
基于重采样策略的随机森林算法在乳腺肿瘤分类中的研究
2020-01-10 12:43侯珂珂蔡莉莉
现代计算机 2019年34期
侯珂珂,蔡莉莉
(1.中山大学新华学院健康学院,广州510520;2.中山大学新华学院生物医学工程学院,广州510520)
0 引言
乳腺癌是一种影响女性健康和生命的恶性肿瘤。根据2018年国际癌症研究机构的最新调查结果,在全球女性癌症中乳腺癌的发病率为24.2%,居女性恶性肿瘤的首位[1]。近年来,我国每年诊断出的乳腺癌患者达30万之多,发病率呈现逐年上升的趋势。随着综合治疗手段的开展和普及,全球乳腺癌死亡率呈下降趋势,但是在中国尤其是广大农村地区,这一变化并不明显。而对乳腺肿瘤的早期诊断和治疗,可以有效提高乳腺癌患者的存活率和治愈率[2-3]。
随着计算机技术和人工智能技术的发展,多种计算机辅助诊断技术已被应用于乳腺肿瘤的早期诊断。刘琼荪等人提出了基于径向基神经网络的乳腺肿瘤诊断模型,仿真结果表明训练样本的平均误差率为0,100个检测样本的平均误差率为23.5%[4]。王曙燕等人研究了模糊聚类分析在乳腺肿瘤图像数据分类中的应用,取得了较高的分类准确率[5]。易静等人利用223例临床手术患者的11项指标,基于4种决策树算法,建立了乳腺肿瘤腋窝高位淋巴结分类诊断研究模型,分类模型的准确率为83.79%[6]。金强等人利用附加了动量项和自适应速率的改进BP神经网络算法对乳腺肿瘤进行诊断,正确识别率达到了91.25%,平均误识率为8.75%[7]。章永来等人设计的改进的支持向量机分类算法,在乳腺肿瘤的分类诊断中表现了较好的分类效果,分类准确率达98.59%[8]。徐胜舟等人提出融合遗传算法和支持向量机的乳腺肿瘤分类诊断方法,AUC值达到了0.908[9]。Samala等人利用多任务迁移学习深度卷积神经网络,实现了对高精度乳腺X线图像的乳腺肿瘤诊断[10]。Bayramoglu等人采用放大倍数独立的深度学习分类方法实现乳腺肿瘤组织病理学图像的分类,准确率达83%[11]。
然而,临床医学数据通常具有明显的样本类别不平衡性。不平衡的数据会导致分类器偏向多数类,影响少数类的分类效果。而在医学诊断数据中,少数类样本往往具有至关重要的现实意义,对少数类的错误分类可能会导致严重的后果。例如,将恶性乳腺肿瘤患者错误的分类成良性患者,贻误治疗,将会危及患者的生命健康。决策树、神经网络、支持向量机等传统的分类算法通常假设数据集具有均匀的数据分布和相同的误分类代价,因此在处理不平衡数据时,不能有效反映数据的分布特征,分类结果出现类别偏置现象,大大减弱算法性能。
随机森林作为一种性能良好的集成学习算法[12],具有较高的分类性能,能够很好地规避过拟合现象,降低分类系统的泛化误差,已被广泛应用于众多领域,尤其是医学数据的分类任务中。
本文针对UCI乳腺肿瘤数据集样本类别存在的不平衡性问题,首先分别基于不同的重采样策略构建类别平衡的数据集,然后采用随机森林算法构建乳腺肿瘤数据分类模型,引入医学数据分类模型评价指标查全率、查准率、F1-score与未使用采样策略的构建的分类模型进行比较,同时引入混淆矩阵以直观评估对少数类的分类效果影响。
1 随机森林算法
随机森林是一个由多个决策树分类器构成的集成分类器,每个决策树分类器通过投票来决定最优的分类结果。随机森林的分类思想为:
(1)利用bootstrap重采样方法从原始训练集中随机抽取k个样本,形成k个相互独立的bootstrap子样本集,每个子样本集的样本容量与原始训练集相同。
(2)每个bootstrap子样本集利用CART算法生成单棵决策树。在决策树的每个节点分裂时,从全部M个特征中随机选择m(m<M)个特征,按照“基尼基数(Gini index)”最小原则,再从m个特征中选择最优特征作为分裂特征进行分支生长。假设当前选取的特征ti中包含K个样本类别,pk表示第k个类别样本量占总样本总量的比例,则ti的基尼值为:
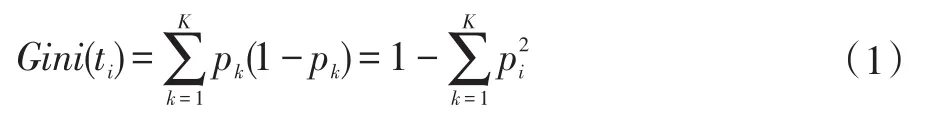
(3)重复步骤(2),针对k个 bootstrap子样本集,构建k棵决策树,形成随机森林。
(4)根据k棵决策树的投票结果,选出最终分类。
2 基于重采样策略的随机森林分类模型构建
2.1 数据选取
本文选用UCI机器学习库中的乳腺肿瘤病例样本数据,该数据由美国威斯康辛大学医学院收集和整理。该数据样本包括569个病例数据,含有357例良性样本和212例恶性样本。样本比例为1.68:1,存在一定的数据不平衡问题。
每个病例样本为32维数据,包含病例编号、诊断标签、细胞核10个特征量的平均值、标准差和最坏值。其中,第1个字段为病例编号;第2个字段为诊断类别标签(B为良性,M为恶性);第3-12个字段为10个特征的平均值;第13-22个字段为10个特征对应的标准差;第23-32个字段为10个特征对应的最坏值。
2.2 采样策略
医学数据集分类模型的构建,数据预处理工作十分重要,可能会直接影响到分类的准确率[4]。数据处理中的采样策略应用较为广泛的主要有两种,即过采样和欠采样。
(1)过采样方法
过采样是一种通过增加少数类别的样本数量,以平衡数据集的方法。其中,随机过采样是通过随机复制少数类样本来增加少数类的样本数量,是最简单的过采样方法。但该方法仅是通过简单复制少数类,没有增加新的分类信息,容易造成分类过拟合问题。SMOTE算法是比较常用的过采样方法,并表现了较好的效果。SMOTE算法通过向少数类别样本数据之间插入人工合成样本,有利于改善原始样本数据的不平衡性。
(2)欠采样方法
与过采样方法相反,欠采样是通过减少多数类样本量,使其与少数类样本量趋同,以平衡数据分布,例如随机欠采样、数据清洗方法等。随机欠采样会随机删除多数类样本,减轻数据的不平衡程度。数据清洗法则通过“清洗掉”类间重叠样本来平衡数据集。
本文分别采用数据处理中的SMOTE过采样方法和随机欠采样方法构建基于不同采样策略的随机森林分类模型,探讨不同采样策略对分类模型性能的影响。
2.3 分类模型性能评价指标
准确率(Accuracy)是评价分类器性能的常用指标。然而对于不平衡数据集问题,特别是医学临床问题,准确率不能很好说明分类器的性能。针对本文中的乳腺肿瘤不平衡数据分类问题,我们还引入正向样本和负向样本的查全率(又称召回率,Recall)、查准率(Precision)以及F1-score作为分类效果的评价指标。
定义1准确率正确分类的测试样本数量占所有测试样本数量的比例,记为Accuracy,计算公式如式(2)所示:
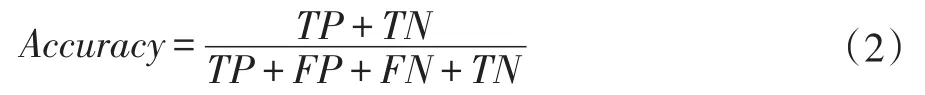
其中,TP为实际为正样本,分类器也正确分类为正样本的样本量;TN为实际为负样本,分类器正确分类为负样本的样本量;FP为实际为负样本,分类器错误分类为正样本的样本量;FN为实际为正样本,分类器错误分类为负样本的样本量。
定义2正向查全率正向查全率为正确分类的正样本数量占正确分类的正样本和错误分类为负样本的比例,记为Recall_P,计算公式如式(3)所示:

定义3负向查全率负向查全率为正确分类的负样本数量占正确分类的负样本和错误分类为正样本的比例,记为Recall_N,计算公式如式(4)所示:

定义4正向查准率正向查准率为正确分类的正样本数量占正确分类的正样本和错误分类为正样本的比例,记为Precision_P,计算公式如式(5)所示:

定义5负向查准率负向查准率为正确分类的负样本数量占正确分类的负样本和错误分类为负样本的比例,记为Precision_N,计算公式如式(6)所示:

定义6 F1评分F1评分是综合考虑查全率和查准率计算的结果,记为F1-score,计算公式如式(7)所示:

其中,当计算正向评分时,Precision=Precisionn_P,Recall=Recall_P,当计算负向评分时,Precision=Precision_N,Recall=Recall_N。
3 实验与分析
实验中训练集和测试集的数据比例按照7:3进行划分,训练数据为398例,测试数据为171例。以下在数据分析时,用B表示正向样本,用M表示负向样本。
(1)决策树个数对分类性能的影响
为探究决策树个数对算法分类性能的影响,选取欠采样策略下,决策树个数N分别为3、6、9、11时进行实验,实验结果如表1所示。
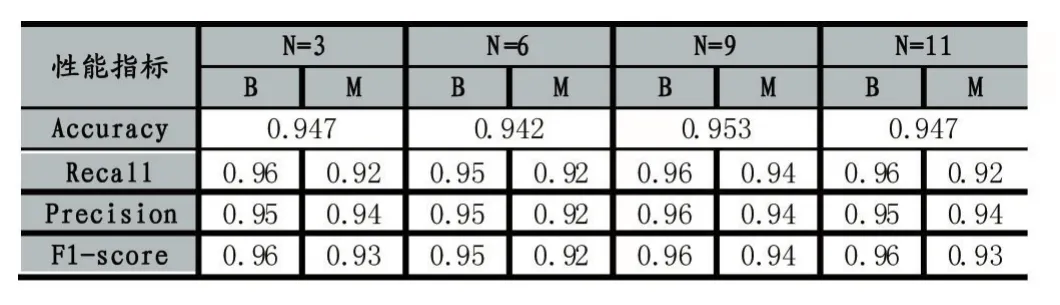
表1 决策树个数对分类性能的影响
由表1可以看出,当N=9时,分类模型的各性能指标较好。综合考虑分类效果和时间效率,以下实验将决策树个数选定为9,以此分析采样策略对分类效果的影响。
(2)采样策略对分类性能的影响
为了探究采样策略对分类性能的影响,本实验分别测试了未采样、欠采样、过采样策略下的分类效果,如图1和表2所示。
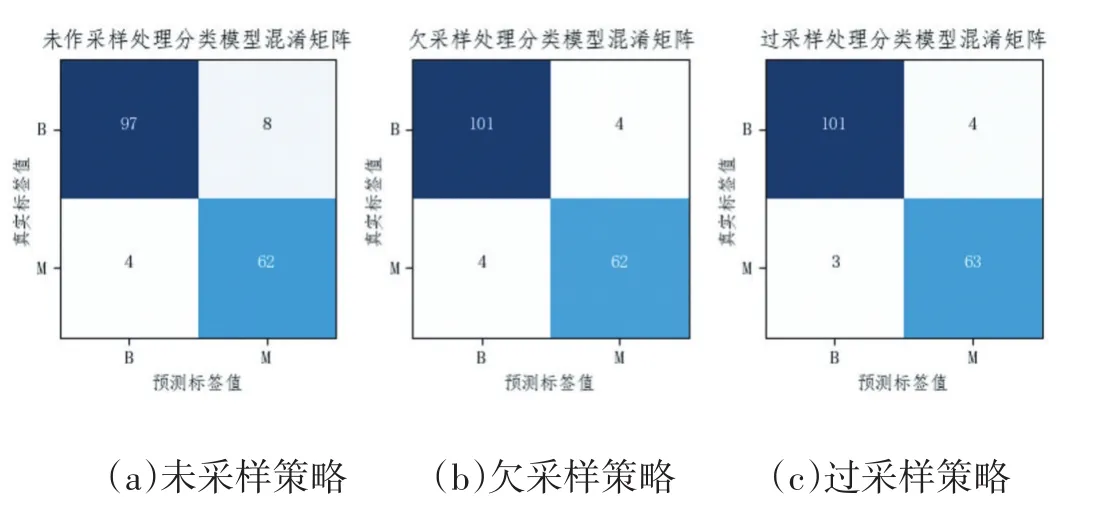
图1 不同采样策略的混淆矩阵
图1 (a)显示,在未采样策略下,105个正向样本中有8个被错误划分为负向样本,66个负向样本中有4个被错误划分为正向样本;图 1(b)(c)结果显示,在采用欠采样和过采样策略后,正向样本及负向样本中错误划分的样本量均有不同程度的减少。
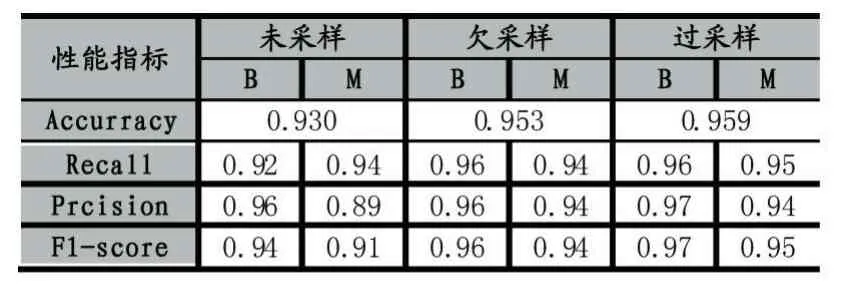
表2 不同采样策略对分类性能的影响
表2结果表明,在未采样策略下,负向样本的分类效果不佳,低于正向样本的分类效果;相比于未采样策略,欠采样和过采样策略下各性能指标均有不同程度的提升,其中,对负向类的查准率均提高了5%,F1-score分别提高了3%和4%,性能提升明显。
因此,在该乳腺肿瘤的分类问题中,经欠采样和过采样策略处理数据后的分类模型性能均优于未作采样处理后原始数据模型分类效果,而且过采样策略具有更优异的表现,较好地改善了不平衡数据集引起的分类偏置现象。
4 结语
为了解决乳腺肿瘤数据集类别不平衡的问题,本文基于不同的重采样策略构建平衡数据集,采用随机森林算法建立乳腺肿瘤分类模型,探究不同采样策略对乳腺肿瘤数据集的分类效果的影响。实验结果表明,对比原始数据集,使用采样策略后的数据构建的乳腺肿瘤分类器性能有一定提升,且经过采样处理后构建的分类模型较欠采样处理后的分类性能更好。
猜你喜欢
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
昆明医科大学学报(2022年2期)2022-03-29
健康之家(2021年19期)2021-05-23
计算机系统应用(2021年2期)2021-02-23
家庭百事通·健康一点通(2020年7期)2020-08-27
科学与信息化(2019年28期)2019-10-21
海峡姐妹(2018年6期)2018-06-26
软件导刊(2017年4期)2017-06-20
科学与财富(2016年32期)2017-03-04
