
基于大数据思维实现全球三十国GDP总量分析与预测
2020-01-14 11:05:54王硕,彭虹
安徽科技学院学报 2019年5期
王 硕, 彭 虹
(福建农林大学 金山学院,福建 福州 350002)
随着人工智能与大数据时代的到来,经济学与大数据的结合为经济学的研究提供了新的发展方向[1]。探索性数据分析(Explorative Date Analysis,EDA)更为经济学领域带来了新的、更为科学的研究分析方式。在传统的科学看来,数据是需要彻底“净化”和“集成”,计算的目的是找出“精准答案”,而其背后的哲学是“不接受数据的复杂性”。然而,大数据中更加强调的是数据的异构性、动态性和跨域等复杂性,其中包括弹性计算、鲁棒性、虚拟化和快速响应等不同种手段。图灵奖获得者Jim提出了科学研究的第四范式,即数据密集型科学发现(Date-intensive Scientific Discovery)。“数据密集型科学发现范式”的主要特点是科学研究人员只需要从大数据中查找和挖掘所需要的信息和知识,无需直接面对所研究的物理对象。从“基于知识解决问题”到“基于数据解决问题”,重视“相关性”的分析,而不仅仅是因果分析[2]。
亚当·斯密的经济学理论是以个量分析为主,根据对单个消费者、厂商和生产要素所有者的分析来进行经济学理论和经济现象的研究和分析。凯恩斯主义经济学则侧重于分析总量变量,根据他所建立的涉及总量变量的理论,主张从国家层面干预经济生活[3]。传统的经济学研究都以经济现象的理论研究为主[4],即大多以“基于知识解决问题”的研究方式,辅助以少量、个体、单一性、非动态性、非异构性的数据来解决已发生的经济现象,缺乏对经济学理论和经济现象形成和发生的独创性、预见性、科学性和普适性的研究。国内学者基于大数据分析的相关研究从2012年开始。覃雄派等[5]以MapReduce为代表的非关系数据管理技术阵营,从关系数据管理技术所积累的宝贵财富中挖掘可以借鉴的技术和方法,面向大数据的深度分析需求,分析了RDBMS与MapReduce的竞争与共生。喻国明[6]以2009~2012年百度搜索词数据库为研究对象,运用大数据的价值挖掘与分析技术,对“社会暖度”“社会幸福感”以及“社会压力”等中国社会的舆情指数进行测度并提出了社会管理和协调的重要启示。杨虎等[7]构建了基于大数据分析的互联网金融风险预警系统,并提出了互联网企业风险管理的依据和措施。崔媛[8]基于农业气候对农作物的影响,利用大数据分析了C-D-A模型的可行度并提出了各种天气条件下保障与提高农作物产量的理论依据。
从现有研究可以看出,如何科学有效的利用好经济数据去研究动态的、多维的、复杂的经济学理论和经济现象成为现代经济学研究的新课题,现有研究已经将大数据分析方法运用于宏微观经济、自然环境分析中,但以全球经济为分析对象,结合大数据分析方法进行实证,并进行经济预测的研究较为缺乏。本文针对多维相关性数据条件下的全球GDP总量排名前30国GDP未来发展相关性变量的研究,对30国GDP未来发展给出了趋势变化情况和相关性分析,进一步丰富大数据研究中的理论和实践内容。
1 数据的处理及模型设定
1.1 前30国GDP总量
研究以2017年为例,选取了全球GDP排名前30位的国家为研究对象,数据来源于世界银行网站。数据显示,2017年美国和中国GDP总量均在10万亿美元以上,其中美国GDP总量已经接近20万亿美元(表1)。
由表1可以看出,全球GDP排名前30国GDP总量占全球GDP总量的比值为85.81%。前30国GDP总量占比已经达到全球GDP总量的85%。采用前30国作为研究对象,在得出2018~2022年前30国GDP总量及发展趋势的同时,可以实现从局部对未来全球GDP总量及经济发展情况的有效预测。

表1 全球GDP排名前30国及其GDP总量
数据来源:根据世界银行网站数据整理所得。
1.2 影响全球GDP总量的因素
全球共233个国家和地区,其中国家有197个,地区有36个。由于影响国家GDP总量的因素较多,其中涵盖政治、经济、人文、地理等各个方面,因此难以实现对所有影响因素进行全部归类,进而进行所有变量的相关性分析。为了对前30国GDP总量进行精确的预测,并基于现有数据的可获得性以及考虑尽可能不造成数据混乱及相关性数据的不可降维性,从影响经济发展的角度挑选可能对各国GDP产生影响的因素:其中主要因素是国家财政收入、实际利用外资额、广义货币供应量、财政支出总量、固定资产投资总额[9]、不同国家的人口量、劳动力参与率、居民消费价格指数、国民生产总值、能源总量、对外贸易总量[10]、税收收入、汇率、外债、实体经济虚拟经济占国家GDP总量比重等[11]。
1.3 数据的收集处理
研究采用python软件在世界银行网站中收集到相关性变量数据,对于影响前30国GDP相关性数据进行探索性数据分析(Explorative Date Analysis,EDA)。然后对相关性数据进行归纳整理,迅速获取我们所需要的相关性指标量。
1.4 聚类分析对于不同类型经济体的归类
层次聚类法是最常见的一种聚类方法,在数据挖掘和基因表达分析领域经常使用。使用该方法无须事先了解数据总共分为几类,例如,数据没有按照预先设定的类别数进行划分。相反,结果由一个层次或一组嵌套分区构成。基于模型的聚类框架包括三个主要的部分:
首先,利用基于模型的聚合聚类分割对EM算法进行初始化;其次,通过EM算法对参数进行最大似然估计;第三,根据贝叶斯因子的BIC逼近,选择模型和类别数。
模型将分类似然函数作为目标函数。分类似然函数公式如下:
其中γi是第i个观测点的分类标记,如果xi属于第k个成分,则γi=k。在混合模型当中,每个分量包含的观测点数n呈多项式分布,其概率参数为π1,π2,……,πc。
基于模型的聚合聚类方法是对分类似然函数最大化的过程。起始状态时每个点为一个单一的类,算法执行时每一步骤将分类似然函数增长最快的两类合并。这一过程重复执行直至所有观测点合并为一组。
根据python所收集的数据,为了对大量动态的、多维的、异构性数据进行有效降维[12],将前30国划分为不同大类的经济体,进行合理科学的归纳分析;运用SPSS进行聚类分析,采取层次聚类对数据情况进行分类汇总(图1)。

图1 聚类分析30国聚类结果图
由图1可知,全球GDP排名前30国被划分为5类,分别为美国、中国、日本、印度各为一类,其余国家为一类。通过层次聚类得出具有类似特征值的国家,用以对不同国家进行科学系统划分,为运用BP神经网络多隐含层变量法对前30国进行精准预测做铺垫。
1.5 BP神经网络预测模型
根据生物体大脑的原理开发的人工神经网络可以定义为一凭借众多简易的并行工作处理单位合并而成的复杂系统,它的工作原理由网络的结构、关联的程度和众多单位的应对问题时的策略选择决定,和非线性动力学系统相似,与人类思维十分相近。BP(Back Propagation)网络为目前被普遍使用的人工神经网络模型的代表,其实质为一种按误差逆传播算法工作的多层前馈网络。考虑到BP神经网络可以对非线性模型进行预测的特性,因此在本文中采取了BP神经网络对全球前30国GDP总量进行预测与分析。
BP神经网络是应用最广泛的神经元网络模型之一,其学习过程中由信号的正向传播与误差的逆向传播两个过程组成。正向传播时,模式作用于输入层,经隐含层处理后,传入误差的逆向传播阶段,将输出误差按某种子形式,通过隐层向输入层逐层返回,并“分摊”给各层的所有单元,从而获得各层单元的参考误差或称误差信号,以作为修改各单元权值的依据。权值不断修改的过程,也就是网络学习过程。此过程一直进行到网络输出的误差逐渐减少到可接受的程度或达到设定的学习次数为止。BP网络模型包括其输入输出模型,作用函数模型,误差计算模型和自学习模型。BP网络由输入层,输出层以及一个或多个隐层节点互连而成的一种多层网,这种结构使多层前馈网络可在输入和输出间建立合适的线性或非线性关系,又不致使网络输出限制在-1和1之间[13]。
2 实证分析
根据聚类分析所划分的5种不同经济体类型,运用BP神经网络将技术与产业革新、劳动投入[14]、国家财政收入、实际利用外资额、广义货币供应量、财政支出总量、固定资产投资总额、不同国家的人口量、劳动力参与率、居民消费价格指数、国民生产总值、能源总量、对外贸易总量、税收收入、汇率、外债、实体经济虚拟经济占国家GDP总量比重等多变量因素;结合各个国家1987~2017年GDP总量数据带入BP神经网络中。
2.1 美国
如图2所示,美国GDP总量一直保持较高的增长态势,但在2020年之后GDP总量增长逐渐趋缓,这是由于美国的经济体量较大,经济较为发达,市场结构较为健全,很难再找到新的经济增长爆发点,同时不断升级的贸易摩擦带来的风险也是阻碍美国经济增长的重要方面(表2)。

图2 美国GDP总量神经网络预测图

表2 美国GDP总量预测结果
2.2 中国
中国GDP总量随着中国经济增长前景继续表现强劲,为中国加快推进经济改革提供新的发展契机。供给侧结构性改革和贸易摩擦虽然给中国经济在2018~2020年期间带来经济阵痛,但是在2020之后随着技术与产业革新的逐步完成,中国经济又呈现阶梯式爆炸性增长(图3,表3)。

图3 中国GDP总量神经网络预测图

表3 中国GDP预测结果
2.3 日本
日本在上世纪90年代后出现经济停滞,虽然在2009年前后出现经济较快增长,但又很快出现下滑。其主要原因是日本经济一直面临着经济增长放缓、工资增长缓慢、生产率增长乏力、人口老龄化等问题的影响,如果未来上述问题仍不能得到效解决并出台相关解决政策,未来日本经济增长仍然不容乐观(图4,表4)。
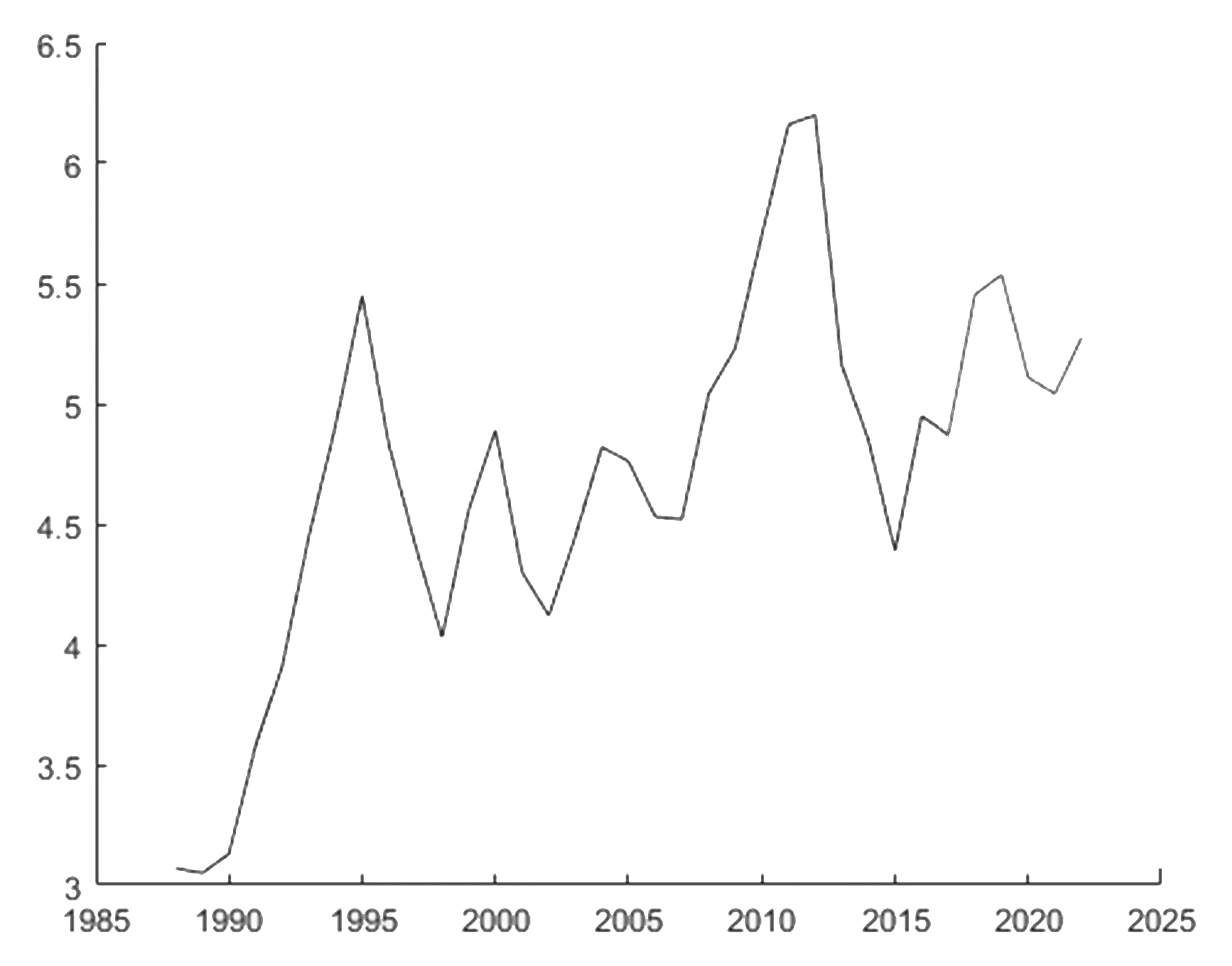
图4 日本GDP总量神经网络预测图

表4 日本GDP总量预测结果
2.4 印度
印度经济在2018年后迎来了较快发展,主要是由于人口红利所造成的。印度的发展模式重消费而非投资、重内需而非出口、重服务业而非制造业、重高新技术产业而非劳动密集技术含量低的工业,这种方式使印度经济对全球经济不景气冲击的抵抗力较强,表现出比较强的韧劲和经济平稳增长的长周期性。印度经济在2020年后又呈现出新的较快经济增长(图5,表5)。
图5 印度GDP总量神经网络预测图

表5 印度GDP预测结果
2.5 剩余国家
剩余国家2018~2022年间GDP总量预测值呈现锯齿形变化趋势,这是由于全球经济发展的不确定性因素较多,平均增速放缓,经济下行压力大。据彭博社经济部称,2018年全球经济增速急剧放缓,扩张速度降至2008年全球金融危机以来的最低水平(图6,表6)。
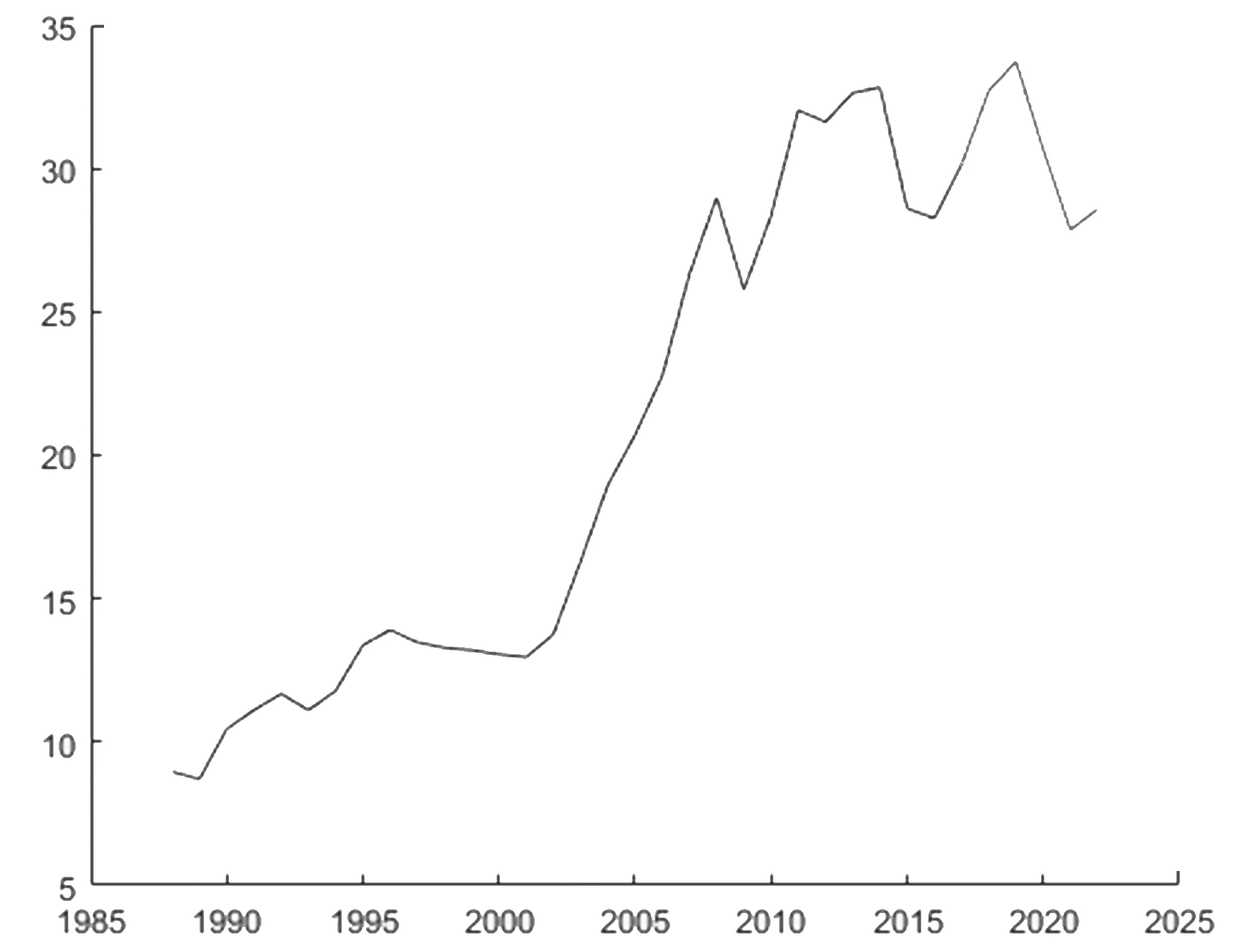
图6 剩余国家GDP总量神经网络预测图

表6 剩余国家GDP预测结果
研究将上述实证数据进行分类加总,则全球30国的GDP总量预测结果见下表9所示。根据预测结果,2018年全球30国GDP总量增长速度为7.79%,2019年将放缓至4.27%;2020年全球30国GDP总量出现下降,下降速度为2.40%,2021年下降速度为2.46%;2022年又出现增长,增长速度为3.92%。全球经济增速放缓,经济的不稳定和不确定性使得30国的经济发展一直维持在一个较为低迷的发展状态(表7)。

表7 全球三十国GDP总量预测结果
3 结论与建议
3.1 结论
2018~2022年全球前30国经济增长整体而言较为缓慢,虽然在变化中也有增长趋势,但经济增长的动力仍明显不足,其中有部分国家甚至出现经济停滞和经济倒退的情况。其主要原因可能是是前30国经济受制于一系列深层次结构性困境,难以走向复苏和增长。从分析可以看出,中、美、印3国仍旧是2018~2022年前30国经济增长的主要动力。从整体来看,在未来的一段时间,前30国经济由于又受到逆全球化升温、贸易保护主义抬头等新的不确定性因素影响,其国家经济发展将与全球经济发展保持较为相似的变化趋势,即将维持低增长和弱复苏态势,短期内不稳定性、不确定性增加。
3.2 政策建议
首先应加强全球层面的经济治理与经济改革,推动全球经济一体化,更合理地解决全球资源的利用问题。第二,健全更具约束力的贸易规则,减少各国贸易摩擦。第三,稳步深化金融政策改革,加强金融监管。第四,加大对经济困难国家的政策性投资及援助力度,充分促进不发达国家经济增长,以此带动发达国家、发展中国家的经济增长。
各国政府应首先加大对固定资产的投资,大力支持新兴产业的发展。第二,就业是民生之本,应有效促进就业。第三,积极实施出口优惠的税后政策,鼓励企业出口,减少相关产业的贸易保护,促进市场的自由竞争。第四,注意优化财政支出结构,减少直接的财政干预经济的方式。第五,为市场松绑,充分发挥市场在资源配置方面的主导作用,充分挖掘市场潜力。第六,规范合理政府支出,提高政府支出效率。第七,进一步深化供给侧结构性改革,改变市场供求关系。第九,加强对实体经济的政策性倾斜力度,以实体经济带动国家经济发展。
猜你喜欢
黄河之声(2022年10期)2022-09-27 13:59:46
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
今日农业(2021年3期)2021-12-05 01:46:23
今日农业(2021年10期)2021-11-27 09:45:24
电子制作(2019年19期)2019-11-23 08:42:00
中国化肥信息(2019年1期)2019-01-17 21:31:12
中学生数理化·八年级物理人教版(2017年11期)2017-04-18 11:22:51
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
