
生成对抗网络GAN 综述*
2020-01-11 06:26梁俊杰韦舰晶蒋正锋
计算机与生活 2020年1期
梁俊杰,韦舰晶+,蒋正锋
1.湖北大学 计算机与信息工程学院,武汉430062
2.广西民族师范学院 数学与计算机科学学院,广西 崇左532200
1 引言
近年来,随着计算能力的提高,数据量的积累以及对动物神经网络的研究及成果[1],使得人工智能领域发展迅速,尤其在机器学习方面最为突出。依据数据集是否有标记,机器学习任务被分为有监督学习、无监督学习和半监督学习。目前机器学习方法,特别是深度学习方法在有监督学习任务中取得令人振奋的成绩,如图像识别[2-3]、语音合成[4-5]、机器翻译[6-7]等。
有监督学习依赖带标记的数据,然而大量带标记数据的获取代价昂贵,在数据生成、策略学习等学习任务中,这些标记数据的获取甚至不可行。无监督学习更符合智能的思想,研究者们普遍认为,无监督学习将会是人工智能未来重要的发展方向之一。
生成模型是无监督学习任务中的关键技术,早期的生成模型有深度信念网络(deep belief network,DBN)[8]、深度玻尔兹曼机(deep Boltzmann machines,DBM)[9]等网络结构,它们将受限玻尔兹曼机(restricted Boltzmann machine,RBM)[10]、自编码器(autoencoder,AE)[11]等生成模型融合其中,形成了效果不错的生成式模型,但泛化能力却不强。
生成对抗网络(generative adversarial networks,GAN)是Goodfellow 等人[12]在2014 年提出的一种新的生成式模型。GAN 独特的对抗性思想使得它在众多生成器模型中脱颖而出,被广泛应用于计算机视觉(CV)、机器学习(ML)、语音处理(AS)等领域。在arXiv 上以generative adversarial networks、generative adversarial nets 和adversarial learning 为关键词的论文发文量总体呈逐年上升趋势(如图1),并且GAN被应用的学科领域很广,如图2 显示的是arXiv 上GAN 论文所属学科领域。这些数据说明了对GAN这一模型研究的火热程度,也说明了该方法在人工智能等领域的重要性。

Fig.1 Trend of the number of GAN papers published on arXiv图1 arXiv 上GAN 论文数量的变化趋势

Fig.2 Top 10 subject categories of GAN papers published on arXiv图2 arXiv 上GAN 论文所属的TOP 10 学科领域
2 原始生成对抗网络
2.1 GAN 网络结构
GAN 的网络结构由生成网络和判别网络组成,模型结构如图3 所示。生成器G接收随机变量z,生成假样本数据G(z)。生成器的目的是尽量使得生成的样本和真实样本一样。判别器D的输入由两部分组成,分别是真实数据x和生成器生成的数据G(x),其输出通常是一个概率值,表示D认定输入是真实分布的概率,若输入来自真实数据,则输出1,否则输出0。同时判别器的输出会反馈给G,用于指导G的训练。理想情况下D无法判别输入数据是来自真实数据x还是生成数据G(z),即D每次的输出概率值都为1/2(相当于随机猜),此时模型达到最优。在实际应用中,生成网络和判别网络通常用深层神经网络来实现。
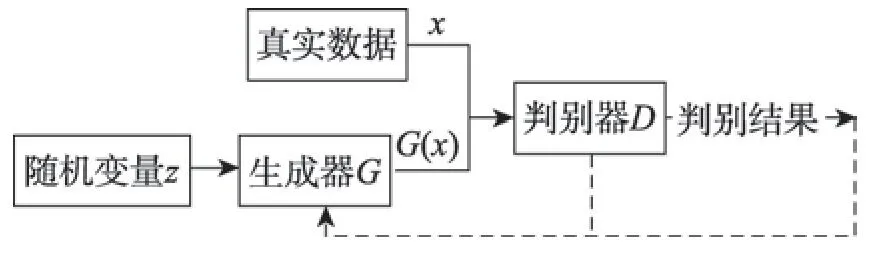
Fig.3 GAN network model structure diagram图3 GAN 网络模型结构示意图
GAN 的思想来自于博弈论中的二人零和博弈[13],生成器和判别器可以看成是博弈中的两个玩家。在模型训练的过程中生成器和判别器会各自更新自身的参数使得损失最小,通过不断迭代优化,最终达到一个纳什均衡状态,此时模型达到最优。GAN 的目标函数定义为:

2.2 生成网络
生成器本质上是一个可微分函数,生成器接收随机变量z的输入,经G生成假样本G(z)。在GAN中,生成器对输入变量z基本没有限制,z通常是一个100 维的随机编码向量,z可以是随机噪声或者符合某种分布的变量。生成器理论上可以逐渐学习任何概率分布,经训练后的生成网络可以生成逼真图像,但又不是和真实图像完全一样,即生成网络实际上是学习了训练数据的一个近似分布,这在数据增强应用方面尤为重要。
2.3 判别网络
判别器同生成器一样,其本质上也是可微分函数,在GAN 中,判别器的主要目的是判断输入是否为真实样本,并提供反馈以指导生成器训练。判别器和生成器组成零和游戏的两个玩家,为取得游戏的胜利,判别器和生成器通过训练不断提高自己的判别能力和生成能力,游戏最终会达到一个纳什均衡状态,此时生成器学习到了与真实样本近似的概率分布,判别器已经不能正确判断输入的数据是来自真实样本还是来自生成器生成的假样本G(x),即判别器每次输出的概率值都是1/2。
3 原始GAN 模型存在的问题分析
原始的GAN 并不成熟,存在着诸多问题,其中梯度消失和模式崩溃(collapse mode)问题严重限制GAN 的发展。只有了解问题发生的本质,才能做出相应的改进,本章主要对GAN 在训练中存在梯度消失和模式崩溃的原因进行分析。
3.1 梯度消失问题分析
梯度消失即是利用误差反向传播(back propagation,BP)算法[14]对深度神经网络进行训练时,梯度后向传播到浅层网络时基本不能引起数值的扰动,最终导致神经网络收敛很慢甚至不能收敛。GAN 存在梯度消失的问题,并且在判别器训练得越好的时候,生成器梯度消失得越严重[15]。最优判别器如式(2):

在最极端的情况下,当判别器达到最优时,此时生成器模型如式(3):
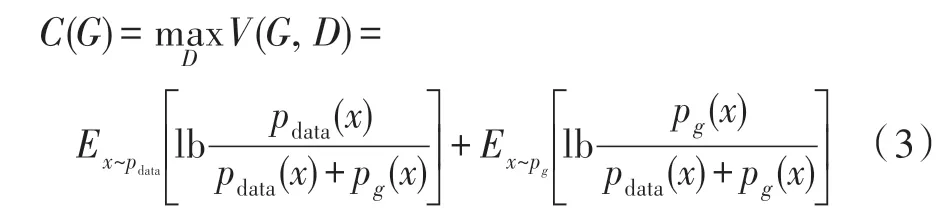
原始GAN 模型使用KL 散度(Kullback-Leibler divergence)[16]和JS 散度(Jensen-Shannon)17]衡量两个分布之间的差异,即是:

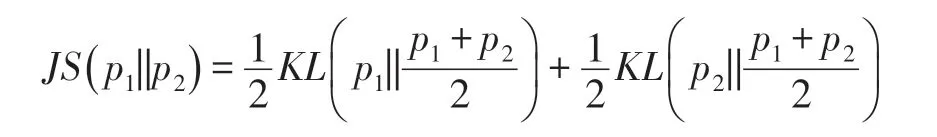
训练GAN 网络需要极小化C(G),即是要求min(JS(pdata||pg)),JS 散度的值越小表示两个分布之间越接近,这符合生成器的优化目标,即是要生成以假乱真的样本(两个样本之间的概率分布很接近)。当两个分布有重叠的时候,优化JS 散度是可行的,而在两个分布完全没有重叠部分,或者重叠的部分可以忽略时,JS 散度是一个常数,此时梯度为0,即生成器在训练的过程中得不到任何的梯度信息,出现梯度消失的现象。下面从两个分布是否有重叠部分分析梯度消失的原因。
对于两个分布pdata(x)和pg(x),不难得出如下四种情况,如图4 所示。
情况1pdata(x)=0 且pg(x)=0
情况2pdata(x)≠0 且pg(x)≠0
情况3pdata(x)=0 且pg(x)≠0
情况4pdata(x)≠0 且pg(x)=0
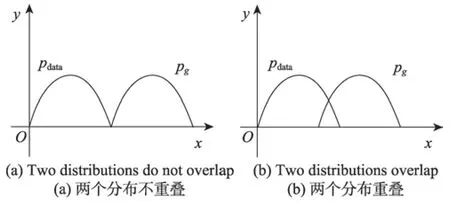
Fig.4 Sample probability distribution图4 样本分布图
(1)两个分布没有重叠部分。对于情况1,由于pdata和pg的取值都在函数的支撑集(support)之外,因此情况1 对JS 散度无贡献。情况2 由于两个分布的支撑集没有交集,因此对最后的JS 散度也无贡献。对于情况3,将pdata(x)=0 且pg(x)≠0 带入式(4),得到式(5)。
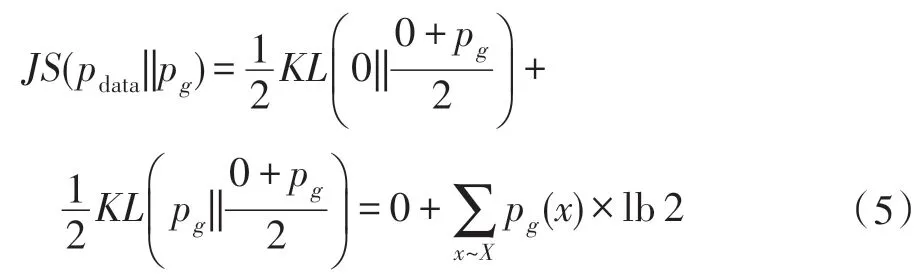
(2)两个分布有重叠部分。文献[18]指出,两个分布在高维空间是很难相交的,即使相交,其相交部分其实是高维空间中的一个低维流形,其测度为0,这说明两个分布相交部分可以忽略不计,此时JS 散度的值和(1)讨论的一致,换言之,pdata和pg两个分布只要它们没有重叠部分或者重叠部分可以忽略,那么JS 散度就固定是常数lb 2,这对于梯度下降法而言意味着梯度为0。文献[19]证明了若存在一个判别器D无限接近于最优解时,即||D-D∗||<ε,有如下关系:
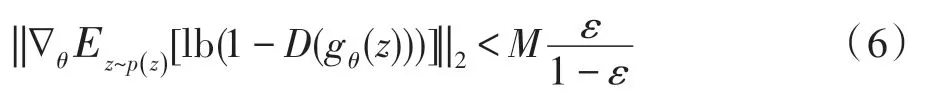

3.2 模式崩溃问题分析
GAN 模式崩溃(mode collapse)是指GAN 生成不了多样性的样本,而是生成了与真实样本相同的样本,该缺陷在数据增强领域中是致命的。为解决GAN 梯度消失问题,Goodfellow 等人重新定义了损失函数,如式(8)。
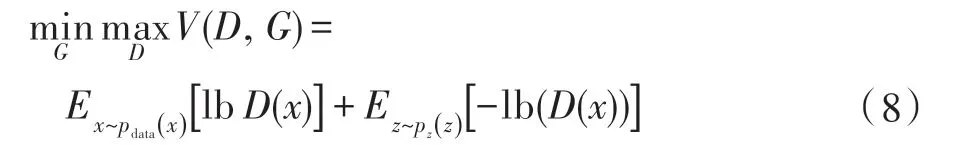
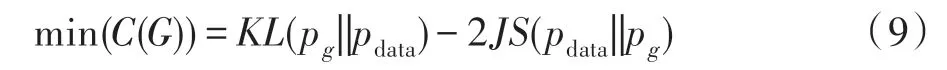
要优化该目标函数,则要求同时满足式(10)、式(11)。

式(10)要求pg和pdata的概率分布一样,而式(11)则要求pg和pdata的概率分布不一样,这样会产生矛盾,使得生成器无法稳定训练。放宽约束,只要求满足式(10)同样不可行。如下:
(1)当pg(x)→0 且pdata(x)→1 时,0,此时的KL(pg||pdata)趋近于0。该情况说明了生成器生成了与真实样本相似的样本。
(2)当pg(x)→1 且pdata(x)→0 时,∞,此时的KL(pg||pdata)趋近于正无穷。该情况说明生成器生成了不真实的样本。
情况(1)生成的样本缺乏多样性,惩罚较小,生成器宁可生成一些重复但很安全的样本,也不愿意生成多样性的样本,该现象就是模式崩溃。情况(2)是生成器生成了不真实的样本,样本缺乏准确性,惩罚较大。
4 改进GAN 模型
研究者们针对GAN 存在训练困难等问题,通过不断探索,最终提出了很多基于GAN 的变体。本章主要对一些典型的GAN 变体进行讨论。
4.1 CGAN
原始GAN 对于生成器几乎没有任何约束,使得生成过程过于自由,这在较大图片的情形中模型变得难以控制。CGAN(conditional GAN)[20]在原始GAN 的基础上增加了约束条件,控制了GAN 过于自由的问题,使网络朝着既定的方向生成样本。CGAN的网络结构如图5 所示,CGAN 生成器和判别器的输入多了一个约束项y,约束项y可以是一个图像的类别标签,也可以是图像的部分属性数据。CGAN 的目标函数变成如下式(12)。
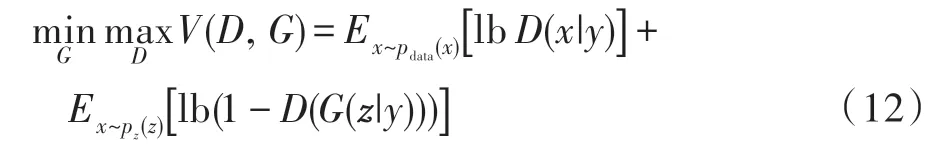

Fig.5 CGAN model architecture diagram图5 CGAN 模型架构图
CGAN 的缺点在于其模型训练不稳定,从损失函数可以看到,CGAN 只是为了生成指定的图像而增加了额外约束,并没有解决训练不稳定的问题。
4.2 LAPGAN
LAPGAN[21]基于CGAN 进行改进,它能够生成高品质的图片,如图6 是LAPGAN 模型的学习过程。LAPGAN 的创新点是将图像处理领域中的高斯金字塔[22]和拉普拉斯金字塔[23]的概念引入GAN 中,高斯金字塔用于对图像进行下采样,拉普拉斯金字塔用于上采样以此重建图像。高斯金字塔被定义为,其中I0=I是原始图像,Ik+1是Ik下采样的图像,K是尺度变换的层数,拉普拉斯金字塔由式(13)表示。

Fig.6 Learning process of LAPGAN model图6 LAPGAN 模型学习过程

其中,u(∙)表示上采样,该式表达了原始图像与经过变换之后图像的残差,即是hk=Ik-u(d(Ik)),其中d(∙)表示下采样。LAPGAN 实际是学习样本和生成样本之间的残差,如式(14)。

4.3 DCGAN
DCGAN(deep convolutional GAN)[24]的提出对GAN 的发展有着极大的推动作用,它将卷积神经网络(convolutional neural networks,CNN)和GAN 结合起来,使得生成的图片质量和多样性得到了保证。其网络模型结构如图7 所示。DCGAN 使用了一系列的训练技巧,如使用批量归一化(batch normalization,BN)稳定训练,使用ReLU 激活函数降低梯度消失风险,同时取消了池化层,使用步幅卷积和微步幅卷积有效地保留了特征信息。DCGAN 虽然能生成多样性丰富的样本,但是生成的图像质量并不高,而且也没有解决训练不稳定的问题,在训练的时候仍需要小心地平衡G和D的训练进程。
4.4 CylcleGAN
传统的不同两个域中的图片要实现相互转化,一般需要两个域中具有相同内容的成对图片作为训练数据。比如pix2pix[25],但是这种成对的训练数据往往很难获得。CylcleGAN[26]可以让两个域的图片互相转化并且不需要成对的图片作为训练数据。CylcleGAN 是一个互相生成的网络,其网络是个环形结构,如图8 所示。
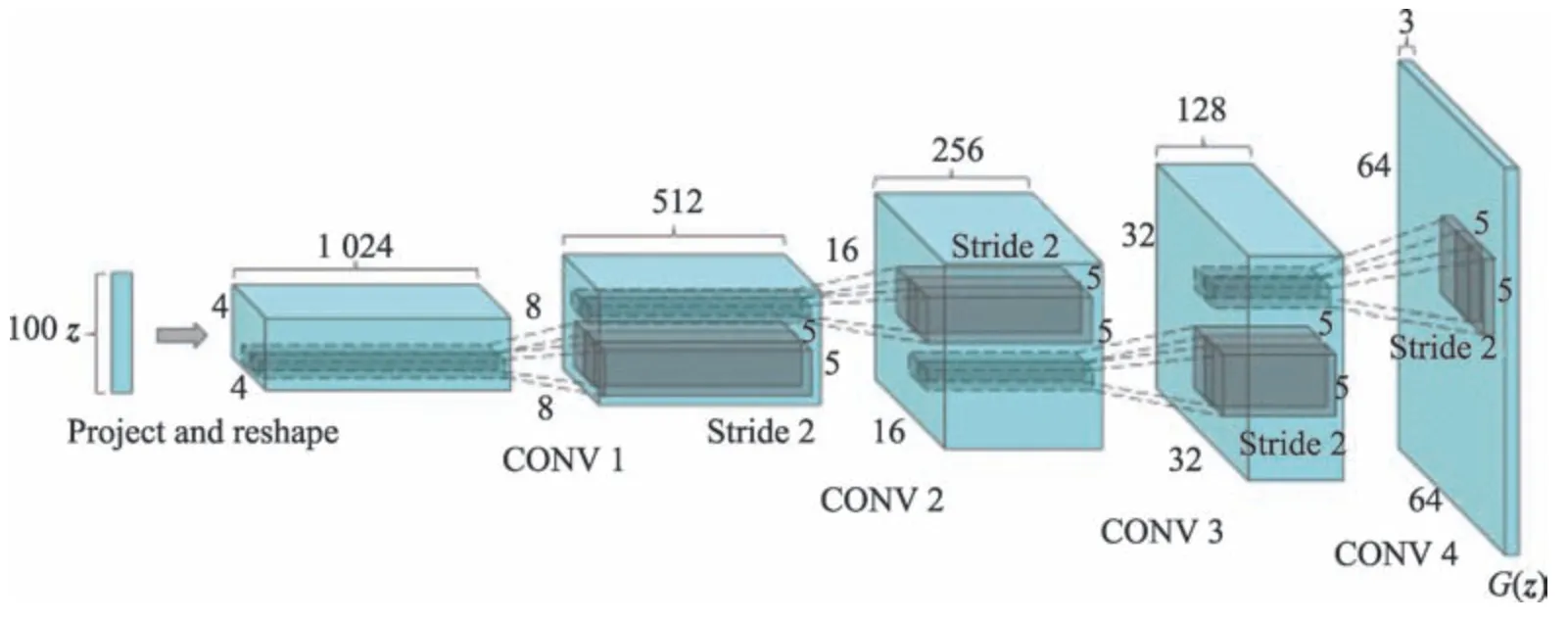
Fig.7 DCGAN model architecture diagram图7 DCGAN 生成模型架构图

Fig.8 CylcleGAN structure diagram图8 CylcleGAN 结构图
x表示X域的图像,y表示Y域的图像,G和F是两个转换器,DX和DY是两个判别器。如图8(a),X域的图像x经转换器G转换成Y域的图片G(x),并由判别器DY判别它是否是真实图片。同理,Y域的图像y经转换器F转换成X域的图片F(y),再由判别器DX判别它是否是真实图片。为了避免转换器将域内的所有图片都转换成另一个域内的同一张图片,CylcleGAN使用循环一致性损失(cycle consistency loss)做约束。最终的损失函数由三部分组成,如式(15)。
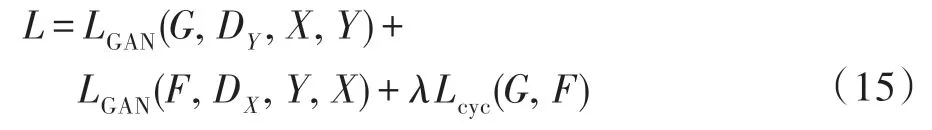
CylcleGAN 的缺点是其循环机制能保证成像不会偏离太远,但是循环转换中会造成一定的信息丢失,使得生成图像质量不高。
4.5 StackGAN
根据文字描述人工生成对应高质量图片一直是计算机视觉领域的一个挑战,StackGAN[27]是第一个根据文字描述生成图像分辨率达到256×256 的网络模型。其网络模型结构图如图9 所示。
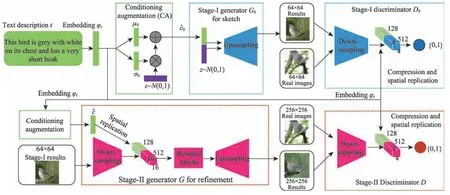
Fig.9 StackGAN network model structure图9 StackGAN 网络模型结构图
StackGAN 的训练分为两个阶段,它们分别被定义为Stage-Ⅰ和Stage-Ⅱ。Stage-Ⅰ阶段是根据给定的文字描述,学习到初始的形状和色彩,生成低分辨率(64×64)的图片;Stage-Ⅱ阶段根据Stage-Ⅰ生成的低分辨率图像以及原始文字描述,生成具有更多细节的高分辨率(256×256)图片。在Stage-Ⅰ阶段中,词嵌入向量φt经过全连接层生成高斯分布N(μ0(φt),σ0(φt))中的μ0和σ0,最后与z噪声向量拼接作为G0的输入,通过一组上采样生成64×64 的图像。Stage-Ⅱ阶段以高斯隐含变量以及Stage-I 生成器的输出作为输入,来训练生成器和判别器。但是这种分段式模式可能会出现每个任务找不到重点,最终导致生成失败。
StackGAN 及其改进版StackGAN++[28]都是用于文本生成图像的网络,目前在该领域比较新的突破性工作是由斯坦福大学李飞飞教授小组发表的文献[29],该研究引入了场景图的概念,相比于StackGAN 和StackGAN++方法,它能够处理更加复杂的文本,并且取得了不错的效果。
4.6 InfoGAN
GAN 强大的学习能力最终可以学习到真实样本的分布,但对输入噪声信号z和数据的语义特征之间的对应关系不清楚。一个理想的情况是清楚它们之间的对应关系,这样就能通过控制对应的维度变量来达到相应的变化。比如对于MNIST 手写数字识别项目,在知道其对应关系的情况下,可以控制输出图像的光照、笔画粗细、字体倾斜度等。InfoGAN[30]解决了这个问题,它将输入噪声z分成两部分,一部分是噪声信号z,另一部分是可解释的有隐含意义的信号c。InfoGAN 模型结构图如图10 所示。
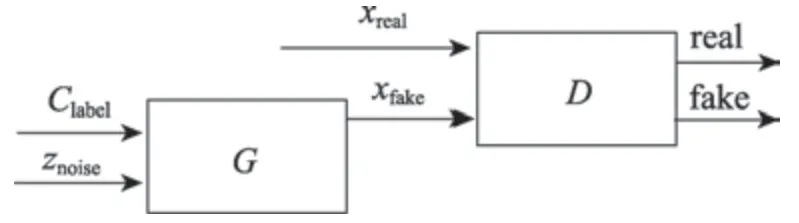
Fig.10 InfoGAN model structure图10 InfoGAN 模型结构
生成器的输入多了一个隐含变量C(c1,c2,…,cL),它代表的是如上面提到的图像的光照、笔画粗细、字体倾斜度等图像的语义特征信息。InfoGAN 对目标函数进行了约束,即c和G(z,c) 之间的互信息I(c;G(z,c)),如式(16)。

实验证明了InfoGAN 确实学到了一些可解释的语义特征,通过控制这些特征可以生成想要的数据。如图11,通过控制角度、宽度,生成形状不一样的数据。

Fig.11 Feature learning of angle or width of image图11 图像的角度或宽度的特征学习
4.7 WGAN
原始GAN 训练出现梯度消失和模式崩溃的主要原因是使用JS 距离来衡量两个分布,WGAN(Wasserstein GAN)[31]使用Wasserstein 距离(又称EM(Earth-mover)距离)代替JS 距离对真实样本和生成样本之间的距离进行度量。
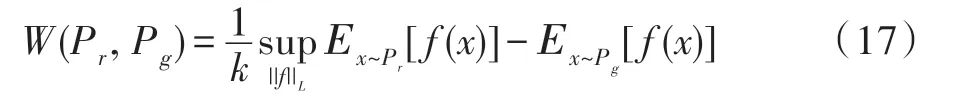
Wasserstein 距离在两个分布没有重叠或者重叠部分可以忽略的情况下仍然能够很好地度量它们之间的距离,同时Wasserstein 距离是平滑的,这在理论上能解决梯度消失/爆炸的问题。但在实验过程中发现,WGAN 往往存在梯度消失/爆炸的情况,其主要原因是为了满足Lipschitz 限制条件,直接用weight clipping 方式将参数clip 到[-c,c]范围内,在最优策略下,参数往往会走极端,即参数要么取最大值(如0.01),要么取最小值(如-0.01),这意味着拟合能力差,同时参数c很难确定,稍有不慎就会引起梯度消失/爆炸,如图12 所示。
4.8 WGAN-GP
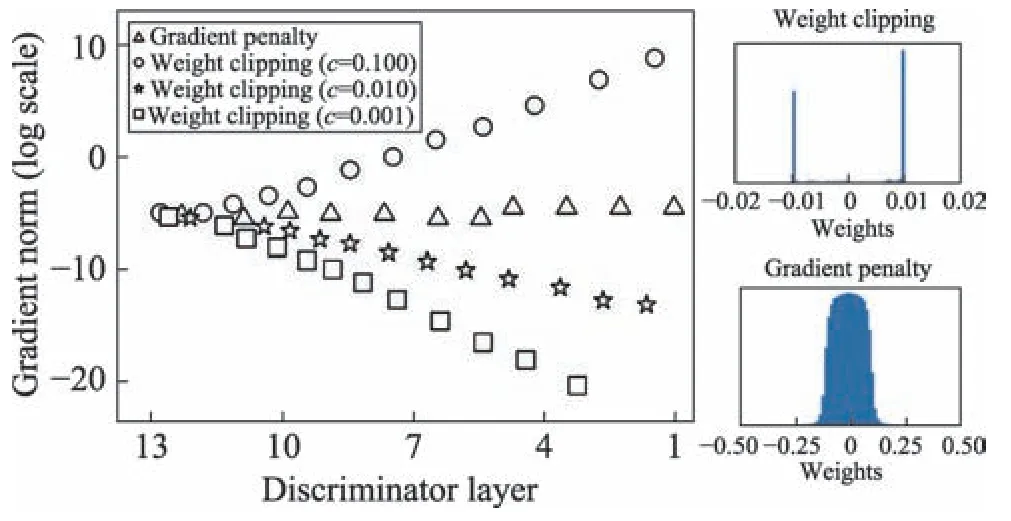
Fig.12 WGAN gradient disappearance/explosion analysis图12 WGAN 梯度消失/爆炸分析
WGAN-GP[32]是针对WGAN 为满足Lipschitz 连续性条件强行将权重剪切到一定范围,如[-0.01,0.01]之后造成网络拟合能力差、容易发生梯度消失/爆炸等问题而进行改进的一种GAN 模型。作者抛弃了WGAN 中的weight clipping,使用一种称作梯度惩罚(gradient penalty)的方式来满足Lipschitz 连续性条件。具体而言,它增加了一个额外的loss 函数来实现判别器梯度与K之间的联系(Lipschitz 限制是要求判别器梯度不超过K),如下:

这里K=1。
WGAN-GP 解决了梯度消失/爆炸的问题,同时能生成更高质量的样本。但在实验中发现该方法收敛速度慢,在同一数据集下,WGAN-GP 需要训练更多次数才能收敛。
4.9 EBGAN
EBGAN(energy-based GAN)[33]从能量的角度诠释GAN,它将判别器D视为一个能量函数,该能量函数将靠近真实样本域附近视为低能量区域,远离真实样本区域则视作高能量区域。因此EBGAN 在训练中,生成器会尽可能生成能量最小的样本,而判别器则会对这些生成的样本赋予高能量,其模型结构如图13 所示。

Fig.13 EBGAN model structure图13 EBGAN 模型结构
EBGAN 将判别器设计成能量函数,这种改进的优点是可以用更多、更广泛的损失函数来训练GAN结构,但EBGAN 同样存在缺点,在实验中发现其收敛速度很慢,其他模型都已经能够生成大致表达图像的轮廓,它生成的图像依然杂乱无章。
4.10 BEGAN
传统的GAN 是优化生成数据分布与真实数据分布之间的距离,认为两者的分布越相似,G的生成能力越好,很多GAN 的改进也是基于该思路。BEGAN(boundary equilibrium GAN)[34]并没有直接去估计生成分布pg和真实分布px的距离,而是估计两者分布误差的距离。作者认为,分布之间的误差分布相近的话,也可以认为pg和px是相近的。BEGAN 将判别器G设计成自编码器用来重构分布误差,并优化分布误差之间的距离,如下式:
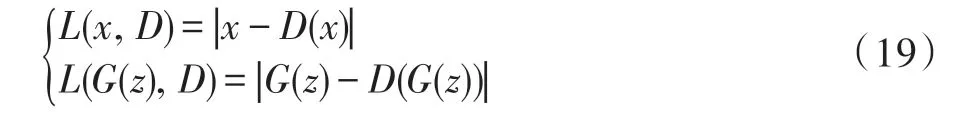
BEGAN 提出一种均衡概念,用以平衡G和D的训练,使GAN 即使使用很简单的网络,不加如BN、minibath 等训练技巧也能得到很好的训练效果。同时还提出了一种能够在样本多样性和样本质量上均衡的超参数以及衡量模型收敛性的方法。实验中发现BEGAN 收敛很快,并且G和D训练平衡,但超参数的选取比较考量经验。
4.11 LSGAN
LSGAN(least squares GAN)[35],又叫最小二乘生成对抗网络,具体工作是将传统GAN 的交叉熵损失函数换成最小二乘损失函数,该做法有效改善了传统GAN 生成图片质量不高,训练不稳定的问题。最小二乘损失与交叉熵损失相比,优势在于生成样本在欺骗判别器的前提下同时让生成器把距离决策边界比较远的生成图片拉向决策边界,这样保证了生成高质量的样本。作者认为以交叉熵作为损失,会使得生成器不会再优化那些被判别器识别为真实图片的生成图片,即使这些生成图片距离判别器的决策边界仍然很远,也就是距离真实数据比较远,因为此时的交叉熵损失已经很小,生成器完成了为它设计的目标。LSGAN 的缺陷在于它并没有解决当判别器足够优秀时生成器发生梯度弥散的问题,因为按照WGAN 的理论(式(17)),最小二乘函数并不满足Lipschitz连续性条件,它的导数没有上界。
4.12 BigGAN
BigGAN[36]是目前为止生成图像质量最好的GAN 模型,它在ImageNet(128×128 分辨率)训练下,IS(inception score)高达166.3,比之前最好的52.52(SAGAN(self-attention generative adversarial networks)[37])提升2 倍多,同时FID(frechet inception distance)下降至9.6。BigGAN 通过将模型扩大得到性能的提升,它在训练中使用了很大的Batch(2 048),并且在卷积层的设计上使用了更大的通道数(channel)。同时文章还使用截断技巧(truncation trick),使模型性能得到提升,并且训练变得更加平稳。为了在样本多样性和保真度上进行平衡,将正交正则化应用到生成器上,同时对判别器的梯度做适当惩罚。BigGAN的缺点也很明显,BigGAN模型很大,参数多,训练成本高。
表1 是典型GAN 模型的对比。
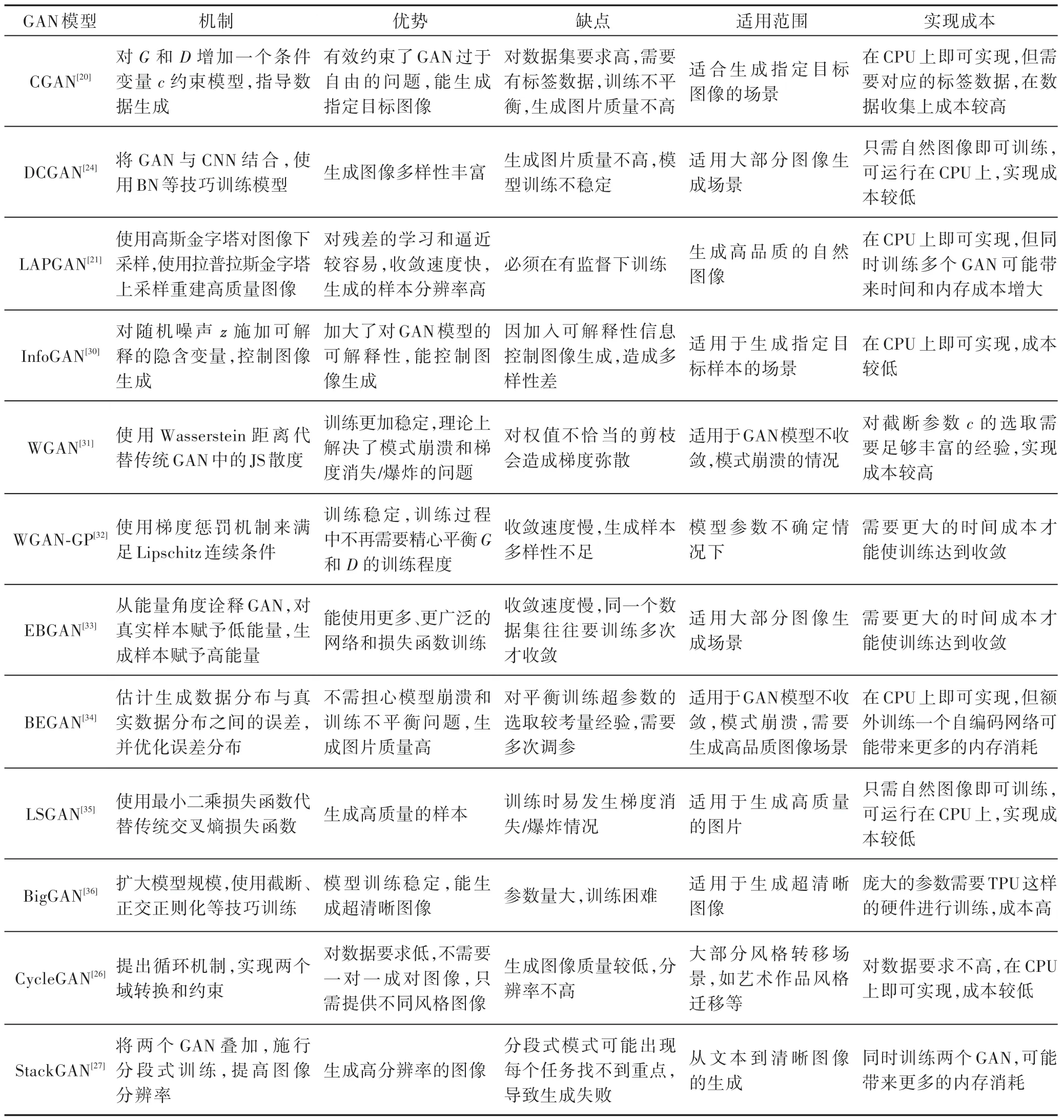
Table 1 Comparisons of typical GAN models表1 典型GAN 模型对比
针对表1 的总结,在MNIST 数据集上进行实验以验证其准确性。图14 是各个GAN 训练过程中生成器和判别器损失函数变化(实验代码参考网络https://github.com/znxlwm/pytorch-generative-modelcollections),可以看出:原始GAN 训练不平衡,而CGAN 仅在损失函数上加上一个约束项,没有针对GAN 训练不稳定的根本原因进行改进,即没有真正解决模型训练不稳定问题;BEGAN 是在Wasserstein距离上得到启发,本质上还是满足Lipschitz 连续性条件,因此其训练平衡、稳定且收敛速度极快;EBGAN从能量角度对GAN 进行改进,有效解决了训练不平衡问题,但是收敛速度慢,迭代40 000 次后生成器依然没有收敛;LSGAN 使用最小二乘损失函数代替原始的交叉熵损失函数,但其不满足Lipschitz 连续性条件,可以看到训练中存在梯度消失/爆炸的情况;WGAN对截断参数c选择不合理会造成训练不稳定的情况,这对经验有较高的要求;WGAN-GP 使用梯度惩罚(gradient penalty)技巧满足了Lipschitz 连续性条件,解决了WGAN 训练不平衡的问题,但是收敛速度慢;InfoGAN 增强了对GAN 的解释性,使得训练平衡,同时收敛速度快。DCGAN 能生成多样性丰富的样本,但分辨率较低,并且DCGAN 只是在网络结构和训练技巧上进行了改进,并没有真正解决模型训练不稳定的问题;LAPGAN 的生成器在每一阶段都能学习到不同的分布,并作为下一层的补充信息,这有助于生成高分辨率的图像;BigGAN 是一个规模很大的GAN,使用截断、正交正则化等技巧训练生成高分辨率的图像,同时缺陷也很明显,其参数量庞大,需要在TPU(tensor processing unit)或多个GPU(graphics processing unit)下训练,成本高;CycleGAN 使用循环机制有效充分运用了两个域的信息,同时其对训练数据要求不高,只需提供不同风格数据图像就可以实现风格转换,实现成本低,但循环转换会造成一定的信息丢失,使得生成样本质量较低;StackGAN 应用在文本到图像生成的领域,它能生成高分辨率的图像,但是其分段式模式也往往造成各个分任务找不到重点,导致生成失败。

Fig.14 Change process of loss when GAN model is trained on MNIST dataset图14 GAN 模型在MNIST 数据集上训练时loss的变化过程
5 GAN 与VAE、RBM 比较
变分自编码器(variational autoencoder,VAE)和受限玻尔兹曼机(RBM)是除GAN 之外的两个优秀的生成式模型,在MNSIT 数据集上对比了GAN 与VAE、RBM 的性能,最后总结GAN 对比于这两大生成式模型存在的优势与劣势。
从图15 可以看到VAE 和RBM 生成的图像相对于GAN 而言较模糊,这说明了GAN 能生成更加清晰的图像。图16 中图(a)、(b)分别为GAN 生成器和判别器的损失,图(c)、(d)分别为KL 散度变化以及VAE 损失变化的过程,可以看到GAN 是比较难训练的。总体而言,GAN 的优势在于:
(1)从实际结果看,GAN能产生更好的生成样本。
(2)GAN 框架可以训练任何生成网络,在模型设计上不需要遵循任何种类的因子分解,所有的生成器和鉴别器都可以正常工作。
(3)相比RBM,GAN 没有变分下界,也没有棘手的配分函数,样本是一次生成的,并没有重复地应用Markov Chain 来生成。

Fig.15 3 generation models generate results on MNIST图15 3 种生成模型在MNIST 上生成结果
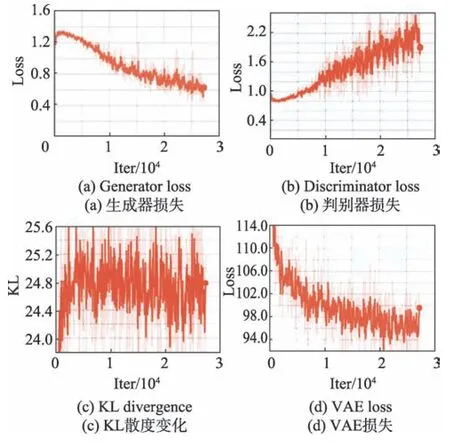
Fig.16 GAN and VAE training parameters change process图16 GAN 和VAE 训练参数变化过程
(4)相比于VAE,GAN 没有引入任何决定性偏置(deterministic bias),VAE 由于优化的是对数似然的下界,而不是对数似然本身,因此引入了决定性偏置,这也导致了其生成的实例比GAN 更模糊。
GAN 的劣势体现在:
(1)训练GAN 需要达到纳什均衡,目前没有找到很好的达到纳什均衡的方法,甚至是否存在纳什均衡仍然没有很好的理论证明,因此GAN 相对于VAE而言其训练是不稳定的。
(2)GAN 对离散数据的生成效率很低,如文本数据。
(3)可解释性差,生成模型的分布没有显式的表达;极易受到对抗样本的干扰,导致模型错误的输出。
6 GAN 的典型应用
6.1 生成数据
目前,数据缺乏仍是限制深度学习发展的重要因素之一,而GAN 能够从大量的无标签数据中无监督地学习到一个具备生成各种形态(图像、语音、语言等)数据能力的函数(生成器)。以生成图像为例,GAN 能够生成百万级分辨率的高清图像[38],如BigGAN、WGAN,WGAN-GP 等优秀的模型。但是GAN 并不是单纯地对真实数据的复现,而是具备一定的数据内插和外插作用,因此可以达到数据增广的目的。比如用GAN 来生成一张红颜色的汽车图像,GAN 生成的汽车图像颜色可能变成了黑色,或者在汽车的轮胎、车窗上和原图像有差别,这样一张图像就可以生成出很多张不同的图像,与经过剪切、旋转生成的图像相比,使用GAN 生成的图像数据更符合模型训练的需要。不同GAN 模型生成图像结果如图17 所示。

Fig.17 Image results generated by different GAN models图17 不同GAN 模型生成图像结果
6.2 图像超分辨率
图像超分辨率一直是计算机视觉领域的一个研究热点,SRGAN(super-resolution generative adversarial network)[39]是GAN 在图像超分辨率应用上的一个成功案例。SRGAN 基于相似性感知方法[40]提出了一种新的损失函数,有效解决了恢复后图像丢失高频细节的问题,并使人能有良好视觉感受。在此之前的其他超分辨率图像处理模型如Residual Network[41]以及在其基础上改进而来的SRResNet[42]都是追求高的PSNR(peak signal-to-noise ratio),但在实验中发现较高的PSNR并不能带来良好的视觉效果[43-44]。SRGAN从特征上定义损失,它将生成样本和真实样本分别输入VGG-19 网络,然后根据得到的特征图的差异来定义损失项,最后将对抗损失、图像平滑项(生成图像的整体方差)和特征图差异这3 个损失项作为模型的损失函数,得到了很好的效果。图18 是应用在图像超分辨率上的网络模型实验的结果,可以看到SRGAN 的PSNR 虽然不是最高,但生成的图像细节、纹理更明显。

Fig.18 Super-resolution image generation图18 超分别率图像生成
6.3 图像翻译和风格转换
图像风格迁移是将一张图片的风格“迁移”到另一张图片上。深度学习最早是使用CNN 框架来实现的[45],但这样的模型存在训练速度慢,对训练样本要求过高等问题。由于GAN 的自主学习和生成随机样本的优势,以及降低了对训练样本的要求,使得GAN在图像风格迁移领域取得了丰硕的研究成果[46-52]。
6.4 其他
GAN 除了应用在数据生成、图像超分辨率、图像翻译和风格迁移等领域外,在其他领域也有着很好的表现,如与人体相关的人体姿态估计[53]、行为轨迹追踪[54]、人体合成[55];与人脸相关的人脸检测、人脸合成[56]、人脸表情识别[57]、预测年龄[58]等。此外GAN 还在图像分割[59]、图像复原[60]、图像补全[61]中表现出色,文献[60]使用生成对抗网络思想的对抗损失提出了一种端到端的模糊图像复原方法;文献[61]提出一种基于生成式对抗网络的图像补全方法,生成器用于对图像缺失区域进行补全,判别器对补全效果判别并指导生成器学习。GAN 对时间序列数据同样表现出强大的学习能力,如音乐生成[62]、视频预测与生成[63-64]。文献[65]使用一种对偶对抗学习机制,经过训练后能够准确预测下一帧或多帧的视频;文献[64]采用将随机噪音向量映射到视频帧的方法来实现未来帧的预测;不仅如此,GAN 在重症监护室的ICU 记录生成[66]、检测恶意代码攻击[67]、医疗影像分割[68]、目标跟踪检测[69-71]、自动驾驶[72]等领域都有令人非常惊艳的表现。
7 面临的挑战和未来的研究方向
7.1 GAN 面临的挑战
(1)性能与成本权衡的问题。SAGAN、BigGAN等都证明了庞大的GAN 模型能得到性能上的提升,如BigGAN 生成了超清晰的图像,但是庞大的模型需要使用TPU 或者多个GPU 训练,成本高。一个可行的方法是保证性能的同时将模型压缩,如使用模型量化[73]等方法,但这仍是一个严峻的挑战。
(2)GAN 在使用类别特定数据集(如人脸、卧室)进行训练时已经能生成逼真、高质量样本,但建模具有多个类别,高度多样化的数据集(如ImageNet)的分布仍然是一项重大的挑战,通常需要根据另一种输入信号来调节生成或为特定任务训练模型,此外GAN 在这种高可变性的数据集中难以生成全局一致的高分辨率样本。
(3)GAN 的全局收敛性未得到真正证明。GAN的训练方式是交替优化生成器和判别器,这和其他神经网络不同。目前比较常用的是基于博弈理论原理进行GAN 的训练,但这一过程是在资源限制的情况下完成的,下一步应该要研究怎样减少这样的资源限制。或者试图分析常规神经网络来解答GAN 收敛性的问题,因为生成器模型和判别器模型的参数均为非凸性损失函数,这与绝大多数神经网络有相似之处。
7.2 GAN 未来的研究方向
虽然目前GAN 的理论结构仍不太成熟,限制了GAN 在相关领域的应用与发展,但GAN 仍然是一种很有发展前景的网络模型,未来GAN 将在以下方面取得进一步的发展:
(1)理论突破。GAN 的理论基础是博弈论中的二人零和博弈,目前还没能在理论上真正证明均衡点的存在性,同时GAN 训练的不稳定性如梯度消失、模式崩溃、过拟合和生成样本自由度较高等模型性能问题仍是当前GAN 所面临的问题。从理论层面上进行突破,找出导致以上问题的根本原因并做出改进是GAN 未来的一个重点研究方向。
(2)算法拓展。GANs 在图像合成、图像超分辨率等连续样本上表现良好,但是在离散样本如文本处理上的表现还低于基于似然的语言模型。对GAN的算法拓展,使GAN 这一个优秀模型的应用范围更加广泛,是迫切需要解决的问题。目前的一个方向是GAN 吸收机器学习中最新的理论与研究成果并与之相结合,如GAN 与强化学习结合。
(3)解决对抗样本带来的困扰。分类器极易受到对抗样本的影响,往往会因为故意添加的一些细微干扰就会导致模型判断错误。比如判别器D判别一个生成样本G(z)为假,却将加了扰动的生成样本G(z)+p判定为真。对抗样本影响GAN 的性能,如何解决这个问题,使得模型的精度和稳定性有所提升,是未来一个充满前景的研究方向。
(4)证明GAN 可以为什么样的分布建模。研究者们发现,GAN 在MNIST 数据集上训练比在Imagenet、CIFAR-10 等数据集上训练更为容易,原因是MNIST 数据集的类别相对较少。这说明GAN 对数据集的规模存在偏好。GAN 可以对一些数据建模但效率很低,或者甚至存在一些GAN 无法学习的分布。如何建立一套理论和标准来判断一个数据集是否适合使用GAN 来训练,将是GAN 领域未来的一个重要的研究方向。
(5)完善评测体系。目前GAN 模型没有一个科学的、统一的评估标准,各项研究工作中无非是提出适用于当前研究成果的判定方法,或是直接由人的肉眼来评判。因此提出一个更精确的评价指标,采用统一的标准,构建标准化、通用化的科学评估体系是亟待解决的问题。
(6)针对GAN 可解释性差进行改进。GAN 一般是输入一个噪声信号z进行训练,但是对输入的噪声信号和数据的语义特征之间的对应关系不清楚,使得很难控制GAN 生成需要的样本,虽然InfoGANs 等模型对此做了相应的一些改进,但这方面仍缺乏系统的研究。解决GAN 解释性差的问题,将会对GAN未来的发展有着重大的意义。
8 结束语
本文对GAN 这一模型在原理、应用、存在挑战和未来研究方向等方面进行了介绍和总结,GAN 模型的提出为人工智能领域注入了新的活力,特别在无监督学习上,GAN 的对抗性思想提供了一种新的算法框架,促进了这一领域的发展。虽然GAN 目前还存在诸多未解决的难题,但对GAN 的继续探索,相信未来一定能突破这些难题,打造出更优秀的模型。
猜你喜欢
九江学院学报(自然科学版)(2022年2期)2022-07-02
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
福建基础教育研究(2019年3期)2019-05-28
西部资源(2018年1期)2018-11-01
领导决策信息(2018年16期)2018-09-27
人大建设(2017年10期)2018-01-23
数学学习与研究(2017年3期)2017-03-09
中学生数理化·八年级数学人教版(2016年4期)2016-08-23
理科考试研究·高中(2016年9期)2016-05-14
新高考·高二数学(2015年7期)2015-10-22
