
嵌入互联网舆情强度的人民币汇率预测
2019-12-23 07:19王吉祥过弋戚天梅王志宏李真汤敏伟
计算机应用 2019年11期
关键词:机器学习
王吉祥 过弋 戚天梅 王志宏 李真 汤敏伟

摘 要:针对目前人民币汇率预测研究存在的数据源单一导致难以提升预测效果的問题,提出一种嵌入互联网舆情强度的预测技术,通过融合多方面数据源进行对比分析,有效降低了人民币汇率的预测误差。首先,融合互联网外汇新闻数据和历史行情数据,并将多源文本数据转化为可计算的特征向量;其次,通过情感特征向量构建五种特征组合并对其进行对比,给出了嵌入互联网舆情强度的特征组合作为预测模型输入;最后,设计外汇舆情影响汇率预测的滑动时间窗口,建立基于机器学习的汇率预测模型。实验结果表明,嵌入互联网舆情的特征组合相对于不含舆情的特征组合在均方根误差(RMSE)和平均绝对误差(MAE)上分别提升了9.8%和16.2%;此外,长短期记忆网络(LSTM)预测模型比支持向量回归(SVR)、决策回归(DT)和深度神经网络(DNN)预测模型表现更好。
关键词:机器学习;文本向量化;舆情影响力;汇率预测;滑动时间窗口
中图分类号:TP391
文献标志码:A
RMB exchange rate forecast embedded with Internet public opinion intensity
WANG Jixiang1, GUO Yi1,2,3*, QI Tianmei1, WANG Zhihong1, LI Zhen4, TANG Minwei4
1.School of Information Science and Engineering, East University of Science and Technology, Shanghai 200237, China;
2.National Engineering Laboratory for Big Data Distribution and Exchange Technologies, Shanghai 200237, China;
3.Shanghai Engineering Research Center of Big Data and Internet Audience, Shanghai 200072, China;
4.Department of Risk Management, China Telecom BestPay Company Limited, Shanghai 200085, China
Abstract:
Aiming at the low prediction effect caused by single data source in the current RMB exchange rate forecast research, a forecast technology based on Internet public opinion intensity was proposed. By comparing and analyzing various data sources, the forecast error of RMB exchange rate was effectively reduced. Firstly, the Internet foreign exchange news data and historical market data were fused, and the multisource text data were converted into the computable vectors. Secondly, five feature combinations based on sentiment feature vectors were constructed and compared, and the feature combination embedded with intensity of Internet public opinion was given as the input of forecast models. Finally, a temporal sliding window of foreign exchange public opinion data was designed, and an exchange rate forecast model based on machine learning was built. Experimental results show that feature combination embedded with Internet public opinion outperforms the feature combination without public opinion by 9.8% and 16.2% in Root Mean Squared Error (RMSE) and Mean Squared Error (MAE). At the same time, the forecast model based on Long ShortTerm Memory network (LSTM) is better than that based on Support Vector Regression (SVR), Decision Tree regression (DT) and Deep Neural Network (DNN).
Key words:
machine learning; text embedding; public opinion impact; exchange rate forecast; temporal sliding window
0 引言
人民币汇率预测一直是广大学者和研究者关注的话题与方向。近年来中美贸易失衡有加剧的趋势,美国政府将其对中国巨额贸易赤字的根源归咎于人民币币值的低估,并将人民币兑美元汇率视为影响中美双方经贸关系的焦点问题[1], 因此,在当下人民币汇率双向波动和弹性扩大的环境中,对人民币汇率进行有效预测,对于指导个人投资行为、帮助企业制定科学的国际贸易决策以及国家外汇储备资产管理和外汇风险防范都有着重要的意义[2]。
人民币汇率走势的预测及分析是许多金融领域学者们关注并研究的方向,但是结合舆情数据去预测短期内人民币汇率的涨幅却少有研究。多数文献对人民币汇率的研究是利用宏观经济学与计量统计学的模型去拟合人民币汇率的曲线,但是这种方法不能预测汇率在外界金融事件和舆情影响下的波动。实际上,影响汇率的诸多因素中除了定量的实际观测数据,像舆情这类非结构化的定性数据也具有很大的影响力。互联网的快速发展,提升了舆情传播对经济社会的影响力。尤其是各种新型网络平台的出现,使信息的传播更加快速,渗透更为深刻。网络舆情数据不仅对股票价格[3]和商品价格有影响,对外汇汇率也有极大的影响。
为了应对上述挑战,本文在融合了互联网舆情数据和人民币汇率历史数据的基础上,设计舆情影响人民币汇率预测的滑动时间窗口并构建预测模型。本文主要贡献如下:
1)嵌入互联网舆情情感,并对比词向量、情感极性、情感强度等不同嵌入方式的预测效果;
2)根据舆情时效性较短的特点,设计了输入向量滑动窗口和预测滞后滑动窗口;
3)在真实的人民币汇率数据集上进行实验,验证本文提出的方法能够提高预测效果。
1 相关工作
1.1 舆情影响力
舆情事件在互联网中的发展像生物一样会经历出生、成长、衰老和死亡的过程。某一舆情事件的发生,通常会伴随网络舆情信息的传播。文献[4]提到公共危机事件的网络舆情生命周期有潜伏期、成长期、爆发期和平息期。文献[5]的实验曲线趋势表明,舆情参与人数和转发频次的演化特征几乎一致。网络舆情的传播会在前期爆发时到达一个高峰,消退一段时间后还會涨到另一个高峰,在这之后一段时间会慢慢削弱。
行为经济学表明,公众舆论深刻影响个人行为和决策[6]。文献[7]表明网络舆情通过影响入市资金流进一步影响股市行情;文献[8]证实并分析了基于微博的投资者情绪对股票市场的影响,舆情可以在一定程度上预测股票价格;文献[9]将非结构化文本数据转化为结构化的特征向量矩阵,与股票的收益率建立支持向量回归(Support Vector Regression, SVR),研究结果表明,预测的股价涨跌趋势与实际趋势基本吻合,可以通过分析网络舆情来对股市未来发展趋势进行预测;文献[10]分别从社交媒体和财经新闻中的文本信息中捕捉社会情感和专业意见,然后通过张量表示由这两个信息源组成的整个市场信息空间以及公司特征。实验表明与传统的基于矢量的系统相比,从多信息源的联合效应角度研究社会情绪作用的智能系统更有效。上述的文献足以说明网络舆情的直接影响力非常之大,能够影响人民币汇率并能在预测方面作出贡献。然而没有文献给出舆情影响力与时间的具体函数关系,无法量化舆情具体的影响力值。
1.2 价格预测模型
学者们对于人民币汇率预测模型研究文献较少,所以作者也查阅了股票价格预测的文献。研究者们多数利用机器学习和神经网络来研究对价格的预测。机器学习算法主要包括支持向量回归(SVR)和人工神经网络等。文献[2]运用SVR方法对人民币汇率进行实证预测,结果表明基于SVR的汇率预测方法在预测精度和稳定性方面优于对照模型,更能体现汇率行为所反映的经济因素;文献[11]验证了SVR有助于使用机器人技术自动作出外汇市场中买/卖的交易决策;文献[12]从Twitter捕获1-170-414个数据点,并使用文本挖掘方法提取情绪并应用于SVR提高预测效果;文献[13]使用带有延迟因子的前馈神经网络能较好地预测短期的外汇汇率。随着深度学习的快速发展,其应用变得更加广泛,尤其是卷积神经网络(Convolutional Neural Network, CNN)算法和循环神经网络(Recurrent Neural Network, RNN)算法等。文献[14]表明与机器学习方法相比,基于CNN的预测模型可以有效提高长期预测的准确性;基于RNN和门控递归单位的模型[15]来预测中国股市的股票能够获得良好的预测性能;文献[16]使用在线股票论坛的信息融合股票市场数据,通过RNN实现预测,实验结果表明模型在带情感的数据上表现明显更好。
综合上述文献,学者们在预测人民币汇率上已有多方面的研究与实验,但仍有空白之处: 第一,没有将外汇舆情数据作为人民币汇率预测的基础,忽略了汇率受外界事件的影响。互联网外汇舆情的影响力不容小觑; 第二,缺少外汇舆情影响人民币汇率的滑动时间窗口,忽略了舆情的时效性和情感特点。随着时间的增加,舆情影响力会有不同的变化且有延迟现象, 设计外汇舆情影响汇率预测的滑动时间窗口能够改善这个问题, 所以本文将重点研究设计外汇舆情影响人民币汇率预测的滑动时间窗口以及融合网络舆情数据和历史行情数据,利用机器学习方法构建人民币汇率预测模型,最后对比四组预测算法并进行分析与评估。
2 准备性研究工作
2.1 数据准备
本文实验的数据均通过Python编写的爬虫工具采集。目前具有较大影响力的财经资讯网站主要包括华尔街见闻(https://wallstreetcn.com)、路透社、彭博新闻社等。华尔街见闻作为一个综合多信息源的集成者,在其相关领域具有很大的参考价值,因此本文将其作为实验研究的数据源。本文实验采用2016-06-30—2017-12-29共369个交易日的历史行情数据和外汇舆情数据。
历史行情数据示例如表1所示,字段包含时间和人民币汇率(美元兑人民币)。互联网外汇新闻数据示例如表2所示,采集的字段有包括发布时间和新闻内容。
发布时间新闻内容
2016-06-30T15:23新浪援引外媒称,中国央行愿意让人民币汇率在今年降至1美元兑6.8元
2016-06-30T17:07BBH高级副总裁Marc Chandler:英镑的走势和基本面并没有关系,反弹的原因是空头平仓以及机构投资者在月末和季末调整仓位
2016-06-30T18:10MBM研究团队首席研究员Richard Cox:瑞士央行如市场预期维持了其扩张性的货币政策,理事会主席Thomas Jordan也承认负利率政策还将会维持一段时间
2016-07-01T16:20【提醒】北京时间16:30将公布英国6月制造业PMI
2.2 数据预处理
本文的互联网舆情数据的预处理主要包括:对文本进行分词、替换文本中特殊符号、去除低频词和停用词等。
实验采用jieba分词工具,它的分词模式有三种:精确模式、全模式和搜索引擎模式。精确模式试图将句子最精确地切开,适合文本分析,并且速度非常之快。
在信息检索和自然语言处理的过程中,为了节省存储空间和提高检索效率,需要过滤掉一些对当前实验无用且没有含义的字词和符号,这些字词和符号就叫作停用词。本实验采用的是哈尔滨工业大学停用词表和百度停用词表的结合。
2.3 文本数据特征化
本文的互联网外汇舆情数据来源于华尔街见闻,爬取的新闻数据包含了诸多与外汇领域有关的情感词及其情感强度。本文利用公共情感分析工具将互联网新闻数据处理成特征向量,并将其作为预测模型的输入来预测人民币汇率,具体分析流程如图1所示。
为了探究互联网舆情对人民币预测的影响,本文分别将数据处理成5种特征维度的数据,如表3所示,其中:PT代表人民币历史汇率特征,PT&WV代表人民币历史汇率和新闻词向量的特征组合,PT&PV代表人民币历史汇率和新闻情感极性值的特征组合,PT&QV代表人民币历史汇率和新闻情感強度值的特征组合,PT&CQ代表人民币历史汇率和新闻情感强度的变化值的特征组合。
3 美元兑人民币汇率预测模型实现
本文实验的技术路线第一阶段如图2所示,第二阶段如图3所示。
本文首先采集互联网外汇舆情数据和人民币历史行情数据,并将文本型数据处理成特征向量; 进而设计了滑动时间窗口以探究舆情对汇率预测的影响; 接着基于机器学习构建人民币汇率预测模型,包括SVR[17]、决策树回归(Decision Tree regression, DT)[18]、深度神经网络(Deep Neural Network, DNN)[19]和长短期记忆网络(Long ShortTerm Memory network, LSTM)[20]; 最后对预测模型进行对比和评估。
3.1 特征组合的选择
本文实验开发环境为Pycharm64,开发语言为Python3.6,操作系统为Windows 10。本次实验建立的SVR价格预测模型和DT价格预测模型,直接使用了Python自带的Sklearn[21]里的工具包,DNN和LSTM模型在Keras框架上实现。
回归算法的常用评估方法有均方根误差(Root Mean Squared Error, RMSE)和平均绝对误差(Mean Absolute Error, MAE),见式(1)和式(2)。RMSE和MAE越小,代表预测的误差越小,预测效果越好。
RMSE=∑mi=1(yt-yt′)2m(1)
MAE=∑mi=1yt-yt′m(2)
其中:m为样本数量,y为标签值,y′为预测的真实值。
为了对比分析五种特征组合对人民币汇率预测结果的影响力,分别用以上两种评价指标对其进行评估。以LSTM算法为例(采样时间为30min),其他参数均为默认值,滑动窗口分别为1,2,…,80。
由表4均值可得,PT&CQ和PT&QV的RMSE相对最小,相比于PT提高了9.8%。说明历史行情数据加上情感强度及其变化值的特征组合RMSE效果最好。PT& CQ的MAE相对其他数据来说较低,相比于PT降低了16.2%。说明加上情感强度值变化的数据表现效果最好。
综上所述,融合外汇领域互联网舆情数据的混合特征组合(PT&WV、PT&PV、PT&QV和PT&CQ)比仅含有历史行情数据的预测效果要更好。而在这些混合特征组合中, PT&WV包含了互联网外汇新闻的词向量特征,计算了每条新闻中的所有词汇的词向量。这使PT&WV含有更多的信息量,实验证实了其效果比PT要好。PT&CQ的RMSE值和MAE值都相对较低。由于PT&CQ包含了互联网外汇舆情的强度值的变化,能够较好地反映出互联网舆情的情感变化情况,因此对人民币汇率的预测帮助较大。接下来将基于预测效果最好的PT&CQ特征组合进行实验。
3.2 输入向量窗口的设定
训练模型输入的向量中包含的时间节点越多能表达越多的信息量,但是窗口太大会增加算法复杂度从而影响模型的运行效率, 所以本文仍需寻找一个最优的时间节点个数作为滑动窗口的大小。本节除采用PT&CQ作为输入向量外,其余实验配置和参数设置均与3.1节相同。
从图4可得,PT&CQ预测结果的RMSE在窗口值为[1,5]时较小,值在0.003-5附近波动。窗口值为[5,70]逐渐上升到最大值,随后略有下降并在0.005值上下波动。考虑到能够尽量多地输入时间点特征为模型提供更多的信息量,本文将训练模型的最佳输入窗口值定为5。
3.3 预测滞后窗口的设定
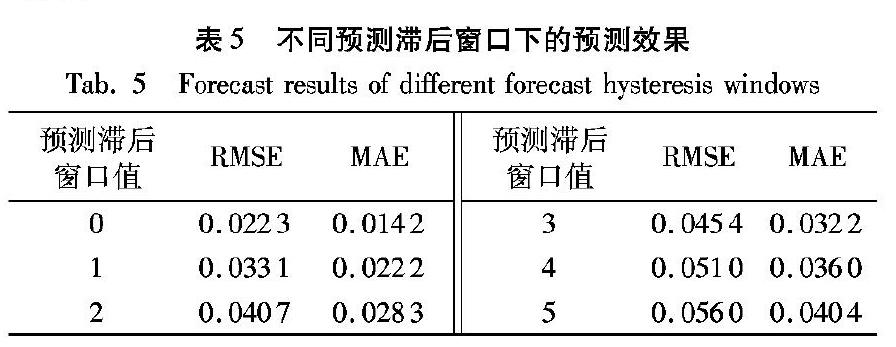
由3.2节的实验结果得知,训练模型时输入向量的窗口为5预测效果最好。此时,训练输入的特征维度包括5个时间节点的特征(每个时间节点特征为44维),用这些特征维度去预测第6个时间节点和第7个时间节点将得到不一样的预测结果。所以在得知最优训练输入窗口的情况下,本文仍需寻找最优的预测滞后窗口。由于训练输入窗口为5,按常理可知预测滞后窗口不应该大于5,即在[0,5]中寻找最优的预测滞后窗口。本节的实验配置与参数设置与3.1节的实验相同。
从表5可得,在数据训练输入窗口为5并采取不同预测滞后窗口时,预测结果的RMSE值在窗口值的整个取值区间逐渐增大,最小值为0.022-3,最大值为0.056-0。MAE值表现相似,在区间内逐渐增大,最小值为0.014-2,最大值为0.040-4。综合表现结果来看,预测滞后窗口值为0时效果最好。
预测滞后窗口较小时预测结果的RMSE和MAE值较低。这样的结果可能是由于滞后的窗口越大,窗口中的信息被抛弃,使得模型训练时遗失了距离预测时间点最近的信息,从而导致了预测结果不理想。
3.4 预测模型参数寻优
本文实验的预测模型选取了SVR、DT、DNN和LSTM四種方法进行对比分析。SVR的核函数为径向基函数,DT的树深为20,其他参数都采用了默认的参数。在DNN和LSTM模型中,一般认为增加隐层数可以降低网络误差,提高精度,但也使网络复杂化,从而增加了网络的训练时间和出现“过拟合”的倾向。所以本文实验在设计神经网络层数时考虑3层网络(有2个隐层),靠调节隐层节点数来获得较低的误差,这样的训练效果要比增加隐层数更容易实现[22]。
如何寻找这个最佳隐节点数,学者们给出了一些方案,见式(3)~(5):
∑ni=0Cin1>k(3)
其中:k为样本量,n1为隐层节点数, n为输入层节点数。当i>n1时,Cin1=0。
n1=(n+m)12+a (4)
其中:n为输入层节点数,m为输出层节点数,a为1~10的常数。
n1=lbn(5)
本文实验利用式(4)计算出隐节点个数的取值范围,再进行实验选择最优的隐节点数目。实验以LSTM为例,3层网络结构,输入层节点数为44,输出层节点数为1,所以隐层节点数取7~17。
由表6可得,在隐节点数为[7,17]的整个取值区间中,RMSE值和MAE值都不是很稳定,波动起伏较大。当隐节点数为13时,RMSE值和MAE值最小,那么将最优隐节点的个数取为13是较为合理的决定。
4 实验与结果分析
本文实验的数据是2016-6-30—2017-12-29共369个交易日的行情数据和互联网新闻舆情数据。对比四种机器学习的预测模型,训练集和测试集的比例为10∶1,DNN和LSTM网络模型的网络层数为3,隐节点数为13。训练模型输入窗口值取5,预测滞后窗口取0。分别用不同的采样区间的数据做实验,得到如图5、6结果所示。
从图5和图6可以得到,SVR在采样区间120min时效果最好;DT在采样区间15min时效果相对较好;DNN在采样区间为60min时效果最好,RMSE和MAE都最小;LSTM采样区间为5min时效果最好,RMSE和MAE都是最低值。
SVR的原理是在高维空间中寻找出一个曲面进行分类,但是由于本文数据的稀疏性,很难精准地寻到这样的高维曲面。DT可能更适用于特征维度不相关的数据,本文的实验数据特征之间并不是完全独立的,这极大地影响了DT的算法效果。DNN是最简单的神经网络模型,没有处理序列关系的功能。LSTM模型能够捕捉长序列关系,学习保留需要的信息,遗忘不需要的信息,更符合本文含有时间序列特征的数据,所以LSTM比DNN表现出更好的人民币汇率预测效果。综合对比四种预测模型,LSTM的RMSE值和MAE值相对较小,是四个预测模型中预测效果最好的模型。
5 结语
本文将外汇历史行情数据与互联网外汇新闻数据融合作为预测美元兑人民币汇率的源数据,研究了模型训练的输入向量窗口和预测滞后窗口的合理设置,对比分析了外汇新闻更好表达情感并为预测算法作基础的特征组合,最后对比分析了四种机器学习模型的预测效果。从实验中能够发现加入外汇新闻数据比仅含有历史行情数据预测未来汇率变化的效果更好,且将外汇新闻数据处理成情感强度变化值来预测人民币汇率效果最好。模型训练的输入向量窗口不宜过大,小窗口更能给出好的预测效果,实验给出的最优结果是5。预测滞后窗口设置为0有助于预测人民币汇率。相比其他预测模型,LSTM的RMSE值和MAE值都较小,预测效果更好。
由于本文构建的外汇领域的新闻情感关键词汇表较为简单、词汇数量较少,导致构建的情感向量维度很大一部分是数据为零(新闻内容中没有匹配到关键词),这是本文实验的不足。实际上当前外汇领域并没有可用的具有领域特色的关键词汇表,这对本文的实验也是一个挑战,未来希望能够补充更多的外汇领域关键词。另外,在对情感特征化的处理上本文采用了现有的公共情感分析工具,这对外汇领域的人民币预测算法的适用性不是最佳的,未来将改进情感分析算法以适用于外汇领域。目前本文对输入向量窗口和预测滞后窗口的最优值设定为定值,而对于波动频繁的人民币汇率,自动变化寻找最优大小的滑动窗口能够达到更好的预测效果,这也是本文的未来工作之一。
参考文献 (References)
[1]秦喜文,张瑜,董小刚,等. 基于EEMD和SVR的人民币汇率预测[J].东北师大学报(自然科学版), 2017, 49(2):47-51. (QIN X W, ZHANG Y, DONG X G, et al. Forecasting RMB exchange rate based on EEMD and SVR[J]. Journal of Northeast Normal University (Natural Science Edition), 2017, 49(2):47-51.)
[2]马超. 人民币汇率预测[D]. 济南: 山东大学, 2017:8-56. (MA C. RMB exchange rate forecast[D]. Jinan: Shandong University, 2017: 8-56.)
[3]FRSCHLER F, ALFANO S. Reading between the lines: The effect of language sentiment on economic indicators[C]// Proceedings of the 2017 Enterprise Applications, Markets and Services in the Finance Industry, LNBIP 276. Berlin: Springer, 2017:89-104.
[4]赵岩,王利明,杨菁. 公共危机事件网络舆情生命周期特征分析及对策研究[J]. 经济研究参考, 2015(16):57-69. (ZHAO Y, WANG L M, YANG J. Analysis of the characteristics of public opinion cycle of public crisis events and its countermeasures[J]. Economic Research Reference, 2015(16):57-69.)
[5]丁洁. 基于社会网络的网络舆情演化研究[D]. 南京: 南京理工大学, 2015:38-44. (DING J. Analysis on the evolution of online public opinion based on social network[D]. Nanjing: Nanjing University of Science and Technology, 2015: 38-44.)
[6]PAGOLU V S, REDDY K N, PANDA G, et al. Sentiment analysis of Twitter data for predicting stock market movements[C]// Proceedings of the 2016 International Conference on Signal Processing, Communication, Power and Embedded System. Piscataway: IEEE, 2016: 1345-1350.
[7]陈云松,严飞. 网络舆情是否影响股市行情?基于新浪微博大数据的ARDL模型边限分析[J]. 社会, 2017, 37(2):51-73. (CHEN Y S, YAN F. Does online sentiment predict stock market indices? The ARDL bounds tests based on Sinamicroblog data[J]. Society, 2017, 37(2):51-73.)
[8]张信东,原东良. 基于微博的投资者情绪对股票市场影响研究[J]. 情报杂志, 2017, 36(8):81-87. (ZHANG X D, YUAN D L. Research on the impact of investor sentiment on stock market based on microblog[J]. Journal of Intelligence, 2017, 36(8):81-87.)
[9]朱昶胜,孙欣,冯文芳. 基于R语言的网络舆情对股市影响研究[J]. 兰州理工大学学报, 2018, 44(4):103-108. (ZHU C S, SUN X, FENG W F. Study on the impact of network public opinion on the stock market based on Rlanguage[J]. Journal of Lanzhou University of Technology, 2018, 44(4):103-108.)
[10]LI Q, WANG J, WANG F, et al. The role of social sentiment in stock markets: a view from joint effects of multiple information sources[J]. Multimedia Tools and Applications, 2017, 76(10):12315-12345.
[11]THU T N T, XUAN V D. Using support vector machine in FoRex predicting[C]// Proceedings of the 2018 IEEE International Conference on Innovative Research and Development. Piscataway: IEEE, 2018:1-5.
[12]SEETO E W K, YANG Y. Market sentiment dispersion and its effects on stock return and volatility[J]. Electronic Markets, 2017, 27(3): 283–296.
[13]鄧景炜. 基于神经网络的外汇汇率预测研究[D]. 广东: 暨南大学, 2017:56-65. (DENG J W. Research on foreign exchange rate forecast based on neural network[D]. Guangdong: Jinan University, 2017: 56-65.)
[14]LIU C, HOU W, LIU D. Foreign exchange rates forecasting with convolutional neural network[J]. Neural Processing Letters, 2017, 46(3):1095-1119.
[15]CHEN W, ZHANG Y, YEO C K, et al. Stock market prediction using neural network through news on online social networks[C]// Proceedings of the 2017 International Smart Cities Conference. Piscataway: IEEE, 2017: 1-6.
[16]LIU Y, QIN Z, LI P, et al. Stock volatility prediction using recurrent neural networks with sentiment analysis[C]// Proceedings of the 2017 International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems, LNCS 10350. Berlin: Springer, 2017: 192-201.
[17]AWAD M, KHANNA R. Support vector regression[J]. Neural Information Processing Letters and Reviews, 2007, 11(10):203-224.
[18]QUINLAN J R. Induction on decision tree[J]. Machine Learning, 1986, 1(1):81-106.
[19]SCHMIDHUBER J. Deep learning in neural networks: an overview[J]. Neural Networks, 2015, 61:85-117.
[20]SHI X, CHEN Z, WANG H, et al. Convolutional LSTM network: a machine learning approach for precipitation nowcasting[C]// Proceedings of the 28th International Conference on Neural Information Processing Systems. Cambridge, MA: MIT Press, 2015: 802-810.
[21]PEDREGOSA F, VAROQUAUX G, GRAMFORT A. Scikitlearn: machine learning in Python[J]. Journal of Machine Learning Research, 2011, 12:2825-2830.
[22]王嶸冰,徐红艳,李波,等. BP神经网络隐含层节点数确定方法研究[J]. 计算机技术与发展, 2018, 28(4): 31-35. (WANG R B, XU H Y, LI B, et al. Research on the method of determining hidden layer nodes in BP neural network[J]. Computer Technology and Development, 2018, 28(4):31-35.)
This work is partially supported by the National Key Research and Development Program of China (2018YFC0807105), the National Natural Science Foundation of China (61462073), the Scientific Research Project of Science and Technology Committee of Shanghai Municipality (17DZ1101003, 18511106602, 18DZ2252300).
WANG Jixiang, born in 1995, M. S. candidate. Her research interests include natural language processing, data mining.
GUO Yi, born in 1975, Ph. D., professor. His research interests include text mining, knowledge discovery.
QI Tianmei, born in 1994, M. S. candidate. Her research interests include natural language processing, data mining.
WANG Zhihong, born in 1990, Ph. D. candidate. His research interests include natural language processing, text mining.
LI Zhen, born in 1976, Ph. D. Her research interests include financial risk management, fraud risk prevention.
TANG Minwei, born in 1990, M. S. His research interests include abnormal event detection, malicious group recognition.
猜你喜欢
电子技术与软件工程(2016年22期)2016-12-26
时代金融(2016年27期)2016-11-25
科教导刊(2016年26期)2016-11-15
活力(2016年8期)2016-11-12
科学与财富(2016年28期)2016-10-14
电脑知识与技术(2016年20期)2016-08-19
电脑知识与技术(2016年12期)2016-06-14
科教导刊·电子版(2016年10期)2016-06-02
科教导刊·电子版(2016年10期)2016-06-02
电脑知识与技术(2016年3期)2016-04-07
