别能力,如扫描、复印等等,而现在,这些基本的图形识别已经不足以满足计算机应用领域发展的需求,很多领域需要具有更强大识别功能的系统。对于图形的识别包含对图形整体的识别和对图形局部的识别,当然,局部特征是识别图形的关键所在,只有通过算法分割、获取图形更多的局部信息,才可以更好的展现出图形识别系统的优势。
在互联网技术高速发展的时代,非常符合人们视觉认知与审美习惯的图形已成为人们日常生产生活中信息处理与传递的重要载体,字符、图形、图像,从简到繁,他们所蕴含的信息在储量上也会有着很大的差别,越复杂的图形往往识别难度越大。在现阶段,用于图形识别的方式主要有局部算子提取、灰度级提取等,运用这些方式,可以有效识别各种图形,如商标、照片等。当然,目前在图形识别研究中由于研究目的和方向不同,学者采用的方法也多种多样,具体而言,根据识别的层次不同,可以将识别方式划分为两类:其一是对图形特征进行描述的方法,譬如Freeman链码表示法、不变矩特征描述算子、傅里叶算子和Blum图形骨架法等,这些方法会对图形的色彩、轮廓等具体属性进行描述;其二是先对图形进行特征提取而后进行识别的方法,这类方法弥补了图形特征描述的不足,在细节描述的基础上结合了相关特征区域的提取,从而提高图形识别的精准度。如图1所示。
2 搭建图形识别环境
基于OpenCV设计图形识别系统,首先需要遵循OpenCV的运行程序,在计算机函数算法的基础上整合各个步骤,分类聚合,形成一个完整而又科学的图形识别系统。系统的形成在于环境,硬件与软件环境是系统设计的基础,因而,图形识别系统的第一步要搭建图形识别环境,具体的图形识别环境包括一些两个部分:
2.1 OpenCV调用
尽管在上文中提及到OpenCV有着非常强大的兼容性,可以在不同的操作系统上和软件工具中运行,但是还是要采用恰当的接口,才能够让OpenCV顺畅运行。本文所用的软件为OpenCV3.3版,在Java已经建好项目的Eclipse开发环境中解压OpenCV压缩包中的build文件,选择OpenCV-x86包导入,并选择与电脑操作系统相对于的OpenCV-300库导入到现有项目中,这些准备工作完成之后,便可以在现有项目环境下运行OpenCV。
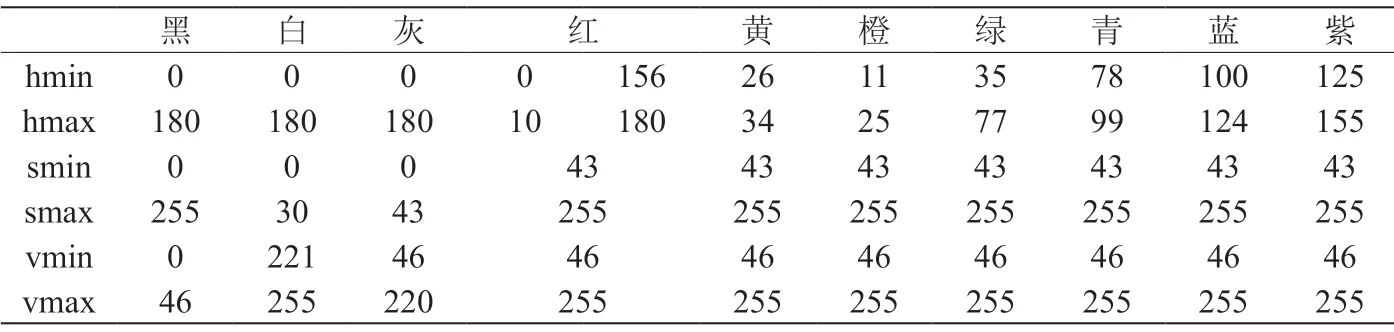
表1:各颜色H、S、V取值范围

图2:识别原图

图3:保留红色区域图
2.2 图形预处理
对图形进行预处理,是为了提高后面OpenCV图形识别处理的速度和质量。图形的预处理包括两方面内容,一方面是对图形的像素值进行处理;另一方面是对图形的颜色空间进行处理。首先采用OpenCV-Java库中的函数Imgproc.resize(src,dst,dsize)对图形的像素值进行处理,也就是用函数命令将图形缩小,其中,函数命令中scr为原图,dst 为图形输出。
之后,同样采用相应的函数命令对图形的颜色空间进行处理。相较于对图形像素值的处理而言,对图形颜色空间的处理较为繁琐,因为在OpenCV所默认对图形作出处理的是BGR颜色空间,但是现在多为可以把任何像素颜色都表示为红、蓝、绿组合的RGB类型图形,所以需要将RGB类型的图形转换为BGR模型,但又由于光环境的影响,RGB模型不能够将颜色进行细致的区分,这就需要采用HSV模型来对图形的颜色进行比较细致的区分。HSV是一种可以根据颜色的直观特性而创建的颜色空间,其具体参数为H(色调)、S(饱和度)、V(明度),其中色调与饱和度用来表示颜色信息,明度是表示像素的一个单独参数,在具体操作中可以忽略明度这一参数,只关注色调与饱和度这两个与颜色信息有关的参数。因为HSV颜色空间中的颜色在H、S与V方面都有着明确的取值范围,便非常容易将图形的颜色进行分割 (各颜色三个分量 H、S、V 取值范围请见表1)。将识别度不高的BGR再次转换为HSV模型,具体通过cvtColor这一方法对进行图形模型的转换,其各步骤函数命令分别为“Imgproc.cvtColor (imageResized, HSVImg,Imgproc .COLOR_RGB2BGR ) ”、“Imgproc.cvtColor(imageResized, HSVImg, Imgproc.COL-OR_BGR2HSV)”,其中图形导入的命令为imageResized ;图形输出的命令为HSVImg。在颜色空间转换完成之后,利用H与S的范围取值对图形颜色进行预区分。图2、图3分别为是原图和经过提取只保留红色区域后的图形影像。
3 读取图形信息
读取图形信息是继图形预处理之后对图形进行的识别工作,具体的读取包括三大步骤,即图形颜色的识别、图形形状的识别、图形拟合检验。第一阶段是图形的颜色读取,包括以下步骤:
(1)获取经过预处理的图形像素点的H、S和V的值,并在HSV颜色空间内遍历图形的像素点,以便通过具体的H、S、V取值来辨别图形上的颜色,进而精准获取各种颜色对应的像素点,同时累计其具体个数。具体说来,在获取图形像素各颜色H、S、V的值时,采用的函数代码为:
double[]clone = HSVImg.get(i, j).clone();
int h= (int)clone[0];
int s = (int)clone[1];
int v = (int)clone[2];
(2)在获取图形各颜色像素点值之后,通过设置阈值来进一步将图形的颜色进行分割,设定阈值是为了避免在图形颜色识别过程中受到光影的干扰。文章根据图形的颜色属性,将阈值界值设定为200,也就是说当阈值大于等于200时,说明图形中有该种颜色;阈值小于200时,则说明图形中没有此种颜色。之后,用OpenCV中的Scalar类对图形颜色进行辨别,得到各种颜色取值的大小限值。比如,在分割图形颜色之后,绿色的最大值为Scalar Maxval=new Scalar(77,255,255);// 绿色最大值;其最小值为Scalar minval=new Scalar(35,43,46);// 绿色最小值。在得到各颜色的大小限值之后,采用函数 Core.bitwise_and()将分割后得到的区域颜色图形保存到局部变量rdst当中。之后,将颜色分割之后的区域图形输出,便得到了颜色分离之后的图形,对其他颜色的分割与上述对绿色分割的过程相同,反复操作,将函数命令中的主题颜色替换即可。在获取各颜色像素点值的基础上按颜色区域对图形进行分割,如此便完成了对图形第一阶段的识别工作,但为了图形识别有着较高的质量,还需要对上述识别结果的基础上进行第二阶段的识别。第二阶段的识别是形状识别,这一识别过程要求图形必须是三通道图像,所以需要将保存在局部变量rdst中的各颜色图形转为三通道图像,具体函数命令为 rdst.convertTo( rdst, CvType.CV_8UC3),以便于后期进行灰度化处理,在将各颜色图形格式转换完毕之后,相继进行以下步骤对图形的形状进行识别:
3.1 图形滤波除噪
在第一阶段颜色识别中,经分割所获取的各颜色区域图形难免会存在噪点,为了尽可能避免光影环境对图形识别试验的干扰,需要在图形形状识别之前进行滤波除燥处理,用中值滤波器去除干扰因素,中值滤波器是一种典型的低通滤波器,可以在除噪的同时使之前分割的各颜色图形保持边缘特性。滤波除燥所对应的OpenCV方法是medianBlur。
3.2 图形灰度化
OpenCV对图形形状的识别是环环相扣的,前一步骤是后一步骤的必要充分条件。将已经转换好格式的各颜色图形进行灰度化处理,为之后的二值化奠定前提条件。图形灰度化处理的函数命令为:
Imgproc.cvtColor(imageResized,HSVImg,I mgproc.COL-OR_BGR2GARY),通过这一函数将原先彩色图形中的三个参数即H、S、V的数据取量降低,从而使得各颜色图形中的每个像素点只包含灰度信息,其值域为[0,255]。
3.3 二值化和膨胀
图形的二值化处理是对已经进行灰度处理而获得的图形设置合理的阈值,以进一步降低函数的运算量。所谓的二值化处理,其实是采用 threshold方法把整个图形处理为只包含黑、白两值的像素点,其中黑值为0,白值为1,这相对于灰度像素值再次降低,对图形的识别更加方便快捷,经二值化处理后得到的图形可以中几何学的概念进行特征描述和分析。
但是,二值化处理之后的图形仍然会存在一些杂点,这些杂点会对接下来的试验产生一定程度的干扰,可以利用背景膨胀将杂点去掉,以保证试验的高精准。背景膨胀所对应的方法是dilate,一般来讲,背景膨胀是用结构元进行膨胀或者进行腐蚀运算,其原理为当结构元的原点像素经过待膨胀的经二值化处理后的图形中所有白值(即值为1)像素点时,结构元所有白值像素点所对应的待膨胀二值化处理后的图形像素这便设定为1,这样经过背景膨胀后的图形便将绝大部分微小的杂点去除掉。算上对图形的预处理,图形经过HSV颜色空间转化、各颜色区域提取、滤波处理、灰度化处理、二值化处理和背景膨胀,得到了较为精准的各颜色区域图形,且函数运算量大大降低,这为下一步的图形识别做好了充分的准备。除燥二值化图如图4所示。
4 轮廓拟合
对图形的识别最后一个环节是对图形轮廓的捕获和拟合,具体说来,首先需要找到图形的轮廓,这就要用腐蚀函数,即Imgproc.erode将图形中那些零散不连通的像素点去除掉,而后在用膨胀函数命令Imgproc.dilate 把现有的图形轮廓连通。在本文实验中体现为:采用上述提及的滤波、膨胀等函数命令将干扰图形轮廓的像素点去掉、将并不封闭的轮廓去掉。具体的函数命令为:采用Imgproc.findContours获取图形的轮廓,而后用命令:

将干扰轮廓识别的杂点以及其他不成型的轮廓去除掉。而后,用findContours命令提取目标图形轮廓,这样提取出来的轮廓图像是一张二值图像,也就是说只有黑值和白值,但是输出的图像显示的是每一个连通区域轮廓点的集合,要想更真切的看清图形的轮廓,还需要采用 drawContours 方法把点集合成的轮廓画出来。
在将轮廓捕获出来之后,下一步便需要对捕获的轮廓进行拟合,拟合的过程也称之为轮廓逼近。OpenCV中有大量的用于轮廓拟合的函数,如minAreaRect、isContourConvex、boundingRect、contourArea、convexHull、minEnclosing-Circle、moments、ap-proxPolyDP等等,这些函数方法各有偏重,需要在具体的试验中根据所捕获图形轮廓的特征选择最恰当的函数用来实现拟合。本文在上述步骤中所捕获的图形轮廓由散点集合而成的线段居多,因而选择 approxPolyDP 这一方法对轮廓进行逼近处理。在逼近处理的过程中,线段的长度可以根据具体实际情况进行调整,一般而言,线段的长短不同,所拟合出来的轮廓对于线段数量的需求也就不同,用长度为12.0的线段对前面的轮廓进行逼近,而逼近圆形、三角形和矩形所用线段的数量分别是8条、3条和4条,而且从逼近的过程来看,用于逼近的线段之间有着明显的界限,这说明对圆形和简单多边图形实现了较好的识别。轮廓拟合的内在原理是:用函数Imgproc.approxPolyDP 对图形轮廓进行拟合处理之后,可以通过函数polyShape.toArray().length获取轮廓凸点个数及凸点彼此间的距离,根据凸点位置、凸点个数、凸点彼此间的距离判断图形的具体形状。
5 总结
本文基于OpenCV,在大量实验的基础上,对一些简单的图形进行识别;并遵循实验逻辑整合步骤形成完整合理是图形识别系统,最后结果显示,按照该流程系统对图形的识别精准度可达到99%以上。实验过程中,用Java调用OpenCV,并注重实验的细节处理,如颜色空间、图形格式、滤波处理等等,这些细节性的处理在图形识别系统中非常关键,对识别精准度影响巨大,所以,在具体的实验中,要统筹处理识别系统的各个步骤。基于OpenCV所设计的图形识别系统可应用于实际生成生活之中,如交通信号识别、门禁识别等等。但本实验中存在的不足是没有对较为复杂的图形进行识别研究,在今后的研究中,将尝试扩大图形识别的范围、增加识别的难度,一方面检验本文所设计图形识别系统的可重复性,另一方面促进智能识别工作的进步。

图4:除燥二值化图
猜你喜欢
北京航空航天大学学报(2022年6期)2022-07-02
高技术通讯(2021年3期)2021-06-09
装备制造技术(2020年1期)2020-12-25
制造技术与机床(2019年11期)2019-12-04
上海大学学报(自然科学版)(2018年5期)2018-11-02
自动化学报(2017年5期)2017-05-14
自动化学报(2017年11期)2017-04-04
光学精密工程(2016年1期)2016-11-07
计算机工程(2015年4期)2015-07-05
舒适广告(2008年9期)2008-09-22
