
安全高效的生物识别外包计算方案研究
2020-01-06 02:12邱意民
计算机工程与应用 2020年1期
周 亮,应 欢,戴 波,邱意民
1.中国电力科学研究院有限公司,北京100192
2.国网浙江省电力有限公司,杭州310007
1 引言
目前,生物识别(Biometric Identification,BI)已广泛应用于金融支付、企业管理、刑侦取证等领域。随着网上交易/支付等互联网应用发展,生物识别技术在互联网应用服务中正发挥着十分重要的作用[1-3]。目前,生物识别系统一般预先采集用户个体的生理生物特征(比如指纹、虹膜等)或者行为生物特征(比如键击等),注册用户账号并建立关联的生物特征数据库;在后续的识别过程中,对于用户提交的生物特征,系统将遍历预先建立的生物数据库并找到匹配的生物特征记录,从而认证用户的身份。在互联网应用中,由于应用服务方建立的生物识别系统往往涉及数量庞大的用户,因此遍历大规模生物特征数据库将引入巨大的计算开销,识别速度将受到显著影响。
云计算平台是支撑互联网应用的重要基础设施,它通过虚拟化技术实现了大规模存储和计算资源的整合,提供了分布式的、按需配置的存储、计算服务[4]。云计算技术的普及为互联网应用中生物识别系统的部署提供了新的模式:应用服务方(即生物数据库所有者)可将生物数据库存储在云服务器端,由具有强大计算能力的云协助完成高计算代价的生物识别任务,从而提高识别速度。
尽管借助云计算可以显著减轻数据库所有者的存储和计算开销,然而数据外包存在着天然的安全隐患:将隐私数据(例如生物特征数据)存储在云端后,数据所有者很难确保这些数据没有泄露或者被非授权地使用[5]。这种隐私问题在生物识别任务外包计算的场景下尤为突出:个体的生物特征数据由于具有唯一性、不可替代性等特征,一旦泄露往往会引发更严重的安全问题(如身份滥用、非授权访问等)。因此,基于隐私保护和身份安全方面的考虑,应用服务方将生物识别任务外包给云服务器时,需要部署有效的隐私保护机制对用户的生物特征数据进行脱敏处理,并保证云服务器可以在不获知数据明文的前提下完成生物识别,认证用户身份。
1.1 相关研究工作
如何在保证生物数据隐私的前提下完成生物识别近年来成为了学术界关注的热点问题,研究人员针对生物识别应用设计了大量的隐私保护方案。
文献[6-10]首先考虑了非外包场景下的安全生物识别方案。在该场景中,生物数据库所有者并不将数据库外包存储,而是本地进行生物数据的匹配计算;整个识别过程中,数据库所有者维护的生物数据库和待识别用户提交的生物特征均不会泄露给对方。针对上述场景,文献[6-8]先后提出了基于同态加密的隐私保护技术。随后,文献[9-10]结合混淆电路技术对上述方案进行了改进,实现了效率上的提升。然而,这些方案[6-10]中数据库所有者和待识别用户的计算及通信开销均随着数据库容量的增大而线性增加。当处理大规模生物数据库时,这些方案将带来巨大的计算和通信开销。此外,上述方案[6-10]均是基于非外包场景设计,方案中涉及的大量基于生物数据明文的计算因隐私保护的考虑无法外包给云服务器。因此,数据库所有者和待识别用户实际上无法节约本地的计算开销,这一进步说明在外包场景中部署上述方案[6-10]并不可行。
近年来,针对云计算场景,文献[11-16]先后提出了多个生物识别外包((Biometric Identification Outsourcing,BIO)方案。这些方案均涉及生物数据库所有者、待识别用户和云服务器三个参与方,设计目标是保证云服务器可以在不获知生物数据库明文和待识别用户生物特征明文的前提下,协助生物数据库所有者完成生物识别。文献[11]首先提出了基于秘密分享算法的多服务器安全生物识别(Multiple Server Secure Biometric Search,MSSBS)方案。在该方案中,生物数据库所有者首先在本地将数据库拆分成n 份并存储到多个云服务器上,并假设云服务器哪怕串谋也只能获取其中至多k 份。在这种假设下,MSSBS 方案[6]可以保证生物数据的安全,使得云服务器能在不获知生物数据明文的情况下完成识别。作为后续工作,文献[12]提出了基于两个互不串谋的云服务器的外包隐私保护生物认证(Outsourceable Privacy-Preserving Biometric Authentication,O-PPBA)方案。然而,该方案每处理一次生物识别请求都需要两个云服务器之间的频繁交互,这带来了极大的通信开销。此外,上述MSSBS[11]和O-PPBA[12]方案的假设均不够实际,无法抵挡现实应用中云服务器之间的串谋攻击。
最近,研究人员也设计了多个基于单个云服务器BIO 方案。Yuan 等人[13]设计了基于矩阵混淆机制的生物数据隐私保护技术,并相应构造了BIO 方案。该方案[13]声称在云服务器知晓数据库中部分数据明密文对的情况下仍能保证数据隐私。然而,Wang 等人[14]分析了文献[13]中方案的安全漏洞,通过设计具体攻击指出,云服务器可以基于生物数据明密文对恢复出数据库拥有者的密钥,并进一步恢复出整个生物数据库明文。为保护密钥的安全,Wang 等人[14]利用矩阵相似变换的特殊性质设计了新的数据隐私保护技术,并构造了两个新BIO方案(CloudBI-I及CloudBI-II),以抵抗具有不同背景知识的云服务器。但是,文献[15]指出,Wang 等人[14]进行的方案安全性分析并不完备,CloudBI-I/Cloud-BI-II方案[14]仍存在其他的隐私缺陷。文献[15]设计了多个具体的攻击,通过这些攻击云服务器可以精确恢复出其他方案参与方的隐私生物数据。为抵抗文献[15]提出的攻击,Hahn 等人[16]对Wang 等人[14]的方案进行了改进,在利用矩阵变换的基础上通过添加噪声的方式对生物数据进行了进一步的保护,并声称可以保证数据的隐私性。然而通过分析发现,Hahn等人[16]的BIO方案仍具有安全隐患,云服务器仍可以推断出其余方案参与方的数据隐私。
综上所述,设计可实际部署的云环境中的生物识别外包方案目前仍是一个开放性难题。本文将针对这个问题展开研究,设计安全高效的数据隐私保护技术,解决上述难题。
1.2 本文创新点及结构
本文主要研究生物识别外包计算问题,技术贡献可以概括如下:
(1)对最新研究方案[16]进行了详细的安全性分析,并提出了一个具体的攻击算法。利用该攻击,云服务器可以准确地恢复整个明文生物数据库。
(2)将数据拆分技术[17]与特定矩阵变换相结合,设计了全新的生物特征数据加密算法,并构造了改进的生物识别外包方案EBIO(Enhanced Biometric Identification Outsourcing scheme)。同时,本文对改进方案进行了安全性及复杂度分析。理论结果表明,EBIO 方案可以在保证生物数据隐私的前提下高效完成生物识别任务。
(3)对EBIO方案进行了原型实现,并基于不同规模的生物数据库对方案进行了性能评估。实验结果表明,EBIO 方案可以高效完成生物识别任务,对于方案各参与方均不会造成过高的计算和通信开销。
2 系统模型及敌手模型
2.1 系统模型
本文考虑如图1 所示的系统模型。典型的BIO 方案涉及数据库拥有者(记为Owner)、待识别用户(记为User)以及云服务器(记为Cloud)三个参与方,包括数据库加密(图中步骤0)以及生物识别(图中步骤1~4)两个阶段。

图1 BIO方案系统模型
假设Owner 预先采集了m 个用户的生物特征,并建立明文生物数据库D={b1,b2,…,bm}。在数据库加密阶段,Owner 首先调用密钥生成算法(KeyGen)生成密钥K ,随后调用数据加密算法(DateEnc)加密每个采集的生物特征记录bi得到其密文Ci,并将密文数据库DE={C1,C2,…,Cm}发送给Cloud。
在生物识别阶段,User 首先提交生物特征向量bt给Owner进行识别,后者调用检索加密算法(QueryEnc)加密bt得到密文Ct,并将Ct发送给Cloud。收到Ct后,Cloud执行密文匹配算法(Match),以密文数据库DE以及查询生物特征密文Ct为输入,输出与bt最为相似的生物数据记录密文Ch。云端识别计算完成后,Cloud将Ch返回给Owner。最后,Owner 调用验证算法(Verify)解密Ch并判断bh与bt是否匹配,并将最终生物识别结果返回给User。
与现有研究[6-16]保持一致,本文假设Owner 采集的生物特征记录bi以及User 提交的查询生物特征bt均由n 维特征向量表示,即bi=[bi,1,bi,2,…,bi,n] ,bi=[bt,1,bt,2,…,bt,n](特征向量的生成方法不在本文的讨论范围内)。特征向量之间的相似度由欧氏距离衡量,两个向量相互匹配指两者之间的欧氏距离小于某一预设值(记为ε),如dist(bh,bt)<ε。
综上,基于图1所示系统框架的BIO方案共包含五个具体算法(KeyGen、DateEnc、QueryEnc、Match、Verify),其中只有Match算法由Cloud执行。
2.2 敌手模型
本文沿用文献[14]中的敌手模型,假设系统中的Cloud为敌手,并将其根据已知信息的不同分为三类:
(1)第一类敌手仅仅知道生物数据库密文DE={C1,C2,…,Cm}以及查询生物特征向量密文Ct,即该敌手的已知信息为K1={DE,Ct}。
(2)第二类敌手在第一类敌手的基础上还知道明文数据库D={b1,b2,…,bm}中k(k ≪m)个明文生物特征记录,但不知道对应密文,即敌手的已知信息为K2={DE,Ct,P},其中P ⊂D 且|P|=k(即P 是D 包含k 个生物特征记录的子集)。
(3)第三类敌手在第一类敌手的基础上还能与User 串谋,可任意选择l 个明文查询生物特征向量并获知其对应密文,即敌手的已知信息为
由于K1⊂K2且K1⊂K3,第一类敌手的已知信息为第二类和第三类敌手的子集。因此,如果一个生物识别外包方案可以抵抗第二类或第三类敌手的攻击,则该方案自然可以抵抗第一类敌手攻击。
然而,K2和K3之间不存在包含关系,即K2⊄K3且K3⊄K2。因此,生物识别外包方案在第二类和第三类敌手攻击下的安全性是分别考虑的。由于兼顾第二类和第三类敌手已知信息的敌手过于强大,与现有研究工作[13-16]保持一致,本文也不考虑这类敌手的攻击。
2.3 设计目标
基于上述系统模型和敌手模型,可实际部署的BIO方案需满足正确性、隐私性及高效性三个设计目标。
(1)正确性:如果Owner、User 和Cloud 均诚实执行BIO 方案,那么Cloud 返回的Ch满足dist(bh,bt)=min{dist(b1,bt),dist(b2,bt),…,dist(bm,bt)} ,即Cloud 可遍历得到D 中与bt最相似的生物特征记录的密文Ch。
(2)隐私性:在BIO 方案执行过程中,Cloud 不能基于其已知信息获得任何隐私生物特征数据,包括明文生物特征记录bi∈D 以及明文查询生物特征向量bt。
(3)高效性:BIO 方案在实现上述正确性和隐私性目标的同时,不应给方案各参与方带来过高的计算和通信开销。
3 对Hahn等人方案的安全性分析
Hahn 等人[16]提出了一个BIO 方案,并声称当Cloud知道部分数据库明密文对的情况下还能保证方案的安全性,即Cloud不能获知数据库中其他任意的生物特征记录明文或者查询生物特征向量明文。本章首先对Hahn等人方案[16]进行简单回顾,随后将设计具体攻击算法证明该方案并不能抵抗文中[16]假设的敌手。
3.1 Hahn等人方案回顾
(1)数据库加密阶段:Owner 首先选取随机可逆阵M1,M2∈R(n+2)×(n+2)作为密钥。随后,Owner 调用算法1 加密每个生物特征记录bi得到Ci,并将密文数据库DE={C1,C2,…,Cm}发送给Cloud;其中算法1的步骤1中diag(x1,x2,…,xn)表示以x1,x2,…,xn为对角线元素的对角矩阵。
算法1 Hahn等人方案数据加密算法
输入:生物特征记录明文bi=[bi,1,bi,2,…,bi,n]∈D,密钥(M1,M2)
1.扩展bi为对角矩阵Bi=diag(bi,1,bi,2,…,bi,n,bi,n+1,1),其中
2.随机选取单位下三角矩阵Qi,计算Ci=M1QiBiM2。输出:生物特征记录密文Ci
(2)生物识别阶段:User 与Owner 协同执行算法2,最终由Owner 生成查询生物特征向量密文Ct,并发送给Cloud。
算法2 Hahn等人方案检索加密算法
输入:查询生物特征向量明文bt=[bt,1,bt,2,…,bt,n]∈D,密钥(M1,M2)
1.User扩展bt为对角矩阵Bt=diag(bt,1,bt,2,…,bt,n,1,rt),其中rt为随机实数;User同时选取扰动向量ht=[ht,1,ht,2,…,ht,n],并将其扩展为对角矩阵Ht=diag(ht,1,ht,2,…,ht,n,0,0)。
2.User 计算bt与ht的欧氏距离dist(bt,ht) ,并将B′t=2dist(bt,ht)Bt+Ht发送给Owner。
3.Owner 随机选取单位下三角阵Qt,并计算Ct=BiQiM2
输出:生物特征记录密文Ci
当收到Ct后,Cloud调用算法3找到与bt最相似的生物数据向量密文,其中算法3 步骤1 中tr(·)表示矩阵求迹符号,即tr(CiCt)表示矩阵CiCt的迹(对角元素之和)。这里,省略与安全性分析无关的方案内容(如验证算法等),可以参考文献[16]了解具体细节。
算法3 Hahn等人方案密文匹配算法
输入:密文生物数据库DE={C1,C2,…,Cm},密文查询生物数据Ct
1.计算si=tr(CiCt),∀i=1,2,…,m。
2.求得h 满足sh=max{s1,s2,…,sm},并相应输出Ch。
输出:识别结果Ch
Hahn 等人[16]声称,Cloud 即便知晓数据库中部分生物记录明密文对,仍无法获取其他任何生物数据。文章接下来将介绍一个具体攻击,证明具有上述能力的Cloud可以恢复出整个明文生物数据库。
3.2 针对Hahn等人方案的攻击
不失一般性,假设Cloud 已知(bi,Ci)i=1,2,…,k。根据算法3,对于任意密文查询生物特征向量Ct,Cloud将基于每个Ci计算tr(CiCt)来完成识别。本节接下来将介绍一个具体攻击,利用该攻击Cloud可以基于其已知信息恢复出整个明文数据库D。该攻击可分为以下两个步骤。
(1)获取查询生物特征明密文对根据矩阵求迹运算的性质,成立:


根据假设,每个bi=[bi,1,bi,2,…,bi,n]对Cloud都可知,故Cloud可以基于上述等式构造如下线性方程组:

当k >n+2 时,Cloud 可以求解上述方程组确定[,,…,并重构得到B′t。重复上述步骤,Cloud可得到多个查询生物特征明密文二元组(B′t(i),i=1,2,…,n+1,并保证之间线性独立。
(2)构建线性方程恢复明文生物特征记录
对于任意Cj∈DE,Cloud基于上述确定的计算:

根据上述等式,Cloud可构造如下线性方程组:

算法4 对Hahn等人方案的攻击算法
输入:生物特征记录明密文对(bi,Ci)i=1,2,…,k,查询生物特征向量密文(N >n+2),密文生物特征记录Cj∈DE
1.for l=1 to N do
2. 基于已知bi=[bi,1,bi,2,…,bi,n]构建线性方程组:

4.end for
6.对于密文生物特征记录Cj,构造线性方程组

求解对应明文bj。
输出:生物特征记录明文bj
4 改进方案EBIO
根据第1.1 节的相关研究工作介绍,目前尚未有可实际部署的BIO 方案。本章将结合数据拆分技术[17]以及特定矩阵变换设计隐私保护技术,并构造在第2.2 节敌手模型下安全高效的生物识别方案。
4.1 方案构造
本章构造的方案EBIO 基于第2.1 节的系统模型,包括数据库加密和生物识别两个阶段,涉及(KeyGen、DateEnc、QueryEnc、Match、Verify)5 个算法。在数据库加密阶段,Owner 调用密钥生成算法KeyGen 生成3 个(n+2)×(n+2) 阶随机可逆阵M ,N1、N2作为密钥。随后,Owner 调用算法5(数据加密算法)加密每个生物特征记录bi∈D 得到密文Ci,并将密文数据库DE={C1,C2,…,Cm}发送给Cloud。
算法5 数据加密算法(DataEnc)
输入:生物特征记录明文bi=[bi,1,bi,2,…,bi,n]∈D,密钥(M,N1,N2)
1.扩展bi为b̂i=[bi,1,bi,2,…,bi,n+1],其中bi,n+1=-(bi,12+…+bi,n2)。
输出:生物特征记录密文Ci=(C′i,C″i)
在生物识别阶段,对于User提交的查询生物特征向量bt,Owner 调用算法6(检索加密算法)加密bt得到密文Ct=(Ct,1,Ct,2),并将其发送给Cloud。
算法6 检索加密算法(QueryEnc)
输入:查询生物特征向量明文bt=[bt,1,bt,2,…,bt,n]∈D,密钥(M,N1,N2)
1.扩展bt为=[bt,1,bt,2,…,bt,n,1,rt] ,这里rt∈R 为随机实数。
3.随机选取单位下三角矩阵T ∈R(n+2)×(n+2),计算V1=,V2=。
4.随机选取单位下三角矩阵R1, R2∈R(n+2)×(n+2),计算Ct,1=V1BtR1M-1,Ct,2=V2BtR2M-1。
输出:查询生物特征向量密文Ct=(Ct,1,Ct,2)
随后,Cloud调用算法7(密文匹配算法)基于DE及Ct找到与bt最相似的生物数据记录,并向Owner 返回该记录对应的密文Ch。
算法7 密文匹配算法(Match)
输入:密文生物数据库DE={C1,C2,…,Cm},查询生物向量密文Ct=(Ct,1,Ct,2)
1.计算si=+tr(C″iCt,2),∀i=1,2,…,m。
2.求得h 满足sh=max{s1,s2,…,sm},并相应输出Ch。
输出:识别结果Ch=(C′h,C″h)
最后,Owner 调用算法8(验证算法)解密Ch,并判断bh是否为bt匹配的生物特征记录,并相应向User返回生物识别结果。
算法8 验证算法(Verify)
1.计算M-1C′h+M-1,提取对角线元素重构bh。
2.计算dist(bh,bt)。
输出:若dist(bh,bt)<ε,返回1;否则,返回0
4.2 正确性分析
定理1 EBIO方案是正确的生物识别外包计算方案。
证明 根据第2.3节中的正确性定义,本节接下来证明,若EBIO方案参与方均诚实执行协议,则Cloud返回的Ch满足

由于V1,V2,,R1,R2均为单位下三角阵,根据矩阵求迹运算的性质,得到:
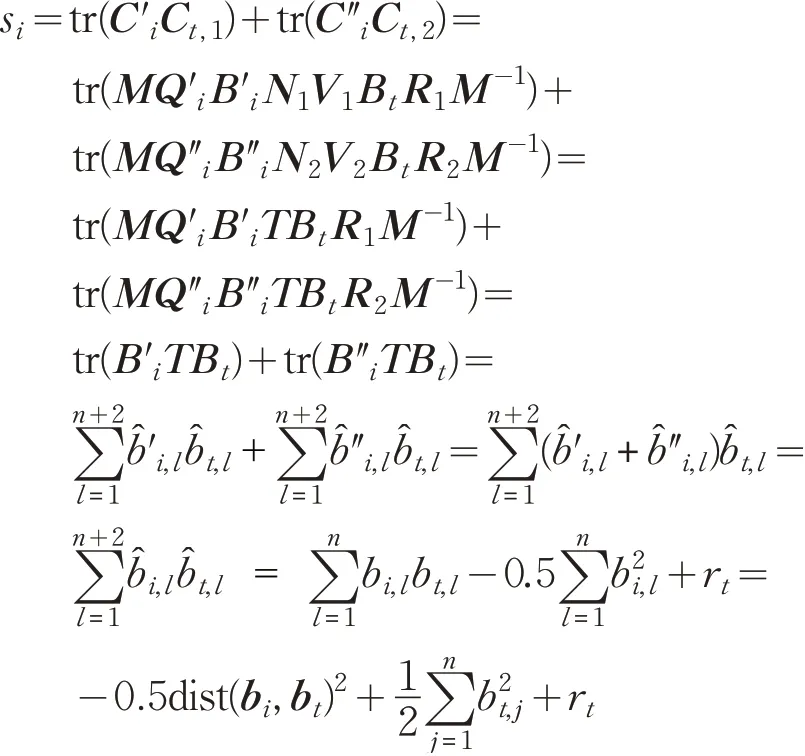
因此,若si>sj,则有:

综上,如果sh=max{s1,s2,…,sm},那么:

EBIO的正确性得证。
4.3 隐私性分析
根据第2.2 节敌手模型,第一类敌手的已知信息是第二和第三类敌手的子集。因此,如果EBIO 方案可以抵抗第二类或第三类敌手的攻击,那么该方案自然可以抵抗第一类敌手攻击。本节接下来将分别证明EBIO方案在第二类和第三类敌手攻击下的隐私性保护性。
定理2 EBIO方案在第二类敌手攻击下是隐私保护的生物识别外包计算方案。
证明 根据第2.3节中的隐私性定义,本节接下来证明在EBIO 方案中,第二类敌手不能基于其已知信息K2={DE,Ct,P}来获得其他任何隐私的生物特征数据(包括明文生物特征记录bi∉P 以及明文查询生物特征向量bt);其中,DE为生物数据库密文,Ct为查询生物特征向量密文,P 是包含k(k ≪m)个生物特征记录的D 的子集。
首先证明敌手不能通过直接解密Ci获得bi。根据3.1节方案构造,每个bi首先转换成,然后加密生成。由于矩阵M,都是由Owner随机选取的,敌手在不知道这些随机矩阵的情况下,无法直接对Ci进行解密恢复得到bi。类似地,敌手也无法对Ct进行解密恢复得到bt。
接下来证明敌手不能基于已知的明文生物特征记录集合P 获取更多的信息。由于EBIO方案采用了随机数据拆分技术,因此数据加密算法和检索加密算法均不属于距离保持变换(Distance Preserving Transformation,DPT),即∀bi,bj∈D ,敌手不能从dist(bi,bj)推导得到其对应密文Ci和Cj。根据文献[17]的安全性分析,现有基于已知样本的签名链接攻击(the Signature Linking Attack)[17]以及主成分分析的攻击(PCA-Based Attack)[0]对非DPT变换均不奏效,因此在EBIO方案中敌手无法基于其已知的明文生物特征记录集合P 获取隐私信息。
进一步地,由于敌手不知道已知生物数据记录的对应密文,故文献[15]以及本文第3.2 节提出的基于生物特征记录明密文对的攻击均不适用。因此,敌手无法基于已知的生物特征记录明文获取更多的隐私信息。
综上所述,EBIO 方案在第二类敌手攻击下是隐私保护的。
定理3 EBIO方案在第三类敌手攻击下是隐私保护的生物识别外包计算方案。
证明 根据第2.3节中的隐私性定义,本节接下来证明在EBIO 方案中,第三类敌手不能基于其已知信息来获得其他任何隐私的生物特征数据(包括bi∈D 以及l),其中DE为生物数据库密文,Ct为查询生物特征向量密文,是敌手选择的查询生物特征向量明文,而是其对应密文。
接下来证明敌手不能基于已知的查询生物特征向量明密文对获取更多的信息。不失一般性,假设敌手已知l 组明密文对,其中为求解随机矩阵,敌手关于有(n+1)(n+2)l个未知数,关于有2(n+2)2l个未知数,关于M 有(n+2)2个未知数,然而敌手基于已知的仅能够造如下2(n+2)2l 个线性方程:

由于未知数个数((n+1)(n+2)l+2(n+2)2l+(n+2)2)大于方程数个数2(n+2)2l,敌手无法基于已知明密文对恢复出用于生物数据加密的随机矩阵,因此无法对生物数据密文进行解密。
综上所述,EBIO 方案在第三类敌手攻击下是隐私保护的。
根据第2.2 节的敌手模型,由于第二类和第三类敌手均强于第一类敌手,因此EBIO 自然在第一类敌手攻击下也是隐私保护的。
4.4 复杂度分析
本节接下来对EBIO方案各参与方的计算和通信开销进行分析。假设矩阵向量乘法和矩阵间乘法的计算复杂度分别为O(n2)和O(n3),这里n 表示生物特征向量的维度。
计算开销:在数据库加密阶段,Owner 将花费O(mn3)的一次性开销离线加密m 个生物特征记录。在生物识别阶段,Owner 将花费O(n3)的开销加密每个查询生物特征向量;接着,Cloud 将花费O(mn3)的开销计算{si}i=1,2,…,m以及O(m)的时间开销确定集合中的最大值sh;最后,Owner花费O(n3)来验证云端识别结果。
通信开销:在数据库加密阶段,Owner 将一次性花费O(mn2)开销上传整个密文生物数据库;而在识别阶段,针对单个识别请求,User 将花费O(n)的开销发送bt,而Owner和Cloud仅需要O(n2)的开销。
综上所述,Owner在线生物识别阶段的总计算开销为O(n3) 。由于本地完成生物识别的计算开销为O(mn),当m >n2时,EBIO方案可以给Owner可以带来本地开销显著的节约。
为更好地说EBIO 方案的高效性,比较了EBIO 方案和相关方案中各参与方的计算和通信开销,结果如表1所示;其中m 表示明文数据库D 中的生物特征记录数目,n 表示各生物特征向量的维度。总体来看,EBIO方案和CloudBI-II方案[14]中各参与方在初始化和识别阶段的复杂度相同,而比Hahn等人方案[16]在识别阶段的计算上更为高效。然而,根据文献[15]以及本文第3.2节的安全性分析,CloudBI-II方案[14]和Hahn等人方案[16]均无法同时抵抗第二和第三类敌手的攻击。综上所述,EBIO方案在保持计算/通信高效的同时实现了更强的隐私保护。
5 EBIO方案的实现和实验评估
为进一步验证本文提出EBIO 方案的可用性,本章将对EBIO进行原型实现以及实验验证。与现有BIO方案[13-16]的实验评估方法保持一致,本章也采用随机生成的指纹数据库作为实验数据集;数据库中每一个指纹特征都由FingerCode编码[19]表示,即每一个指纹特征都表示为640 维的特征向量(即n=640),向量每一维都是8 bit整数。搭建了与文献[14]中类似的实验环境。具体来说,模拟了具有1 000个节点的云服务器,其中每个节点都是一台配置8 GB内存和3.5 GHz I7 4771处理器的台式机,并利用单独的一个节点模拟用户端。EBIO 方案的所有算法都由MATLAB 进行实现。根据第1.1 节相关工作介绍以及第3章的安全性分析,现有基于单个云服务器的BIO方案均存在安全漏洞,因此本章将不对现有方案进行实现。
5.1 EBIO在线阶段的开销
EBIO方案的数据库加密阶段仅涉及Owner的一次性开销,并不影响在线生物识别的效率,因此本章主要讨论EBIO 方案在生物识别阶段的开销。表2 描述了Owner和Cloud在生物识别阶段的计算和通信开销。表中数据显示,随着生物数据库规模不断增加,Owner 在生物识别阶段的计算开销(包括加密查询生物特征向量bt以及重建bh并计算dist(bh,bt)的开销)保持不变,而Cloud 的计算开销(即计算{si}i=1,2,…,m的开销)随着数据库规模的增加线性增加。

表1 EBIO方案和相关方案的复杂度及安全性对比
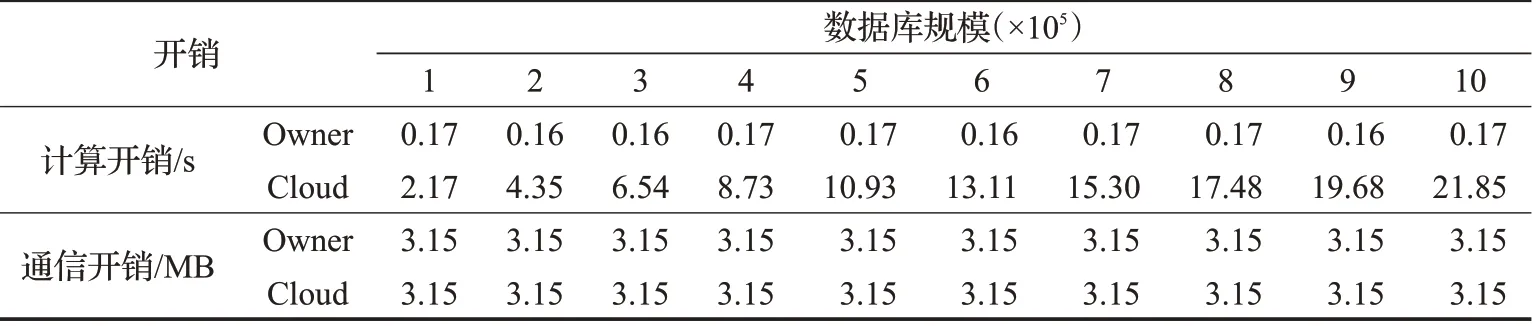
表2 EBIO方案生物识别阶段中Owner和Cloud端的计算和通信开销
实验结果进一步表明,尽管Cloud端的开销是线性增加的,但由于EBIO 的密文匹配算法(算法7)易并行化实现,这部分开销可以均摊至每个Cloud 节点,并由它们并行完成。因此,Cloud 可以高效地完成识别。例如,当生物数据库包含百万量级(106个)指纹特征向量时,Cloud 完成一次生物识别的时间仅约22 s。通过将繁重的识别任务外包给Cloud,Owner 完成一次生物识别只需要进行几次简单的矩阵变换,因此计算开销大幅度降低。如表2 所示,Owner 处理一次识别请求的计算开销在0.25 s以内,显著小于Cloud的计算开销。
在通信开销方面,Owner和Cloud的开销均为常数,并与数据库容量独立。对于每一次生物识别请求,Owner和Cloud的总通信开销仅为6.30 MB。
5.2 Owner部署EBIO方案带来的开销节约
为了更直观地说明Owner通过部署EBIO带来的计算开销上的节约,本节比较了Owner本地进行单次生物识别计算和部署EBIO借助Cloud进行单次生物识别计算的开销进行对比,实验结果如图2所示。
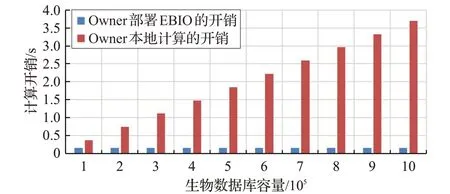
图2 Owner处理单次生物识别任务的计算开销
实验结果表明,Owner在非外包场景下本地处理一次生物识别请求的计算开销将会随数据库容量增加而线性增长。而通过部署EBIO 方案,当生物数据库容量增加时,Owner处理一次生物识别请求的计算开销保持不变,且显著小于非外包场景下的计算开销。当处理大规模生物数据库时,这种开销节约将十分显著。例如,当数据库包含100万个生物特征记录时,非外包场景下Owner的开销是3.80 s,而部署EBIO方案Owner的开销仅为0.17 s。
考虑到网络应用中常常存在多个User 同时提交生物识别请求的情况,本节还比较了Owner在非外包和外包场景下同时处理多个生物识别请求的计算开销。如图3描述了Owner同时处理10个生物识别请求的情况。

图3 Owner同时处理10次生物识别任务的计算开销
实验结果表明,当生物数据库规模确定时,Owner在外包和非外包场景下处理多个生物识别请求的计算开销均会随生物识别请求数目的增加而线性增加。由于在EBIO 方案中,Owner 将高代价的生物识别计算外包给了Cloud,因此本地的计算开销将显著小于非外包场景的计算开销。当Owner 同时处理的生物识别请求数目越多时,Owner 通过部署EBIO 方案节约的计算开销将更加显著。例如,当数据库包含100万个生物特征记录时,非外包场景下Owner 同时处理10 个生物识别请求的开销约38.0 s,而部署EBIO方案Owner的开销仅为1.6 s。
综上所述,EBIO 方案可以高效地完成生物识别任务,能满足实际应用的需求。
6 结束语
本文对云环境中的生物识别外包方案进行了系统的研究。首先描述了生物识别外包(BIO)方案的系统模型、敌手模型和设计目标。随后本文对最新研究进展[16]进行了详尽的安全性分析,通过具体攻击揭示了文献[16]中方案的安全缺陷。为实现安全高效的生物识别外包,本文结合数据拆分技术[17]以及特定的矩阵变换重新设计了生物特征数据加密算法,构造了改进的生物识别外包方案EBIO。理论分析表明,EBIO方案能保证识别结果的准确性,同时可以确保生物特征记录和查询生物特征向量的隐私性。本文还对EBIO方案进行了原型实现。实验结果表明,EBIO 方案可以高效地完成生物识别,不会给方案各参与方带来过高的计算和通信开销。
猜你喜欢
黑龙江大学自然科学学报(2022年1期)2022-03-29
政工学刊(2021年2期)2021-11-26
计算机仿真(2021年10期)2021-11-19
阅读与作文(小学高年级版)(2019年2期)2019-03-27
民间故事选刊·上(2018年1期)2018-01-02
通信技术(2016年10期)2016-11-12
信息安全与通信保密(2016年10期)2016-11-11
小小说月刊·下半月(2016年6期)2016-05-14
中国资源综合利用(2016年11期)2016-01-22
作文与考试·高中版(2008年12期)2008-07-01
