
基于稀疏自编码支持向量机泵站故障检测
2020-01-01 02:34:38殷振兴
水科学与工程技术 2019年6期
殷振兴
(江苏省淮沭新河管理处,江苏 淮安 223005)
泵站主要承担水资源调度任务,当泵站运行状态劣化到一定程度,机组正常运行受到影响,无法正常生产工作,则泵站系统出现故障[1]。 机械故障的特点主要表现为潜在性、渐发性、耗损性等[2],对于泵站机组中水泵与电机等旋转机械,主要有基础松动、轴承故障、油膜振荡等故障,这些旋转机械中几乎过半故障均为转轴引起[3],转轴故障一般为不对中故障、油膜涡动及转子质量不平衡等[4],因此,对转轴进行故障检测保证转轴正常运行具有重要意义,有利于梯级泵站更好地运行。
针对多要素不确定性故障,根据深度学习理论知识构建稀疏自编码器,可完成泵站故障特征表达,再结合支持向量机(SVM)良好的分类能力建立自编码的SVM故障检测模型,以达到泵站不确定性故障检测目的。
1 计算原理与方法
近年来深度学习在科研领域被广泛应用,相比之前的神经网络,深度学习深度神经网络(Deep neural network,DNN)算法在输入与输出层间包含了多于一层的隐含层,是一种前馈人工神经网络,识别率提高了一个档次。
1.1 稀疏自动编码器
自动编码是一种典型的无监督学习,本质是神经网络结构中的一层隐含层,其目的是为了表达网络的输入等于输出这一等式[9]。 若多层神经网络也被视为一个多层结构编码系统,其输出均等于输入,提取出每个隐含层的激活值,便得到多组原始数据的新表达方式,其激活值与原始数据形成新的特征映射。这便是一个特征学习的过程,亦是自动编码可行性的出发点。
隐藏神经元的数量较大,可能比输入像素的数量还多,若不稀疏化将无法得到输入的压缩表示。Hinton提出的一种防止神经网络过度拟合的Dropout方法[10],是一种解决此问题的技术。稀疏编码前后的模型对比如图1,关键是在训练期间从神经网络中随机丢弃单位(及其连接)。 可以防止过多单元之间的相互适应。在训练期间,从指数数量级的不同“稀疏”网络中抽取样本。在测试时,通过简单地使用具有较小权重的单个未稀疏网络,很容易近似平均所有这些稀疏网络的预测效果。
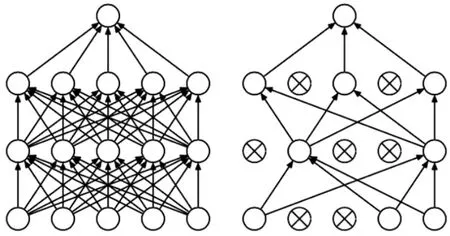
图1 稀疏编码前后的模型对比
1.2 支持向量机
若为一个分类问题,神经网络在得到编码数据后将数据输入输出层得到结果,其输出层仅依据结果比重进行类别划分,缺少一个寻优的决策过程。而SVM对事物划分是依据事物本身特征进行二次寻优,得到有效的寻优分类面。
1.3 稀疏自编码支持向量机模型
综合稀疏自动编码与支持向量机的特点,建立了稀疏自编码支持向量机模型,泵站故障检测原理如图2。
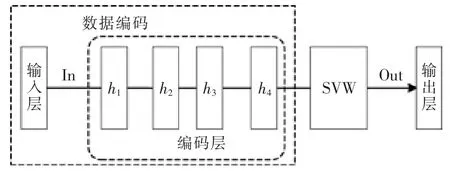
图2 泵站故障检测原理
2 泵站仿真实验研究
2.1 SVM故障检测可行性实验
为验证SVM对转轴油膜涡动故障检测的可行性,在正常运行与油膜涡动倍频上各取100组能量分布数据。通过观察频谱结构发现二者在1~4倍频成分上分布相似,但半频成分上,正常运行时所取样本值较小,而油膜涡动时却近似为1,可见油膜涡动时与正常运行情况有明显区别。
利用SVM进行测试,发现油膜涡动时在振动频率特征分布上区分度较正常运行时大,与观察频谱结构规律一致,正确率100%。 实验测试结果显示自编码的SVM亦可达到满意的检测结果,表明SVM在小样本故障简单情况下检测的有效性。
2.2 故障特征提取必要性实验
若遇到更为复杂的情况,SVM检测方法是否可以继续保持良好的检测性能,下面做进一步验证。
同样各取100组正常运行样本和不对中样本数据,观察发现两者在频率分布上差异性较小,均存在较为丰富的高频成分,无法通过频谱结构得出检测结论。
对100组样本数据建立检测不对中故障SVM,模型惩罚因子c取5000,核函数宽度取100。 结果表明正确率仅70%,SVM分类器无法获得不对中故障知识,从而亦无法得到高精确度的检测结果。
根据前述设计计算原理与方法进行无监督学习构造多层自动编码层,并基于训练数据通过BP算法对整体编码系统开展微调,稀疏自编码系统微调的迭代精度曲线如图3。
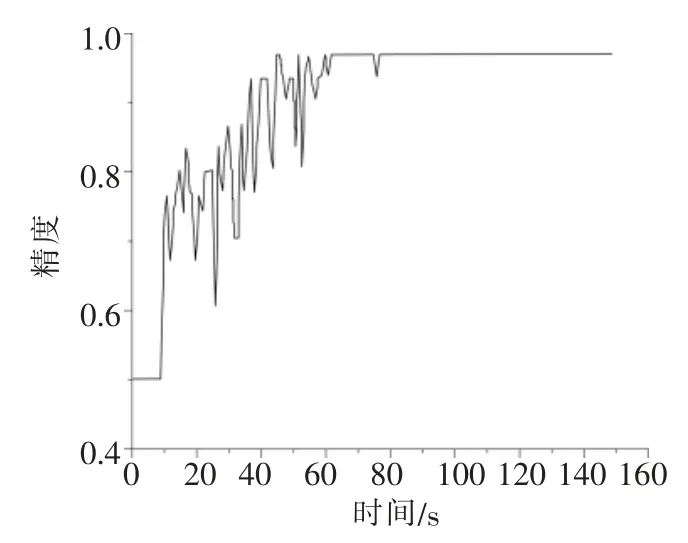
图3 稀疏自编码系统微调迭代精度曲线
图3显示了稀疏自编码器微调过程,即两类信息在保持原始信息不变时编码特征又一次组合,亦可以表述为泵站故障特征重构特征的过程。可以看出,0~60s时,整个编码系统精度波动较大但整体呈上升趋势,表明在0~60s迭代时精度上升较快,效果提升明显。 60s后逐渐收敛于一个固定值。
为保证与实验输入数据维度一致,选取h3层数据输入已训练好的SVM。
微调后,抽取h3层编码数据进行SVM的模型训练。取10组泵站不对中故障数据进行模型测试,稀疏自编码的SVM测试结果能够准确检测出对应的泵站故障,正确率达100%,远高于了仅使用SVM分类器正确率的70%。 表明稀疏自编码的SVM对于泵站不对中故障检测具有可行性、有效性。
为检验模型检测精度提高是否受到特征提取的影响,模型编码层对故障数据是否具有有效的特征提取能力,提取编码后的数据进行比较分析:
(1)首先将原始数据经过稀疏自动编码器编码,使原始特征重新分布到现在的5个维度上。
(2)其次使用样本类间距离评价特征提取效果,随机从正常样本及不对中故障样本各选2组进行计算类间距离。
(3)最后从这两类中各选1组计算样本距离(随机进行5次取平均值),样本类间距离如表1。
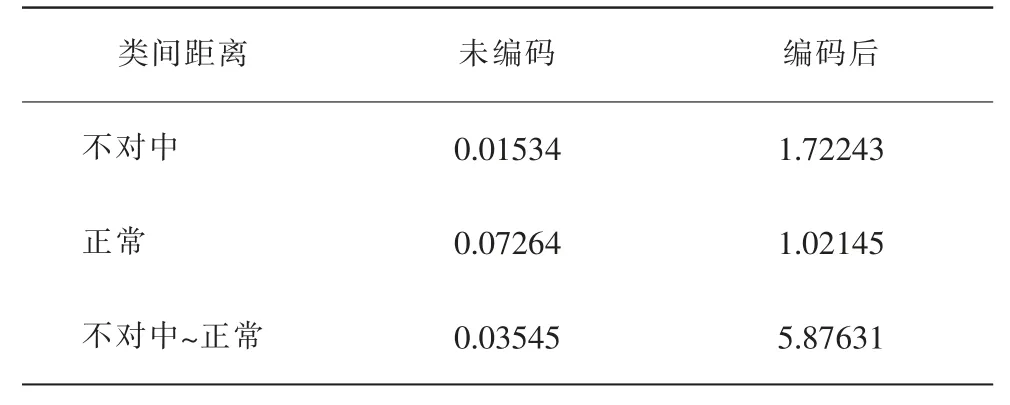
表1 样本类间距离
视2组数据距离越短为同一类别可能性越大[11],未编码数据计算类间距离均接近于0。表明数据相似大,难以做出正确区分。编码后样本数据之间的距离均较大,编码前后两类数据分布如图4和图5。
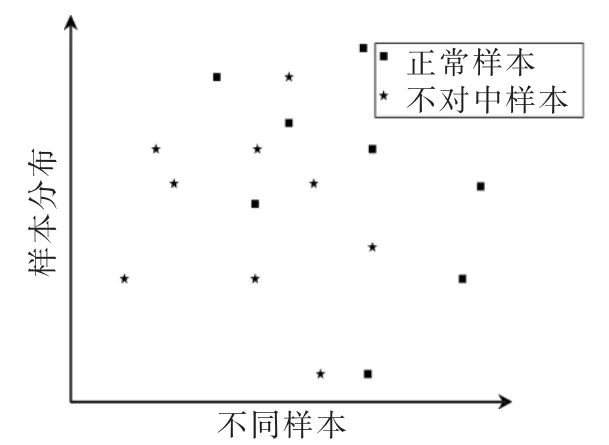
图4 未编码两类数据分布
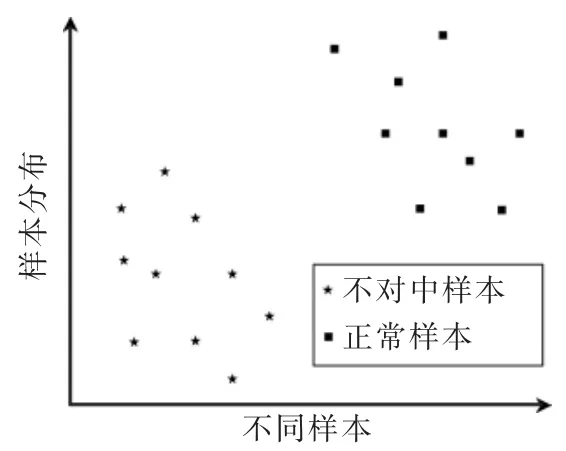
图5 编码后两类数据分布
可以看出编码增加了两类数据的类间距离,即通过编码使得本来相似度大的频率特征重新分布。表明编码层对于两类数据得到了较好的特征表达,验证了其有效提取特征的能力。
实验结果表明稀疏自编码的SVM识别故障方法与SVM方法对比结果显著,但是否对于其他识别方法仍具有优势,下面以相同结构的BP神经网络开展进一步实验,分别从检测时间、训练精度、测试精度3个方面对比不同检测方法的实验结果,不同检测方法实验结果如图6。
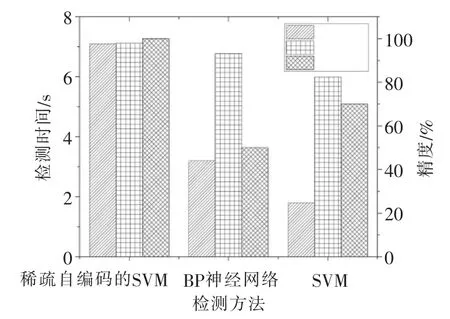
图6 不同检测方法实验结果
(1)检测时间。3种方法所用时间分别为7.1,3.2,1.8s,稀疏自编码的SVM检测方法耗时最长,可能是因为稀疏自编码的SVM模型复杂度较高,运算量较大。
(2)训练精度。 3种方法训练精度分别为97.9%,93.2%,82.4%,稀疏自编码的SVM的检测方法在训练集上出现了最好的检测结果,依次为BP神经网络和SVM。
(3)测试精度。 3种方法测试精度分别为100%,50%,70%,稀疏自编码的SVM的检测方法在测试集上表现出显著的优越性,这是因为SVM求解分类面时,只受支持向量影响,而与其他样本无关。 稀疏自编码的SVM结合了自编码器的特征提取能力及SVM较强的分类面寻优能力。
从实验结果可知,SVM检测方法耗时最少,但训练精度与测试精度均较差,BP神经网络的检测方法虽然在训练集上表现了较好的检测结果,但测试集的结果只有50%,稀疏自编码的SVM虽然耗时稍长,但鲁棒性强,识别精度最高。 此外稀疏自编码的SVM检测方法在故障检测中摆脱了人工特征提取的局限性,在泵站故障检测中表现出良好的优越性。
3 结语
(1)对于有限样本情况下,稀疏自编码的SVM检测方法在泵站故障检测可获得较高的精度,验证了方法的可行性、正确性及有效性。
(2)对比了SVM、稀疏自编码的SVM、BP神经网络3种泵站故障检测方法,得出稀疏自编码的SVM虽然耗时稍长,但鲁棒性强,识别精度最高。 此外稀疏自编码的SVM检测方法在故障检测中摆脱了人工特征提取的局限性,在泵站故障检测中表现出良好的优越性。
猜你喜欢
湖南水利水电(2021年6期)2022-01-18 06:07:40
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09 06:12:12
汉字汉语研究(2020年2期)2020-08-13 07:52:48
电子制作(2019年22期)2020-01-14 03:16:24
疯狂英语·新读写(2018年3期)2018-11-29 22:37:11
电子制作(2018年19期)2018-11-14 02:37:08
河南水利年鉴(2017年0期)2017-05-19 02:32:09
自动化学报(2017年11期)2017-04-04 02:52:58
河南水利年鉴(2016年0期)2016-08-03 05:01:40
河南水利年鉴(2015年0期)2015-08-16 04:25:49
