
基于AlexNet模型的AD分类
2020-01-14 07:48:48张柏雯吴水才
北京工业大学学报 2020年1期
张柏雯, 林 岚, 吴水才
(北京工业大学生命科学与生物工程学院, 北京 100124)
阿尔兹海默症(Alzheimer’s disease,AD)是最为常见的神经退行性疾病. 随老龄化趋势,预计到2050年,全球AD患者将达到1.6亿[1]. 目前AD的发病机制尚不明确,一经发现难以逆转. 但AD一般具有较长的临床前期,若能在AD早期发现并及时做出正向的治疗干预,将有可能延缓AD的发病时间[2]. 轻度认知障碍(mild cognitive impairment,MCI)是介于AD与正常老化(normal control,NC)的一种中间状态,MCI患者被认为是AD患病的高危人群[3]. 但老年人的认知退化程度与临床表现常存在特异性[4],单凭认知量表测量难以准确区分. 结构磁共振图像(structural magnetic resonance imaging,sMRI)因其对脑部组织解剖结构显像的高分辨率,且具有无创、图像易获取等优势,被广泛用于AD的早期诊断中.
深度卷积神经网络(convolutional neural networks,CNN)近年来在图像识别领域表现突出,逐渐被运用于医学图像领域的研究中[5]. 相比于传统机器学习算法需要手工特征提取,深度学习的方法不但能够发现一些潜在的疾病特征,同时减少了手工提取感兴趣区的人为因素,避免或减少了模型构建前的预处理步骤,提高了工作效率[6]. 由于sMRI是三维的影像模态,最合适的研究方法是直接建立三维的CNN模型. 但总体来说,三维的CNN模型目前还不是特别成熟. 在深度学习时代,数据至少与算法一样重要,CNN需要大量的数据进行预训练. 神经影像的样本数目远小于自然图像的数目. 三维的CNN模型必须在模型复杂度和训练收敛性之间做一个权衡,难以充分发挥三维模型的优势. Hosseini-Asl等[7]运用自编码器与三维CNN结合的方法进行AD分类预测,在AD与NC中取得了97.6%的分类准确率. 尽管该模型取得了优异的性能,但它需要将三维体素块输入自编码器进行大量训练,得到预训练好的卷积核后再输入三维的CNN模型中. 这种网络训练的方式,存在训练复杂度高、模型深度较浅的问题. 另一种可行的方法是借鉴在ImageNet举办的大规模视觉识别挑战赛(ImageNet Large Scale Visual Recognition Challenge,ILSVRC)中脱颖而出的经典网络,如AlexNet[8]、GoogleNet[9]等,来进行AD、MCI与NC的分类研究[10]. Sarraf等[11]将功能磁共振成像(function MRI,fMRI)和sMRI转换为二维的图像切片后分别输入LeNet-5[12]和GoogleNet中,通过对经典网络模型的迁移训练实现对AD与NC分类. 该方法在fMRI中获得了94.32%的准确率,在sMRI分类准确率中最高一组达到98.7%. 但该方法的一个严重缺陷是没有考虑到同一受试者的二维sMRI切片间存在很高的空间相关性,同时fMRI二维切片也存在时间和空间相关性. 这样,预测集和验证集图像间有很高的相关性,实际的分类模型并不能很好地解释AD的分类结果. 吕鸿蒙等[13]运用AlexNet及增强AlexNet网络模型,在AD与NC、AD与MCI、MCI与NC的分类中分别取得了94.70%、97.10%、80.62%的准确率. 但该研究同样也存在没有考虑sMRI空间相关性的问题.
在ILSVRC出现的经典模型中学习的权重可用于初始化其他数据集的模型,并显著提高性能. 本文基于NC、MCI和AD的sMRI和CNN中的经典模型AlexNet,运用迁移学习的方法提取图像特征,再进行三维特征重组,之后结合机器学习的方法建立分类模型,实现AD、MCI及NC的分类.
1 材料与方法
1.1 研究对象及数据获取
本研究受试对象为422名年龄在55~90岁的老年人,数据均来自于阿尔兹海默症神经影像学计划(Alzheimer’s Disease Neuroimaging Initiative,ADNI)数据库(http:∥adni.loni.usc.edu/). 采用的是ADNI-1阶段的延续“ADNI重大计划项目”(ADNI Grand Opportunities,ADNI-GO)与ADNI-2阶段的AD、晚期MCI(late MCI,LMCI)与NC受试者的基线(baseline,即第0个月)sMRI数据[14]. 受试者均无抑郁等精神疾病,并根据ADNI的要求接受跟踪随访的数据采集,每次受试均接受简易精神量表(mini-mental state examination,MMSE)及临床痴呆评测表(clinical dementia rating,CDR)评测. 实验对象具体特征如表1所示.

表1 实验对象特征
数据集采集设备均为Philips 3.0T MRI扫描设备,研究所需图像为三维磁化快速梯度回波成像MPRAGE,TR=6.8 mm,TE=3.1 mm,FOV:RL=204 mm;AP=240 mm;FH=256 mm,扫描层厚为1.2 mm,层数为170,体素为1 mm×1 mm×1.2 mm.
1.2 AlexNet网络结构
本研究中特征迁移学习使用的基础网络模型为AlexNet,结构如图1所示. AlexNet为8层网络结构,前5层为卷积层,后3层为全连接层,其中前2层卷积和第5层卷积后均跟随池化层,每一个卷积层均采用ReLU激活函数[8]. 大小为227×227的RGB三通道图像输入AlexNet,分别经过了卷积、ReLU、池化、归一化过程. 其中第1层卷积过程的卷积核大小为11×11,步长为4;池化采用为重叠池化,设置步幅为2、池宽为3的滑动窗口. 第2层卷积过程的卷积核为5×5,步长为1,池化方式与第1层一致. 经过上述过程,在第2层的输出大小变为了13×13×256. 之后的3个卷积层均采用卷积核大小为3×3,步长为1. 在第5层卷积后跟随1次池化,池化方式与前2层相同. 经过5次卷积计算,可将图像的特征进行抽象,往往能表达出具有分类特征的信息. 各层具体的网络参数如表2所示.
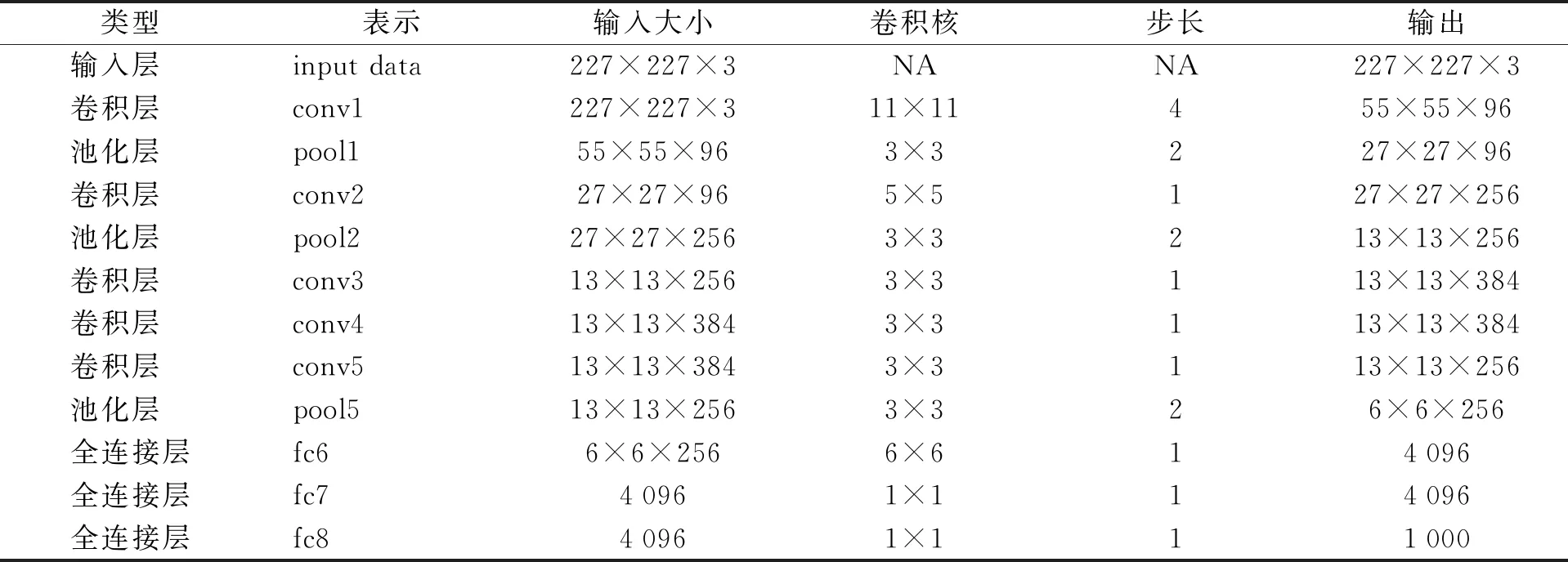
表2 AlexNet网络参数
1.3 图像预处理
前人研究显示灰质萎缩是早期AD与NC区分的重要依据[15],本研究中应用体素形态学(voxel-base morphometry,VBM)的方法,基于受试者全脑的灰质密度图而进行分析[16]. 全脑的灰质密度图在Matlab2015b(the mathworks,Sherborn,US)中运行通用工具包SPM-12(statistical parametric mapping,London,UK)完成[17]. 主要步骤有:DICOM至img+hdr的格式转化;将所有受试者的图像空间标准化到统一模板;再将脑组织进行分割,提取灰质信息;运用Dartel工具箱[18]将每位受试者图像依次迭代,与前一次生成的灰质模板进行配准,之后将所有配准后的图像平均得到新的模板,直到得到最优模板. 再将所有灰质图像标准化到最优模板,灰质平滑设置半高宽为8 mm的高斯平滑核. 经过调制后的灰质密度图,体素值就反映了相应的灰质密度信息.
AlexNet的输入图像尺寸为227×227的RGB三通道. 经过上述灰质密度图的生成步骤后,对每位受试者图像均进行插值、剪切与填充等步骤,以符合AlexNet的网络输入需求. 本文采用的是横断位图像输入网络模型的方式,考虑到AD与LMCI多发生于海马、内嗅皮质区、颞中回等区域,由于SPM-12生成灰质密度图的过程中,预处理过的图像在z轴横断面上、下均存在着空白区域,靠近z轴上端保留着少部分脑皮层区域、下端保留着小脑邱体,这些区域对AD与LMCI分类并不敏感. 为了降低后续分类中特征维度远远大于特征数对分类模型精度带来的影响,将这些空白区域与不敏感区域舍去,最终保留每位受试者在横断面的65层图像信息,再将所有图像分别转换为RGB三通道的伪彩图.
1.4 基于AlexNet的迁移学习特征提取
特征提取运行环境为:Ubuntu14.04,CAFFE深度学习平台,配置CUDA 8.0环境,GPU为Tesla k20c,内存为64 GB. 将图像输入预先训练好AlexNet模型,设置相对应的参数,进行逐层特征提取. 如图2为一幅灰质图像输入AlexNet模型后提取特征可视化后的示意图. 根据特征迁移学习的原理[19],靠近输入层的前端卷积层一般反映出的是图像的边缘、纹理等信息,如图2(a);靠近全连接层的后端卷积层一般反映的是图像细节信息,这些信息中能抽象出具有代表性的分类特征. 在AlexNet中一般认为conv3、conv4、conv5三个卷积层能用作之后的分类提取[18],如图2(b)~(d). 将每位受试者的图像按照z轴从上到下的顺序依次输入AlexNet提取特征,根据AlexNet模型的参数,如表2所示,即每一层图像在conv3、conv4的特征维度为13×13×384,conv5特征维度为13×13×256,将每位受试者的特征变量按照原65层排列顺序重新组成一组三维特征.
经过重组后的特征,每位受试者在conv3和conv4的特征维度都达到140万维以上(65幅13×13×384),而在后续分类中,每组的样本总量不足400例,这样的特征维度不但远远大于样本总量,而且存在过多的冗余信息,无疑会对后续分类造成维度灾难[20]. 因此对特征选用与AlexNet中一样尺寸的池化方法.
1.5 特征降维与选择
需要对AD与NC、AD与LMCI、LMCI与NC三组分别进行二分类. conv3、conv4和conv5虽然都能反映出输入图像的细节信息,但是具体在哪一层有更好的表现,在不同研究中并无定论,所以本研究将conv3、conv4和conv5的特征均作为下一步的分类特征. 在上述重叠池化降维后,虽然维度相较提取时的已有大幅降低,但相对于每个分类组的个数仍处于特征数远远大于分类样本数量,因此本研究分类模型构建首先进行了特征降维,再经过特征选择,最后构建分类器分类.
具体方法步骤如下.
步骤1运用主成分分析(principal component analysis,PCA)对各个分类组的原始特征进行降维. PCA能通过线性或非线性组合的方法构造相关特征,使原始的高维特征映射到低维,保留最重要的特征信息,可以从多元事物中更好地解析出主要的影响因素[21]. PCA主要计算过程有:读取各分类集数据;去均值、计算协方差矩阵;计算特征向量及特征值,并按照特征值大小排序;再根据各个主成分累计的贡献率大小选取主成分,从而得到降维后的矩阵.
步骤2运用序列前向搜索(sequential forward search,SFS)特征选择. 虽然经上一步骤所保留的特征已按照贡献率大小排名,但并不能说明贡献率高的特征对于接下来的分类器训练最佳. 因此接下来选用SFS的方法在每个PCA后的分类组的训练集中分别进行特征选择. SFS通过自上而下的搜索找到最佳特征,是一种“只出不进”的贪心算法[22]. 根据各组别受试者的实际个数,选择每组别随机化后合适数量的受试者作为SFS特征选择及之后分类器的训练集. SFS主要计算过程有:首先从空集开始;当遇到最佳分类特征时更新特征子集;重复上述过程,直到目标子集数量达到设定的个数为止;在实际选择特征时,能通过最终的特征目标子集的误分比率的最低值来确定哪些特征及多少个特征个数作为后续特征分类的训练集最佳.
步骤3运用支持向量机(support vector machines,SVM)构建特征分类器. 使用LIBSVM工具包[23],设置线性核函数对各分类组分别进行分类. 每组选用与上述SFS算法一致的子集作为训练集,其余受试者均为测试集. 最后,统计SVM的分类结果,对整体模型设计进行评估.
2 结果
首先,将conv3、conv4和conv5的各分类组进行PCA降维,保留贡献度在前95%的特征. 经过PCA后,所有分类组的特征个数均小于受试者的个数. 但是贡献度的排名并不能等同于分类信息的排名,如图3所示,在conv3中AD与LMCI分类组,图3(a)显示第一主成分的贡献率也只占到13%,排名的前50个主成分占到的主成分贡献率也不足50%. 由图3(b)可以看出,AD与LMCI并无明显的分界,说明即便第一主成分与第二主成分也不具有较强的分类敏感性. 所以需要在训练集进行SFS的特征选择,AD、LMCI与NC每组分别选择随机化后的75例受试者作为训练集,其余均作为测试集,各组分类集与测试集的个数如表3所示. 根据各分类组的SFS错误分类比率,大约在第20个特征时,错误分类率达到最低,且误分比率相对稳定. conv3中AD与LMCI分类组中SFS错误分类比率的统计图如图4所示. 所以对3个分类组SFS均选取20个特征作为下一步分类器构建.
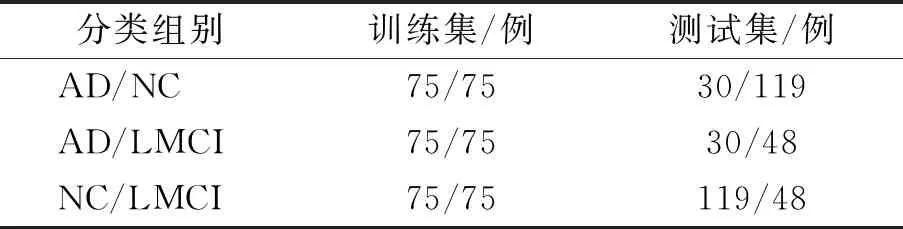
表3 训练集与测试集
将SFS选择出的各分类组的特征作为SVM分类器的输入,得到conv3、conv4和conv5的各个分类组的分类结果,如表4所示. 实验结果评价采用准确率(Accuracy)、灵敏度(Sensitivity)与特异性(Specificity)3项作为模型评价指标. 其定义为
(1)
(2)
(3)
式中:nTP为真阳性(true positive)在AD与NC、AD与LMCI的分类中,为被准确识别出的AD样本个数;在LMCI与NC的分类中,表示准确识别的LMCI样本个数.

表4 各组二分类结果
nFP为假阳性(false positive)在AD与NC、AD与LMCI的分类中,为AD受试者被划分为了NC或LMCI组的样本个数;在LMCI与NC的分类中,为LMCI划分到了NC组的样本个数.
nFN为假阴性(false negative)在AD与NC、AD与LMCI的分类中,为NC或LMCI受试者被划分为了AD组的样本个数;在LMCI与NC的分类中,为NC划分到了LMCI组的样本个数.
nTN为真阴性(true negative)在AD与NC、LMCI与NC的分类中,为被准确识别出的NC样本个数,在AD与LMCI的分类中为准确识别出的LMCI样本个数.
3 结论
1) 由表4的二分类结果表明,通过迁移学习提取图像特征再进行三维重组的方式,对于AD、LMCI与NC之间的分类是一种可行的方法. 对conv3、conv4与conv5三个卷积层分别进行了分类,经方差分析,得到p=0.97(p>0.05),说明conv3、conv4与conv5三层在分类结果的差异不具有统计学意义.
2) sMRI本身是三维图像,任何一个扫描层都可能与其上下层的扫描信息存在着重要的关联. 将三维图像转成二维,再使用深度学习网络训练的方法,并不会将每位受试者的信息作为一个整体. 这样训练集和测试集间存在高度相关,结果并不具有实际意义. 三维卷积网络由于神经影像数量的限制,并不能充分发挥三维卷积网络的特性,而且训练比较复杂. 本研究中,基于经典的二维卷积网络模型,通过三维特征组合的方式,将每位受试者看作一个整体而构建分类模型,取得了较好的分类结果.
3) 研究中也还存在一些缺陷. 更深、更广的深度模型是近期CNN领域研究的方向. 与AlexNet相比,VGG-16、ResNet、GoogleNet等网络模型在网络宽度更宽、在网络深度上更深、模型结构更加复杂[24],它们非常可能会为AD分类提供更好的结果. 与前人用深度学习方法在AD、MCI与NC分类研究中的结果对比,本研究的方法并未在实验结果中有明显的改进. 一个可能的原因可能是采用了迁移学习的算法来提取图像的通用特征,特征并没有为神经影像进行优化,后续的研究中将通过对经典网络进行微调训练来进一步提高模型性能.
猜你喜欢
中国心血管杂志(2022年2期)2022-11-25 17:29:20
中国心血管杂志(2022年4期)2022-11-25 16:59:06
小学生学习指导(低年级)(2021年9期)2021-10-14 07:57:00
中国心血管杂志(2021年6期)2021-01-02 08:18:16
中学生数理化·七年级数学人教版(2019年10期)2019-11-25 07:34:00
小学生学习指导(低年级)(2019年9期)2019-09-25 07:43:28
中国临床医学影像杂志(2019年2期)2019-04-25 06:15:38
中国临床医学影像杂志(2019年2期)2019-04-25 06:15:38
中国心血管杂志(2019年3期)2019-01-04 16:25:09
小学生学习指导(低年级)(2018年9期)2018-09-26 05:59:46
