
复杂场景下基于R-FCN的小人脸检测研究
2020-01-06 02:16降爱莲
计算机工程与应用 2020年1期
李 静,降爱莲
太原理工大学 信息与计算机学院,山西 晋中030600
1 引言
目前,人脸检测[1]在面部相关应用系统中起着非常重要的作用。尽管近年来已取得巨大进步,但人脸检测技术上的挑战依然存在。如图1所示,人脸因种种影响因素变化很大,包括面部部分的遮挡、不同的尺度、光照条件、不同的姿势、丰富的表情等。最近,基于区域方法的成功,推动了目标检测的发展。典型算法中Fast/Faster R-CNN[2-3]是基于R-CNN[4]的算法,以在感兴趣的区域内进行区域检测的方式实现检测。但是,直接将区域特定操作的策略应用到完全卷积的网络中,比如残差网络ResNet[5],由于分类精度高,最终导致检测性能较差。

图1 复杂场景下的多个人脸图像示意图
基于此,本文基于R-FCN[6]框架,引入Squeeze-and-Excitation模块[7],使得能够显式地建模特征通道之间的相互依赖关系,且不需要引入新的函数或者层,最终在模型和计算复杂度上具有良好的特性。
通过查阅文献,发现近期关于人脸检测的研究进展,大多集中于使用深层卷积神经网络。当图像出现复杂场景及较大的外观变化时,需要被不同类型的注意力机制关注。在注意力机制和人脸检测研究进展的启发下,本文在全卷积网络结构中引入了残差注意力机制。
2 相关工作
本文研究了复杂场景下基于R-FCN的小人脸检测算法,通过文献调研将相关工作组织成如下三个部分:
在过去几年里,人脸检测已经得到广泛的研究。Viola 和Jones[8]发明了一个使用Haar-like 特征的级联AdaBoost 人脸检测算法,在那之后,大量的工作集中在发展更高级的特征和更强的分类算法。文献[9]开发了一个多任务训练算法,共同学习人脸检测和校准。文献[10-11]使用基于Faster R-CNN 算法,提高了人脸检测算法的性能。文献[12]探索了人脸的上下文信息,并提出一种实现高性能检测小脸的算法。
现阶段,人脸检测方面的进展主要得益于强大的深度学习方法。基于卷积神经网络CNN的目标检测算法在人脸检测方面取得了很大发展,典型的算法中R-FCN是以一种完全卷积的方式实现检测,该算法大大提高了训练和测试的效率。
为了能有效检测到小人脸,近些年针对复杂场景下的人脸检测研究提出,从空间维度层面来提升网络的性能。但是,目前已很难再从空间维度层面来提升网络的性能。文献[7]提出网络可以从其他层面来提升性能,即研究特征通道之间的关系。文献[13]提出新的思路,即将深层卷积神经网络与人类视觉注意力机制相结合,应用到图像检测中。
本文基于以上研究,提出将文献[7]与文献[13]中的核心方法,即重新分配图像特征通道间的权重,以及特征图间的权重,共同融合到R-FCN算法中,用于复杂场景下的小人脸检测,取得了很好的效果。
3 提出的方法
本文从三个方面改进了针对人脸检测的R-FCN框架。首先,为了更精准的检测小脸,本文设置了更小尺寸的Anchors,并将位置敏感的感兴趣区域池化到更小的尺寸;其次,提出在主干网络ResNet 上引入Squeezeand-Excitation模块,显式地建立特征通道之间相互依赖的关系,并且自适应的重新校准通道的特征响应;最后,将深度卷积神经网络与人类视觉注意力机制进行有效的结合,引入了Residual Attention Network(残差注意力网络),使得不同层次的特征图能够捕捉图像中的多种响应结果。并且采用多尺度训练策略和Online Hard Example Mining(OHEM)技术对数据进行训练。
3.1 R-FCN框架
R-FCN最初用于目标检测,是一个基于区域的完全卷积网络。R-FCN主干网络为残差网络ResNet-101,从ResNet-101 输出的特征图中,RPN 根据Anchors 生成一系列的ROIs,这些ROIs进一步被输入到R-FCN模型的位置敏感RoI池化层中,并产生每一类的分数图和边界框的预测图。R-FCN 模型的最后两个全局平均池化层分别用于类分数图和边界框预测图,得到聚合类分数和边界框的预测。
本文采用R-FCN算法有两个主要优点:第一,位置敏感RoI 池化层巧妙地将位置信息编码到每个RoI 中,映射到输出分数地图的某个位置上;第二,将完全卷积网络ResNet 与基于区域的模块结合起来,使得R-FCN 的功能图更容易表达,也更容易学习类的分数和边界框。
为了提高检测准确率,更好的检测小目标人脸,本文基于R-FCN 列举了多个小尺寸的anchors,比如设置anchors_scales 为(16,32,64,128,256,512),这些小的anchors 对于有效捕捉小人脸是极其有帮助的。此外,在位置敏感的RoI 池化层设置了更小的pool_size 来减少冗余信息。
3.2 Squeeze-and-Excitation模块
在传统R-FCN 工作中,ResNet-101 体系结构主要用于特征提取。众所周知,ResNet 构建了一个极深的网络,将channel-wise 和spacial 信息一起提取到local receptive fields 里,得到了具有高度代表性的图像特征。但是,在此过程中,ResNet-101 忽略了图像特征通道之间的关系。在local receptive fields中,特征通道之间的关系是一个不确定因素,导致了图像中重要信息的丢失,因此,检测小的人脸时,出现误检或漏检的情况。
与传统R-FCN相比,本文在主干网络Resnet-101上引入了Squeeze-and-Excitation模块,使得能够显式地建模特征通道之间的相互依赖关系。另外,采用了一种全新的特征重标定策略。具体来说,就是通过学习的方式来自动获取到每个特征通道的重要程度,然后依照这个重要程度去加强有用的特征并抑制对当前任务用处不大的特征。
如图2 为Squeeze-and-Excitation 模块示意图。给定一个输入,其特征通道数为c1,通过一系列卷积等一般变换后得到一个特征通道数为c2的特征。与传统R-FCN不一样的是,本文通过三个操作来重标定前面得到的特征。
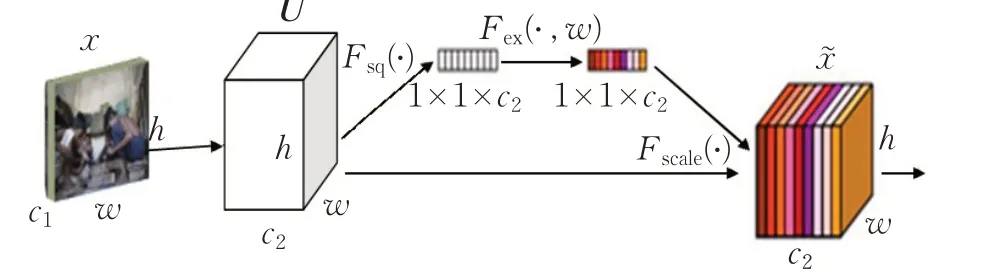
图2 Squeeze-and-Excitation模块
如图2 所示,X →U 的实现过程,一般就是CNN中的一些普通的操作,例如卷积或一组卷积,如公式(1)所示。

U 为图2中左边第二个三维矩阵,有c 个大小为的feature map。其中,vc表示第c 个卷积核,xs表示第s 个输入,uc表示u 中第c 个二维矩阵,下标c 表示channel数目。
如公式(2)所示,对应图2中的函数Fsq,即Squeeze操作,本文选择最简单的全局平均池化操作,顺着空间维度来进行特征压缩,对其每个feature map进行压缩,使c 个feature map 最后变成1×1×c 的实数数列,这个实数数列某种程度上具有全局感受野,并且输出的维度和输入的特征通道数相匹配。Squeeze操作得到在特征通道上响应的全局分布,使得网络低层也能利用全局信息。

如公式(3)所示,对应图2 中的函数Fex,即Excitation操作。学习参数W 来显式地建模特征通道间的相关性,通过参数W 来为每个特征通道生成权重。

通过引入两个1×1的conv层,一个是参数为W1的降维层,降维比例为r(本文设置r 为16),一个是参数为W2的升维层。其中,,δ 表示Relu 函数。最终得到维度为1×1×c 的结果s,用来刻画U中c 个feature map 的权重。其中,c 表示channel 数目。且s 是通过两个1×1 的conv 层和非线性层学习得到的。
如公式(4)所示,对应图2 中的函数Fscale,是一个重新加权的操作,将Excitation 输出的权重看作是特征选择后每个特征通道的重要性,然后通过Fscale函数将通道加权到先前特征上,完成在通道维度对原始特征的重标定。

其中,X=[x1,x2,…,xc],Fscale(uc,sc)为特征映射uc∈RW×H和标量sc之间的对应通道乘积。
Squeeze-and-Excitation 模块本质上引入了以输入为条件的动态特征,其有助于提高特征辨别力,使得网络模型更加敏感。
如图3 所示,通过原始残差模块和本文引入的SE-ResNet模块对比可以发现,本模块构造非常简单,而且很容易部署。
3.3 残差注意力网络
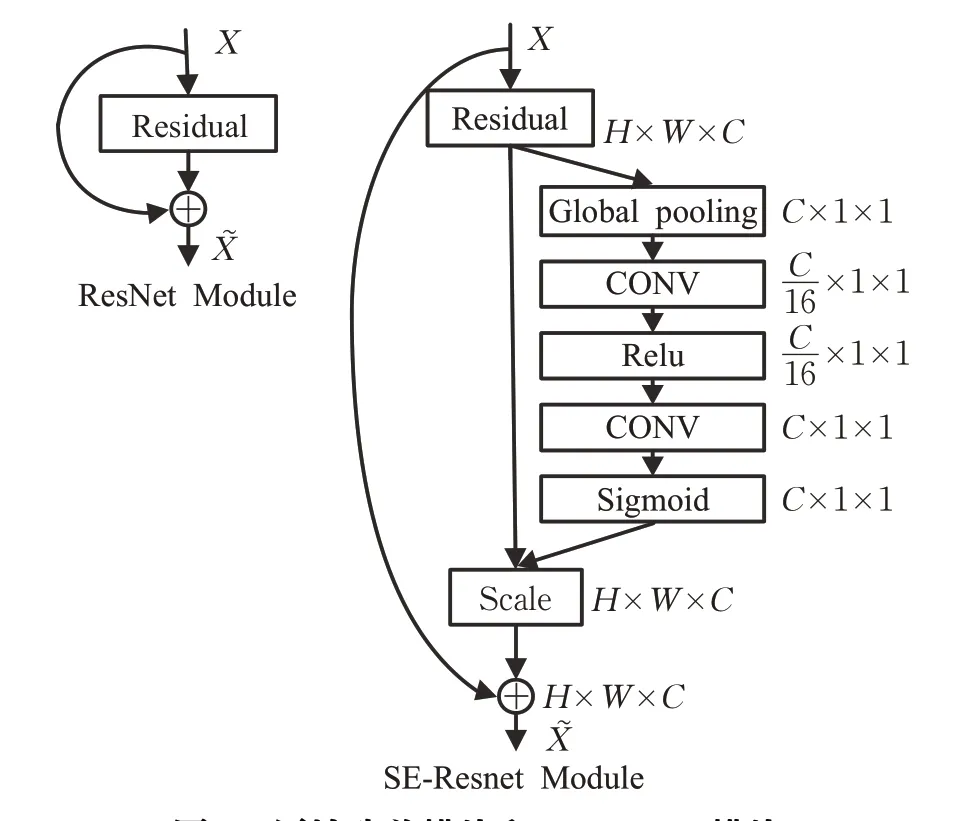
图3 原始残差模块和SE-ResNet模块
传统的目标分类、检测和分割,往往是通过单一的网络结构提取整张图像的特征。从人脑注意力机制去思考,这种方法不一定是最优的,每一个图像样本都具有内容性,而且基本每张图片的内容并不会均匀分布在图片中的每一块区域。所以,对于图像的内容区域使用注意力机制进行辅助,在增强有效信息的同时抑制无效信息,使得进行更准确的检测。
残差注意力网络主要由多层注意力模块堆叠而成,每个注意力模块包含了两个分支:主干分支(Trunk Branch)和软掩膜分支(Soft Mask Branch)。
其中,主干分支为ResNet-101,掩膜分支通过对特征图的处理,输出维度一致的注意力特征图(Attention Feature Map),通过点乘操作将两个分支的特征图组合在一起,得到最终的输出特征图。
如图4所示,对于某一层输出feature map,即下一层的输入,传统R-FCN网络,只有右半部分Trunk Branch,本文在这个基础上增加了左半部分,即Soft Mask Branch。
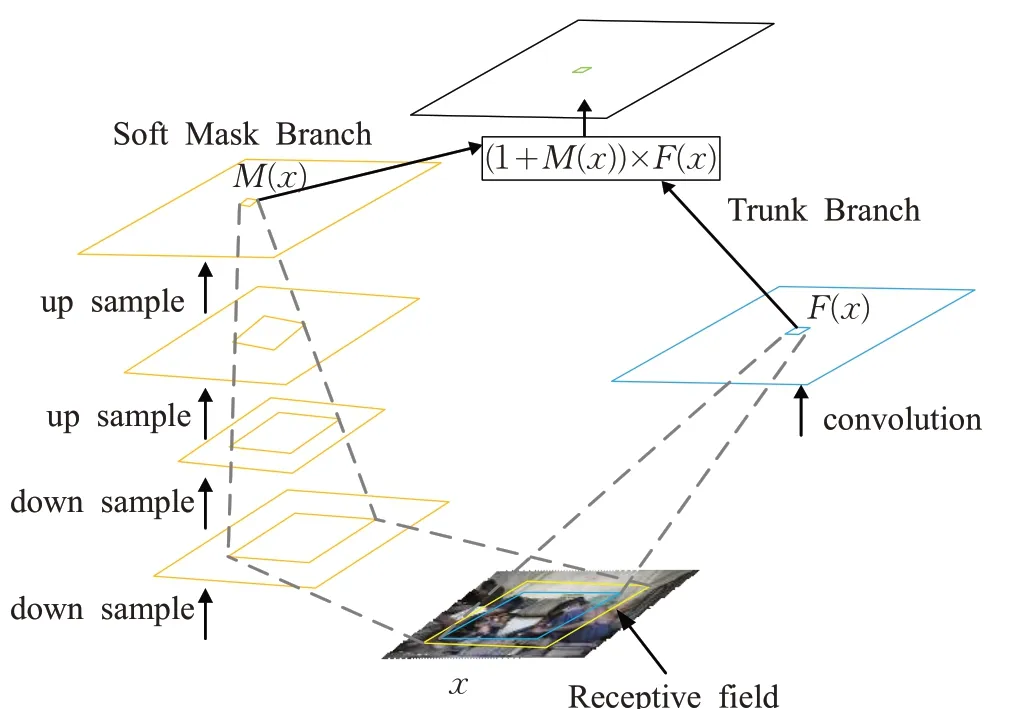
图4 残差注意力网络
在软掩膜分支(Soft Mask Branch)中,特征图的处理操作主要包括采样过程和上采样过程,前者是为了快速编码,获取特征图的全局特征;后者主要是将提取出来的全局高维特征上采样之后,与之前未降采样的特征组合在一起。其目的是使得上下文,高低维度的特征能够更好的组合在一起,这样就结合了全局和局部的特征,增强了特征图的表达能力。
接下来,将Soft Mask Branch与Trunk Branch的输出相结合,Soft Mask Branch输出的Attention Map中每一个像素值,是对原始Feature Map 上的每一个像素值的重新加权,它会增强有意义的特征,同时抑制无意义的信息。由于Soft Mask Branch的激活函数是Sigmoid,输出值在(0,1)之间,所以,无法直接将这个Weighted Attention Map输入到下一层中,导致前后两层的Feature Map有较大的差异。因此,为了进一步抑制不重要信息,将Soft Mask Branch与Trunk Branch输出的Feature Map进行相乘,得到了一个加权后的注意力图Weighted Attention map,最终该注意力模块的输出特征图如公式(5)所示。

其中,M(x)为Soft Mask Branch的输出,F(x)为Trunk Branch的输出。
3.4 多尺度训练和测试
本文受文献[14]的启发,采用多尺度的训练和测试策略以提高性能。在训练阶段,将输入的最短边调整为1 024。这个训练策略保证模型在不同尺度上检测人脸的鲁棒性,特别是在小人脸上,能够很好地检测。在测试阶段,为每个测试映像构建一个图像金字塔,金字塔中的每一个尺寸都独立测试,用于更好地检测小的和一般人脸。最终将各种尺寸的测试结果合并为图像的最终结果。
在RPN阶段,为了精准的检测小人脸,将一系列多尺度和纵横比结合起来构造多尺度anchors,比如纵横比设为(0.5,1,2),然后这些anchors 映射到原始图像来计算IoU(Intersection-over-Union,交集并集比)分数,规则如下:(1)拥有最高IoU 分数的anchors 被严格地视为正样本;(2)IoU得分高于0.7的被视为正样本;(3)IoU得分低于0.3 被视为负样本。最后,采用Non-Maximum Suppression方法,根据给定的IoU评分来调整anchors。
本文算法采用多分类损失函数,同时考虑了分类的损失,和位置的损失,如公式(6)~(8)所示。
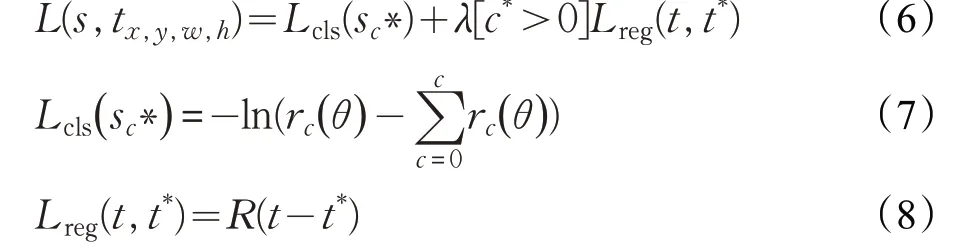
其中,c*表示ROI的类标,Lcls表示分类的交叉熵损失,Lreg表示位置的损失,t*表示真实回归框的参数,t=( tx,ty,tw,th)表示RPN得出的回归框的参数。如果分类正确,[c*>0]为1,分类错误则为0,对分类错误的不进行位置损失。超参数λ=1,表示分类损失和位置损失同等重要。
本文算法采用回归函数Smooth-L1 loss,如公式(9)所示。

其中,x=t-t*。
4 实验及结果与分析
4.1 实验环境
本文的实验环境配置如表1所示。

表1 实验环境配置
4.2 数据集
本文使用人脸检测领域最常用的标准公开数据集Widerface[15]来评估本文算法,它包含32 203 张图片及393 703 张已标注人脸,Widerface 数据集图片中的人脸在比例,姿势和遮挡方面都具有很大的变化。图片中人脸数据偏多,平均每张图片有12.2 个人脸,密集小人脸非常多。数据集包含三部分:训练集train、验证集val、测试集test,分别占40%、10%、50%。本文在复杂场景下进行检测,难度会有所加大,所以在这种检测困难的情况下验证集和测试集分为三个难度等级为“easy”“medium”“hard”的子集。
4.3 模型训练策略
本文采用预训练的ResNet-101模型进行特征提取,经过ImageNet[16]数据集的训练,使其具有强大的图像特征提取能力。在训练阶段,将输入的最短边调整为1 024,模型使用SGD算法(随机梯度下降)在Widerface数据集上进行训练,更新网络权值,每次迭代训练时,从这些正负样本中随机选择128 张为一个Mini-batch,将OHEM应用于负样本,并设置正和负样本的比例为1∶3,设置初始学习率为0.001,经过4 万次迭代后,降低学习率为0.000 1,继续迭代2 万次结束训练。测试时,图片不需要缩放,直接以原图的方式输入到已训练好的模型中。在Widerface测试集上进行人脸检测的部分检测结果,如图5 所示的绿色矩形框。如图所示,是本文算法在Widerface 测试集上的部分测试效果图,对于复杂背景中的小尺度人脸一般算法往往不能有效检测,而本文算法在检测小人脸上具有显著的优势。

图5 部分测试效果图
4.4 实验结果分析
4.4.1 模型性能分析
在残差网络ResNet-101 上进行融合后,首先验证融合后残差网络模型的有效性,本文在数据集上进行了实验,并从性能的增益来进行论证,结果如表2所示。

表2 不同模型的性能对比
表2 分别展示了ResNet-101、ResNet-152 和融合后模型的结果。从上表可以看出,融合后的模型在错误率上远远低于原始模型,这说明其能够给网络带来性能上的增益。值得一提的是,本文错误率甚至低于更深的ResNet-152。
从表3可以得出设置多个尺寸、多个比例的anchors,有助于提升人脸的检测精度,同时设置较小尺寸的anchors,可以有效地捕捉小的人脸。

表3 anchors的设置分析对比
4.4.2 不同子集下算法准确率分析
将本文算法与近几年提出的人脸检测算法Faceness-Net[17]、MTCNN[9]、Faster RCNN[3]、CMS-RCNN[11]进行比较,在Widerface验证子集上的测试结果,如表4所示。
本文算法与其他算法在同一数据集上的实验结果表明,本文算法在easy、medium、hard子集上精度分别为89.3%、87.0%、75.7%。与其他人脸检测算法相比,本文算法在easy、medium、hard子集上的检测精度与Faceness-Net 相比,分别提高了17.7%、26.6%、44.2%;与MTCNN算法相比,分别也提高了4.2%、5.0%、15.7%。与上述两个算法相比本文通过重新分配图像特征通道间的权重,及特征图间的权重,使得网络模型更加敏感,最终证明本文算法在人脸检测上的精确性。

表4 本文算法与其他人脸检测算法的对比
虽然本文算法在easy、medium 子集上检测结果略逊于Faster RCNN、CMS-RCNN,但是在hard 子集上却远远超过了以上两种算法,分别提升了4.1%、11.4%。说明本文算法在小人脸检测上比其他方法表现得更好,在easy、medium子集上也具有一定鲁棒性。
4.4.3 运行时间分析
所有算法都在NVIDIA GeForce TITAN X GPU上运行,从Widerface 数据集中随机抽取1 000 张图像,结果如表5所示。
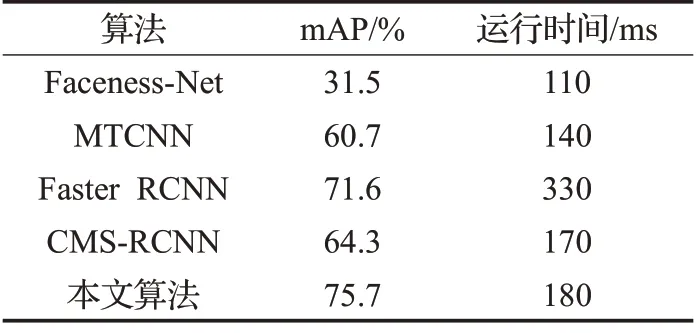
表5 不同人脸检测算法的运行时间对比
表5 给出了在Widerface 人脸数据集中不同检测算法的运行时间比较,运行时间是在Widerface 数据集中随机抽取1 000张图像的平均检测时间。
与近几年提出的人脸检测算法相比,本文算法在Widerface 测试集上测试的精度为75.7%,运行时间为180 ms,Faceness-Net、MTCNN虽然运行时间为110 ms、140 ms,但是它们检测的平均精度为31.5%、60.7%,远远低于本文结果,FasterRCNN 检测的平均精度虽然达到不错的结果,但是其运行时间过长;相较于CMSRCNN,本文算法精度明显高出10%,运行时间却与其基本相近。
综合以上,本文算法无论是检测精度还是运行时间均优于其他算法。
5 结束语
本文提出一种基于R-FCN 框架的人脸检测算法,融合Squeeze-and-Excitation 模块、残差注意力机制、多尺度的训练和测试,以及Online Hard Example Mining策略,通过将图像的特征通道与特征图进行加权,增强重要信息的同时抑制无效信息,使得网络模型更加敏感。在处理复杂的人脸和非人脸分类与检测问题时,能够更加精准。通过在Widerface 数据集上的实验,验证了在检测小人脸时,本文算法检测精度上优于现有的算法。虽然改进后的算法参数有所增加,但实验证明本文算法的时间复杂度并没有明显提高,下一步的工作将设计更加精简的网络框架,进一步降低检测的时间复杂度。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
小雪花·成长指南(2022年1期)2022-04-09
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
北京航空航天大学学报(2020年10期)2020-11-14
自动化学报(2019年6期)2019-07-23
动漫星空(2018年9期)2018-10-26
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
中国惯性技术学报(2015年1期)2015-12-19
