
Improving RGB-D SLAMthrough extracting static region using delaunay triangle mesh
2020-01-08 10:16ZHANGXiaoguoZHENGBingqingLIUQihanWANGQinYANGYuanSchoolofInstrumentScienceandEngineeringSoutheastUniversityNanjing210000China
中国惯性技术学报 2019年5期
ZHANG Xiaoguo,ZHENG Bingqing,LIU Qihan,WANG Qin,YANG Yuan(School of Instrument Science and Engineering,Southeast University,Nanjing 210000,China)
Abstract:To solve the problem of simultaneous localization and mapping (SLAM) in the dynamic environment of robotics navigation,a real-time RGB-D SLAM approach that can robustly handle high-dynamic environments is proposed.A novel static region extraction method is used to segment the dynamic objects from the static background,and the feature points in the static region are integrated into the RANSAC method to estimate the camera trajectory.The dynamic entities are identified and isolated by discarding the edges in the Delaunay triangle mesh of current frame according to distance-consistency principle in a rigid body.Combined with the weighted Bag-of-Words method,the system accuracy is further improved by reducing the weight of the dynamic object in the dynamic scene.Experimental results demonstrate that,compared with the existing real-time SLAM method,the proposed method improves the accuracy by 81.37% in the high-dynamic sequences of the TUM RGB-D datasets,which significantly improve the accuracy of navigation and positioning of mobile robots in dynamic scenes.
Key words:SLAM; dynamic environments; static region extraction; Delaunay triangulation; loop detection
In recent years,the approaches pertaining to Visual Simultaneous Localization and Mapping (VSLAM) have been developed significantly.The state-of-the-art methods[1-4]are now capable of running the application in real-time with robust performance.To simplify the problem formulation,most of these SLAM systems assume that the environment under observation is static,i.e.none of the observable objects in scenes proposes any change in their dynamics or shapes.However,dynamic objects,such as human beings and vehicles,exist in real environments.Assuming that everything is static in a dynamic environment,this will lead to the deterioration of the whole SLAM process due to data association errors,failures in loop closure procedure,and erroneous state estimations[5].Therefore,the SLAM in dynamic environments has attracted attention of many researchers in the past several years.
Most existing SLAM methods can be roughly categorized into two groups:sparse system and dense system.To handle dynamic objects,different strategies are used for these two groups.Sparse SLAM[2,4,6],as the most widely-used formulation,estimates 3D geometry from a set of keypoint-matches,then the camera’s egomotion is obtained using closed-form solution from the correspondences.Since the points from the static environment follow the same motion,RANSAC (Random Sample Consensus) regression is usually used to filter out dynamic objects in these systems[7-8].Davison[9]introduced a real-time camera tracking system known as monoSLAM (monocular Simultaneously Localization and Mapping),which used an extended Kalman filter (EKF)to estimate the camera pose.Later in [10-11],Meilland and Newcombe maintained the assumption that the underlying environment is stationary and suggested to discard the dynamic element points by considering them outliers to the systems.However,RANSAC algorithm lacks robustness in high-dynamic environments and can result in accuracy reduced when the active feature points exceed the static ones[12].To improve the system’s robustness in dynamic environments,Masoud[5]used multilevel-RANSAC (ML-RANSAC) algorithm to detect and classify objects into stationary and moving objects,however,the use of Lidars limits its versatility.Kang[13]proposed a rotation-translation decoupling algorithm,applying “far point” to estimate the orientation of the visual system,while the “near point” is used to estimate the translation of the camera under RANSAC framework.The system can reduce the impact of the nearby moving objects on the visual odometry,but the translation estimation can be contaminated by dynamic objects.Azartash[14]used an image segmentation method to separate the moving part of the scene from the stationary part,performing motion estimations per segment then optimizing the motion parameters by minimizing the remaining error using the motion parameters of each segment,but it takes too much time in segmentation,which hinders the real-time applicability.
The dense SLAM estimates 3D geometry in conjunction with a dense,regularized optical flow field,thereby combining a geometric error (deviation from the flow field) with a geometry prior (smoothness of the flow field)[1,3].To improve the precision of the system,dynamic objects need to be found and excluded from the geometric optimization process.Zollhofer[15]proposed to reconstruct a non-rigid deforming object in real time with a single RGB-D camera,and the non-rigid registration of RGB-D data to the template is performed using an extended non-linear As Rigid As Possible (ARAP) framework by implementing on an efficient GPU pipeline.Unfortunately,it requires an initial static model/template of the body that is later tracked and reconstructed,and the template is then deformed over time based on the rigid registration and non-rigid fitting of points.Sun[16]used an intensity difference image to identify the boundaries of dynamic objects,then dense dynamic points are segmented using the quantized depth image.These methods[14-16]achieve stable performance in highly dynamic scenes,but as mentioned before it takes too much time in segmentation and it can hardly run in real-time.Keller[17]proposed a point-based fusion approach to reconstruct a dynamic scene in real-time,and the approach considers outliers from the iterative closest point (ICP)as possible dynamic points and assigns a confidence value which later determines if the point is static or dynamic.The dynamic points are used as seeds for region growing method in order to segment the entire dynamic object in its corresponding depth map.This kind of implementation is proved to work effectively in indoor environments[14,16-17],but also limits its application in a small space and suffers from computation cost.Kim[18]proposed to use depth difference to multiple warped previous frames to calculate a static background model,but when the dynamic object moves parallel to the image plane,only the boundary of dynamic object can be found due to the aperture problem[12].
To compensate dynamic objects in systems,all above mentioned methods require a correspondence matching step,where either a dense or sparse correspondence is needed.While accurate dense correspondences matching is time consuming[14,16-17],approximation[18]suffers from the aperture problem,and pretrained model[15]cannot be applied in large scenes.Accurate matching of 2D keypoints can be performed in real-time[7-8],but sparse 2D keypoints could be distributed unevenly in the environment.If a dynamic object has many textures or the dynamic keypoints outnumber static keypoints,the RANSAC regression could easily fail especially when dynamic objects move in rigid-motion for many inappropriate matches will be applied in estimation.In this paper,we use a distance-preserving principle[19]to identify dynamic objects from static background,i.e.the distance between two features in a rigid body motions should maintain their distance throughout the runtime.Furthermore,through integrating an efficient loop closure detection procedure into the system,we achieve a real-time RGB-D SLAM system that can handle dynamic environment efficiently.
The main contributions of this paper are:
1.A novel efficient static-region extraction method is proposed to segment the dynamic objects from the static background.It calculates the maximum clique of the triangle mesh in the current frame,which is constructed according to the distance-preservation principle in the 3D rigid motion.
2.A weighted Bag-of-Words method is performed to decrease the influence of the dynamic objects in loop detecting,which degrades the moving points while upgrades the static feature points according to the extracted static region in frames.
The effectiveness of this method against dynamic objects is tested on dynamic sequences from TUM RGB-D dataset.The proposed method can greatly reduce the tracking error and outperforms the state-of-the-art SLAM systems in most dynamic sequences.
1 Framework
The overview of the system is illustrated in Fig.1.Similar to ORB-SLAM2[2],three threads are incorporated in parallel:tracking,local mapping and loop closure,to simultaneously estimate the scene structure and camera motion (6 DOF) without any prior knowledge of the scene.The tracking thread is to localize the camera with every frame,the local mapping to manage the local map and optimize it,and the loop closure to detect large loops and correct the accumulated drift.Different from ORB-SLAM,only the matched feature points distributed in the static background are applied to track camera by minimizing the reprojection error defined between two static point sets.Furthermore,a weighted Bag-of-Words(BoW) method is performed to decrease the influence of the dynamic objects in loop detecting,integrating the point-weight adjustment strategy into the original BoW method to generate more appropriate visual words.
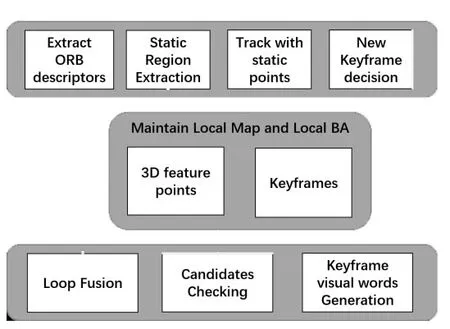
Fig.1 Framework of the proposed RGB-D system
We first initialize the structure and motion with the first frame,which is also the first keyframe,and set its pose to the origin and create an initial map from all its keypoints.Then the camera is tracked and the pose is optimized in every frame with improved RANSAC method,combining with static-region extraction algorithm; after that,a keyframe is set if the current frame satisfies the following conditions:1) the current pose is estimated successfully; 2) the current frame tracks less than 80% points than the existing keyframe; 3) the current frame can contribute more than 40 new points.A covisibility graph is maintained in the system to optimize the reconstructed map and the camera trajectory in a local covisible area.Meanwhile,loop closure is integrated to compensate the drift with the partial BoW representation,and the visual words of keyframes are compared and several tests are executed to make a correct loop,then the global bundle adjustment is performed to achieve global consistency.
2 Methods
2.1 Tracking with static region extraction method
The overview of the proposed static region extraction method is illustrated in Fig.2.For each incoming frame,firstly a group of matched points is obtained with the latest keyframe in BoW acceleration matching process; then the Delaunay triangle mesh is constructed where each pair of matched features is a vertex,and an edge is formed between two such pairs of matched features; after that,the distance consistency check is performed to decide whether to keep the edges in mesh or not,which depends on the difference of 3D distances between the features from the current frame to the keyframe;lastly the maximal clique of remaining mesh is extracted according to hybrid principle.
After the maximal clique is extracted,the relative transformation from the keyframe to the current frame is estimated using PnP algorithm with RANSAC method,where only the static points in the maximal clique are combined in order to reduce the effect of dynamic objects on the transformation estimation.Furthermore,the static weights of points for the keyframe are updated based on the estimated motion,and more accurate pose is obtained by the bundle adjustment operation in a local area.

Fig.2 Flow chart of the static region extraction algorithm
2.1.1 Delaunay triangulation with distance consistency test
The proposed system has embedded a bag-of-words place recognition module[2]based on DBoW2 with improvement of point-weight adjustment strategy,which not only detects loop and decrease the accumulated drift but also accelerates the matching process in tracking thread.When adding an image to the system after initialization,we store a list of pairs of nodes and features in the direct index of the feature words.To obtain correspondences between current frame and the keyframe,we look it up in the direct index and perform the comparison only between those features associated with the same nodes in the vocabulary tree instead of the exhaustive brute search.
LetVbe the set of the distinct points in the Euclidean camera plane of current frame,the elements of which are matched properly with the keyframe in the previous matching process; and letEbe the set of edges between vertices inV.A triangulation ofVis a planar straight-line graphG(V,E') for whichE'is a maximal subset ofEsuch that no two edges ofE'properly intersect,which means no two edges inE'intersect at a point other than their endpoints.The Delaunay triangulations are constructed in camera plane,which maximize the minimum angle of all the angles of the triangles in the triangulation,thus showing good performance in the distance relations of map points.In this paper,the divide-and-conquer algorithm is used to construct the triangulation and it can run in real-time[20].
GivenE'in the current frame,and given the set of edges in graphGin the previous process,we check the distance consistency of two endpoints for every edge inE'and determine whether to discard it or not.This principle is motivated by the maximum clique method from Howard,but we improve it for considering the distance relationship of inliers while determining the best hypothesis.Note that the Mahalanobis distance is used instead of normal Euclidean distance here,and the mathematic model is described in Section 2.1.3.
We compare the 3D distance of two feature points in the current frame with that of the two matched points in the keyframe.According to the fact that rigid body motions are distance-preserving operations,which means the distance between two features should remain their distance throughout the runtime.Thus,the edge is kept if the 3D distance between the features does not change substantially from the keyframe to the current frame.Furthermore,we check the distance difference between frames and delete the edge if the difference above the threshold.Finally,the set of static inliers makes up the graphG(V',E''),whereE''represents the set of remaining edges,andV'represents all endpoints inE''in graphG.

Algorithm 1:Distance consistency check for current frame Input:- a set of edges between vertices in V.- a target cloud Ptgt and a matched-feature pointset of current frame Btgt.- a source cloud of keyframe Psrc.- corresponding feature points index for source cloud {c(i)}i∈Btgt Output:- a graph G(V',E'')set V',E'' empty.for every line in E' do Find the indexes of the two endpoints p1, p2, and name it i and j in Btgt respectively.Calculate 3D distance d1 between P(i)tgt and P(j)tgt and calculate 3D distance d2 between P(c(i))src and P(c(j))src Calculate the absolute value Δd of the difference of d1 and d2 if Δd < thershold Push current line into E''Push p1, p2 into V'end if end for
2.1.2 Region extraction principle
Given a graphG(V',E''),some pairs of matched features across frames form vertexes in the graph,and edges are between two such pairs of matched feature if the 3D distance between the features satisfy the aforementioned condition.In Fig.3,the current frame contains two dynamic objects,with one moving left and the other moving down-right.The solid lines in Fig.3 represent the lines whose distance remains under the threshold,while the dotted lines do not.Only points in {P1’,P2’} belongs to static background,while
To get the optimal group,all groups are obtained and the boundary lines of the mesh are regenerated for each group to avoid the incomplete shape,and then we calculate the number of feature points and the corresponding area of Delaunay triangulation mesh of each group.We compute score for each group in Eq.(1),and choose the best one group and use members of this group to track the camera.
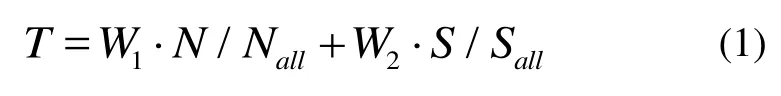
where W1and W2are the weights of the number of pointsNand the corresponding projected areaSof the mesh in graph (W1and W2are set to 0.5 and 1 respectively),and Nalland Sallare total number of feature points and gross mesh area in graphG,respectively.
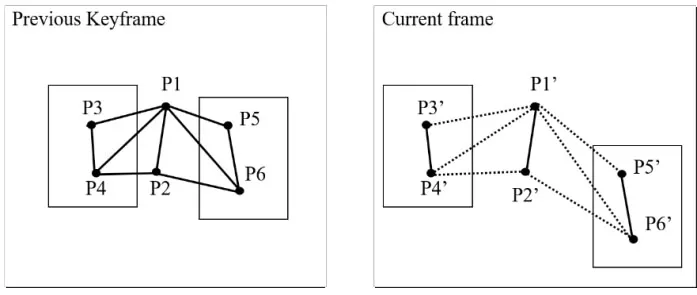
Fig.3 An example of the edges distance consistency
This hybrid principle is based on the observation that the static background features usually distribute evenly,whereas the dynamic foreground points may aggregate in a few small textured areas,so we consider not only the points number but also the area while determining the best hypothesis.Furthermore,a coarse-to-fine strategy is implemented in the process:an initial camera pose is calculated for each group,and those groups with similar poses and a close distance are combined into a bigger one,which is a clustering process and the system keeps on clustering until no two groups are eligible.This strategy avoids the universal low scores in static background due to the isolated small groups.Some experimental screenshots are showed in Fig.4 in the TUM RGB-D dataset“fr3/walking-static”.
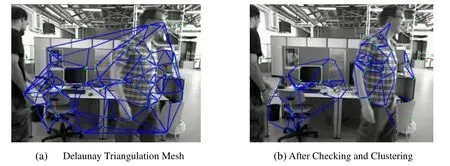
Fig.4 Two screenshots after the Delaunay Triangulation operation and after Distance checking and Clustering operations in the TUM RGB-D dataset“fr3/walking-static”.(a) The frame after the Delaunay triangular mesh construction operation (The edges of the mesh represent the connection relationship of two points,and some points cannot meet the requirements of the depth uncertainty so they are isolated); (b) The frame after distance-consistence checking and clustering operations (The points in the frame are typically grouped as two groups,the members of the first group are in the static background,and the other group in the moving person)
2.1.3 Distance uncertainty model
In the distance measurement of an RGB-D system,the uncertainty of 3D points must be considered due to some incorrect measurements like in boundaries.The Mahalanobis distance is used instead of normal Euclidean distance and the distance between two feature points is defined as:
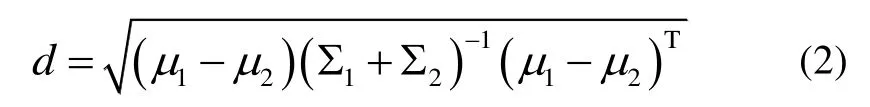
Modelling is combined into the formula to obtain accurate uncertainty of the depth measurement,for the depth measurement of pixels are influenced by each other.The representation of depth is improved,which is considered as independent Gaussian distribution random variable,and its variance is as:
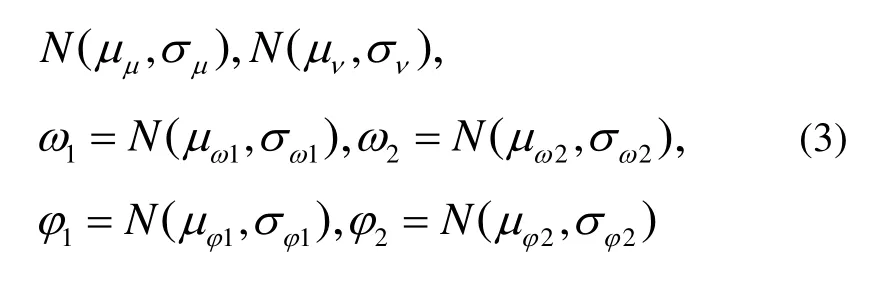
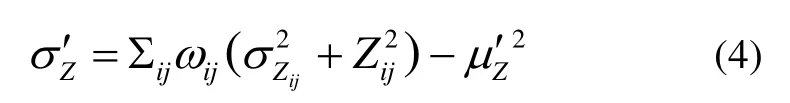
To extend the applicability of the proposed method,we give the corresponding parameters in stereo system here.The fundamental model in stereo system is similar to RGB-D,which means the definitions of d and Σ′are the same,while the difference lies in the source of error:the error terms of stereo system are mainly from the calibration deviation of angle from baseline to optical axis,and the field angle instead of the measurement error is from infrared speckle technology in RGB-D.It is assumed that the horizontal and vertical fields of view parameters are independent Gaussian random variables:
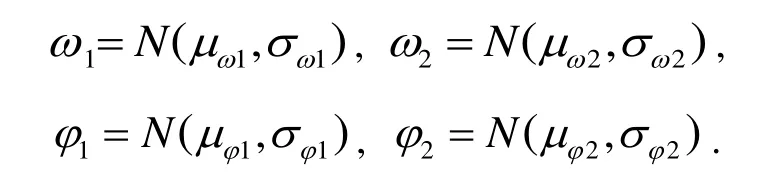
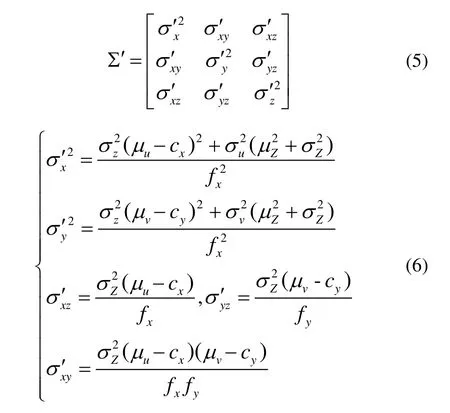
where ω and φ represent the horizontal and the vertical fields of view respectively.The variance parameters in stereo system are:
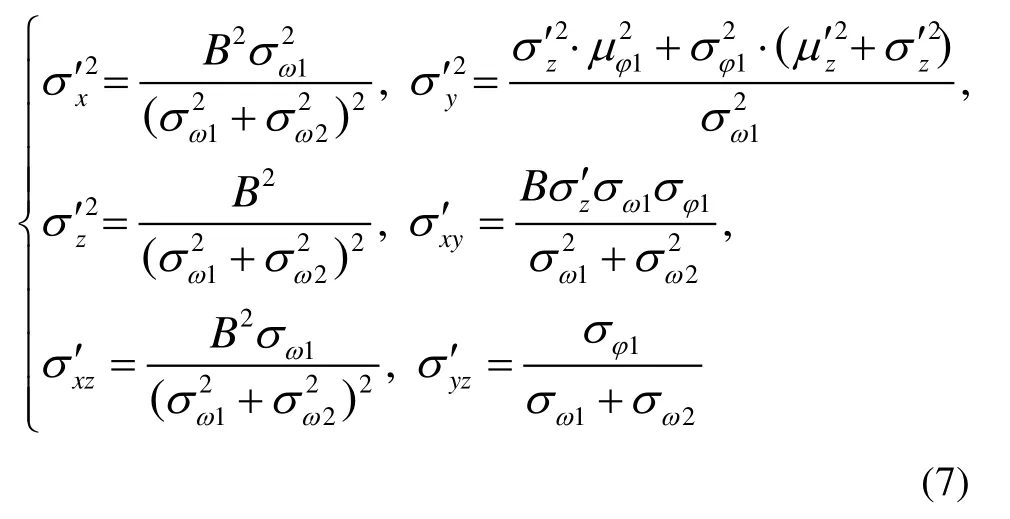
whereBis the baseline,σω1and σω2are the standard deviations of horizontal field angle,σφ1and σφ2are the standard deviations of vertical field angle,and it is assumed that the relative pose of the cameras in the stereo system is an invariant.
2.2 Loop closure with weighted descriptors
A pure visual odometry system usually suffers from drift problem because current absolute pose is obtained by accumulating previous ego-motion estimates,which accumulates the estimation errors.To compensate the drift problem in dynamic environments,the point-weight adjustment strategy is integrated into the Bag-of-words method in the proposed system,and we use the points which are more likely to be static to generate visual words.Before setting a new keyframe,the visual word vtof current keyframe Ktis formally described in descriptor space,which is a set of ORB descriptors generated in tracking thread.Note that only the qualified feature points are used,whose weights are above the static threshold,to generate visual words in the keyframes and the point-weight adjustment procedure is provided in algorithm 2 (θ in algorithm 2 and the static threshold are set to 0.1 and 1 respectively,and the wisrcis 1 originally).Then the new keyframe is set and loop closure is checked with a covisibility graph.A loop closure is detected between Ktand Kt1when the following conditions are fulfilled.
1) Covisibility:we query the keyframe database which stores the visual words of each keyframe,resulting in a list of matching candidates 〈vt,vt1〉,〈vt,vt2〉,…associated with their scores.We save candidates whose scores are above smin,which is from the lowest score of the neighbors of Ktin the covisibility graph,and those candidates directly connected to Ktare discarded.This method gives a good trade-off between the computation cost and the correctness.The consecutive frames in candidates are pushed into the same group,and the one with the highest score is chose from each group and the others are discarded.
2) Temporal consistency:this step checks the temporal consistency of previous queries.One match 〈vt,vt1〉must be consistent with thekprevious matches (kis set to 5 in experiments),which means s(vt-Δt,vt1-Δt),…,s(vt-kΔt,vt1-kΔt) must be above the threshold(smin* 0.8).
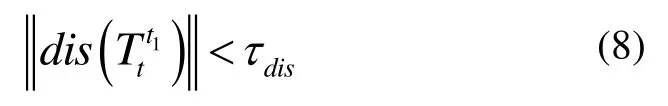
3) Geometric consistency:this step ensures two candidate matching keyframes not be too far away from each other:wheredis(T) extracts the translation vector from the transformation matrixT,and τdisis set to 1.5 m and 3 m in indoor and outdoor environments respectively.
If the keyframe pair 〈Kt,Kt1〉 satisfies all these conditions,a new relative pose constraint between them is generated,which means a new loop is detected.Then the loop fusion module is activated to correct the trajectory as in [2].

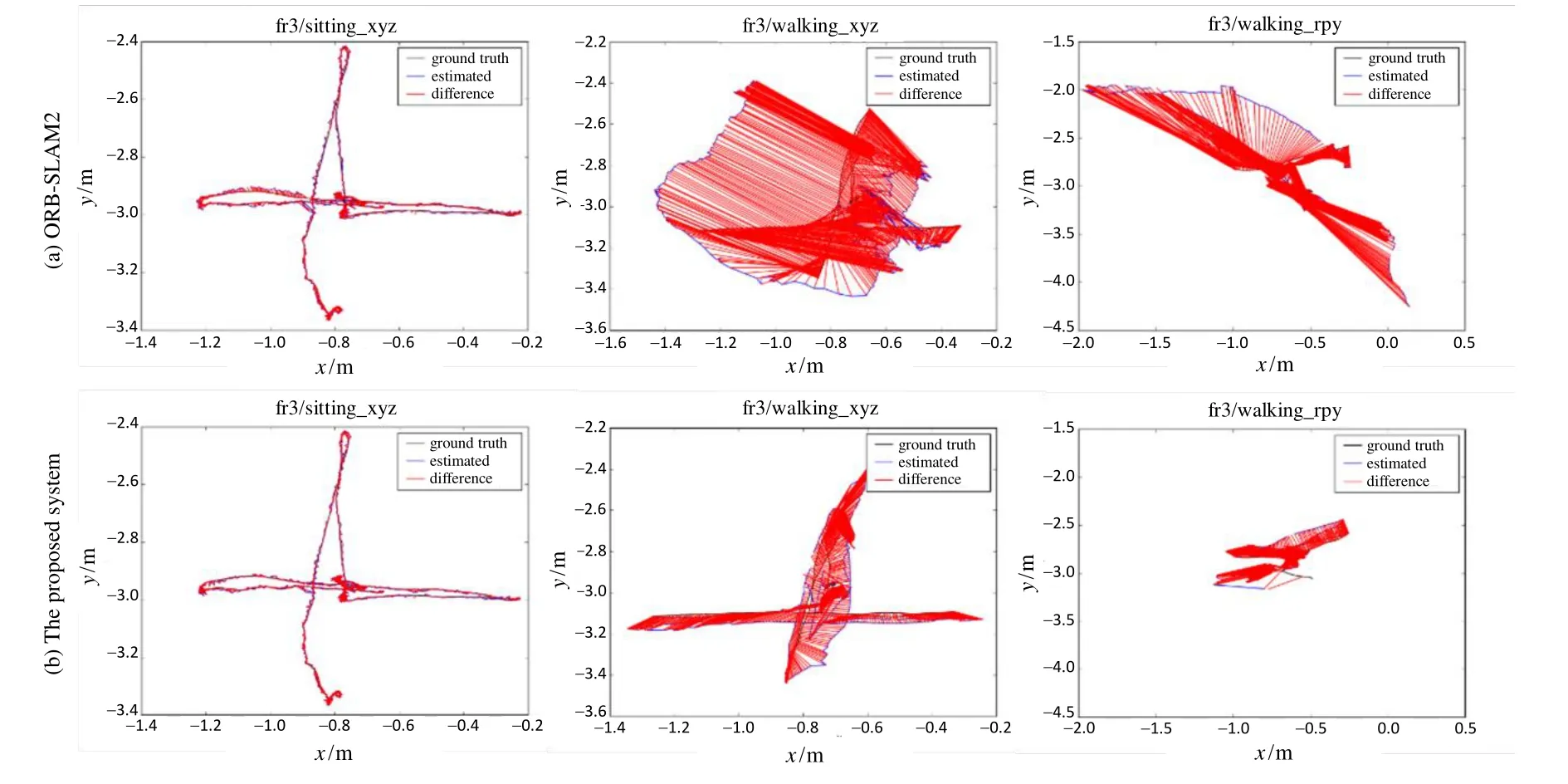
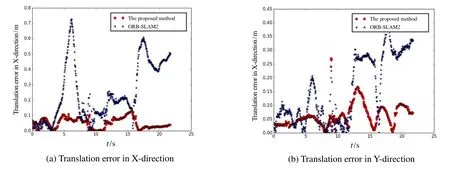
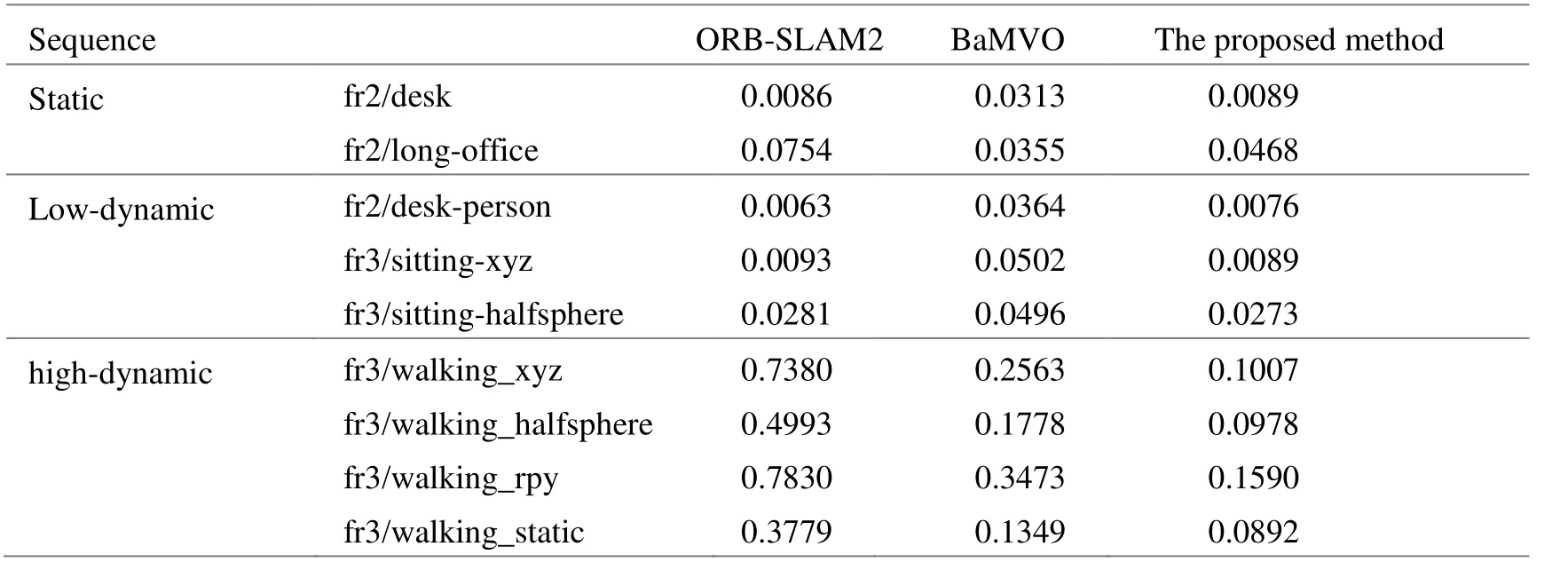
Algorithm 2:Point-weight adjustment procedure Input:- a source cloud of keyframe Psrc- N groups of target cloud Ptgt j and matched-feature point sets Btgt j from every frame correspond to keyframe in tracking thread (0 The whole system is tested with TUM RGB-D dataset.To test the performance of the proposed method in different environments,various kinds of sequences are used,not only the sequences captured in static environment,but also the low-dynamic sequences and high-dynamic sequences.In high-dynamic sequences,more than half of the images are occupied with dynamic objects and dynamic parts account for more than 30% of the picture.In these sequences,people in scenes move in the environment randomly,while the camera also moves with different patterns (static,xyz,rpy and halfsphere).All the experiments are performed on a desktop computer with Intel Core i7-7700HQ CPU (2.8GHz) and 32 GB RAM. PnP and RANSAC methods are used to estimate the camera pose when tracking the current frame,and the callation of the iteration timeskin RANSAC is as follows: whereprepresents the confidence probability,rrepresents the inlier ratio,andNis the number of points in the calculation.We set the confidence probabilitypto 0.99,and we assignr’(the inlier ratio in the last frame)torinitially.In the coarse-to-fine process of the static region extraction algorithm,we firstly perform 3ktimes of iterations in the initial pose estimation,then we combine the eligible group pair which satisfies the following conditions:1) The two groups have similar initial pose estimations.We obtain the pose results of every group and compute the absolute errors of every pair.Those below one-fifth of the maximal error are regarded as similar pose results.2) The two groups are distance-close to each other. The minimal boundary distances of every pair are calculated in the pixel plane and those below 10 pixels are considered to be distance-close in a typical 640×480 frame.The clustering process is performed until no two groups are eligible.Lastly,the static points in the extracted region are used to calculate the camera trajectory,with 10ktimes of iterations in the RANSAC process to ensure accurate results.Furthermore,we recommend setting the distance difference threshold in distance-consistency-check 0.1 m and 0.5 m in indoor and outdoor sequences respectively to have best effect.The parameters can be adjusted dynamically for different application environments. Absolute Trajectory Error (ATE) metric is used to evaluate the system.We compare the results with ORBSLAM2[2]and BaMVO[18].ORB-SLAM2 is a state-ofthe-art SLAM method for static environment,which can only handle small number of dynamic objects.BaMVO is specially designed to handle RGB-D dynamic environments. The improvements are achieved in the proposed system by:using static-region extraction method to find correct correspondences efficiently,where a higher correct ratio results in more accurate transformation estimation; then using these correspondences,the static weighting strategy can reduce the influence of dynamic objects in loop closure.Compared with the proposed method,ORB-SLAM2 takes the static environment assumption in formulation and cannot perform normally in highly dynamic sequences.And the points on the same image coordinate are simply approximated as correspondence in BaMVO,causing transformation estimation error. The comparison results are shown in Table 1,showing that the proposed method outperforms the other two systems in almost all dynamic sequences,especially in the high-dynamic environments.The improvement for high-dynamic sequences is 81.37% compared with ORBSLAM2,and by 51.25% compared with BaMVO.To get further detailed effect of the proposed system,the estimated trajectories are compared with ground truth,and some results are shown in Fig.5 and Fig.6. Fig.5 Some results of the estimated trajectories from ORB-SLAM2 and the proposed system Fig.6 Translation error comparisons between ORB-SLAM2 and the proposed method in “fr3/walking_xyz” Tab.1 RMSE comparison of absolute trajectory error in the TUM RGB-D benchmark In the first row of Fig.5,the trajectories are estimated in ORB-SLAM; and in the second row of Fig.5,the trajectories are estimated with the proposed strategy.It is notable that for the low-dynamic sequence “fr3/sitting_xyz”,the improvement of the proposed system is small,but for high-dynamic sequences,the trajectory error is reduced greatly.We compare the quantitative translation error in Fig.6 from the sequence “fr3/walking_xyz”,where the blue star symbol represents the ORBSLAM2 and the red round symbol represents the proposed method in Fig.6.It can be seen in Fig.6 that the proposed system has more stable and accurate performance than ORB-SLAM2 in this high-dynamic sequence. With multi-thread programming,the frame rate of the proposed system can be around 36 fps,including loop closure and visual odometry estimation,so the system satisfies the requirement of real-time running. In this paper,we present a real-time RGB-D SLAM system that is able to handle highly dynamic environments robustly.The system uses a static region extraction method to segment the dynamic objects from the static background,and the feature points in the static region are integrated into the RANSAC algorithm to estimate the camera trajectory.Furthermore,an improved Bag-of-Words method is performed to detect loops in even highdynamic scenes,compensating the accumulated drift.The proposed method is evaluated using the dynamic sequences from TUM Dataset.Compared with state-ofthe-art real-time methods,in terms of absolute trajectory error per second,the proposed method improves the accuracy by 81.37% in challenging sequences. In future work,we want to investigate how to deal with possible failures in featureless environments and how to provide more accurate camera poses when the dynamic foreground points aggregate in a few small textured areas.A preliminary scheme is to combining direct method with the feature points method in tracking thread and integrating semantic information into the system,which can provide more analyzable scene information and discriminate the entire dynamic object.Furthermore,we want to extend our principle to stereo systems with corresponding parameters we already provide. Acknowledgments:The authors would like to thank the support from Jiangsu Overseas Visiting Scholar Program for University Prominent Young & Middle-aged Teachers and Presidents.3 Experiments
3.1 Parameters setting
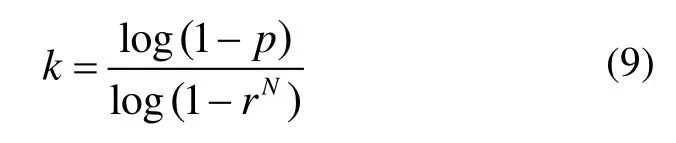
3.2 Contrast experiments
4 Conclusions
