
融合时序的决策树推荐算法研究
2020-01-10 12:43徐志熹钱洋苏扬
现代计算机 2019年34期
徐志熹,钱洋,苏扬
(1.四川省图书馆信息技术部,成都610015;2.电子科技大学计算机科学与工程学院,成都611731;3.电子科技大学外国语学院,成都611731)
0 引言
推荐算法[1]会通过对用户画像,发现用户的喜好或偏好,找到内容与用户之间的深层联系[2],将与用户有关系的内容主动介绍给用户。如何建立一套优质推荐模型使其能更快更准地预测用户对于某些内容的偏好程度[3]是一项具有挑战性的工作。
传统的推荐算法思路[4-5]是在推断用户浏览过网页中对象是偏好时,将用户的所有历史行为认为有同样重要性占比。对用户在过去很久访问的对象和最近访问的对象,都是以同样的权重来计算关联矩阵[6-7],最后得出的是用户较长时间段里的平均兴趣偏好。这类方法没有考虑到用户的兴趣可能随着时间的变化发生改变,其结果不能准确地反映当下用户喜好,随着时间跨度越大,偏差也会越大[8-10],最终使得其推荐内容无法满足用户需求。
本文提出的推荐算法考虑了时间变化的影响,加入用户行为时序,构建行为时序模型。通过收集用户对推荐内容的反馈,可实时更新用户偏好,从而改善下一次推荐内容。研究的主要内容与创新点有:①融合用户行为的时序对用户偏好的影响,提出时序模型;②采用机器学习方法,建立推荐内容计算目标函数;③使用决策树和优化损失函数更新预测参数。
1 用户行为时序模型
将用户的访问过的项目和系统推荐给用户的项目以时间顺序排列记录下来,通过对用户访问过和推荐过的项目序列进行计算,得到行为之间的关系值的大小和用户与行为偏好值。
用户在某n个连续时刻下有着如下的历史行为序列Xi与X(ji≠j)可以是相同或者不同的访问项目,形成时序项目集,即X1,X2,…,表示在n个时间窗口里用户曾经访问过的项目。通过用户的身份变化,当前的行为特征以及对象关联度权重矩阵计算出下一个能满足用户偏好的访问项目Xn+1,并将它推荐给用户。将用户的历史行为记录存储,推荐系统需要提取其中下每次向用户推荐时间点的前几次的用户行为和推荐后的用户行为。
对用户的推荐作为用户行为序列的预测,预测计算的目标函数表示为:

其中Xn表示上一次推荐给用户的项目,Xn+1表示下一个时刻给用户的推荐项,表示通过用户当前的行为给出的推荐选项;Q1和Q2表示上次行为对当前行为的影响参数。
2 基于决策树的参数训练
2.1 模型概括
通常在推荐系统中,会有多种用户参数作为推荐算法的输入,针对公式(1),如何计算出最优的Xn+1主要取决对于Q1和Q2的计算方法。首先构造一颗决策树,如图1所示,采用多项指标来判断,参数Q1和Q2是否需要修改。在本文的图书馆导读推荐系统中会采用如下几个维度,分别是:用户的角色变化,浏览行为的变化以及是否接受上次的推荐内容。通过对系统已有数据的训练,可以得到如图1所示的决策树模型来计算 Q1和 Q2。
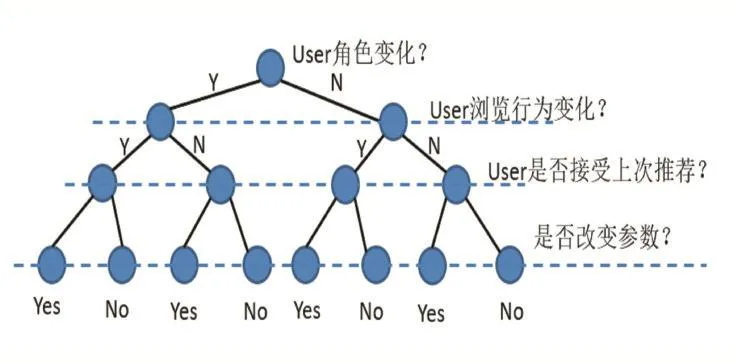
图1 决策树
2.2 预测参数更新
通过构造关于用户身份和行为的目标函数记为:Id和Action来计算Q1和Q2,目标函数记为:
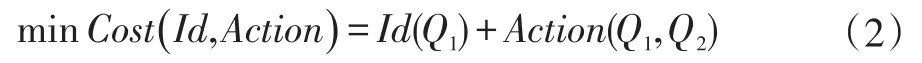
其中,Id函数定义为:

Id函数主要是针对参数Q1来进行的决策判断,主要依据是用户角色属性的是否有变化,在实际中用户角色变化包括身份属性的变化,用户评分升级等都可以用来作为评估属性。
目标函数第二部分Action函数定义为:
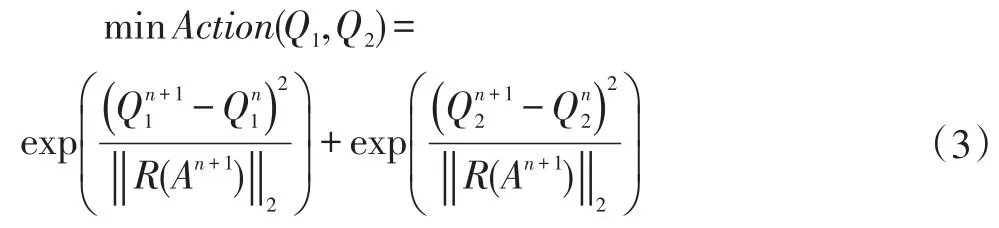
R(An+1)采用协同过滤算法[12-14]计算所有项目两两之间的关系权重。最后对于参数Q1和Q2,分别对公式(3)求导可以得到预测参数的更新值。

通过计算得到的Q1和Q2,能够作为下一次给用户推荐所使用的更新参数。
3 实验
实验部分主要分为两个部分,一个是本文所提出的算法和传统算法在通用数据集上的对比;另一个部分是本文算法在四川省图书馆导读系统中的推荐效果。
3.1 数据集实验对比
实验需要使用的数据集的两个来源:Gowalla[15]、Last.fm[16]。Gowalla是一个基于位置的社交网站,用户可以通过登录来共享他们的位置。用户友谊关系网络是无向的,使用公共API收集,由196591个节点和950327条边组成。在2009年2月至2010年10月期间,Gowalla总共收集了6442890个用户的签到。
数据集一共分成两部分。第一部分loc-gowal⁃la_totalCheckins.txt文件中包含有用户签时产生数据段,内容包括时间、地点、用户的ID,总共有6,442,890条数据项;另一部分为loc-gowalla_edges.txt。Gowalla文件存储有用户的社会关系,该文件包含有196,591个用户信息。Last.fm数据集收集了Last.fm网站上的上千名用户的音乐鉴赏记录信息,可以为研究者提供关于音乐推荐的数据集。该数据集记录每一个用户在网站中收听过的艺术家以及他们的作品,提取了最受欢迎的艺术家和音乐播放次数。本文用每种数据中的70%的数据用户训练,而剩下的30%的数据作为测试数据。所用到的筛选过后的数据如表1所示。
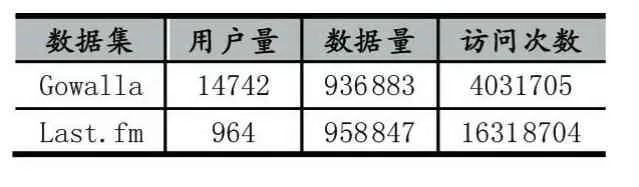
表1 实验数据集
用于对比的传统推荐算法包括:
随机推荐法[17]:从距离用户当前时刻最近的多个访问过的对象中随机选择一个项目推荐给用户。
流行度推荐法[18]:根据每个项目的流行度,将所有项目按照大小排列,流行度的计算方法是ln(1+nv),nv为项目v的出现频率。
Δtuv最近项目推荐法[17]:该方法假设最近被访问过的项目有着更大的可能性再次被用户访问,需要使用指数最近性测量法e-Δtuv,是推荐的时间点和用户u上次访问项目v时间点的间隔。该推荐方法的计算主要基于加权项e-Δtuv。
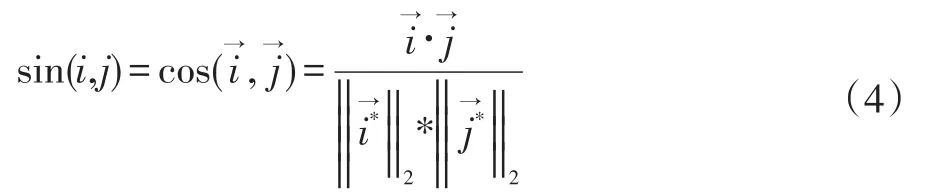
协同推荐算法[19]:基于余弦相似度,计算公式(4),为用户建立数学模型,找出与目标用户最近的邻居用户,推荐邻居的偏好项目。
推荐准确的评估需要用到平均正确率(Average Precision)的计算方法,首先定义对于用户u的推荐出正确的项目的概率为:
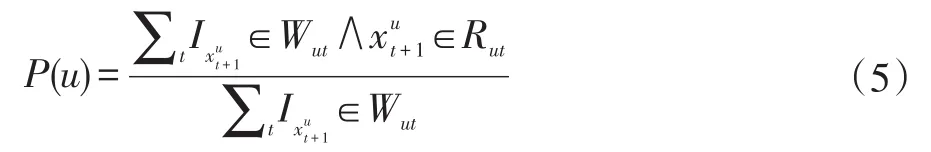
其中,Rut是用户u在t时刻的推荐组合。使用宏平均 MaAP(Macro-Average)和微平均 MiAP(Micro-Average)作为评估指标[17],MaAP衡量评估中全部正确推荐的分数,而MiAP是评估中所有用户的平均推荐准确率,两者主要区别在是否要考虑用户序列长度的不均衡。
实验结果的情况如图2所示。基于用户时序决策模型的推荐在Gowalla和Last.fm两个数据集上使用MaAP和MiAP计算出的的测试准确率都高于与之比较的基础方法。Gowalla数据集中访问序列的长度比Last.fm数据集更不均衡,MaAP计算出的结果中,基于用户时序决策模型的推荐方法相对于基本方法准确率提高的比率比MiAP的计算结果更高。
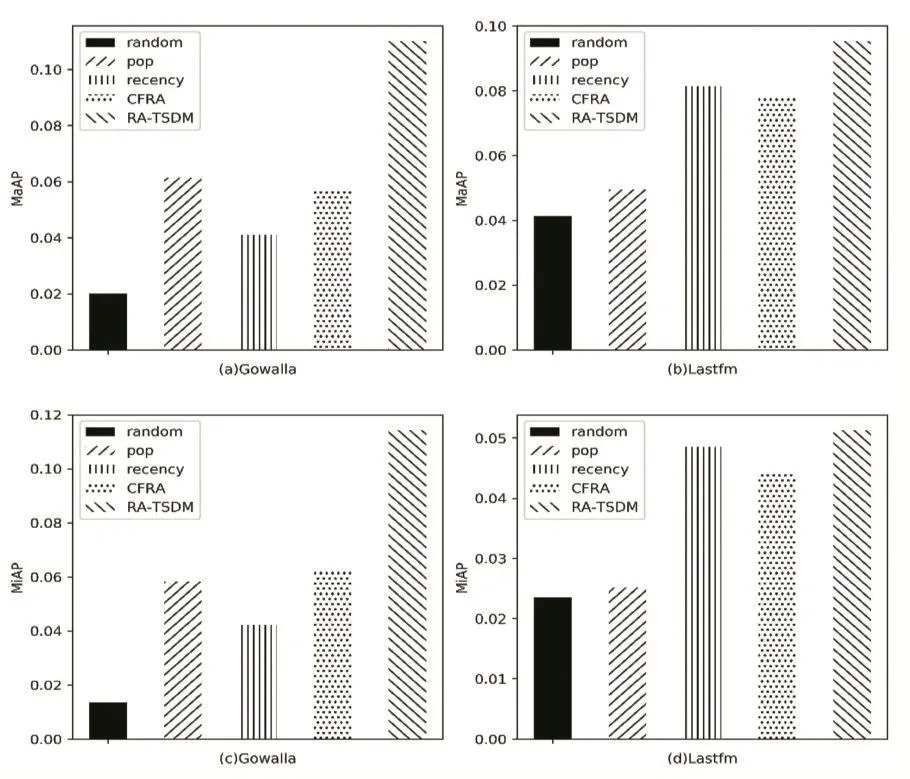
图2 实验结果对比
3.2 导读系统推荐实验
本文算法已应用于四川省图书馆智能导读系统,为用户提供咨询问题推荐,运行结果如图3所示。在该系统中,推荐算法会根据用户针对同类问题在历史时序上进行模型构造,训练出与历史咨询问题相关联系较高的推荐列表。

图3 导读系统咨询问题推荐实例
图3 的问题推荐中,左图(a)为第一次测试结果,用户在反馈满意后,该推荐系统在右图(b)第二次测试同类问题时,给用户提供的答案更聚焦“充电”,更准确地为用户提供答案。
4 结语
本文提出了用户历史行为对当下行为的影响基础上,提出了行为时序概念,从而构建了时序模型,将到用户的兴趣可能会随着时间发生偏移的问题,用系统与用户交互的反馈结果来构建决策树模型,通过机器学习来实时学习用户的动态兴趣偏好这一目标函数,让算法结果更能匹配用户的当前状态的偏好。本文所提出的算法,已在实际智能咨询系统中运行,并取得了较好的实际效果。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
小猕猴智力画刊(2022年3期)2022-03-28
农业工程学报(2022年1期)2022-03-25
意林·作文素材(2021年23期)2021-01-22
科学与信息化(2019年28期)2019-10-21
科学与财富(2016年32期)2017-03-04
中学生数理化·八年级数学人教版(2016年4期)2016-08-23
理科考试研究·高中(2016年9期)2016-05-14
新高考·高二数学(2015年7期)2015-10-22
决策与信息·下旬刊(2013年1期)2013-03-11
