
基于强化学习的两轮模型车控制仿真分析
2020-01-08 02:06
测控技术 2019年12期
(东南大学 仪器科学与工程学院,江苏 南京 210096)
自20世纪80年代以来,强化学习已经广泛应用于各大领域。例如,在智能驾驶技术领域中,强化学习为车辆驾驶行为学习提供了框架,使得车辆能够模仿人类学习所使用的反复试错方法,采取所需要的行动。通过机器人与环境的交互学习,为其行动作用设置不同的奖励和惩罚,以获取最大的累计奖励为目标,这一启发式学习方法广泛应用于各种场景。例如,Yau[1]等人提出利用强化学习算法使交通信号控制器通过观察和学习选择出最优的交通控制方案,如确定交通信号灯的信号周期、绿信比,提高系统性能。DeepMind团队使用深度强化学习算法训练AlphaGo[2],连胜数十位围棋高手,棋力已经超过人类职业围棋顶尖水平。
强化学习算法中,Q-Learning、Sarsa算法是强化学习领域中代表性的算法。默凡凡[3]利用Q-Learning算法进行了仿真实验中的动态避障。刘卫朋[4]等人提出了基于Sarsa算法的未知干扰因素补偿方法,提高了机械臂轨迹跟踪的控制性能。Q-Learning算法在面对选择时会考虑到之前试错的Q值,并倾向于选择具有冒险性的动作。Sarsa算法与Q-Learning算法相比更为保守,倾向于选择之前试错中Q值更大的动作。DQN算法是近年来提出的一种基于深度神经网络和Q-Learning的方法,具有更强的学习能力。刘志荣[5]等人提出了一种基于DQN的复杂状态环境下进行良好路径规划的方法。状态和动作作为神经网络的输入,经神经网络处理后得到动作的Q值。
基于强化学习的控制方法可以优化机器人的运动控制。然而,强化学习在实际使用中存在着高成本的问题,包括试错带来的经济成本以及执行学习操作带来的时间成本。本文通过将Gym、ROS和Gazebo有机结合,搭建了用于不同环境下的强化学习算法仿真的小车平台,以提供一种利用仿真环境模拟实物运动控制的方案;并最终使用其对经典的三种强化学习算法在两轮模型车的行走控制训练中进行测试验证,根据在复杂度递增的地图中奖励曲线图的表现,对算法的收敛性和鲁棒性进行分析。
1 相关工作
在强化学习和仿真结合方面,Zamora[6]等人提出了基于ROS和Gazebo的OpenAI Gym扩展。OpenAI Gym是强化学习研究的工具包[7],其专注于对强化学习的训练设置,旨在最大限度地提高每次训练的总奖励的期望并尽可能快地获得结果。Gazebo模拟器是一个3D建模渲染工具[8],ROS是一种机器人操作系统[9],将Gym与Gazebo结合,以帮助软件开发人员创建机器人应用程序。
在强化学习实际应用中,Sutton[10]等人在悬崖行走问题中使用了Q-Learning算法和Sarsa算法。此外,Wang[11]等人在Q-Learning和Sarsa的基础上提出了一种Backward Q-learning算法。Shen[12]等人提出了基于DRL的多船自动避碰方法。Peters[13]等人则使用策略梯度方法(Policy Gradient Methods)将强化学习方法扩展到高维机器人领域(如机械手,腿式或人形机器人)。Wang[14]等人将强化学习与遗传算法结合起来,提出了一种用于解决多机器人协调问题的二层多智能体结构。Sharma[15]等人提出了模糊马尔可夫对策作为模糊Q-Learning算法 (FQL)的一种改编。该方法利用增强信号对机械手的模糊马尔可夫博弈控制器的在线结论部分进行了调优。Abdi[16]等人提出了一种用于交通流量预测的情绪时间差分学习算法。近年来,Wiering[17]在强化学习方面中还提出了一种集成算法。他们的思想结合了Q-learning、Sarsa算法、Sutton[18]提出的actor-critics (AC)算法、Q和V函数(QV-learning)。Wiering[17]提出的AC学习自动机(ACLA)结合了不同强化算法价值函数导出的策略,但由于需要集成不同强化学习算法,需要对许多参数进行调优,消耗了大量的计算时间。针对Q-Learning算法的开发-探索平衡性问题,Guo[19]等人提出了一种基于metropolis准则的模拟退火算法(SA-Q-Learning)以改进Q-Learning算法。与Q-Learning算法和玻尔兹曼探索相比,SA-Q-Learning算法的收敛速度将更快。将自适应学习率和模糊均衡器集成到模糊Sarsa学习算法(FSL)中,Derhami[20]等人提出了一种增强的模糊Sarsa学习算法(EFSL),利用自适应学习率防止高访问状态的参数过拟合,利用模糊均衡器实现了合理的开发-探索平衡管理。
综上所述,强化学习算法领域已有多方面研究,各种强化学习算法在不同环境中的控制效果存在差异,通过仿真平台,利用强化学习算法对模型进行仿真控制验证,是理解强化学习以合理选择算法的快捷方式。
2 软件架构及测试框架
软件框架由3个部分组成:OpenAI Gym、ROS和Gazebo,如图1所示。OpenAI Gym作为强化学习的工具包,与ROS环境交互。ROS是一个机器人操作系统平台,用于系统开发,构建两轮模型车和控制算法等仿真模型。Gazebo仿真平台提供强大的物理引擎、高质量的图像处理以及作图的界面。ROS作为Gym与Gazebo仿真平台连接的桥梁,以便在实际环境中验证和标准化强化学习算法。

图1 整体框架
设置两轮模型车无碰撞绕地图行驶两圈为训练成功的标志,对强化学习各方法的测试验证框架分为以下3个部分:① 测试三种算法在3张地图中的训练成功概率;② 在3张地图中依次测试验证同一种算法的训练效果;③ 在同一张地图中依次测试验证三种算法的训练效果。
3 强化学习算法
3.1 强化学习
强化学习系统由智能体和环境两部分组成,目的是通过试错的方法进行从环境到行为映射的学习,寻找使奖励值函数达到最大时的动作方案。建立基于强化学习的两轮模型车控制仿真分析时,需要对强化学习算法中的状态集合S、动作集合A以及奖励矩阵R进行合理定义。为验证平台的有效性,选取Q-Learning、Sarsa和DQN三大主流强化学习算法进行有效性与鲁棒性的测试验证。
3.2 算法原理
3.2.1 基于Q-table
Q-Learning算法与Sarsa算法采用Q表的形式决策,通过不断更新Q-table里的值,根据新的值来判断在某个状态S下模型该采取的动作A。
Q-Learning算法基于Q值函数估计[22]。Q值函数表示智能体在当前状态下采取下一个动作的值函数,一般初始化为0。
Q(st,at)←Q(st,at)+α(rt+1+γmaxQ(st+1,at+1)-Q(st,at))
整体算法流程如下。
算法1:Q-Learning算法
初始化所有状态和Q值函数Q(s,a)
重复(每一轮次)
选择随机状态st或初始化状态st
重复(轮次中的每一步)
用ε-贪婪法选出在当前状态st的动作at
执行动作at,得到新状态st+1和奖励rt+1
计算新Q值函数Q(st,at):
st←st+1
直至st为终止状态
直至搜索到所需轮次的数量
Sarsa算法与Q-Learning算法类似,同样基于Q值函数估计[23]。然其区别在于:Q-Learning算法是一种离线算法,在选择Q(st,at)时使用了greedy方法,而计算Q(st+1,at+1)时使用max方法,实际做决定时,选择的不一定是max的动作; Sarsa算法则是在线算法,它在行动中进行学习,因此选择Q(st,at)与Q(st+1,at+1)时都采用贪心方法,其Q值函数更新公式可以表示为
Q(st,at)←Q(st,at)+α(rt+1+γQ(st+1,at+1)-Q(st,at))
整体算法流程如下。
算法2:Sarsa算法
初始化所有状态和Q值函数Q(s,a);
重复(每一轮次)
选择随机状态st或初始化状态st
用ε-贪婪法选择出在当前状态st的动作at
重复(轮次中的每一步)
执行动作at,得到新状态st+1和奖励rt+1
用ε-贪婪法选出在当前状态st+1的动作at+1
计算新Q值函数Q(st,at):
Q(st,at)←Q(st,at)+α(rt+1+γQ(st+1,at+1)-Q(st,at))st←st+1;at←at+1
直至st为终止状态
直至搜索到所需轮次的数量
3.2.2 基于Q-network
DQN算法的基本思路来源于Q-Learning[24],区别于Q-Learning用状态S和动作A计算Q值,DQN算法中利用Q网络进行Q值计算。Q网络为卷积神经网络,DQN算法采用经验回放的方法,构建一个系统存储样本,通过随机抽取以往记忆库中的数据,对抽取数据进行学习,打破经历之间的相关性,使神经网络的更新高效,解决结果难以收敛的问题。Q网络训练的损失函数为
L(θ)=E[(TargetQ-Q(s,a;θ))2]
TargetQ=r+γmaxa′Q(s′,a′;θ)
DQN算法的基本流程如下。
算法3:DQN算法
初始化Q网络的所有参数ω,基于ω初始化所有的状态和动作对应的Q值。清空经验回放集合D
开始迭代:
初始化S为当前状态序列的第一个状态,获得其特征向量Φ(S)
在Q网络中将Φ(S)作为输入,得到Q网络对应的所有Q值输出。用ε-贪婪法在当前Q值输出中选择对应动作A
在状态S执行动作A得到新状态S′对应的特征向量Φ(S′),奖励R(S)和是否终止is_end
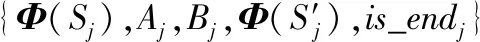
S←S′
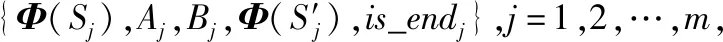
使用均方差损失函数:
通过神经网络梯度反向传播更新Q网络的参数ω;
如果S′是终止状态,则当前轮次迭代结束,进行下一轮迭代。
4 研究过程
4.1 实验平台
实验平台基于ROS操作系统,利用OpenAI Gym进行强化学习的研究和测试验证,利用Gazebo对实验进行仿真。两轮模型车(如图2所示)装有Hokuyo激光雷达,精度为±40 mm,测量距离为0.06~10 m,测量角度范围为270°。分别利用Q-Learning、Sarsa和DQN,利用模型车的激光雷达数据进行训练,测试验证算法在不同地图下的有效性与鲁棒性。

图2 两轮模型车
4.2 实验环境
实验场景设置3个不同复杂程度的12 m×12 m的3D仿真环境,3张地图依次设为MAP1、MAP2、MAP3,墙壁高度1 m、通道宽度1.35 m、通道总长度42 m。每个地图的复杂度由转角数量决定,转角数越多,相应地图复杂度越高。具体模型如图3所示。
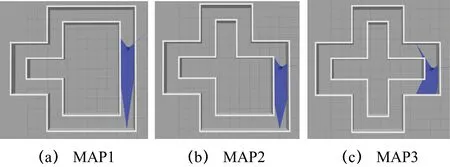
图3 尺寸相等的3种地图
4.3 实验模型
在实验中,模型车的最终目的是通过训练以实现稳定绕地图通道行驶且不会撞到墙壁等障碍物。设置模型车无障碍绕地图行驶两圈为训练成功的标志。
实验以雷达为主要传感器进行训练。雷达居于模型车中心位置,当雷达检测到距障碍物的最小距离小于0.2 m时,即认为模型车撞到了障碍物,该回合立即结束并进行下一回合;否则,模型车将根据所用算法,选取不同策略来选择下一动作。参数设置如表1所示。
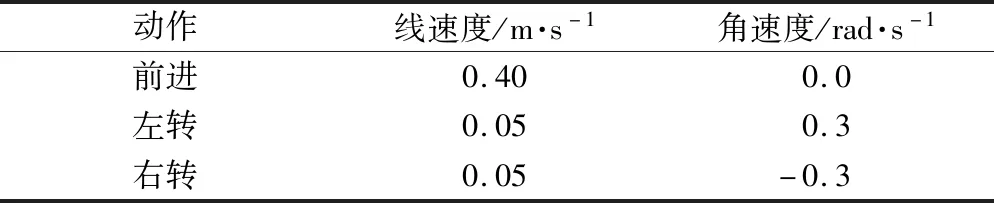
表1 动作离散化及其参数设置
模型车的动作集共有3种:前进、左转、右转。根据所涉及的地图环境和先验知识,分别进行设置,具体奖励值如表2所示。

表2 动作设置奖励
4.4 实验参数
分别采用Q-Learning算法、Sarsa算法及DQN算法对模型车进行训练,以2400个回合后模型车的训练情况以及需要多少个回合能够顺利行驶两圈作为测试验证的主要依据。模型车的学习周期为2400个回合,每个回合结束的标志是模型车撞到障碍物,周期结束后,统计模型车所得奖励,进入下一个回合的学习。
Q-Learning算法与Sarsa 算法中的学习速率的参数设置如表3所示。

表3 算法参数设置
4.5 结果分析
按照算法对应的参数及模型车的奖惩规则进行实验,每一回合记录一次模型车奖励值,对三种强化学习算法在3种地图下的奖励值进行数据分析。由于回合数较多,用平均值替代每10个回合数的奖励值。模型车无碰撞行驶超过两圈的次数在总训练次数中所占的比例称为训练成功率,如表4所示。

表4 不同算法在3个地图下的训练成功率
由表4可知,随着地图复杂度的提高,三种强化算法的训练成功概率都会下降,且DQN算法训练成功率下降得更快。在复杂度较低的MAP1中,DQN算法的训练成功率明显高于Q-Learning和Sarsa算法,但在最复杂的MAP3中,Q-Learning和Sarsa两种算法训练成功率相差很小,DQN训练成功率最低。因此,在复杂地图中Sarsa算法的稳定性与自适应性更佳。
为了研究Q-Learning算法在不同地图中的表现,在3张地图中分别测量了模型车的训练回合数和奖励值(如图4所示)。图中黑线代表模型车可以无障碍绕地图行驶两圈所获得的奖励值1600。
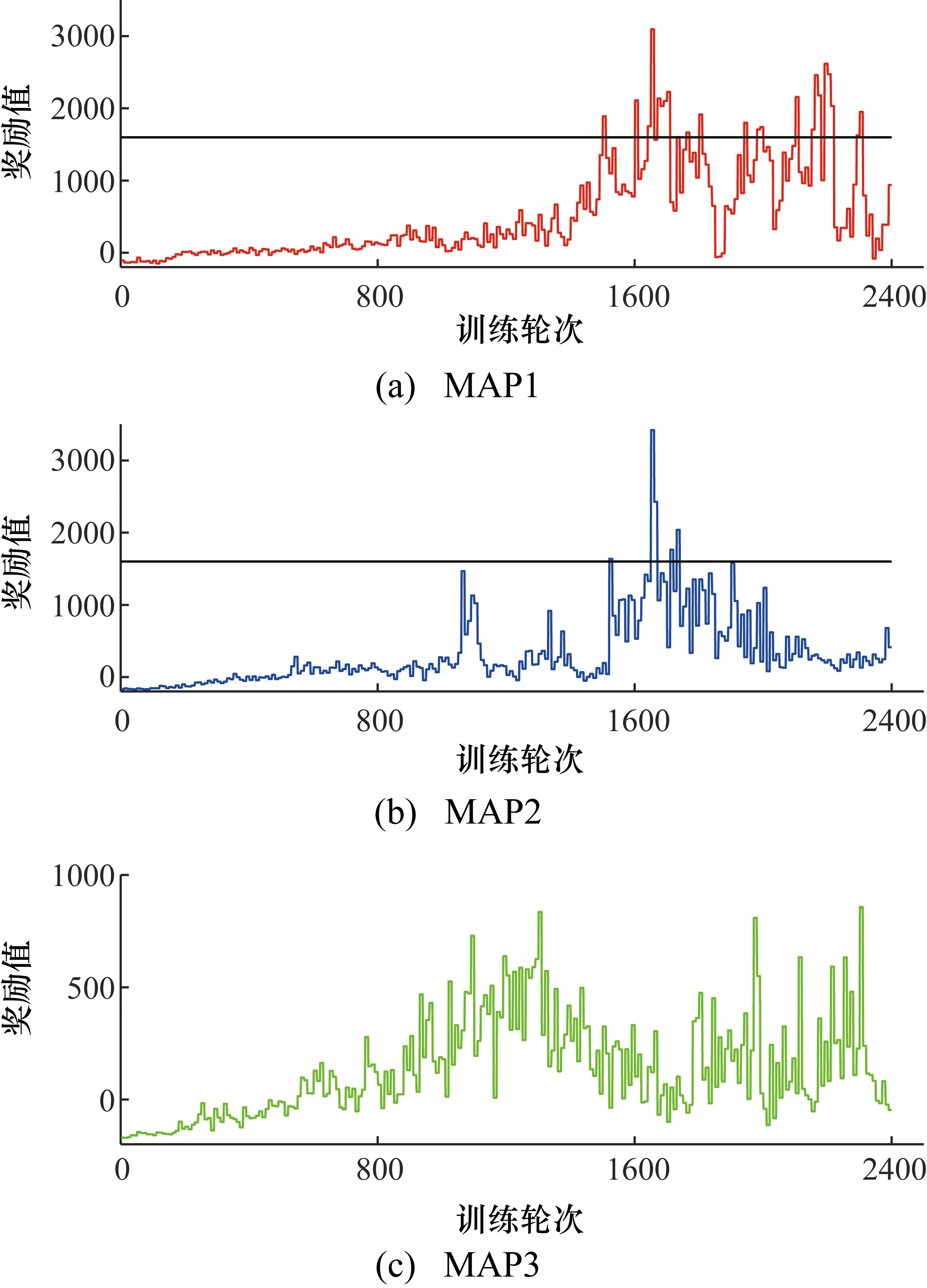
图4 Q-Learning算法在3张地图下的训练结果
MAP1到MAP3地图复杂度递增。分析图4可以得出,使用Q-Learning算法时,模型车在MAP1中的奖励值最高,能顺利行驶两圈的次数最多。而在MAP3中的奖励值最低,且平均奖励值未达到行驶两圈所需奖励值。这种现象与奖惩设置有紧密联系,直行的奖励值为5,大于左右转的奖励值1,故直行通道越多的地图获得的奖励值应该越高。实验现象与预期假设基本符合,得出如下结论:在直行奖励值大于左右转奖励值的情况下,Q-Learning算法往往在较为简单的地图中可以使模型车获得较高的奖励值。
Sarsa算法在不同地图中的表现如图5所示。与Q-Learning算法相比,使用Sarsa算法时模型车在不同地图中奖励值的区分度更低,其行为更加平稳,训练完成后,奖励值保持在较高水平。在复杂度最高的MAP3中,平均奖励值也能达到行驶两圈的奖励值。实验表明Sarsa算法在复杂度较高的地图中表现更好。
Q-Learning算法及Sarsa算法等传统的强化学习算法都需要一张由状态S以及行为A组成的Q值表,当场景的状态过多即Q值表行数过多时,将导致Q值表难以维护。基于此,探究了DQN算法在不同地图中的表现,如图6所示。与前两种算法相比,使用DQN算法时模型车在同地图中的训练轮次与奖励有较大区别。DQN算法采用存储并随机采样经验来打破样本之间的相关性,避免优化目标随优化过程改变的问题。
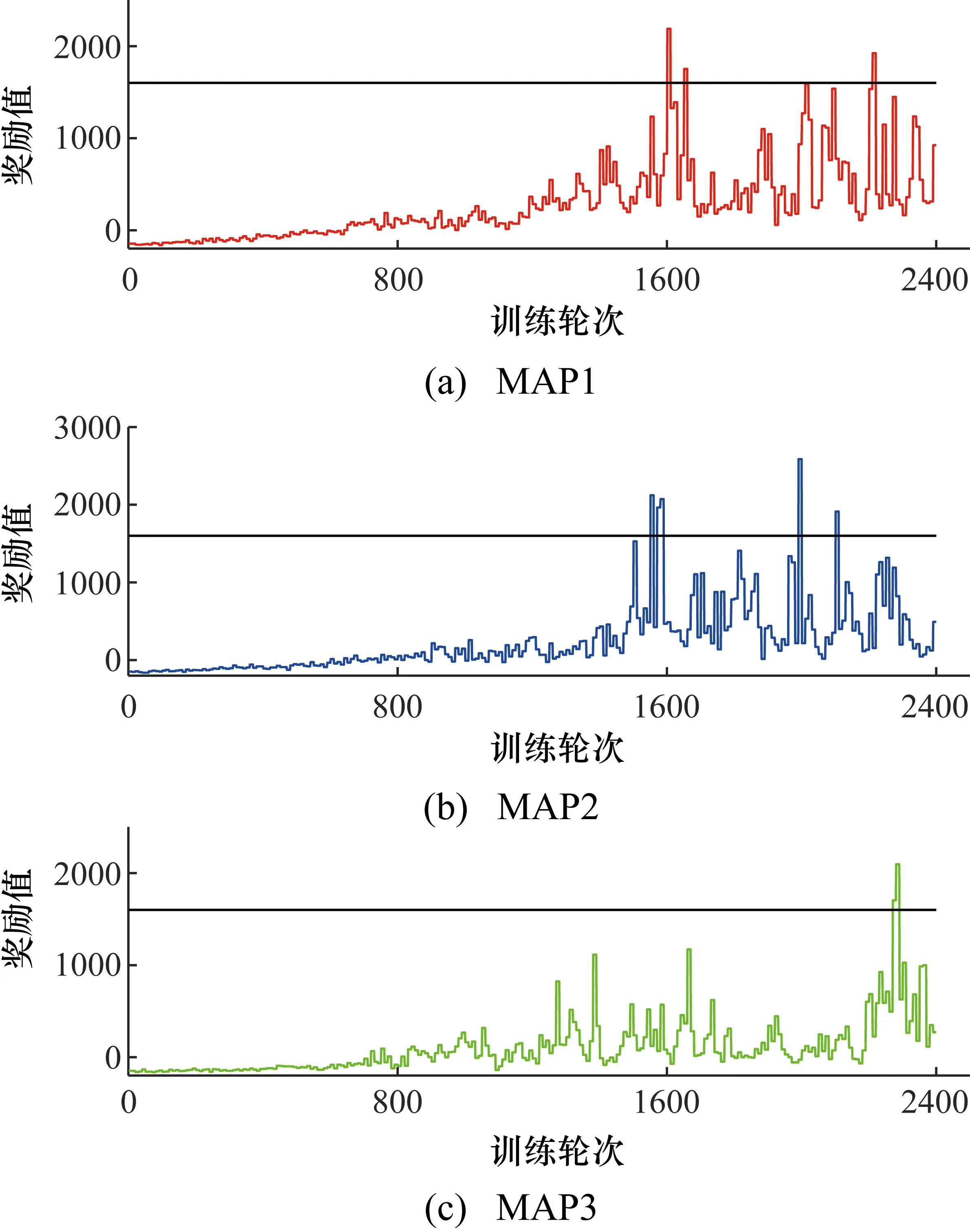
图5 Sarsa算法在3张地图下的训练结果
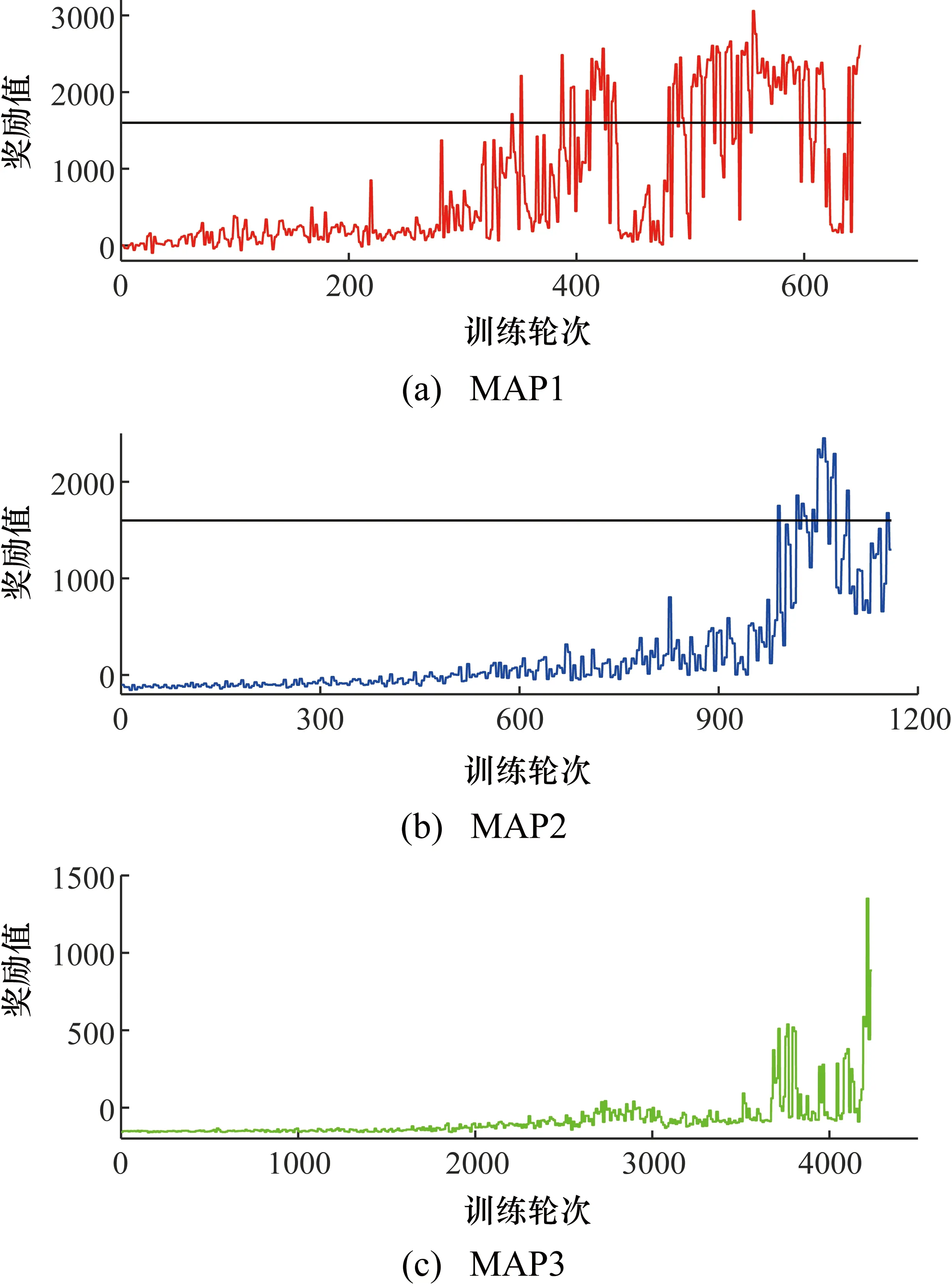
图6 DQN算法在3张地图下的训练结果
但是随着地图复杂度的提升,DQN算法的训练性能下降,训练轮次增加,其原因在于:地图越复杂,对运算处理能力要求越高,需要的训练量越大。但训练量足够大时,DQN算法在MAP3中也可以呈现出很强的收敛性与稳定性。
为了研究三种强化学习算法在同一环境中的表现,在同一地图中测量模型车的训练回合数和奖励值,并绘制相应图表(如图7、图8、图9所示)。可以得出,以模型车行驶两圈作为其训练成功的标志,Q-Learning算法可以更早地实现目标。

图7 MAP1中模型车的训练结果

图8 MAP2中模型车的训练结果

图9 MAP3中模型车的训练结果
这种现象是由于Q-Learning算法可以学习策略,同时更趋于冒险,即下一个状态的奖励值不一定用来更新Q值。即使在Q-Learning算法训练后期,也仍有一定几率去探索,因此训练后期仍有奖励值较低的情况发生。
由于Sarsa算法是一种在线学习算法,使用渐近贪心无限探索策略来更新Q值函数,因此任意时间模型车总有一定概率选择非最优的动作。其中碰撞墙壁的动作也始终有一定的概率被选中,并在Q值函数更新时被记录下来,Q值函数变成了越靠近墙壁,值越小的分布,最终实现Sarsa选择安全路径。将MAP1、MAP2、MAP3三幅地图的Q-Learning算法与Sarsa算法奖励值进行对比,在1400回合数之前Sarsa算法获得的平均奖励值要低于Q-Learning算法,1400回合数之后Sarsa算法获得平均奖励值要高于Q-Learning算法。Sarsa算法训练的速度要比Q-Learning算法速度快,训练完成后,比Q-Learning算法训练效果更好。这也验证了Sarsa算法在控制方面要优于Q-Learning算法。
DQN算法通过经验回放的方式,在过去多个状态下平均化数据分布,提高了训练过程的平滑度,避免了训练发散,提高了收敛性。因而在MAP1中DQN算法在330次训练回合后可以实现模型车无碰撞行驶地图两圈,收敛性远高于Q-Learning以及Sarsa算法。在经验回放中DQN算法采取随机均匀采样,每一步的数据都可以被多次采样,并且随机采样打破了样本之间的相关性,降低了参数更新的方差,提高了算法的稳定性。因而在MAP1、MAP2中一次训练成功后,模型车就可以在之后的训练中有更大的几率训练合格,稳定性也高于Q-Learning和Sarsa算法。
本文选取了三种基于价值的强化学习算法进行研究,相比于基于概率的算法,基于价值的算法决策部分更明确,总是选择价值最高的,收敛速度更快。在明确某个状态执行某个动作价值更高的情况下,尤其是出于对时间的要求,将直行的奖励设置为高于转弯时,使用基于价值的算法更为合适。同时,本实验状态设置较多,使用单步更新的算法更节省计算资源。因此,本文将该三种基于价值的算法在不同环境下的效果作为测试验证对象,以验证平台的有效性。
5 结束语
本文搭建了用于不同环境下的强化学习算法仿真的小车平台,提供了一种快捷的平台环境仿真解决方案。对Q-Learning、Sarsa和DQN三大主流算法的有效性与鲁棒性进行了测试验证。得出以下结论:
① 在传统的强化学习方法中,Sarsa算法的稳定性与自适应性更佳,随着地图复杂度的提高,Sarsa算法仍可以取得较好的结果;而Q-Learning算法往往在较为简单的地图中可以使模型车获得较高的奖励值。
② Sarsa算法训练的速度要比Q-Learning算法快,训练完成后比Q-Learning算法训练效果更好。这验证了Sarsa算法在控制方面优于Q-Learning算法。
③ DQN算法的收敛性与鲁棒性优于Q-Learning和Sarsa算法。
猜你喜欢
新世纪智能(数学备考)(2021年9期)2021-11-24
中学生数理化·中考版(2021年3期)2021-07-22
新世纪智能(数学备考)(2020年9期)2021-01-04
中学生数理化(高中版.高考数学)(2020年9期)2020-10-28
小学生作文(低年级适用)(2019年5期)2019-07-26
中国惯性技术学报(2019年6期)2019-03-04
读友·少年文学(清雅版)(2018年12期)2018-04-04
中央民族大学学报(自然科学版)(2017年2期)2017-06-11
山东青年(2016年3期)2016-02-28
火控雷达技术(2016年3期)2016-02-06
