
基于时间扰动的智能电表隐私保护方法
2020-01-06 02:11蔡子伟徐正全王晓艳
计算机工程与应用 2020年1期
蔡子伟,徐正全,王晓艳
武汉大学 测绘遥感信息工程国家重点实验室,武汉430079
1 引言
智能电表作为推动电网的信息化、智能化、自动化建设的重要设备,与人们的日常生活息息相关。智能电表数据为电力资源的计量计费、电力资源的区域性分配以及第三方的数据挖掘分析等应用提供强有力的数据支撑。但细粒度的电力消费数据也导致了用户隐私信息暴露在攻击者面前。攻击者通过挖掘电力波形变化,可以得到用户家庭不同负载的使用情况,从而在一定程度上获取用户的行为模式和作息习惯、家庭经济与收入状况以及个人偏好和生活习惯等信息,存在严重的隐私泄露风险[1-2]。因此,智能电表隐私保护本质上是对用电模式的保护,而不是传统意义上对于单点数值的保护。
数据扰动方法在半可信或不可信的环境下,通过对原始数据添加扰动来提高机密性,能够在一定程度上调和隐私安全性和数据可用性的矛盾,是智能电表隐私保护的主流方法之一。向原始数据中添加加性或乘性随机噪声来实现安全性和可用性的权衡是一种典型的方法[1-4]。例如Vukovic 等[3]向数据中添加随机噪声,模糊单点数据的同时,又保证聚合数据的精确性。充电电池技术也广泛应用于智能电表隐私保护领域[1-2,5-6],Backes等[5]利用充电电池产生额外的充放电扰动来隐藏消费事件或单个电器的负载特征,提高了模式隐私的安全性。此外,2006 年Dwork[7]提出了一种可证明的隐私度量方法,这种差分隐私技术也成为数据隐私保护的常用手段[8-9]。Ács等[8]提出了一种基于差分隐私与同态加密技术的电力数据聚合算法,可以实现在密文域的数据聚合。当前基于数据扰动的智能隐私保护方法能在一定程度上保障用户隐私的安全性,但仍然存在一些问题:一方面,现有的算法没有考虑到智能电表隐私泄露的特殊性,对模式的保护力度不足;另一方面,当前隐私保护算法专注于数据的安全性而忽略了智能电表数据本身在不同应用领域的可用性保障。
针对上述存在的问题,提出了一种基于时间扰动的智能电表隐私保护方法。本文给出了智能电表数据的时延模型,并对其进行了理论分析,通过错开电表的数据采集和发布时间模糊消费事件,破坏电器的负载特性。该方法的优势主要体现在三个方面:基于时间扰动的隐私保护方案利用了智能电表数据隐私特性,从模式保护的角度出发提高智能电表数据的隐私安全性;本文算法在保护智能电表隐私的同时,也保证了处理后的消费数据在计量计费和数据聚合挖掘上的可用性;采用了ECO数据集[10],利用真实的智能电表消费数据证明方案的可行性,同时利用非侵入式负载监测算法作为攻击手段验证算法的安全性。
2 基于扰动的智能电表隐私保护
数据扰动是目前智能电表隐私保护最常用的一种方法,常用的数据扰动主要包括随机扰动、充电电池、差分隐私等。通过扰动原始数据实现有效的数值破坏来达到隐私保护的目的。
2.1 随机扰动
随机扰动是指通过给用户实时电量添加随机噪声,使得用户的实时电量数据不暴露给外界。随机扰动方法通过直接添加随机噪声n 对每个记录数据进行模糊化处理,从而实现对整体消费曲线的扰动,其基本表达式为:

随机扰动方法的计算开销小,但隐私保护强度较差,同时随机加入的噪声会影响到电力公司的正确计费以及电力数据挖掘实用性。
2.2 充电电池
充电电池[11]的基本思想就是利用一个独立的储能设备向电力消费数据中添加额外的充放电操作来隐藏电力事件或者电器的负载特征,其本质就是通过对部分消费数据的时间搬移,在保证计费周期内用户总耗能不变的同时,实现对智能电表电力波形的破坏,从而起到保护用户隐私的目的。若用c 表示充电电池总容量,用b 表示当前时刻的电池电量,则充电电池的基本模型为:
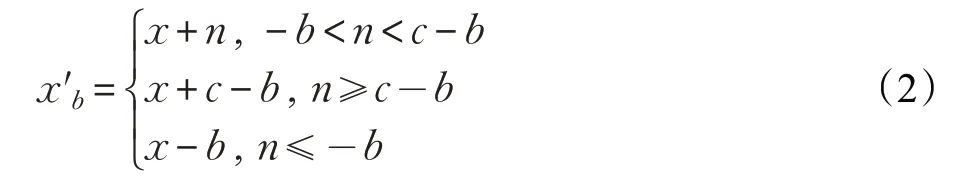
充电电池主要有两个功能:接收来自电力公司的电能并进行存储;为智能电器提供电能。如图1 所示,智能电器可以单独或同时接收来自电力公司和充电电池的电能。来自电力公司的电能经过充电电池中转,使得智能电器的原始电力消费数据分解到不同的时间点上,导致智能电表获取的电力消费数据不能直接反映真实的用电信息,模糊了用户电力消费波形,从而保证了用户隐私的机密性。相比于随机扰动方法,充电电池方法的优点是计算开销小,隐私保护强度相对较好,缺点是成本高。

图1 充电电池工作原理
2.3 差分隐私
差分隐私保护[12]基本思想是单个记录在数据集中或者不在数据集中,对计算结果的影响微乎其微。所以,一个记录因其加入到数据集中所产生的隐私泄露风险被控制在极小的、可接受的范围内,攻击者无法通过观察计算结果而获取准确的个体信息,ε-差分隐私[13]的形式化定义如下:
假设存在随机算法M ,对于任意两个邻近数据集D 和D′,以及M 所有可能输出构成的任意子集O,若算法满足:
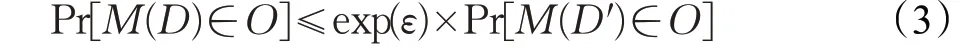
则称算法M 满足ε-差分隐私保护,其中Pr[⋅]和ε 分别表示概率密度函数和隐私保护预算。
差分隐私定义了极其严格的攻击模型,并对隐私泄露风险进行了严谨的数学证明和定量化表示,是目前隐私保护领域的主流算法。它能够提供有效的单一数值保护,同时保证数据集统计规律的准确性。但由于智能电表数据隐私的独特性,其用户隐私不是某个数值或单条记录,而是隐含在整个数据序列的变化规律中。因此单一的差分隐私往往无法对智能电表数据提供有效的模式保护,目前主要通过差分隐私结合同态加密的方案来实现隐私安全性的优化。引入同态加密虽然能提供较好的隐私保护强度,但也极大地增加了计算复杂度,使得计算开销很大,此外加密也降低了智能电表数据的可用性。
3 问题描述与建模
智能电表细粒度的电器消费记录给用户带来了巨大的隐私泄露风险,但同时也为电力资源供给与调度提供了强有力的数据支撑。因此,智能电表隐私保护一方面需要破坏细粒度的原始数据波形,实现用户用电模式的模糊化;另一方面要求保证电力公司对用户电力计费准确性和电力数据聚合挖掘对电网运营维护的有效性。
在整个智能电网中存在数量繁多的智能电表,为用户端到电力公司的数据采集和传输提供支持。假设智能电表的用户集合为,智能电表每隔一段时间进行一次数据采集,将用户智能电表采集的消费数据序列记作X ,用x 表示序列元素,x 可以是电压、电流以及功率等(下文提及的x 以功率为主),则单个用户智能电表数据序列可以表示为:
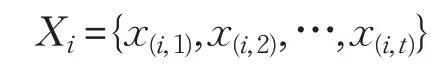
其中,Xi和x(i,t)分别表示用户i 消费的电力数据序列及其智能电表在t 时刻点记录的电力消费数据。同理可以得到经过时延处理后发布的数据序列为:
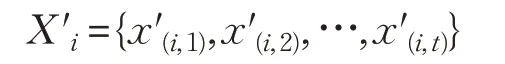
智能电表数据的可用性主要体现在电力计费和电网数据挖掘两个方面,若用r 和T 分别表示电力资源的价格和一个计费周期,用L 表示电力数据挖掘得到的关联规则,例如电力消耗的区域性分布规律等,则智能电表数据可用性的通用模型为:

其中,B(i)表示用户i 在一个计费周期内的电力消费金额,DM()表示数据挖掘算法。
假设攻击者窃取到了智能电表采集的细粒度消费数据,同时利用某种识别算法Rec(),得到用户i 在一段时间内的负载运行状况Y ,其攻击模型如下:

负载运行状况Y 通常由多组状态标签y 表示,y一般描述为y=(t,obj,sta),其中t 表示负载状态转换发生的时刻,obj 表示识别的电器对象,sta 表示电器的运行状态,主要有启动和关闭两种。随后攻击者从一系列状态标签中获取用户负载使用模式,进一步挖掘得到用户的某些个人隐私,从而达到窃取用户敏感信息的目的。
结合上述模型分析,为了实现智能电表数据可用性与隐私安全性的折中,需要保证单个用户在计费周期内电力消费∑t∈Tx(i,t)的准确性,多用户电力消费数据X 聚合挖掘的有效性,同时破坏单个用户电力消费波形的规律性。
4 基于时间扰动的智能电表隐私保护算法
本章针对智能电表数据的可用性模型,结合前文随机扰动和充电电池保护方法的优劣势,为基于时间扰动的智能电表隐私保护算法提供有力的理论基础和应用支撑。
4.1 时间扰动隐私保护算法
在上文中,已经提到智能电表隐私保护中常用的数据扰动机制有随机扰动和充电电池。
随机扰动方法能够有效地模糊单点数值,但其抗滤波的能力较差;充电电池方法能够实现对电力波形的破坏,抗滤波能力强,但其波形破坏程度有限。结合这两种方法,将数值域的随机扰动思想转移到时间轴上,从而得到延时扰动机制。通过加大电力消费在时间轴上的搬移力度,一方面提高扰动机制的抗滤波能力,另一方面实现更强有力的电力波形破坏,达到用电模式保护的目的。下面将对延时扰动机制进行详细介绍。
对于原始序列Xi,数据的采集和发布是即时进行的,即t 时刻记录的电表数据将在t 时刻同时发布。为了达到破坏波形,保护用户隐私的目的,将原始序列Xi的数据记录时刻和发布时刻错开。延时扰动的基本原理如图2所示,对于t 时刻采集到的数据功耗数据x(i,t),在采集时刻t 上添加一个正向时间扰动delay(t),从而确定x(i,t)的发布时刻t′,即t′=t+delay(t)。不同的采集点,在经过正向扰动后可能会得到相同的发布时刻t′,此时将同一发布时刻的所有功耗数据进行叠加,最终得到智能电表在t′时刻发布的消费数据x′(i,t′)。为了更好地表示x(i,t)与x′(i,t′)之间的映射关系,下面定义一个判别函数:

即当参数a=b 时,S=1;否则,S=0。
利用上述判别公式,进一步得到x(i,t)到x′(i,t′)的映射表达式为:


图2 延时扰动算法原理
通过对原始电表数据添加时间扰动,错开数据采集和发布时间,能够有效破坏负载实际运行情况,模糊用户行为模式,从而达到保护用户隐私的目的。
4.2 延时噪声设计
根据时间扰动算法的需求,噪声设计需要满足下列几点要求:
(1)数据实时处理,延时噪声应该为正向扰动。
(2)处理后的发布时刻与记录时刻契合,所以时延单位为整数。
(3)为了避免由于时延产生的误差过大,需要对延时上限加以约束。
本文选取了最常用的几个概率分布,分别为均匀分布、正态分布和拉普拉斯分布。由于正态分布和拉布拉斯分布产生的随机数-∞<n <+∞,为了约束延时噪声上限,对标准分布做以下处理(如图3):寻找特定整数值k,使得当 ||n <k 时,累计的概率大于δ,δ 为某个接近1的数;当 ||n >k 时,n=n mod k。一方面在尽可能不破坏原始分布的前提下,对延时噪声上限加以约束,另一方面使所有值的概率累计为1,保证概率的完整性。k的求解满足下列不等式:

取δ=0.9;根据上式相应得到均匀分布k1≈1,正态分布k2≈2,拉普拉斯分布k3≈3。

图3 拉普拉斯分布概率密度示意图
结合上述分析,可以得到满足本文算法需求的延时噪声表达式如下:

其中,Dmax为延时上限,k 为最大延时系数,为向上取整符号,n(t)表示满足的特定标准分布的随机数。
由此,可以得到满足时间扰动算法的延时噪声函数,根据延时上限Dmax和特定标准分布的随机数n(t)以及相应的延时系数k,就可以求得原始数据点需要加入的延时噪声。
4.3 可用性分析
本文在引言中已经提到过,智能电表数据的可用性主要表现在电力计费、智能电网资源调度与管理、增值服务[1,14]三方面。结合上节的时间扰动模型,分析基于时间扰动的隐私保护方法对于智能电表数据可用性的影响。智能电表数据的可用性大致体现在单个用户在时间上的累计误差和多用户在同一时刻的数据聚合产生的误差。前者保证智能电表电力计费的准确性,后者保证智能电网整体数据聚合的准确性。
单个用户在时间上的累计误差是指经过算法处理后的消费数据与智能电表原始数据在一个计费周期T(一般为30 天)内产生的相对误差,记作e(i),它的表达式如下:

多用户在同一时刻的数据聚合产生的误差是指针对同一区域或具有相同属性标签的N 个用户群体在同一个电表记录时刻由算法引入的相对误差,记作e(t),它的表达式如下:

为了便于进行误差分析我们设定一个时间窗,假设窗口时间跨度为Tw,窗口内数据序列集为Xw。根据模型的扰动机制,得到图4的窗口数据变化。
从图中可以看出,对于一个时间窗而言,在经过时间扰动后,窗口内的数据变化主要分两部分,从上一窗口移入的数据序列集Xin和当前窗口移出的数据序列集Xout,由此可以得到时间窗经过扰动后产生的误差
ew为:

同时考虑数据集Xin和Xout对于误差ew的影响时,由于两个数据集之间产生的数据抵消,使得对公式(12)的后续化简分析存在困难。为了简化误差估算,在这里仅考虑当前窗口移除的数据序列集Xout对窗口扰动误差造成的影响,一方面Xout是当前窗口的部分数据,有利于实时分析;另一方面,这样的分析策略可以有效估计误差与不同变量之间的定量关系,为后续扰动噪声的分布选择提供依据。而且仅考虑数据集Xout得到不同变量之间的定性结果对于误差的原始表达同样是成立的,因为数据集Xin和Xout的数据抵消改变的是公式(12)分子值的量级大小。因此假设误差ew仅考虑当前窗口移出的数据序列集Xout,得到简化误差为:


将式(9)代入上式,则:

根据上式可知仅考虑移出时间窗的数据Xout所造成的相对误差e′w与时延期望E[delay(t)]成正比,与窗口的时间跨度Tw成反比。通过对这两个参数进行控制,能够实现对e′w的有效控制,而实际误差ew比e′w更小;另一方面,在理论上模型仅对功耗信息进行了时间搬移,并未添加额外的扰动,因此在随着窗口的时间跨度增大,误差将趋于0。此外,将表1 中参数代入式(14)可以发现在相同最大延时的条件下,拉普拉斯分布相比其他两种分布产生的误差更小。

表1 三种不同分布的参数对比
4.4 安全性分析
为了能够更直观地衡量不同方法对智能电表数据波形的破坏程度,利用均方根误差(RMSE)来表示数据处理前后的差异程度,其表达式如下:
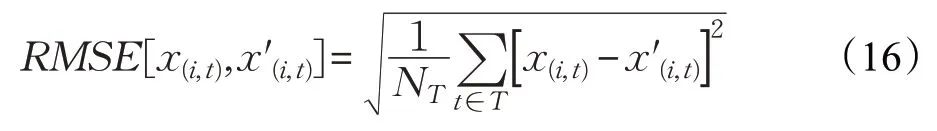
其中,NT表示计费周期内的数据个数。
图5表示不同算法下的均方根误差,通过分析均方根误差可以在一定程度上量化算法对模式的保护程度。从图中可以看到,随机扰动和本文方法相比充电电池方法能够实现更大程度的波形破坏。随机扰动方法的统计距离与最大噪声呈线性递增,随着噪声不断增加直到彻底掩盖原始波形,能够实现最大程度的波形破坏。本文算法对波形的破坏程度受限于数据本身,在不同的延时噪声下能够实现稳定的波形破坏效果。

图5 不同算法的均方根误差分析
智能电表隐私模式保护不同于常规的数值保护,因此很难给出定量的数值分析表达。为了定量分析不同数据扰动方法的安全性,引入非侵入式负载监测算法(Non-Intrusive Load Monitoring,NILM)作为攻击手段。NILM[15-16]是指监测系统在不侵入负荷内部的条件下,利用相应结点电力负荷入口处的电压、电流以及功率变化信息进行对负荷数据进行测量和分析,以得到负荷内部的不同用电设备的功率消耗情况及其相应的比例,从而实现电力负荷分解的一种实时负载监测方法[17]。
采用Weiss等[18]的非侵入式负荷监测方案将智能电表采集的总消费数据进行设备级分解(如图6 所示)。在该方案中,首先确定负载曲线中功耗产生明显变化的时间点,一旦检测到满足条件的边缘,计算物理量之间的跳变差值,并将这种变化标注为一个潜在的设备切换事件。通过对不同用电设备进行标签分类并训练样本集,得到不同类别设备的最佳匹配集群。在对实际用电负荷进行检测时,利用样本标签进行监督式学习,根据负载特性将潜在事件与已知的签名数据库进行对比,最终将边缘映射到单个设备。
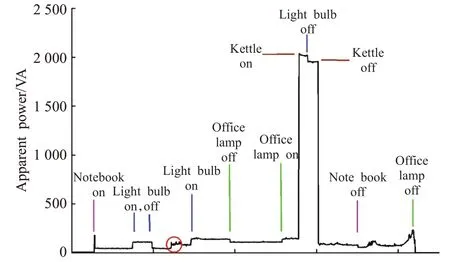
图6 负载监测示意图
利用该负载监测算法对扰动数据中用电设备模式识别的准确率,来判定本文算法的隐私保护性能。
4.5 算法设计
根据本章前几节的数学建模和理论分析,可以得到基于时间扰动的智能电表隐私保护算法的具体描述如下。
输入:原始智能电表数据序列集X 。
输出:时间扰动后的电表数据序列集X′。
方法:
(1)确定时间窗尺寸Tw以及最大时延Dmax,根据Tw生成相应的循环存储器用于存储存储叠加时延后的数据点和其相应的发布位置,并筛选出Xout。
(2)选择时延噪声模式(随机、正态或拉普拉斯分布),对每一个数据点添加相应的正向延时。
(3)对时延后的数据发布点做一次判断,若发布点超出计费周期,则存储到Xout,否则存入循环存储器等待叠加发布。
(4)重复执行步骤(3)直到没有新的数据进入,得到时间扰动后的电表数据序列集X′,以及从当前窗口移出的数据序列集Xout。
(5)发布扰动后的电表数据序列集X′给电力公司或第三方数据使用者。
通过引入时间扰动破坏电表原始波形的结构性来实现隐私保护算法,能够有效避免攻击者针对用户隐私的挖掘行为,同时保证电表数据在电力计费和资源调度分析等方面的可用性。与现有的随机扰动和充电电池方法相比,在相同的扰动尺度下,基于时间扰动的保护方法能够得到更有效的波形破坏效果,进而提供更强的安全性保障,下面通过实验对此进行验证。
5 实验结果分析
为了检测本文算法的有效性,采用真实的电力消费数据对算法进行评估,并分别用误差分析和NILM算法对本算法在可用性和安全性两个角度进行评估。
5.1 实验数据来源
数据集采用开放的ECO数据集[10],该数据集提供了电源开关的综合电力数据以及连接到具体电器的智能插座数据的组合。数据集以1 Hz 的采集粒度,收集了瑞士6个家庭8个月(2012年6月至2013年1月)的超过1亿次的测量数据,每个测量值包含了被测家庭测量时刻的电压、电流以及相位信息,数据采集频率高,时间跨度长。
5.2 时间扰动模式的选取
应用本文隐私保护算法后,仅对移出窗口数据进行相对误差e′w计算,实验结果如图7 所示。这里随机选取了ECO数据集中某一天电表记录数据,使用了3种不同分布的延时噪声:均匀分布、正态分布以及拉普拉斯分布,最大延时设定以200 s 为步长,范围为0~3 600 s,选取的窗口大小为1 d,即86 400 s。从图7可以看出,当噪声曲线趋于稳定后,相对误差e′w与最大延时呈正相关,且在保证最大延时相同的情况下,拉普拉斯分布产生的误差最小,均匀分布产生的误差最大。根据表1的参考系数,结合理论分析得到的结果与实验基本一致。因此本文算法之后的相关实验,采用拉普拉斯分布作为时间扰动模式。
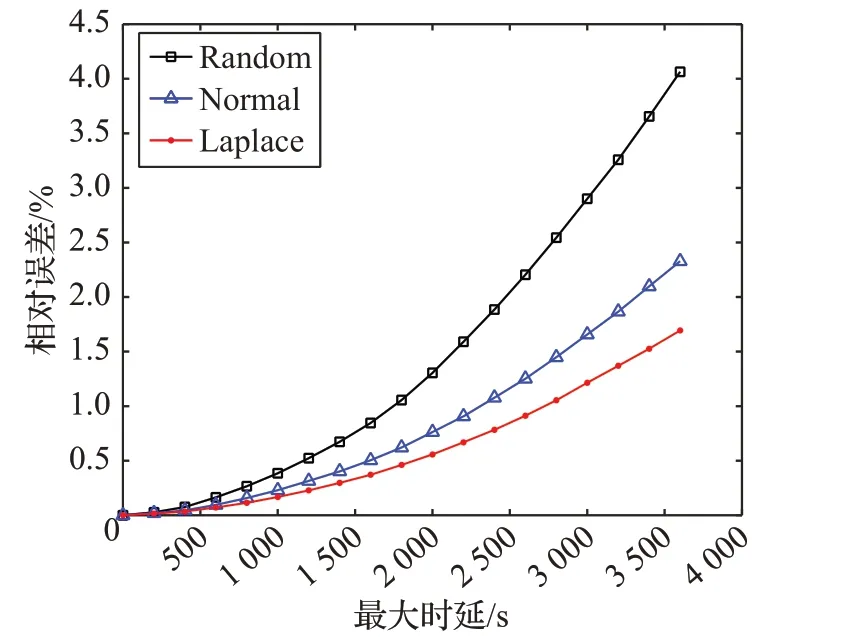
图7 不同噪声延时的误差e′w 分析
5.3 安全性对比实验
基于ECO 数据集对用户的综合电力数据进行扰动,检测不同扰动方案下NILM 的识别准确率,以评估时间域扰动方案对于隐私安全保护的性能。选择3 个主要参数评价NILM 监测的结果并对实验结果进行分析,分别是查准率P 、查全率R 以及F1 度量。 F1 度量是基于查准率和查全率的调和平均定义的:

本文实验选取了Weiss算法下匹配结果最优的4种电器类型:fridge、freezer、dishwasher、kettle,来对比本文算法与随机扰动和充电电池算法的隐私保护强度。
根据图8~10,对比充电电池算法和本文算法抑制电器检测识别的效果。从图8可以看出,相比充电电池算法,本文算法对于四种电器查准率的抑制效果在30%以上,效果最低的fridge比充电电池算法高10%,效果最高的dishwasher 比充电电池算法高60%。在查全率上,如图9所示本文算法也优于充电电池算法,对各项电器的平均抑制效果提高10%以上。F1 参数是评判识别算法效果的综合指标,根据图10的对比结果,本文算法可以让Weiss 算法的识别效果下降50%,稳定状态下比充电电池算法提高10%以上。结合图5均方根误差分析,可以发现本文算法相比充电电池方法具有更有效的波形破坏效果。因此,本文算法对于不同电器在各项指标上都优于充电电池算法,而且本文算法对于电器检测识别的抑制效果收敛速度快,10 s左右的小时延就能得到最优的稳定效果。

图8 3种算法查准率对比

图9 3种算法查全率对比

图10 3种算法F1参数对比
图8 ~10的(b)为随机噪声扰动下电器检测的效果,从图中可以发现,小功率电器(fridge、freezer)和大功率电器(dishwasher、kettle)趋于稳定的噪声点是不同的,前者大概在200 W 左右,后者大概在2 000 W。识别效果趋于稳定的最大噪声功率约为电器本身功率的2倍。对比本文算法与随机噪声扰动的实验效果,可以发现在查准率上随机扰动的抑制效果更好,本文算法在查全率的抑制效果更好,根据F1 参数,总体上两种扰动机制对于电器识别的抑制效果在伯仲之间。但实际上由于随机扰动机制本身的限制,噪声很容易被一些线性滤波器(例如维纳滤波器)抵消,导致隐私保护强度下降。而本文算法由于是在时间轴上添加噪声,导致数值上的变化很难被滤波攻击消除,具有更强的隐私保护效果。
根据上述分析,在查准率、查全率和F1 这3个参数上,本文算法对于电器识别表现出良好的抑制效果。相比于随机扰动和充电电池方法,本文算法表现出更高的波形破坏效率,更好的隐私安全性,并且对识别抑制趋于稳定的速度更快。
5.4 误差对比实验
为了定量分析本文算法对电力计费的影响,统计了单用户时间累计误差,并与随机扰动和充电电池方法进行对比。其中实验的时间周期为1 d,扰动尺度范围为0~1 000,区间间隔为50。为了更直观地对比3 种方法的误差结果,将3 种方法不同的扰动参数进行了尺度统一。
图11 表示单用户时间累计误差的对比结果,从图中可以看出随着扰动尺度的增大,对原始波形的破坏越显著,则单用户在计费周期上的计费误差将逐渐增大。3种算法的相对误差都呈上升趋势,但在实验尺度区间范围内,随机扰动方法的相对误差最高到达1%,而充电电池方法为0.003%,时间扰动方法为0.1%。由此可见随机扰动方法的误差上升速率大概为时间扰动方法的10倍,同时约为充电电池方法的300倍。这种巨大的误差差异主要是因为随机扰动方法是直接向原始数据中添加噪声扰动,引入额外误差的可能性更大,而另外两种方法在本质上都是对原始数据进行时间搬移,并未引入额外的数值噪声。此外充电电池方法是对单点数值的部分搬移,时间扰动是对单点数值的整体搬移,因此在计费误差上,充电电池方法有更好的效果。结合安全性实验,可以发现本文算法在计费误差上的损失,同时也带来了更好的波形破坏效果,提供更强的隐私安全性。
图12 表示多用户在单一时刻的聚合误差对比结果,这一误差决定了电表消费数据在聚合挖掘分析中的可用性。由于本文方法存在小尺度变化导致误差大幅上升的情况,对尺度区间进行单独调整,分别为0~45,步长为5,以及50~1 000,步长为50。从图12 中可以发现,误差大小随着扰动尺度的增大而呈现上升趋势。其中随机扰动方法逼近线性递增结果,而充电电池方法和本文方法的聚合误差分别稳定在2%和10%左右。在多用户单一时刻的聚合误差上,本文算法相比随机扰动方法在较大的扰动尺度上具有更小的误差结果,相比于充电电池方法虽然在误差表现上较差,但本文算法相比于充电电池方法又有更强的安全性。

图11 单用户时间累计误差

图12 多用户单一时刻的聚合误差
结合上述实验分析,本文算法能够有效地将电器切换事件的识别效果降低50%左右,多用户的聚合误差稳定在10%左右,同时在计费误差上有着优异的表现。本文算法在数据可用性和隐私安全性的综合性能相比于其他两种扰动方法表现更好,低于100 s 的时间扰动就能够提供足够的隐私保护强度,同时在计费误差和聚合误差上表现良好,为基于电力数据的应用和挖掘分析提供良好的可用性与安全性支持。
6 结束语
针对现有智能电表隐私保护算法存在模式保护力度不足的问题,本文提出了一种基于时间扰动的智能电表隐私保护方案,对原始消费数据进行延时重组,从而破坏电表记录的功耗数据波形,达到模糊用户行为模式的目的。在保护电表用户隐私安全的同时,也在一定程度上保留智能电表数据在计量计费和数据聚合挖掘的可用性。一方面可以通过改动时延参数使得单用户计费误差维持在0.1%以下,多用户数据聚合误差稳定在10%以内的可控范围,保证计费和数据聚合分析的可用性;另一方面利用NILM算法对比不同方案的隐私保护效果,相比于其他两种方案,本文算法能够将NILM 算法对智能电表数据的识别准确率降低50%左右,波形破坏效率更高,小尺度扰动就能实现模式识别抑制的最优效果,保障用户隐私信息的安全性。
同时本文算法也存在有待改进的地方,从误差对比实验中可以发现,本文算法的整体表现不如充电电池方法,单时刻记录的整体搬移带来了更有效的波形破坏效果,但也导致了时间累积误差和多用户聚合误差的增大。此外,本文对基于时间扰动的智能电表隐私保护方法进行了安全性和可用性的理论和实验分析,但缺少对算法抗干扰抗攻击能力的考查。后续研究中,一方面需要进一步优化延时模式和模型参数,更好地协调隐私安全性和数据可用性;另一方面,需要增加抗攻击实验,比如滤波攻击等,从而验证并提高算法的鲁棒性。
猜你喜欢
通信电源技术(2022年10期)2022-09-21
环球时报(2022-06-30)2022-06-30
中国交通信息化(2022年1期)2022-04-19
中学生数理化·中考版(2021年10期)2021-11-22
数学小灵通·3-4年级(2020年4期)2020-06-24
Special Focus(2019年1期)2019-01-30
中国计算机报(2018年35期)2018-12-04
数学大王·低年级(2018年5期)2018-11-01
通信电源技术(2016年5期)2016-03-22
百科探秘·航空航天(2015年3期)2015-12-01
