
改进的大数据检索自适应性切换搜索算法*
2019-12-30 07:03:00吴雨晨刘萍萍徐江涛
西安工业大学学报 2019年6期
吴雨晨,刘萍萍,徐江涛
(西安工业大学 计算机科学与工程学院,西安710021)
大数据云计算技术是一种分布式计算的拓展,其在执行工作时可将庞大的计算程序进行分解,得到很多个更小的子程序,由集群来统一的完成计算工作,并将最终的计算结果反馈给用户。当前已经出现的分布式搜索引擎技术已经有很多种,例如Ajax技术、基于策略的分布式架构技术、基于Web service技术的分布式搜索引擎以及基于P2P技术的分布式搜索引擎等。分析发现,此类搜索引擎主要都是介于Lucene全文检索引擎工具包来实现的,但是这种方式建立索引的效率较低。Hadoop 分布式系统作为一个强大的分布式计算平台,具有较高的兼容性,其能够运行在不同的硬件平台中。目前Hadoop分布式系统已经逐步应用到了不同类型的智能系统中,使其系统的性能更加优越。
文献[1-2]从全文检索的原理出发提出基于.net的索引器的海量非结构文本搜索,验证了搜索引擎优化的效果。文献[3-4]针对检索网络的复杂变动与检索关键字的语义出发,基于Lucene架构的搜索得分排序算法提出了结合词项位置、文档浏览量、更新时间等因素的AHP二次检索公式,改进的AHP二次检索公式能更有效地提高信息检索的准确度。文献[5-6]针对搜索的实体信息分散且缺乏语义,传统搜索引擎语义如上下文信息时长缺失的缺点,用信息网模型(INM)对Web数据进行语义表示和建模,将实体的所有语义信息组织在一个对象中,快速获取实体完整的语义信息,基于INM构建复杂语义数据库优化搜索引擎性能。文献[7-8]针对特定领域中的专业规律,为了更好的满足专业领域用户的信息需求,构建了主题搜索引擎。该引擎采用锚文本匹配进行领域关键字过滤、加入IKAnalyzer中文分词器,排序搜索结果,并通过STC算法对结果实时聚类,其构建的主题搜索引擎能更高效的在专业领域进行搜索。文献[9-11]针对数据实体信息与转化语义信息之间的关联性误差,提出本体模型分词高斯边缘化融合的特定语义数据检索算法,从而克服中心频率变化对关联性能的影响,实现海量数据干扰下算法的改进,改进算法消除大量关联性误差,提高搜索引擎查准率。
现有搜索算法在复杂问题搜索上性能不足且误差较大,本文拟采用Hadoop分布式计算平台来建立分布式搜索引擎,利用Map-Reduce实现分布式索引模块,最终通过优化自适应性切换搜索算法来提高搜索引擎性能。
1 Hadoop分布式平台及框架
Hadoop分布式平台是一种分布式的系统架构,Hadoop最初分为三部分[12-13],分别是Hadoop Common、HDFS(Hadoop Distributed File System)以及Map-Reduce,每部分能够发挥不同的功能,此外还有很多相关的开源框架。Hadoop分布式平台的组成结构较为复杂,其中最底层为 HDFS,也就是一个分布式文件存储系统。HDFS不仅能够实现文件管理系统的各添加以及删除等操作,而且具有传统存储方式所不具有的优势。基于Hadoop平台来实现对数据的处理和存储具有很大的优势,尤其是对于海量数据的存储和管理,而且对于故障的恢复率比较高、可移植性较强。HDFS组织架构如图1所示。
本文设计的分布式搜索引擎为企业或个人提供个性化的搜索服务,为保证服务器端HDFS文件系统与客户端文件系统的同步,需要对Windows本地文件系统进行监控。因此客户端必须具有多个功能,例如对文件的上传、下载、新建、删除以及修改等操作的实时监控功能。服务器端主要实现的是存取文件以及同步事件等功能,例如需要对文件修改、删除以及建立等事件进行同步处理。
分布式索引子系统主要是对预处理之后文档的分词处理等,能够得到倒排索引并存储到倒排索引库内,其系统总体架构基于Map-Reduce框架实现。实现基于字符串的查询功能,通过界面获得使用者输入的文本,对其进行解析得到关键词等条件,并对倒排索引库进行查询即可得到最终的结果。具体的分布式查询子系统整体架构为:① 输入查询内容。② 对查询内容进行中文分词。③ 对分词结果执行查询。④ 获得查询文档的倒排索引。⑤ 将查询文档的倒排索引存储到索引库。⑥ 利用Map-Reduce计算框架按行分割查询结果,key为文本偏移量,value为一行文档的内容。⑦ 将⑥结果再进行一轮Reduce过程,合并索引的查询结果。
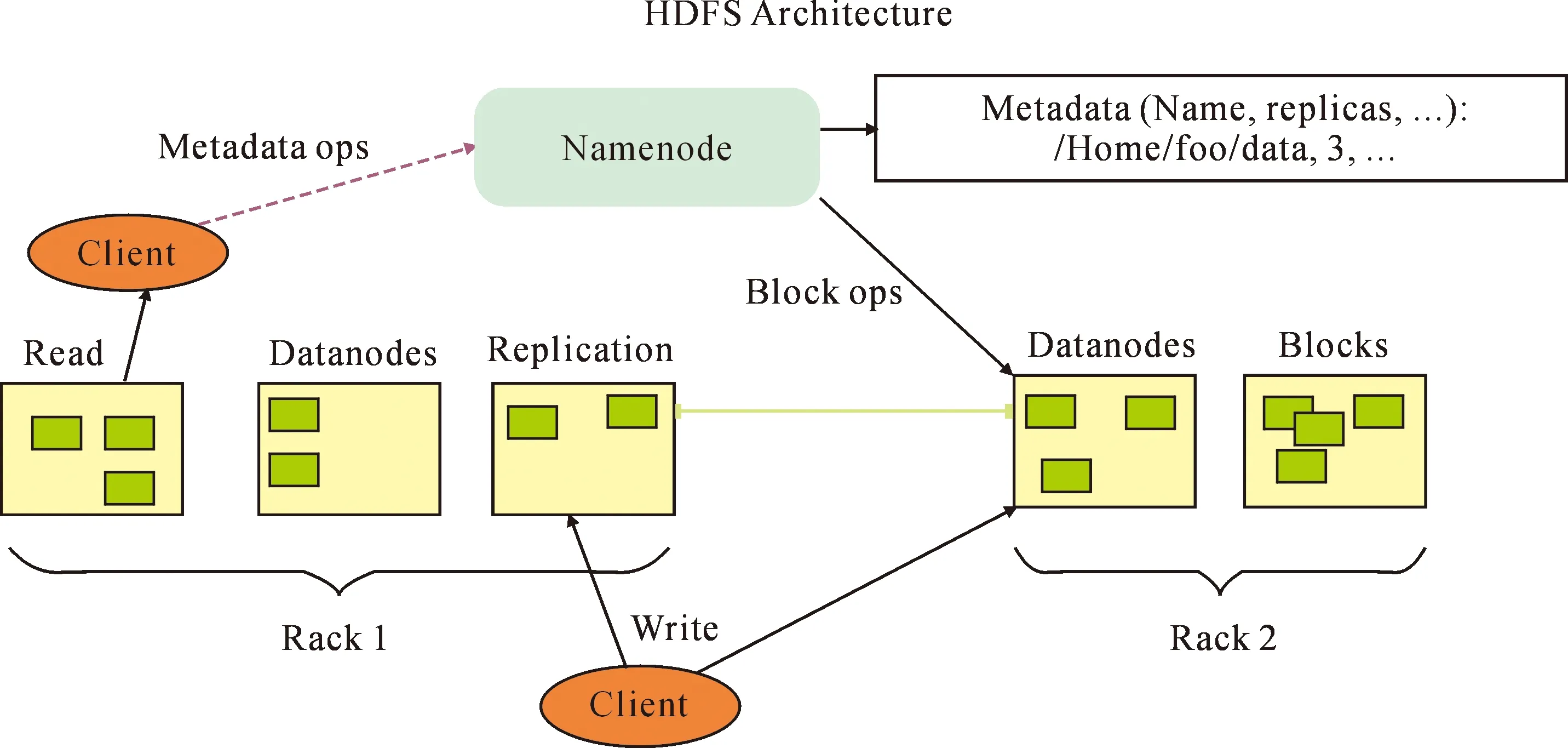
图1 HDFS组织架构Fig.1 HDFS organization
2 算法优化
2.1 TF-IDF算法
通常文档数据量非常巨大,用户进行查询时会得到很多不同的查询结果[14]。为找到与用户真正需求一致的查询结果就需要借助于一定的评分策略,通过特定的网页评分功能来满足用户对查询结果精确性的要求。基于大数据的数据检索系统系统,不同文档之间都是相互独立的,而同一个文档内的标题和内容具有较强的关联性。为了使系统满足用户的个性化查询需求,设计了一种基于用户偏好的搜索方法,并且结合了TF-IDF(Term Frequency-Inverse Document Frequency)算法来改进现有的文档评分策略,从而为用户提供真正符合其需求的搜索服务。
TF-IDF作为一类统计方法,能够有效地对文件集中某个文件的重要程度进行合理地统计。其原理可以理解为两层含义:① 可以认为某个词在文档中出现的次数在很大程度上能够表明这个词与文档的相关程度,这个词出现的次数越多说明相关性越大;② 某个词用来验证文档相关性的作用与含有此词的文档数是一种反比关系。TF-IDF算法的计算公式为
(1)
(2)
tfidfi,j=tfi,j×idfi
(3)
式中:ni,j为文件dj中词的数量,∑knk,j为文件dj中的所有词之和。|D|为语料库的文件数目,|{j:ti∈dj}|为含有词语ti的文件数,而tfidfi,j为词ti和文档的相关性大小。在一份给定的文件里,词频(Term Frequency,TF)为某一个给定的词语在该文件中出现的频率,它是对词数(Term Count)的归一化,以防止它偏向长的文件。对于在某一特定文件里的词语ti来说,它的重要性可表示为逆向文件频率(Inverse Document Frequency,IDF),是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。本文对原始的TF-IDF算法进行了改进,在计算Rank评分时将文档中词的位置纳入影响因素,对于文档中标题和正文出现的关键词分别设置不一样的权重值。例如在词频值计算方面,标题中含有此关键词时就将词频值大小增加6;正文内出现关键词时就将词频值大小增加1。
2.2 算法优化
本文设计的自适应性切换搜索算法,需要基于索引的大小来针对性的处理索引过程。如果索引很小,可以将其直接存入内存;如果索引文件很大,可以建立二级索引,读到内存中的索引列表,可以进行分布式的查询。通过这种方式可以有效地提高对索引文件的搜索效率。
自适应性切割搜索算法的基本原理是基于索引文件大小选择合适的搜索算法[15-16],以256 MB大小的索引文件为界限,如果索引文件大小不超过256 MB,此时用户查询时将索引文件读进内存,对其直接进行查询。如果索引文件大小超过256 MB,需要构建二级索引,查询时先将二级索引读进内存中,用户先对此二级索引进行查询,并以此来查询到原始的索引文件。最终获取的索引文件即为Map-Reduce查询任务的输入,可以得到最终的查询结果。在执行Map-Reduce任务时,将输入文件分割为多个split,同时为每个split建立Mapper。通常情况下split是64 MB,如果输入文件很少,只需少数Mapper就能完成处理任务,此时不能充分发挥分布式计算的高性能优势。同时可能会因为过多的文件分割以及分发过程使得计算效率降低。默认情况下,Map-Reduce任务处理小于256 MB的文件是采用直接将其读入内存的方式,而超过256 MB采用的是并发执行4个Mapper的方式。相关统计数据表明,当前在汉字中使用最普遍的词大约有56 000左右。如果索引文件中囊括了全部的词,此时也可以加载二级索引文件到内存中。另外关键词通常只有少数几个,此时通过建立二级索引的方式,就可以有效地降低查询时的索引文件数。
算法的具体执行过程如下:
1) 对索引文件的大小进行统计,当索引文件超过256MB时就建立二级索引,并将其存储到HDFS。二级索引建立过程如下:
① 启动查询器。
② 统计索引文件大小。
③ 判断索引文件是否大于256M,若索引文件小于或等于256M直接写入内存;索引文件大于256M,流程继续执行。
④ 判断是否已经存在对应二级索引文件,若存在,则将二级索引直接利用哈希表写入内存;若不存在则流程继续执行。
⑤ 对当前索引文件构建倒排索引。
⑥ 加入倒排索引数据库。
⑦ 构建二级索引。
⑧ 加入二级索引库,并写入内存。
2) 对是否存在二级索引进行判断,同时使用flag变量进行表示。如果不存在二级索引,就直接把索引文件存入特定的数据结构中。具体的数据结构如图2所示,其主体是多个哈希表,在每一个哈希表中都有一个指向冲突链表的指针,而哈希值一样的关键词就组成了链表结构。链表节点也就是结构体,其含有关键词及其文档索引信息等。
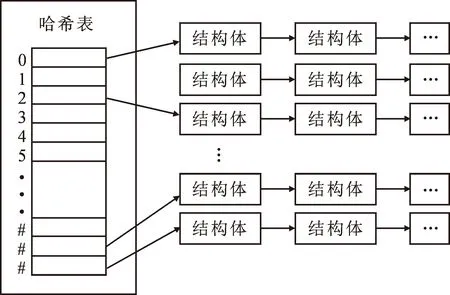
图2 哈希链表结构示意
3) 如果索引文件很大,此时也需要先将二级索引加载到一个数据结构中,但是此数据结构与之前的哈希链表结构有所不同,其链表结构体主要包括了关键词及其索引文档URL。
4) 自适应搜索算法首先是系统获取用户输入的查询内容,作中文分词处理。
5) 此时需要对索引文件大小进行确定,如果其低于256 MB,可以直接按照关键词的哈希值来查询内存中的索引文件并得到结果。
6) 当索引文件的大小超过了256 MB时,需要基于关键词的哈希值来查询二级索引文件。此时将得到的索引文件作为Map-Reduce输入,来得到最终的查询结果。
同时需要基于Map-Reduce框架来建立二级索引,其步骤如下:
① 执行Map-Reduce任务的输入即为之前的倒排索引文件,使用TextInputFormat完成对输入文件的分割。
② 将输入文件中没行内容作为Map()函数的输入,此时的新key值也就是其中含有的关键词;相应的新value值即为关键词所在文件的URL。
③ 通过Reduce()来合并Map()函数的输出,并将最终的结果存储到HDFS文件系统的二级索引库内。
2.3 算法测试
在测试自适应搜索算法的计算性能时,采用了按照大、小索引两种类型计算的方式,并与之前算法的计算性能作对比。测试结果见表1和表2。

表1 小索引文件新旧算法性能测试结果

表2 大索引文件新旧算法性能测试结果
进行查询测试时,选取了五组低于256 MB的索引文件来进行测试。针对每一组索引文件作10次查询,统计每次的查询时间并计算出时间的平均值。测试结果如图3所示,从图3中可以发现,小索引情况时使用新搜索算法花费的时间明显低于原始搜索算法,这说明这种新算法在性能方面具有较大的优势。
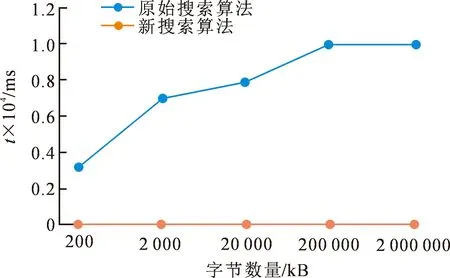
图3 小索引的算法测试结果比较
测试超过256 MB的索引文件的查询性能,这里选择了三组索引文件进行测试。针对每一组索引文件作10次查询,统计查询时间并计算出时间的平均值。得到的测试结果如图4所示,可以发现使用新搜索算法进行查询花费的时间显著小于原始的搜索算法。
通过测试发现,使用文中算法的查询效率显著提高,原因是由于本文的查询测试是基于5节点集群,共有4个索引文件,关键词数也是4个左右,因此关键词可能出现在2个或者是3个索引文件内。而通过二级索引检索能够降低索引文件数,使其变为2个或者3个。同理,如果集群的节点更多,可以将索引文件进行更精细的划分,新算法的计算效率也会更高。
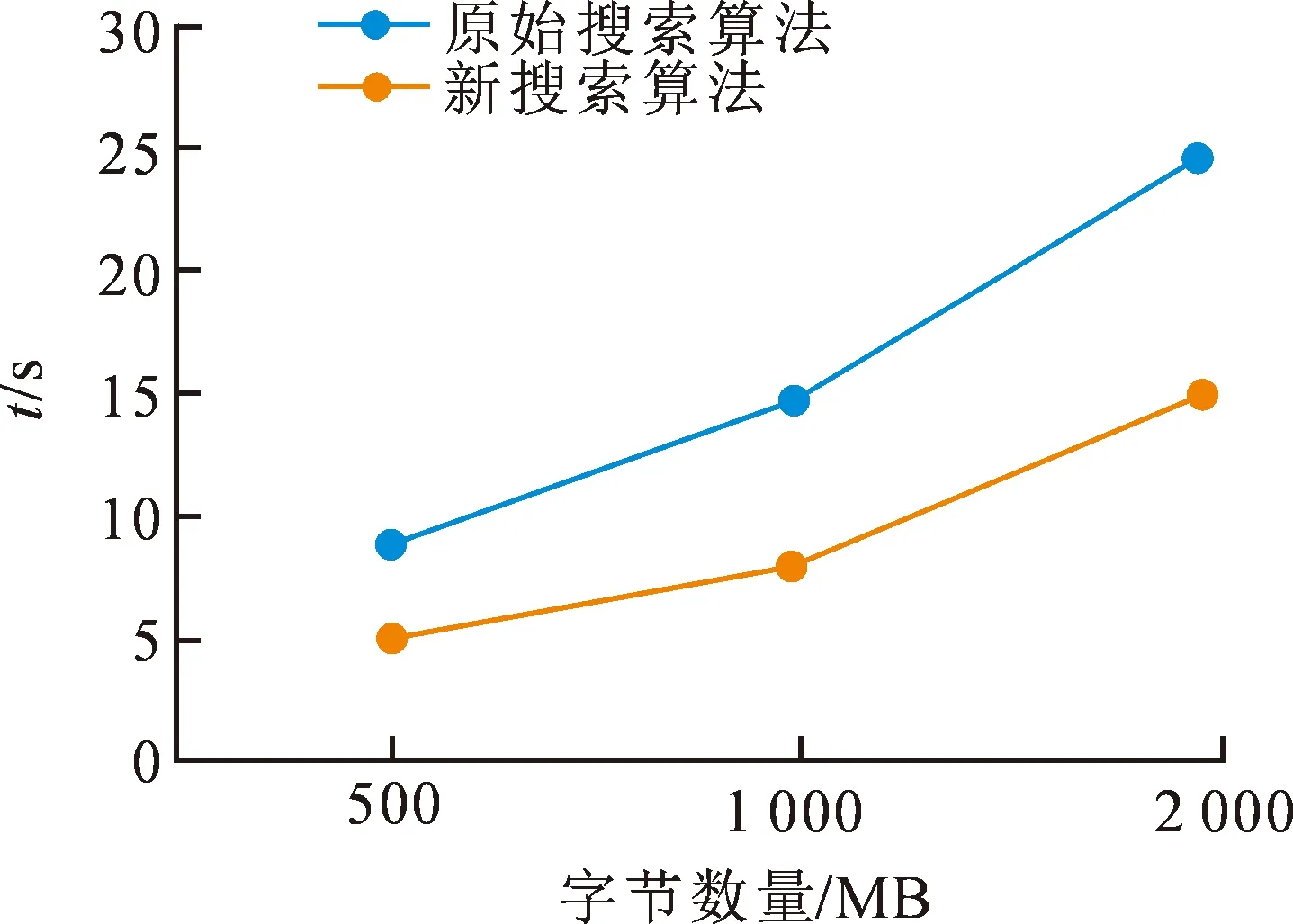
图4 大索引的算法测试结果
3 系统构建
大数据数据检索自适应系统包括客户端与服务器端。在系统正常运行的时候,监控模块会实现对文件的实时监控功能。对于客户端来说,操作本地文件时,系统会对用户的操作事件进行实时的监控处理,同时对监控结果进行划分。下一步为文件同步过程的执行,此时需要文件同步模块提供相应的同步服务。此模块能够基于不同的事件来做出特定的响应,具体的响应包括对服务器端HDFS中文件的增删改查。
3.1 客户端功能模块
在客户端中,对HDFS文件系统进行操作主要包括文件新建、文件下载、文件删除以及文件打开等,其功能分别为:文件新建实现新HDFS文件的创建; 下载实现将服务器端的HDFS文件下载到本地文件夹中;删除实现对HDFS文件的删除;重命名实现对HDFS文件系统中文件的重新命名;打开将HDFS文件系统中相应的文件打开并查看其具体内容;刷新实现对HDFS的文件列表刷新显示。H按钮操作事件监控及分类处理如图5所示。
3.2 服务器端功能模块
系统的后台存储系统使用了HDFS文件系统,可以有效地实现分布式存储功能。结构分为3个节点,其中一个为Namenode主节点,主要实现对元数据信息的存储功能;其余两个为Datanode从节点,主要实现对文件数据块的存储功能。Datanode的文件分块大小为64MB,复制因子为2,表示文件分块备份了2个。系统服务器端的架构如图6所示。
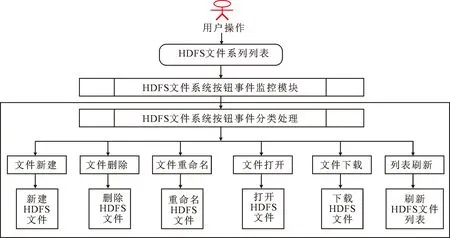
图5 H按钮操作事件监控及分类处理
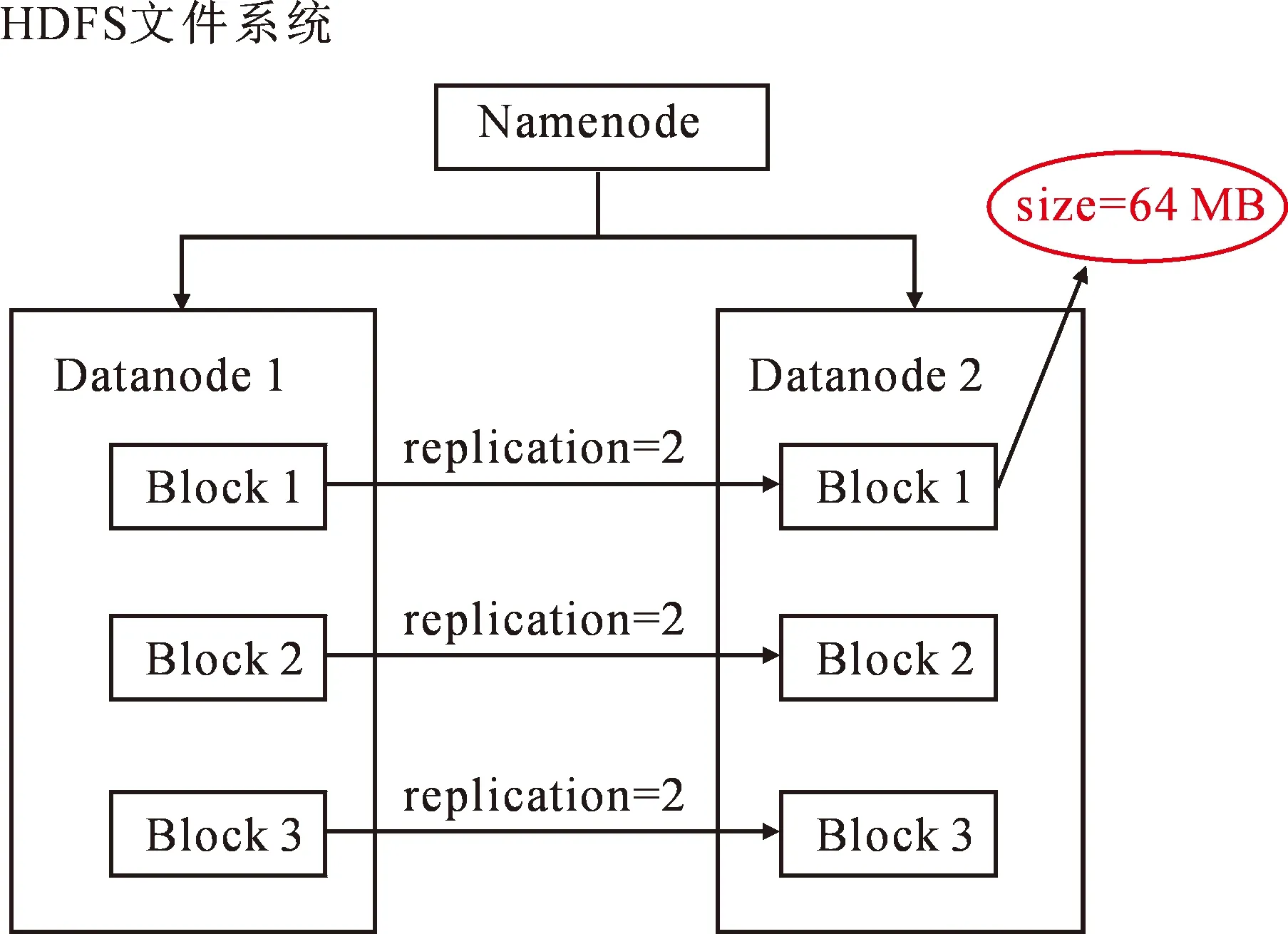
图6 系统服务端的整体架构图
4 性能测试与分析
为充分利用现有的硬件资源进行测试,直接使用一台IBM服务器来模拟五个配置完全一致的节点。具体硬件配置如下:CPU是单处理器单核;内存大小是1 G,硬盘大小是20 G。选择使用Linux下的ubuntu-12.04操作系统 ;使用jdk1.7与Eclipse 3.5来进行Java程序开发;Hadoop平台选择的是hadoop-0.20.2版本;虚拟机选择的是VMware-workstation full-v10.0.0版本。本系统在配置Hadoop集群时,选择其中一个作为Master,其他的都作为 Slave节点,并将网络设置成桥接模式。节点的具体信息见表3。

表3 集群的节点设置
常规的搜索引擎主要在建立索引时需要花费较多的时间,查询过程较为迅速,而查询时间过短会导致受到带宽等因素的干扰,因此对本系统测试时主要是对索引建立进行了测试。为了确定Hadoop集群的性能与节点数量之间的关系,本文将集群的节点数分别设置为2,3,4和5进行测试;对系统运行时间进行比较,分别选择了100,1 000,10 000,100 000以及1 000 000个网页文档来建立倒排索引。性能测试结果如图7所示。
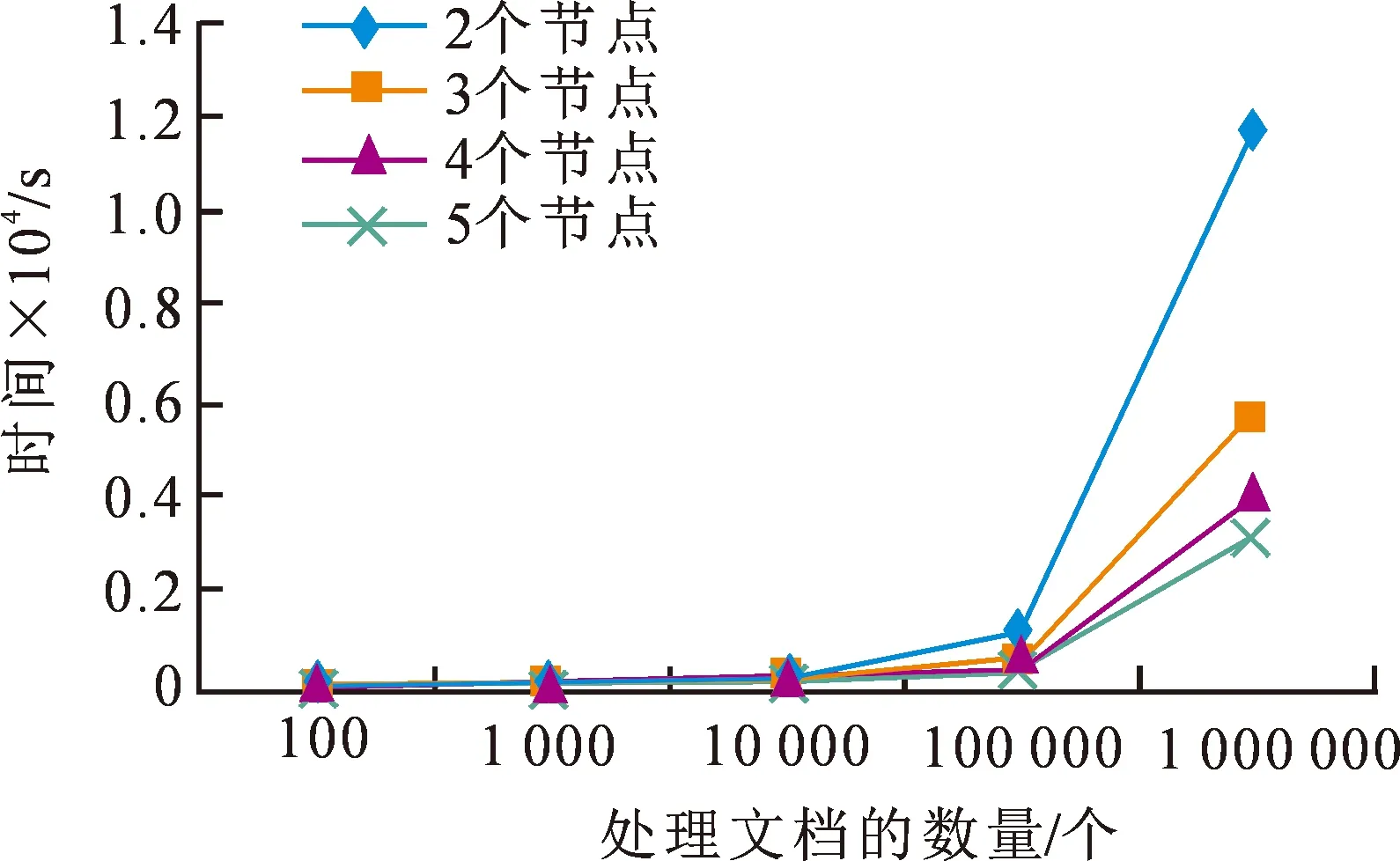
图7 性能测试结果
从图7可以发现,如果网页文档的数量很少,建立索引时间与节点数量。其主要原因为:如果网页文档的数量较少,也只有很少部分节点来执行建立索引任务,其分布式计算性能没有发挥,索引时间也不会随着文档的增多而变化,因为在任务分隔等过程中花费了较多的时间。而如果网页文档足够多时,此时建立索引需要的时间与节点数呈现出负增长关系,即节点数量越大,索引时间就越短,这就证明系统性能随着节点的增多而提升。因此可以采用增加节点数量的方式来提升整个系统的性能。这表明,本系统具有较高的可靠性,即使有多个节点发生了故障,系统仍然能够完成相应任务。
5 结 论
本文设计并实现了一种自适应性切换搜索算法,通过对索引文件大小的有效分析和处理,利用了Map-Reduce框架完成了对索引以及查询两个子系统的设计和实现,优化了分布式搜索引擎的搜索效率。
1) 基于用户的个性化搜索需求来选择合适的搜索方式,提高了搜索结果的精确性。用户在使用Map/Reduce框架进行文件处理时,只需要重新对Map以及Reduce函数进行编写即可实现分布式处理功能,而完全不需要考虑其处理过程中涉及到的通信问题、存储问题以及负载均衡问题等。
2) 选择100,1 000,10 000,100 000以及1 000 000个网页文档来建立倒排索引,建立索引需要的时间与节点数呈现出负增长关系,即节点数目越大,索引时间就越短,证明系统性能随着节点的增多而提升。
3) 通过对五组低于256 MB的索引文件和三组超过256 MB的索引文件进行测试,并针对每一组索引文件作10次查询。当索引文件大小在1 000 MB左右时,算法效果达到最优,搜索时间相较原算法大幅缩短。
猜你喜欢
中国新闻周刊(2021年26期)2021-07-27 04:02:12
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19 08:38:42
信息安全研究(2016年4期)2016-12-01 06:06:54
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
中国卫生(2015年12期)2015-11-10 05:13:38
电测与仪表(2015年15期)2015-04-12 00:43:48
河北科技大学学报(2015年5期)2015-03-11 16:16:37
新疆大学学报(自然科学版)(中英文)(2014年2期)2014-11-06 07:49:12
中央民族大学学报(自然科学版)(2014年1期)2014-06-11 01:28:38
技术经济与管理研究(2014年11期)2014-03-11 17:02:44
