
多 模 式 融 合 的 体 育 视 频 技 术 实 验 分 析
2020-01-13 09:59石庆福
实验室研究与探索 2019年12期
石 庆 福
(郑州轻工业大学 体育学院,郑州 450002)
0 引 言
视频一词源自于电视广播,它由一系列连续的静止图像组成,内容包括感知特征、结构信息和语义信息3方面。近几年来,随着体育运动的普及和盛行,体育视频转播有着大量需求,仅NBA每年的比赛转播就达到2 000余场次,因此体育视频分析有着广泛的应用[1-2]。视频中的语义分析是视频分析中比较重要的一项,经过多年来的努力,底层特征处理的系统和处理方法有了很大进步,但高层语义分析和理解仍然有很多亟待解决的问题,如:语义事件相互间关系研究的缺乏、多模式融合有效分析方法的缺乏和体育视频统一分析框架的缺乏。因此多模式信息融合技术近年来受到越来越多的关注,在体育视频分析领域占据越来越重要的位置[3]。在目前的多模式分析中,孤立事件成为主要考虑对象,通过分析各个孤立事件之间的逻辑关系或因果关系,有助于建立模型进行分析。这种模型的建立需要结合多模式融合的理论,而目前的模式融合有特征和决策2种形式的融合。不同形式的途径分别为:多特征空间共同进行特征融合,获取最终特征,进行特征到决策的转换,得到最终结果;或多特征空间首先分别进行特征到决策的转换,生成不同空间决策,再将不同决策共同进行决策融合,得到最终决策。
特征融合被称为前期融合,在融合后会产生高维向量,由于目前计算技术的限制,融合后的向量需要降维,然而目前这种降维方法仍有争议[4];决策融合被称为后期融合,在视频分析中比较常见,由于处理中有一个中间决策的过程,利用祁佳[5]所提出的概率推理融合不同模式线索的方法,将不同模式信息在贝叶斯网络中实现了融合。该项技术曾成功应用于F1赛车比赛转播中的精彩视频片段提取。
本文基于贝叶斯动态网络,提出了针对多媒体视频的多模式融合分析技术,实现了将多模式信息和事件上下文约束关系的融合处理分析。在贝叶斯动态网络理论的基础上,用拓扑结构表示事件的上下文关系,建立多模式之间交互关系。在此框架的基础上,成功设计了FHHMM、CHHMM和PHHMM 3种统计模型,并通过体育赛事视频对该技术的性能进行了验证。
1 多模式融合语义分析框架的建立
不同模式的分析和不同层次的约束关系是多媒体视频语义分析中的关键,文中基于贝叶斯动态网络,创造性地提出了多层次多模式分析框架,并设计了析因层次隐马尔科夫模型(Factorial Hierarchical Hidden Markov Model, FHHMM)、耦合层次隐马尔科夫模型(Coupling Hierarchical Hidden Markov Model, CHHMM)和乘积层次隐马尔科夫模型(Product Hierarchical Hidden Markov Model, PHHMM)3种模式,下面首先将给出3种模式的表示形式,然后讨论其学习和推理的算法。
1.1 模型表示
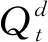

图1 3层HHMM的DBN结构
图1中的相关概率分布表示为3层:
(1) 最上层概率分布。

(1)
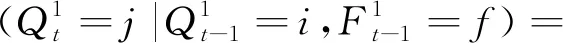

(2)
(2) 中间层概率分布。

(3)
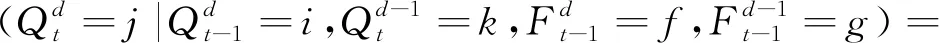
(4)
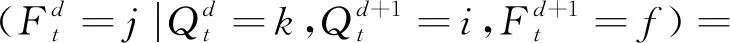
(5)
(3) 最下层概率分布。

(6)

(7)
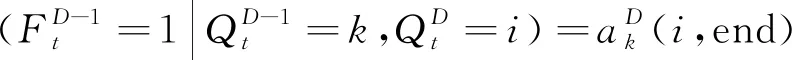
(8)
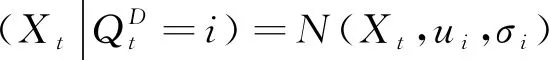
(9)

Xie等[7-8]采用HHMM发现体育视频内容的结构,将一个事件作为一个HHMM过程,然后将各独立事件之间通过马尔科夫链将关系联系在一起;Garg等[9-10]采用多层模型来训练和识别这些具有层次关系的事件;但这两者在多模式融合方面基本没有建树,只是想当然地认为所观测到的数据源于同一模式。
多模式融合在语音识别领域首次被尝试,而后得到重视,接着在贝叶斯动态网络基础上演化而来的被称作耦合隐马尔科夫模型得到大范围的应用[11]。以这种思路为参考,在HHMM模型的基础上提出了如图2所示的FHHMM、CHHMM、PHHMM 3种多模式融合贝叶斯动态模型。动态贝叶斯网络是一种相同结构延时间轴展开的贝叶斯网络,动态贝叶斯网络仍然是一种贝叶斯网络,这种周期性结构更加适合对时间信号的处理。图中方框表示状态变量,圆圈表示来自两个不同模式的观测变量。与传统的HHMM相比,由于这些模型的变量依然保持层次分布状态,故这些策略传承了HHMM层次结构处理的好处。
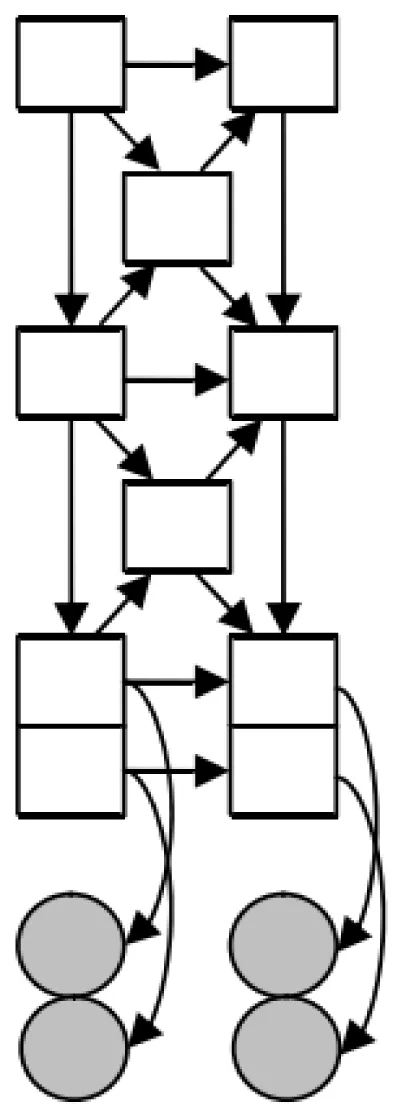
(a) FHHMM模型
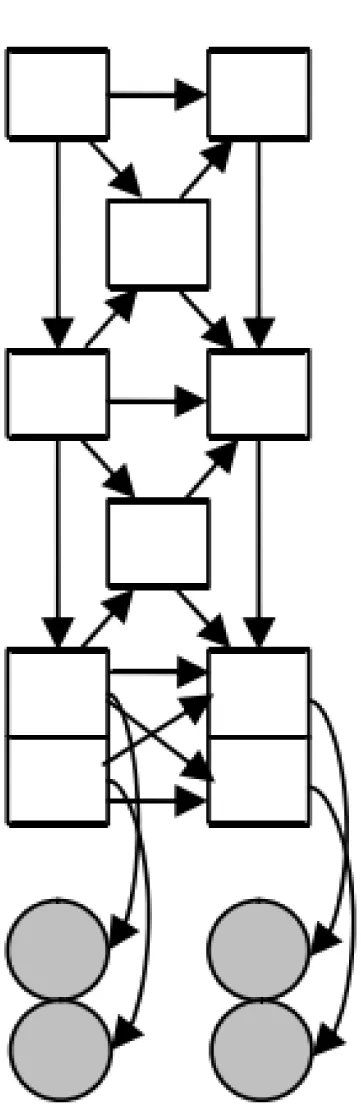
(b) CHHMM模型
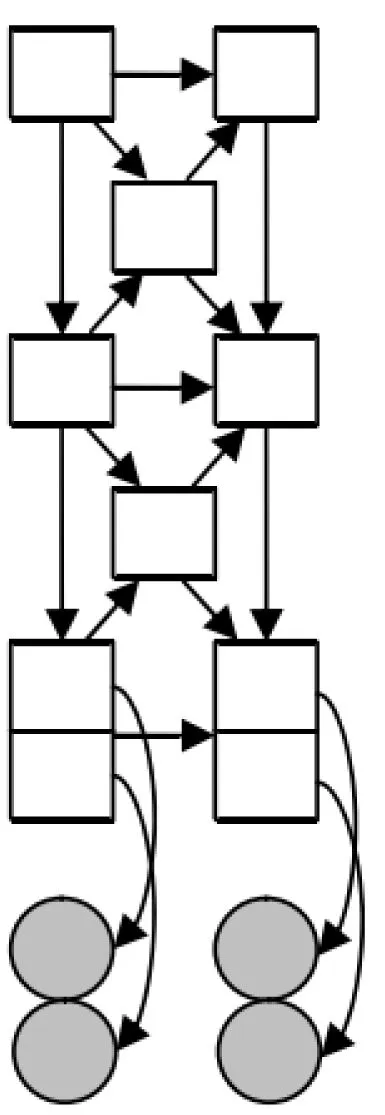
(c) PHHMM模型
除此之外,它们还具有两个优点:① 由于保持了层次结构,避免了融合多个模式时导致高维向量的处理;② 不同模式的箭头表示,可以将多种模式信息的相互关系展示出来。
在实际应用中,动态贝叶斯网络常用来表示一些时间系统的行为,其中节点被分成两部分:上层节点表示系统的内部状态,通常是隐藏的;下层节点表示系统的外部观测,通常是可以测量到的。常用于时间系统建模的隐马尔科夫模型(Hidden Markov Model,HMM)和卡尔曼滤波模型(Kalman Filter Model,KFM)都可以看作是动态贝叶斯网络的特例。HMM 表示为具有离散状态节点的 DBN,而 KFM 表示为具有连续状态节点和观测节点的DBN。
图2(a)中FHHMM对传统的HHMM进行了扩展,把最下面的状态节点分解成了一系列因子,表示为:
(10)
(11)
(12)
(13)
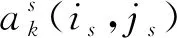
CHHMM的多模式融合更加复杂,其底层的节点关系为:
(14)
(15)
(16)
(17)
PHHMM的底层概率定义为:
(18)
(19)
(20)
(21)
PHHMM的优势在于允许多状态异步性的存在,底层节点能够由多模式任意组合。
1.2 学习和推理
在标记好的样本中估计模型的参数叫做学习,在已有观测序列的基础上,求取概率最大情况下的状态序列被称为推理[12],先研究推理的问题,首先需要把多层次的贝叶斯动态网络转化成马尔科夫模型,采用Viterbi方法求取结果[13]。当然,也可以基于贝叶斯Junction Tree方法来推理。使用Viterbi算法后,转换后的马尔科夫模型为:
(22)
(23)
b(Xt|i)=N(Xt,μiD,σiD)
(24)
马尔科夫模型的状态总数为N=i1,i2,…,iD。
基于结构已知的模型,采用EM算法来训练模型[14]。EM算法的一般分为估计步骤和修改步骤。计算中EM算法容易出现局部最大值的问题,因此,将K均值与Viterbi算法相结合提出了一种效果很好的初始化算法:首先,采用K均值对所有模式的观测特征聚类,作为每个模式各自的初始划元,接着对各节点的概率进行估计,然后,依据估计的参数,运用Viterbi算法划分最优状态,接着参考新的划分,来确定新的估计参数,将上述操作重复,当节点概率不再变大就可以停止。
2 实验检测与结果
为了验证DBN模型的实用性,以足球视频为例,采用上述模型对体育视频中的中断事件和进行事件进行分析。首先对视频提取特征数据,提取的帧图像特征包括:场地面积、图像中运动员占据的面积大小,禁区和中场4种描述符,通过这些特征对足球视频中的基本场景进行区分。场地面积通过场地颜色范围内的像素数目与图像总像素数目做比值可以得到,主色提取算法过程如下:
(1) 将从视频中间部分随机选取的K帧图像放入缓存队列。
(2) 将缓存图像的颜色空间由RGB空间转换到HSV空间,然后选取H分量计算它们的直方图h(i)。设i为像素最多的H色度,初始的主色范围为[i-r,i+r],其中r为主色半径。
(3) 在初始的主色区间上,首先计算主色区间均值m,然后重新设定主色区间为[m-r,m+r],重复上述过程直到主色区间不再变化,或迭代次数超过阈值为止。
考虑到比赛是动态过程,主色会根据时间发生变化,因此在记录中把处于主色范围的像素数目超过一半的帧加入缓存队列,同时抛弃较早的一帧,当更新的帧数超过K/2,则重复以上步骤重新计算主色空间。
运用主色提取算法,首先基于主色来区分颜色特征,用主色表示场地的出现,将主色二值化便得到了图3(b)的二值图。

(a) 原始图像

(b) 二值图像
本次实验为了达成两个目的:① 检测能否实现多模式的融合;② 通过与传统HHMM模型比较,看本文模型的性能如何。为了实现第1个目的,先实现了传统的HHMM的系统,并以此作为基准,在操作时,用来训练的对象只有颜色这一项,接着用来训练的只有运动这一项。针对第2个目的,先实现了特征融合的系统,并以此作为参考,与上述系统不同的是,将运动特征和颜色特征结合在一起作为观测输入的对象。与基于传统模型不同的是,本文的3种模型对各模式各自组建了观测概率与基元。而模型性能会受不同的基元所对应的状态数的影响,因此最终结果取的是各模型的最好结果。
采用20几~10几min的视频作为本次实验的测试数据集,选择的格式是MPEG-1,尺寸为352×288,帧率为25帧/s,每隔0.5 s提取1次运动特征和颜色。然后先对模型训练,接着再评价,主要选用交叉交验的方法。每次实验选择90%的数据来训练,其余的用来测试。上述操作重复次数为10次以上,当全部的数据都经过了实验方可停止。
为了对分析结果有一个整体的衡量,运用常用的查全率R、查准率A以及它们的调和平均值F-value来评价。
查全率
查准率
调和平均值
F-value=2RP/(R+A)
基于帧和基于片段来评价不同模型分析得到的结果分别见表1、2。

表1 基于帧的实验结果 %
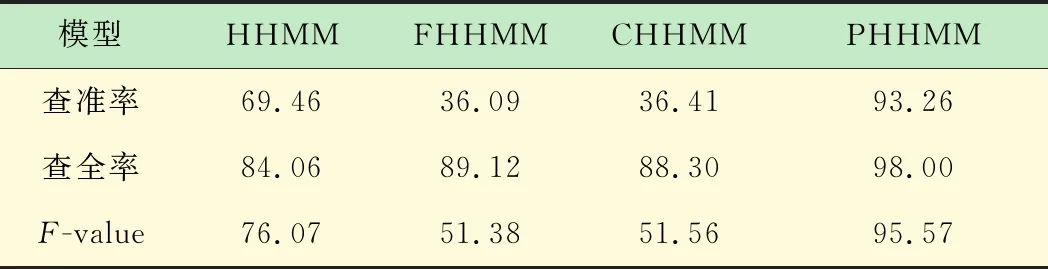
表2 基于片段的实验结果 %
由表1可知,准确率最高的是PHHMM;相对比之下,FHHMM、CHHMM以及PHHMM模型的准确率比使用特征融合的HHMM模型效果好。由表2可见,HHMM、FHHMM以及CHHMM 3种模型的查准率均在70%以下甚至更低,即都表现出了较低的查准率和较高的查全率,这是因为这3种模式的结果出现了过度分割。根据本文的评价算法,只有第1个事件被认为是准确的,因此查准率比较小,而过度分割是由模型在全局间关系约束不强、过度关注局部的变化造成的。不同的是,刚开始的实验中PHHMM的效果不错,没有发生这种状况[16]。综合上述,PHHMM不但能够满足上下文的多层约束关系,而且可以有效利用各模式间动态交互。是一种应用性很好的模型。
3 结 语
多媒体视频中的语义事件的本质是一个多模式的表达,融合视频中运动信息、音频信息和文本信息有助于实现准确的分析,在前人基础上,基于贝叶斯动态网络提出了多模式的多媒体视频分析,实现了将多模式信息和事件上下文约束关系的融合处理分析。在贝叶斯动态网络理论的基础上,首先用拓扑结构表示事件的上下文关系;接着,建立了多种模式之间的连接关系,以此为基础,成功提出了PHHMM模型,以足球视频为例,并通过对其比赛视频中的进行/中断事件的实验测试及与传统HHMM方法的对比,证明了本文提出的模型在多模式的信息与多层次间的约束关系之间做了很好的平衡,性能得到很大的提高。
猜你喜欢
机械工业标准化与质量(2022年6期)2022-08-12
九江学院学报(自然科学版)(2022年2期)2022-07-02
有色金属(矿山部分)(2021年4期)2021-08-30
法律方法(2021年4期)2021-03-16
装备制造技术(2020年2期)2020-12-14
资源导刊(信息化测绘)(2020年5期)2020-06-22
河南科技学院学报(自然科学版)(2020年2期)2020-05-22
铁道通信信号(2016年6期)2016-06-01
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
中国卫生(2015年12期)2015-11-10
