
一种新的倾斜摄影测量点云分类框架
2020-01-09 06:42李枭王双亭王春阳都伟冰赵利霞
遥感信息 2019年6期
李枭,王双亭,王春阳,都伟冰,赵利霞
(河南理工大学 测绘与国土信息工程学院,河南 焦作 454000)
0 引言
随着多视影像密集匹配技术的发展[1],可以较为容易地获取到类比于激光点云精度和密度的倾斜摄影测量点云。该点云主要用于后续的三维建模,基于倾斜影像所构建的三维模型仅是一个单一的表面模型,缺乏语义信息,所以如何在点云层面自动判别场景内的地物并完成建模,实现地物的单体化有着重要的研究意义。
点云分类是三维建模的第一步也是非常重要的一步[2]。目前,点云分类的研究主要集中在激光点云,主要通过有监督的机器学习来进行。Zhang等[3]采用支持向量机(support vector machine,SVM)对3个不同密度的激光点云数据集进行分类处理,并利用连通域分析进行后处理优化。Ni等[4]利用随机森林(random forest,RF)对聚类后的点云数据进行分类,并设置一定的语义规则对错分现象进行修正。Xu等[5]结合机载扫描点云对5种常见的分类器的分类效果进行了系统性的分析。而针对倾斜摄影测量点云的分类研究相对较少,比较代表性的有何雪等[6]将点云与影像进行结合,构建超体素,并采用上下文关系进行优化处理,收到了较好的分类效果;赵利霞等[7]利用随机森林对几何和光谱特征进行优选,减少了特征冗余现象,有效地提高了分类的效率。
上述分类方法均通过监督分类的方式进行。有监督的机器学习通常利用全部训练集进行一次分类,这会导致分类的效率和精度很大程度上都受到训练集的影响。人为选取的训练样本存在较大的主观性,不可避免地存在一些冗余甚至“负作用”的数据。此外,上述文献中所利用的后处理优化方式,需要大量参数、阈值以及规则的设置,优化过程的自动化程度较低。
为了解决上述问题,本文利用信息熵改进随机森林,利用小样本不断迭代的方式,逐步抽取“信息含量”高的训练数据参与分类,充分挖掘训练集的分类能力。针对优化过程自动化程度不高的现象,本文构建了循环置信传播网络(loopy belief propagation,LBP)[8]。该方法通过邻域内信息传递的方式,使邻近的点云类别趋近相同从而达到优化分类结果的目的。
1 分类框架
本文的分类框架由三部分组成:数据预处理;利用信息熵改进的随机森林初次分类;利用LBP算法对初步分类结果进行优化。详细的技术流程如图1所示。

图1 技术流程
1.1 数据预处理
由于倾斜摄影测量点云是高密度的三维彩色点云,所以要对数据进行预处理,处理过程主要遵循以下步骤:
①保留原始特征情况下对点云进行降采样。
②利用布料模拟滤波算法(cloth simulation filtering,CSF)[9]对点云进行滤波,将地面点作为一类纳入分类结果。该算法模拟了虚拟布料覆盖于倒置点云的简单物理过程,通过设定布料节点和激光点的距离阈值将点云分为地面点和非地面点。
③考虑每个非地面点与邻域内其他点的欧式距离,设定阈值进行离散噪声点的滤除。
④选择大约10%的点云作为训练集,选取一定数量的点作为验证数据。
倾斜摄影测量点云区别于激光点云,有真实的纹理信息,本文特征的计算主要从几何特征和光谱特征2个方面进行,两者融合有助于提高分类效果[10],邻域大小为K(K=8)。本文采用的特征集如下:
①协方差系列特征。包括法向量nx、ny、nz,线性(linearity,Lλ),平面性(planarity,Pλ),球度性(scattering,Sλ)以及各向异性(anisotropy,Aλ),这些特征均反映了点云的邻域内的空间分布[11]。
②高程系列特征。包括归一化高程、邻域高程差异以及邻域高程标准差,这些特征能够反映点云的高度变化,有助于区分存在高程差异的地物。
③颜色模型特征。包括HSV颜色模型和Lab颜色模型,这两者颜色特征区别于RGB颜色,加入了感官特征,反映点云颜色的明暗和深浅。
④植被指数特征。包括差异植被指数(visible-band difference vegetation index,VDVI)、归一化绿蓝差异指数(normalized green-blue difference index,NGBDI)、红绿蓝植被指数(red-green-blue vegetation index,RGBVI)。植被指数特征的加入有助于区分植被和非植被地物。
1.2 信息熵改进的随机森林
信息熵是信息不确定性的描述[12],信息熵越大,表示信息不确定性越高,信息含量越高。本文引入二次Renyi熵作为评价信息不确定性的标准。二次Renyi熵可以通过归一化处理后的式(1)得到
(1)
式中:R2(X)表示二次Renyi熵值;p(xi)表示某个点第i个的类别标签的概率;n表示类别个数。
随机森林在点云分类领域有良好的表现[13-14],所以本文将二次Renyi熵与随机森林结合,提出一种改进的监督分类方法。具体的算法流程如下:
①对原始训练集进行抽样(10%)作为初始迭代的子训练集,剩余数据作为迭代过程中更新训练集的数据源。
②首次迭代,获得初次的分类结果。将每个点预测类别的投票数转化为概率值,计算所有点云的二次Renyi熵值。
③从剩余的训练集中选取熵值较大的一定数量(初始子训练集的1/3~1/2)的点作为下次迭代所增加的新数据,更新训练集,并在剩余训练集中对应剔除,保证所选取的训练集不冗余。
④满足迭代次数,输出分类结果(类别标签;类别标签概率;优选的训练集)。
在上述算法流程中,更新训练集所添加的数据为本次迭代过程中熵值较大的一些点,熵值越大代表着这些点标签不确定性和信息含量越高,但是由于其真实类别标签已知,所以本文将这些数据作为已知信息加入下一次迭代,不断优化分类结果。
1.3 循环置信传播优化
传统分类方法在没有空间关系作为先验知识的情况下进行分类过程,依据所得到的类别标签概率去标记每个点的类别是存在一定局限性的。因此,基于单点的分类过程不可避免地会出现散乱点错分的现象,即常见的“椒盐”现象。
为了改善这种现象,本文引入在图像分割领域常用的多级logistic(multi-level logistic,MLL)模型函数,它能够促使图像分割时邻近像素更可能地被分为一类[15-16]。本文利用MLL模型作为描述点云类别标签空间约束关系的先验概率,计算方式如式(2),当点i和j的类别标签xi和xj一致时,该函数会赋予较大的权重,促使邻近点更可能被标记一致。在引入先验概率的基础上,获取每个点的最大后验概率(maximum a posteriori,MAP)是优化过程的核心。
(2)
式中:Z表示归一化常数;μ表示平滑度;C表示点云的邻域范围;δ(xi-xj)是一个单位脉冲函数,当xi=xj时,函数值为1,反之为0。
最大后验概率可以通过求解最大后缘概率(maximum a posteriori marginal,MPM)的方式来进行[17]。因此,本文构建了LBP网络,通过求解置信度的方式来获取最大后验边缘的概率分布,以此确定每个点的类别标签。置信传播是一种特殊的马尔科夫随机场(markov random filed,MRF),它描述了每个点的类别标签独立于整个点云而只依赖于邻近其他点。其中,2个能量函数关联势φi(xi,yi)和交互势ψij(xi,xj)分别利用初次分类结果的类别标签概率和MLL模型构建的空间约束的先验概率表示。
置信传播通过信息传递的方式,将该点的信息经过加权处理传递到邻域的其他节点,以影响其他节点的概率分布。经过一定次数的迭代,每个点的概率分布将会处于一个稳定的状态[18]。每个点通过所有接收到的信息来计算置信度[8],以此确定每个点的类别标签。本文循环置信传播过程采用标准最大乘置信度传播(max-product,MP),算法借鉴文献[16]。图2表示某次迭代过程中信息传递情况。
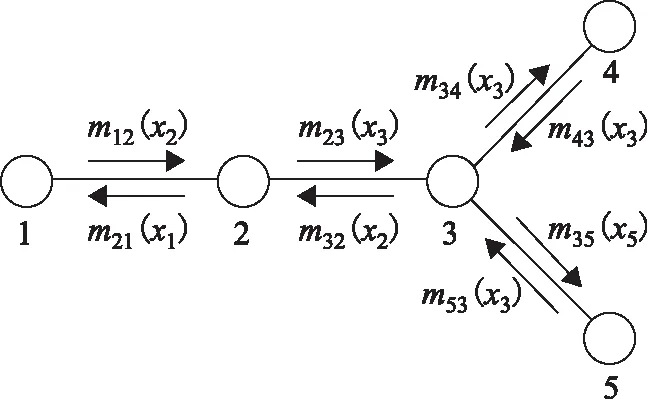
图2 信息传递
置信传播过程中信息传递和置信度的计算公式如式(3)、式(4)所示:
(3)
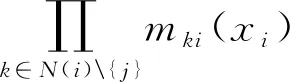
(4)
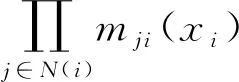
迭代结束后,选择置信度高的类别标签对所有点云进行重新标记,如式(5)所示,得到优化后的分类结果。
xi=argmaxbi(xi)
(5)
2 实验与分析
2.1 测区数据及预处理
本文使用的数据为鹤壁市某区域的倾斜摄影测量点云,研究区域占地0.51 km2,点云数量为1 430 003个,如图3所示。我们利用Matlab 2016a和开源软件Cloud Compare平台验证本文提出的分类框架。本次分类只针对非地面点,所以使用布料模拟滤波算法对地面点进行滤除,滤波结果如图4所示,其中,图4(a)为滤波后的地面点数据,将其纳为单独的地物类别,图4(b)为后续待分类的点云数据集。

图3 研究区域图示

图4 布料模拟滤波结果
针对滤波后的非地面点进行去噪处理。得到参与分类的点云数据集如表1所示。

表1 实验数据集 /个
2.2 信息熵改进RF初步分类结果
本文改进的随机森林算法是利用小样本迭代的方式进行的,所以对原始训练集抽样方式的研究也是一个值得讨论的问题。考虑到不平衡数据的存在,为了使每一类的点云都会被抽取到,本小节主要对等概率和等数量2种抽样方式进行简单分析。前者在抽样过程中保留了原始训练集不同类别点云数量的比例,后者保证每类点云都能抽到相同数量。图5表示2种抽样方式的迭代过程。从图5(a)、图5(b)可以发现2种抽样方式进行的迭代分类,分类精度曲线均呈现一种先上升后稳定的趋势,但是,相对于等数量抽样,等概率抽样最大限度地模拟了原始训练集,该抽样方法能够获得较高的初次分类的精度,而且变化曲线相对比较平稳,可以提高算法运行的稳定性,所以本文的研究也将延用该种抽样方式。
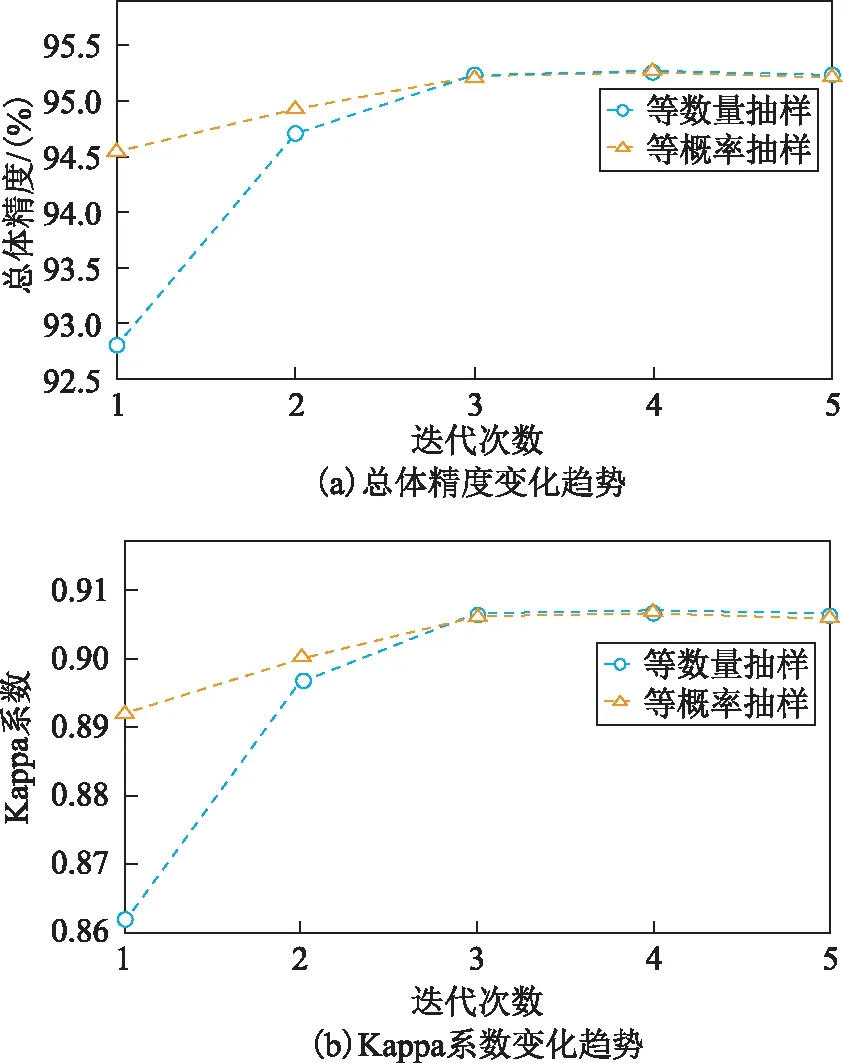
图5 不同抽样方式迭代过程
图6表示算法改进前后分类结果的对比情况。从图中可以看出,当迭代进行到第三次时,改进后算法的分类结果中总体精度和Kappa系数都已经超过传统算法,随着迭代的进行,分类精度还有一定的提高。此外,迭代到第三次所耗费的总时间仅为149.14 s,而利用全部训练集进行传统随机森林分类则会消耗333.54 s。本文的方法虽然分类精度并没有较大的提升,但是算法的运行效率却有了很大的提高。其次,从图6中可以发现随着训练集的不断增加,分类的精度趋于稳定甚至略有下降,说明新添加的训练集对整体的分类效果并没有产生促进作用,这些数据的加入反而使得训练样本冗余,甚至会出现一些“负作用”的数据。所以训练集的优选对提高分类的精度和效率有十分重要的意义。
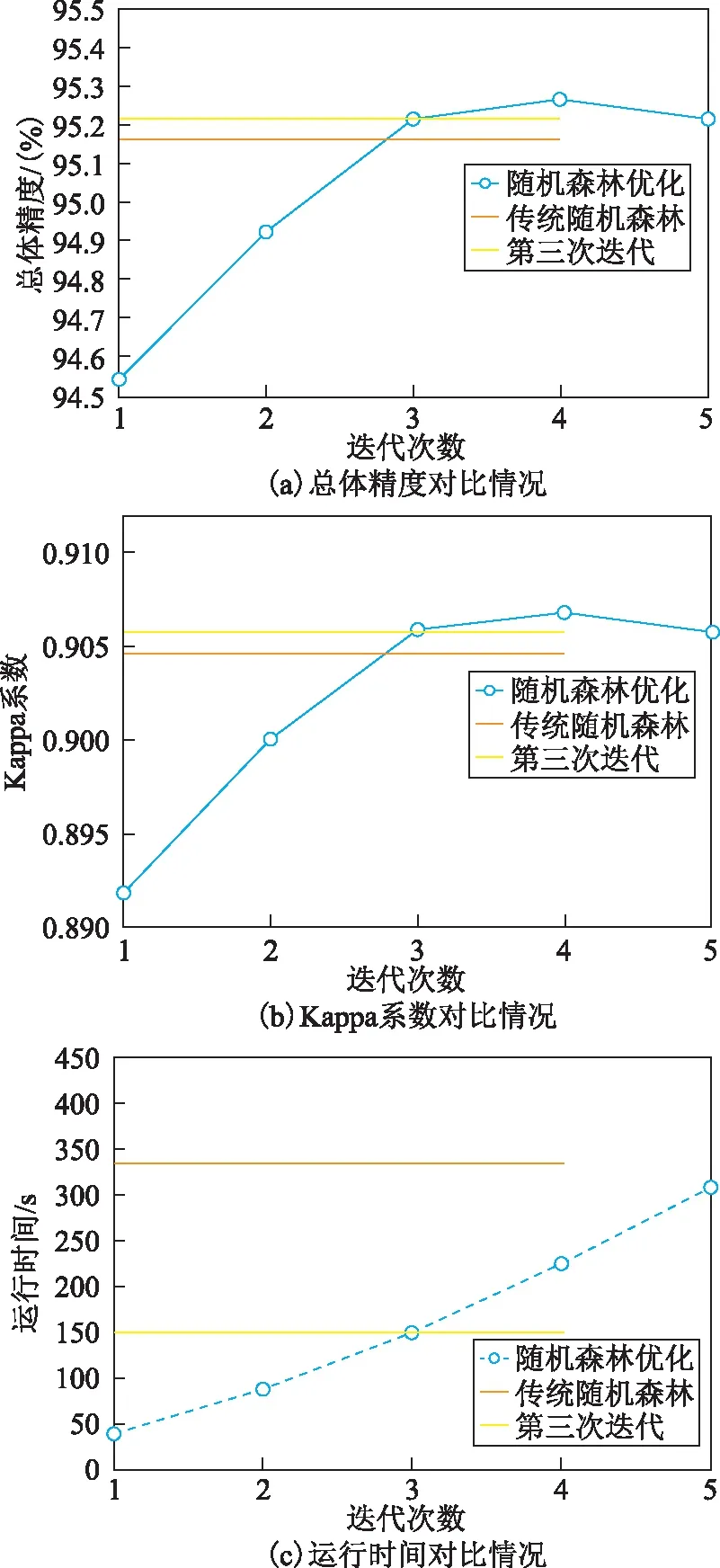
图6 算法改进前后分类结果的对比情况
此外,针对不同点云数据集进行了大量的实验发现,本文提出的改进算法均能在较短的迭代次数内使分类精度达到峰值(一般为3~5次),随着迭代的进行分类精度将会保持稳定状态。
为了验证优选的训练集能否达到预期的分类效果,选择第三次迭代过程的训练集参与随机森林分类,从表2可以看出,利用优选出的训练集进行实验,能够在保证分类精度的前提下,将运行时间缩短80.15%,运行效率大大提高。所以,信息熵改进的随机森林方法能够优选出一组适合于该分类模型且分类能力较强的子训练集,同时能够为该数据集后续的二次使用节约运行成本。
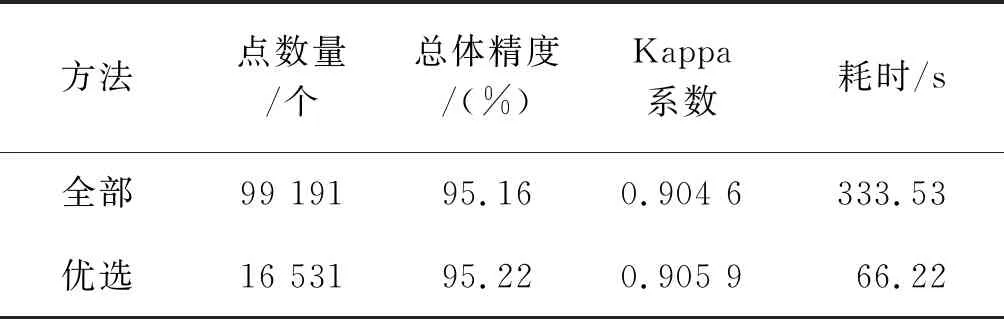
表2 训练集优选前后对比结果
2.3 结果分析
在以下小节中,对文中提出的分类框架和传统单点分类的结果进行定性和定量的分析,并引入一些常用的分类算法进行对比实验。此外,文末还对分类框架的适用性进行了简单的实验分析。
1)定性分析。图7(a)、图7(b)表示基于单点的随机森林分类和文中提出的分类框架二者分类结果,图7(c)至图7(f)表示局部放大图。图7(c)、图7(e)反映了基于单点的分类中出现散乱点错分的“椒盐”现象,其中,大量散乱的植被点云被错分为建筑物。从图7(d)、图7(f)中可以看出,引入LBP算法进行优化后,错分的植被点基本都被修正,说明文中提出的分类框架对解决基于单点分类中的“椒盐”现象十分有效。

图7 分类结果可视化
但是本文提出的分类框架也有着一定的局限性,对于成团簇结构错分的点云,优化能力有限。从图8(a)、图8(b)的黑色框中可以发现,图8(a)中植被错分为建筑物的点云仅有散乱点错分现象被修正,对于团簇结构错分的点云,并没有起到多大的效果,甚至将原本类别标签正确的一些点错误标记。这是由于在LBP算法优化过程中,这些点局部邻域范围内存在大量错误标记的点云,信息传递过程中这些点被赋予了较大的权重信息,随着迭代的进行,错误信息进行了放大,从而出现了原始标签正确但优化后被标记错误的现象。

图8 未修正现象
2)定量分析。本小节中对2种分类方法进行定量的分析。为了验证算法的有效性,引入了总体精度、Kappa系数、查准率、查全率以及F分数作为评判标准。从表3、表4的结果可以看出,本文提出的方法分类的总体精度较传统方法提高了2.15%,Kappa系数增加了4.22%。从两表的查准率可以发现,表4中每一类地物的分类准确性较表3都有一定程度的提高,其中,车辆点的分类准确性较传统方法提高了13.43%。相比于其他2种地物,车辆点通常情况下为独立地物点且不与其他地物点发生“粘连”现象,这使得车辆点局部邻域内点的类别更可能为车辆。在LBP算法信息传递过程中,车辆点的高权重信息影响了其邻域内错分点云的概率分布,错分点云被修正,致使车辆的分类准确性大幅提高。由此可见,文中提出的分类框架的分类性能较传统方法更优。
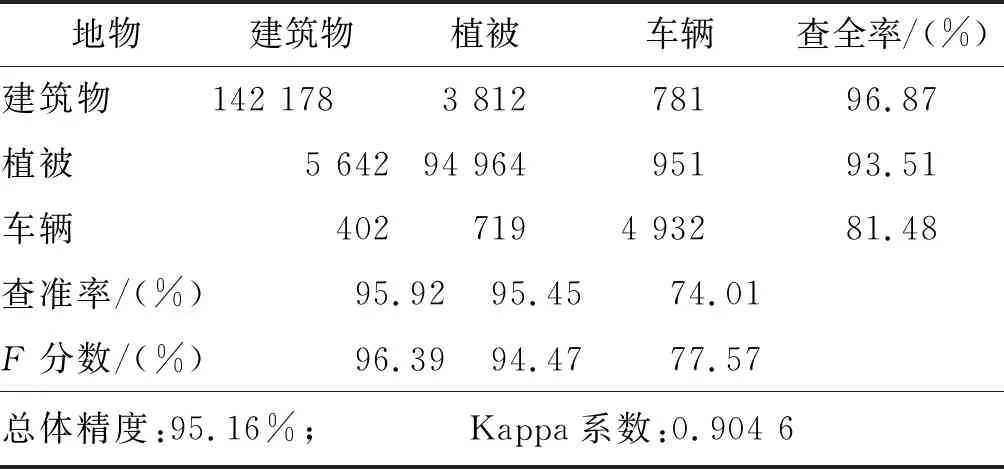
表3 传统随机森林分类结果

表4 本文提出的方法分类结果
同时,本文还引入了目前比较常用的分类器对该数据集进行分类处理。从表5中可以看出,本文倾斜摄影测量点云的分类框架相比于其他几种分类器的分类结果有着较高的分类精度。此外,为了验证本文分类框架的适用性,将分类框架中的随机森林分类器替换为SVM分类器,利用二次Renyi熵改进传统SVM,并利用LBP算法进行后处理优化。从表5中的实验结果发现,改进后的算法较传统SVM分类效果更好,总体精度提高了3.19%,Kappa系数提升了6.25%,说明本文分类框架具有适用于不同传统分类器的能力。
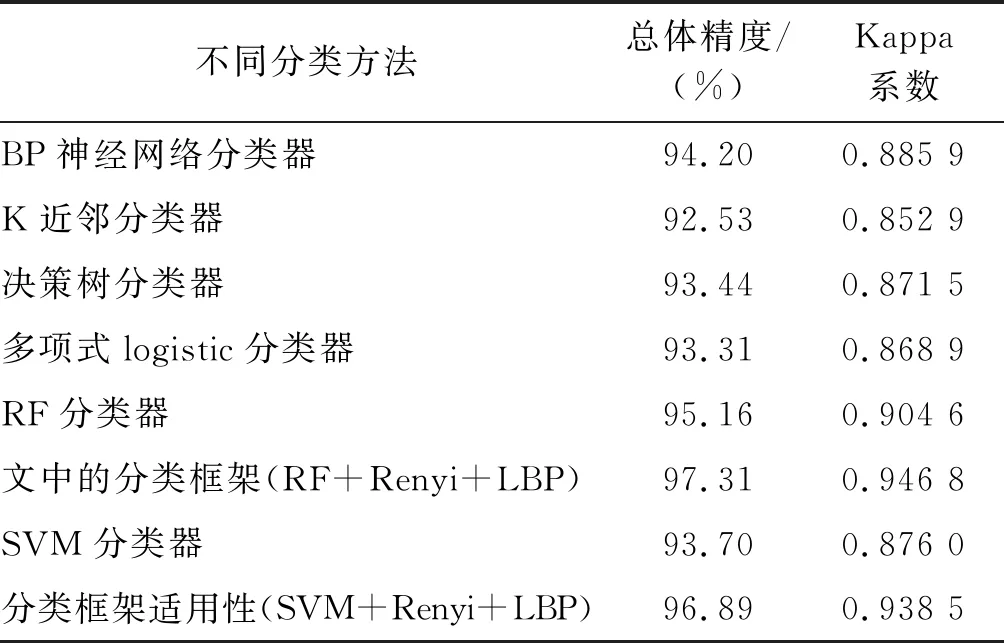
表5 多种分类器分类结果
3 结束语
针对目前点云分类过程大多缺乏对训练集的考虑,以及后处理过程自动化程度较弱的两种现象,本文提出了一种新的分类框架,利用二次Renyi熵改进传统的随机森林,构建LBP网络做优化,并对算法进行了验证,得出了以下结论:①信息熵改进的传统随机森林算法能够在很短的时间内达到传统分类精度,效率成倍提高,优选的训练集仍有很高的分类能力。因此在数据量较大的情况下建议使用。②通过迭代过程发现,随着训练集数量的增加,分类精度并不会呈现正相关趋势,反而保持平稳甚至略有下降。③置信传播的优化处理过程高度自动化,能够提高分类精度,改善“椒盐”现象。④分类框架具有较强的适用性,替换分类器依旧可以获得很好的分类效果。⑤LBP优化算法对成簇状错分点云的修正能力有限,仍需改进。
猜你喜欢
农业工程学报(2022年7期)2022-07-09
吉林大学学报(理学版)(2020年3期)2020-05-29
车迷(2018年11期)2018-08-30
自动化学报(2018年7期)2018-08-20
民族古籍研究(2018年1期)2018-05-21
海峡姐妹(2018年3期)2018-05-09
周口师范学院学报(2016年5期)2016-10-17
新校长(2016年8期)2016-01-10
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
