
基于轮廓系数的参数无关空中交通轨迹聚类方法
2019-12-23 07:19孙石磊王超赵元棣
计算机应用 2019年11期
关键词:聚类分析
孙石磊 王超 赵元棣


摘 要:為消除专家经验的主观性、避免依赖轨迹特征并且减轻实验调参的负担,提出一种基于轮廓系数的参数无关聚类分析(PICBASIC)算法。首先,比较了现有基于欧氏距离的航迹配对方法,并且建立基于动态时间弯曲(DWT)距离和高斯核函数的轨迹相似度计算模型;其次,利用谱聚类对空中交通轨迹进行聚类划分;最后,提出一种基于轮廓系数的最佳簇数寻优方法,并且其具有对聚类结果量化评价功能。利用真实进场轨迹进行实验验证,PICBASIC判断将28L跑道的365条轨迹聚为5个簇,28R跑道的530条轨迹聚为6个簇时聚类质量最佳,平均轮廓系数分别为0.809-9和0.805-6。相同实验数据条件下,PICBASIC与MeanShift聚类的平均轮廓系数差异率分别为-1.23% 和0.19%。实验结果表明:PICBASIC包容轨迹的速度和长度差异,全程无需人工指导或实验调参,而且能够筛除异常轨迹对聚类质量的不利影响。
关键词:空中交通轨迹;聚类分析;轮廓系数;谱聚类;动态时间弯曲;高斯核函数;参数无关
中图分类号: TP181
文献标志码:A
Parameter independent clustering of air traffic trajectory based on silhouette coefficient
SUN Shilei*, WANG Chao,ZHAO Yuandi
Research Base of Air Traffic Management, Civil Aviation University of China, Tianjin 300300, China
Abstract:
In order to eliminate the subjectivity of expert experience, get rid of the dependence on trajectory characteristics and reduce the burden of experimental parameter tuning, a Parameter Independent Clustering BAsed on SIlhoutte Coefficient (PICBASIC) algorithm was proposed. Firstly, existing Euclidean distance based track pairing methods were compared, and a trajectory similarity calculation model based on Dynamic Time Warping (DWT) distance and Gaussian kernel function was established. Secondly, the air traffic trajectories were partitioned and clustered by spectral clustering. Finally, a cluster number optimization method based on silhouette coefficient was proposed, and it had the function of quantitative evaluation of clustering results. Experiments were carried out by using real arrival trajectories to verify the validity of the proposed algorithm. PICBASIC judged that the clustering quality would be respectively optimum if the 365 trajectories of runway 28L were clustered into 5 clusters and the 530 trajectories of runway 28R were clustered into 6 clusters. The average silhouette coefficients in the two situations were respectively 0.809-9 and 0.805-6. Under the same experimental conditions, the difference rates of average silhouette coefficient between PICBASIC and MeanShift clustering were respectively -1.23% and 0.19%. The experimental results demonstrate that PICBASIC can tolerate the speed and length differences of trajectories, dispense with manual guidance or experimental parameter tuning and filter out the adverse impact of abnormal trajectories on the clustering quality.
Key words:
air traffic trajectory; clustering analysis; silhouette coefficient; spectral clustering; Dynamic Time Warping (DTW); Gaussian kernel function; parameter independent
0 引言
针对空中交通轨迹的聚类分析是提高进离场程序的管制适用性、增强空域扇区划分科学性的有效技术手段[1]。但是,当前绝大多数聚类算法都需要一个甚至多个显式或隐式的输入参数,它们的聚类结果通常严重依赖于这些参数[2]。确定合理的参数是困难的,一般需要根据专家经验[3]、轨迹数据特点[4-6]或者多次实验[1,6-9]获得,其中:专家经验判断参数依赖于专家主观经验,缺乏客观的量化分析指标;基于轨迹数据特点设定参数,受轨迹训练样本的飞行速度、交通流量、空域特征等影响,算法局限性强,普适性难以保证;多次实验的方法显然加重了用户的负担,而且实验参数的候选值一般在某个指定范围和变化步长内选取,并不是理论最优值。
针对以上问题,本文提出一种基于轮廓系数的参数无关聚类分析(Parameter Independent Clustering BAsed on SIlhouette Coefficient,PICBASIC)算法。首先,分析空中交通轨迹的数据结构; 然后,将轨迹作为一个整体,通过局部缩放时间维求出轨迹间的动态时间弯曲(Dynamic Time Warping,DTW)距离,再应用高斯核函数变换获得轨迹相似度矩阵;接下来,利用谱聚类提取出相似度矩阵的特征子空间,并对聚类结果基于轮廓系数进行量化评价,进而确定最佳簇数;最后,通过终端区真实空中交通轨迹样本对模型和方法进行验证和分析。
1 空中交通轨迹的特征与表示
根据文献[5]的定义,航迹(track)是指某时刻监视设备记录的某航空器的某个空间位置、速度、航向等特征。轨迹(trajectory)是指在一段时间内,航空器飞行经过的历史痕迹,由一系列按照时序顺序排列的离散航迹组成。
通常,轨迹集可表示为:
TS={T1,T2,…,Ti,…,Tn}
式中:Ti为第i条轨迹,n为轨迹总数。
轨迹Ti可用航迹的数据集表示为:
Ti={pi1,pi2,…,pij,…,pim}
式中:pij表示第i条轨迹中第j个航迹,m为航迹总数。
每一个航迹pij定义为一个4维向量,即:
pij={x,y,z,t}
式中:x、y、z、t分别表示航迹pij的空间位置横坐标、空间位置纵坐标、飞行高度和记录时间。
2 参数无关空中交通轨迹聚类
2.1 定义轨迹的DTW距离
空中交通轨迹聚类分析关键是选择合适的不同轨迹间的相似性度量方法[10]。本文采用欧氏距离来度量轨迹间的相似性,因为它直观性最强,最易被理解与接受。
在求解轨迹间距离过程中,首先需要将不同轨迹的航迹按照某种规则配对,然后以航迹点对的欧氏距离作为轨迹间的距离。图1表示了三种基于航迹点对欧氏距离的轨迹相似性度量方法。
图1(a)方法直接使用兩条轨迹顺序航迹点对之间的距离和除以配对的航迹数[11]。该方法完全没有考虑航空器速度的差别,顺序航迹点对的欧氏距离有可能成为两条轨迹之间的斜距,增大了空间位置相似的轨迹的距离。图1(b)方法在图1(a)基础上进行改进,在计算每一对航迹距离时,同时选取其前后最相近的两个航迹进行计算,获取在此位置附近的5段距离之间的最短欧氏距离[3]。图1(b)方法考虑了航空器速度的差别,但是速度差大小与选取最相邻航迹个数的关系没有深入研究,在两条轨迹的航迹疏密具有显著区别时,仍然无法完全避免图1(a)的问题。图1(c)方法在图1(b)基础上进一步改进,计算局部航迹点与线的法向距离作为两条轨迹间的距离[12]。图1(c)方法直观上缩短了图1(b)方法的局部欧氏距离,但是同样存在图1(b)的问题。而且,三种方法均期望进行比较的两条轨迹的航迹数目相同,否则较长的轨迹会在无法配对的航迹处被截断,信息损失较高。
现实中,大部分空中交通轨迹都不等长,而且由于机型和飞行性能的区别,航空器飞行的速度不同导致不同轨迹的航迹疏密不同。所以,本文利用动态时间弯曲距离的特性来表示轨迹间的距离。首先,DTW距离对相比较的两条轨迹的长度不作要求,即两条轨迹的长度既可以是相等的也可以是不相等的[13]。其次,在保证航迹顺序不变的前提下,基于DTW距离的方法通过重复部分航迹来完成时间维的局部缩放,寻找两条轨迹之间的最佳对齐方式。轨迹间计算DTW距离的航迹配对原理如图2[14]所示。
DTW距离计算方法[14]为:
DTW(Ti,Tj)=
0,mi=mj=0
∞,mi=0ormj=0
dist(pi1,pj1)+min{DTW(Rest(Ti),Rest(Tj)),
DTW(Rest(Ti),Tj),DTW(Ti,Rest)Tj))},
mi≠0,mj≠0 (1)
式中:DTW(Ti,Tj)表示两条轨迹Ti与Tj间的DTW距离;mi和mj分别代表轨迹Ti与Tj的航迹个数;dist(pi1,pj1) 表示两个航迹pi1和pj1之间的欧氏距离;Rest(Ti)和Rest(Tj)分别表示轨迹Ti与Tj去掉第一个航迹pi1和pj1所得的剩余轨迹区间。
根据式(1),如果两条轨迹均存在航迹,则采用递归的方式求取最小欧氏距离作为DTW距离,在这个过程中会产生航迹的最优对应关系。
实践中,航迹空间位置的横、纵坐标与高度坐标的数值范围可能存在较大差异,若不做处理直接计算欧氏距离,则数值范围小的坐标对航迹空间距离的影响程度会降低。此时可将三维坐标逐个归一化,再计算航迹间欧氏距离。例如,高度坐标的归一化,如式(2)所示:
znorm=z-zminzmax-zmin(2)
进一步构建轨迹集TS的距离矩阵R,其元素rij表示轨迹Ti和Tj之间的距离,计算方法如式(3)所示。R为对称方阵。
rij=0,i=j2×DTW(Ti,Tj)mi+mj,i≠j (3)
2.2 基于高斯核函数构造相似度矩阵
轨迹间的距离越小,相似度越高;反之,相似度越低。从距离矩阵到相似度矩阵的转化采用高斯核函数,因为它能够突出轨迹的差异性,显著降低空间距离远的轨迹相似度,有利于提高聚类质量。高斯核函数的基本形式如式(4)所示:
K(xi,xj)=exp(-‖xi-xj‖2β)(4)
式中:‖xi-xj‖2为xi和xj的2范数,β为带宽参数,控制着高斯核函数的局部作用范围。
高斯核函数的结果对参数β敏感,本文利用文献[15]的方法选择β,计算方法如式(5)所示,无需任何领域知识或试错实验,仅仅取决于数据样本集自身特征。
β≈σ2/2.6,λ≤0.01σ2L(λ),0.01<λ<100λσ2=μ2,λ≥100 (5)
式中:σ2是数据样本集的方差, μ是均值,参数λ=(μ/σ)2,L(λ)是关于λ的函数。
构建相似度矩阵S,其元素sij表示轨迹Ti和Tj的相似度,计算方法如式(6)所示:
sij=0,i=jexp[-r2ij/β],i≠j(6)
S为对称方阵,且已归一化。重构距离矩阵,记为R′, 其元素rij′表示轨迹Ti和Tj的距离,计算方法如式(7)所示:
rij′=1-sij(7)
2.3 构造谱聚类的拉普拉斯矩阵
谱聚类的聚类质量一般优于传统聚类算法[16],而且,谱聚类只需确定“聚类簇数”这唯一的参数,所以,本文采用谱聚类构造参数无关的空中交通轨迹聚类方法PICBASIC。
谱聚类算法建立在图论中的谱图理论基础上,其本质是将聚类问题转化为图的最优划分问题。首先构造无向加权图G=(V,E),其中每个顶点vi代表一条轨迹,每条边eij赋予权重为轨迹Ti和Tj的相似度sij。于是,轨迹聚类转化为对该图顶点的划分问题,使不同子图之间的边具有低权重(即不同簇的轨迹相似度低),而子图内的边具有高权重(即同簇内轨迹相似度高)。
然后构造度矩阵D,D为对角矩阵,对角线元素
dii=∑nj=1sij
最后构造正则化的拉普拉斯(Laplacian)矩阵L[16]:
L=D-12(D-S)D-12
2.4 基于轮廓系数确定最佳簇数
经典谱聚类算法需要知晓最终聚类的簇数,设为k; 然后对L求前k个最小特征值及对应的特征向量,构造特征子空间; 最后调用Kmeans聚类算法对特征子空间进行聚类。
文献[5,16]利用特征向量最大谱系值所对应的下标作为簇数k,但是,若数据集之间存在较多相互重叠部分,会出现有2~3个数值相差不大的较大谱隙值,较难确定合理的簇数,需要结合领域知识或者专家经验判断。
最佳的簇数本质上要求的是最佳的聚类质量,使得簇内的对象相似度最高,不同簇的对象相似度最低。验证聚类结果的方法包括分析、实验、评价和举例[10]。本文利用轮廓系数[17]作为对空中交通轨迹聚类结果的评价。轨迹间的距离由式(7)计算。每条轨迹的轮廓系数取值在-1~1,值越大表示该条轨迹所在簇越紧凑,且远离其他簇。为了度量在完整轨迹集上的聚类质量,计算所有轨迹的轮廓系数的平均值,如式(8)所示:
savg=1n∑ni=1s(Ti)(8)
式中:savg为当簇数为k时的轨迹集平均轮廓系数,s(Ti)为轨迹Ti的轮廓系数,n为轨迹总数。
直观上,增加簇数似乎有助于降低每个簇内的轨迹平均距离,因为有机会形成更多稠密的簇,簇中轨迹更为相似。然而由于边際效应,划分太多的簇会导致降低簇内轨迹平均距离的效果下降。因此,PICBASIC预先设定一个充分大的簇数kmax,然后计算从2~kmax范围内各个候选簇数k的平均轮廓系数savg。利用肘方法(elbow method)思想,使用savg关于k的曲线的拐点作为最佳簇数[18]。
实际情况下,空中交通轨迹样本集中常包含航空器脱离标准进离场航线而形成的异常轨迹。当候选簇数k不合理时,异常轨迹会被错误分类到某正常轨迹簇中,导致savg显著降低。除非异常轨迹被单独聚类为一个簇或几个簇,savg才会增大。所以,应用轮廓系数作为聚类结果的评价量化指标,能够有效筛除将异常轨迹混入正常轨迹簇的情况,提高聚类质量。
2.5 PICBASIC算法步骤
输入 空中交通轨迹集TS,充分大的簇数kmax。
输出 最佳簇数kopt,最佳聚类Copt,最大平均轮廓系数smax。
程序前
1)
归一化TS的每个航迹pij;
2)
计算每两条轨迹Ti和Tj之间的DTW距离;
3)
计算rij,构建距离矩阵R;
4)
计算R的方差σ2、均值μ、参数λ、L(λ),进而计算β;
5)
计算sij,构建相似度矩阵S;
6)
计算rij′,重构距离矩阵R′;
7)
初始化kopt=0;
8)
初始化smax=-1;
9)
for k=2 to kmax
10)
聚类C=spectral_clustering(TS, k);
11)
计算平均轮廓系数savg;
12)
if savg>smaxthen
13)
smax=savg;
14)
kopt=k;
15)
Copt=C;
16)
end if
17)
end for
程序后
3 实例分析
为验证PICBASIC的合理性,选择旧金山国际机场连续48h 的真实进场空中交通轨迹[19]进行实验,其中28L跑道共365条轨迹,28R跑道共530条轨迹,未剔除任何异常轨迹,运用Matlab软件进行聚类分析。
3.1 高斯核函数的参数寻优
由轨迹距离矩阵R,根据式(5)或文献[20],可确定高斯核函数的带宽参数β。相关参数如表1所示。
3.2 确定最佳簇数
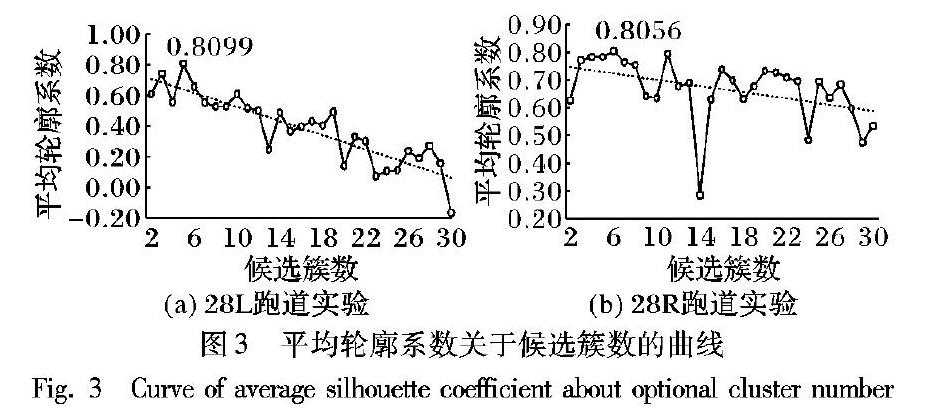
初选设定充分大的候选簇数范围为2到30,绘制平均轮廓系数关于候选簇数的曲线,如图3所示。可见,增加簇数并不能增大平均轮廓系数,反而随簇数增加,平均轮廓系数呈明显下降趋势。当簇数不合理时,会极大降低平均轮廓系数。由图3(a)可知,当簇数为5时,平均轮廓系数达到最大值0.809-9,故确定最佳簇数kopt为5。同理,由图3(b)可知,kopt为6,此时smax达到0.805-6。
应该指出,由于Kmeans算法具有一定的随机性,每次聚类的结果会存在部分差异。但经多次实验验证,平均轮廓系数关于候选簇数的变化趋势是稳定的,最佳簇数与最大平均轮廓系数也是稳定的。即使由于Kmeans算法的随机性,导致某次聚类产生了不佳的结果,由于PICBASIC利用轮廓系数同时对聚类结果进行量化评价,能够帮助用户有效地识别和剔除该次不佳聚类。
通常终端区内空中交通轨迹的盛行流会符合该机场的标准仪表进离场程序,个别情况由于恶劣天气和流量控制会出现等待、绕飞、返航或备降,所以最佳簇数一般不会与原有进离场飞行程序数量相差很大[5]。如果结合空域结构知识,参考机场跑道的标准仪表进离场程序数量,可适当缩减最佳簇数寻优范围,提高算法运行效率。
3.3 聚类结果与分析
28L和28R跑道进场空中交通轨迹聚类结果如图4所示,每个簇用不同线形区分。
由图4(a)可见28L跑道所有进场轨迹被聚类为5个簇,其中进场方向分别为西南、正南、东北的轨迹被划分为同一个簇,区分度明显,但西北方向进场轨迹却被划分为2个簇。再参考图4(b)可知西北方向进场轨迹的起始进场飞行高度存在高低之分,因此被划分为2个簇。28R和28L跑道进场轨迹的走向、飞行高度和形态等具有较高的相似度,聚类结果也相似。由图4(c)和图4(d)可见,28R跑道所有进场轨迹被聚类为6个簇,其中少数几条低飞行高度的异常轨迹被聚为一簇,该种聚类方式避免了异常轨迹对其他簇聚合度的破坏,能有效提高平均轮廓系数。
4 与其他聚类算法对比
在使用相同实验数据的情况下,选取文献[1]中MeanShift聚类与PICBASIC进行对比分析。文献[1]方法非参数无关,无法识别最佳簇数,为了方便比较,人为指定其簇数与PICBASIC按照最大平均轮廓系数确定的最佳簇数相同。此外,文献[1]方法包括3个重要的参数需要设定,分别是采样点数、主成分个数、带宽。为获得满意的聚类结果,多次实验调参后具体参数值详见表2。
聚类结果如图5所示。与图4相比,相似之处在于稠密的、大致相同进场方向的轨迹均被聚为一簇。但两次聚类结果也存在些许差异。由图5(a)和图5(b)可见,文献[1]方法将28L跑道西北方向高低两个飞行高度进场的轨迹划分为同一个簇; 由图5(c)和图5(d)可见,文献[1]方法依然将28R跑道西北方向高低两个飞行高度进场的轨迹划分为同一个簇,而且把东侧进场轨迹划分为正东和东北两个簇。此外,个别异常轨迹被两种方法划分到不同的簇。
为比較两种方法的聚类质量,统一采用平均轮廓系数进行评价,结果如表3所示。
PICBASIC与文献[1]方法的平均轮廓系数差异很小,证明应用PICBASIC得到的聚类结果具有较高的可信度,而且聚类质量较好。但由于PICBASIC参数无关,可避免文献[1]方法中人工指导聚类簇数和多次实验调参,具有更强的客观性、普适性和更低的用户负担。
5 结语
本文从分析空中交通轨迹的相似性度量出发,针对其聚类问题展开研究,提出一种基于轮廓系数评价的参数无关聚类方法,得到如下结论:
1)PICBASIC基于DTW距离定义轨迹间的相似度,具有欧氏距离直观性强、可信度高的优点,而且包容轨迹的速度和长度差异。
2)PICBASIC运算全程无需领域知识或人工经验确定任何参数,提高了算法普适性,增强了聚类结果客观性。
3)PICBASIC对每次轨迹聚类的结果提供量化评价指标,有利于比较聚类质量,降低Kmeans算法随机性的影响。
未来的研究工作包括在轨迹相似性度量中增加时间(航班繁忙时段或空闲时段)维度、剔除异常轨迹、以机型为指定条件进行更细粒度的轨迹聚类分析等,并在此基础上进一步评估和优化终端区飞行程。
参考文献 (References)
[1]赵元棣,王超,李善梅,等. 基于重采样的终端区飞行轨迹可信聚类方法[J]. 西南交通大学学报, 2017, 52(4):817-825.(ZHAO Y D, WANG C, LI S M, et al. Dependable clustering method of flight trajectory in terminal area based on resampling[J]. Journal of Southwest Jiaotong University, 2017, 52(4): 817-825.)
[2]HOU J, LIU W. Parameter independent clustering based on dominant sets and cluster merging[J]. Information Sciences, 2017, 405: 1-17.
[3]王超,徐肖豪,王飞. 基于航迹聚类的终端区进场程序管制适用性分析[J]. 南京航空航天大学学报, 2013, 45(1):130-139. (WANG C, XU X H, WANG F. ATC serviceability analysis of terminal arrival procedures using trajectory clustering[J]. Journal of Nanjing University of Aeronautics & Astronautics, 2013, 45(1): 130-139.)
[4]王莉莉,彭勃. 基于LOFC时间窗分割算法的航迹聚类研究[J]. 南京航空航天大学学报,2018,50(5):661-665. (WANG L L, PENG B. Track clustering based on LOFC time window segmentation algorithm[J]. Journal of Nanjing University of Aeronautics & Astronautics, 2018, 50(5): 661-665.)
[5]王超,韩邦村,王飞. 基于轨迹谱聚类的终端区盛行交通流识别方法[J]. 西南交通大学学报, 2014, 49(3):546-552. (WANG C, HAN B C, WANG F. Identification of prevalent air traffic flow in terminal airspace based on trajectory spectral clustering[J]. Journal of Southwest Jiaotong University, 2014, 49(3): 546-552.)
[6]KALAYEH M M, MUSSMANN S, PETRAKOVA A, et al. Understanding trajectory behavior: a motion pattern approach[EB/OL]. [2019-01-01]. https://arxiv.org/pdf/1501.00614.pdf.
[7]王超,鄭旭芳,卜宁. 基于小波聚类的终端区进场轨迹模式识别[J].计算机应用与软件, 2016, 33(11):112-116. (WANG C, ZHENG X F, BU N. Pattern recognition of approach landing trajectories in terminal airspace based on wavelet clustering[J]. Computer Applications and Software, 2016, 33(11): 112-116.)
[8]石陆魁,张延茹,张欣. 基于时空模式的轨迹数据聚类算法[J]. 计算机应用, 2017, 37(3):854-859. (SHI L K, ZHANG Y R, ZHANG X. Trajectory data clustering algorithm based on spatiotemporal pattern [J]. Journal of Computer Applications, 2017, 37(3): 854-859.)
[9]ZHANG D, LEE K, LEE I. Hierarchical trajectory clustering for spatiotemporal periodic pattern mining[J]. Expert Systems with Applications, 2018, 92: 1-11.
[10]YUAN G, SUN P, ZHAO J, et al. A review of moving object trajectory clustering algorithms[J]. Artificial Intelligence Review, 2017, 47(1): 123-144.
[11]REHM F. Clustering of flight tracks[C]// Proceedings of the 2010 American Institute of Aeronautics and Astronautics Infotech and Aerospace. Reston, VA: AIAA, 2010: 1-9.
[12]徐涛,李永祥,吕宗平. 基于航迹点法向距离的航迹聚类研究[J]. 系统工程与电子技术, 2015, 37(9):2198-2204. (XU T, LI Y X, LYU Z P. Research on flight tracks clustering based on the vertical distance of track points[J]. Systems Engineering and Electronics, 2015, 37(9): 2198-2204.)
[13]AGRAWAL R, LIN K I, SAWHNEY H S, et al. Fast similarity search in the presence of noise, scaling, and translation in timeseries databases[C]// Proceedings of the 21th International Conference on Very Large Data Bases. San Francisco: Morgan Kaufmann Publishers, 1995:490-501.
[14]龚玺,裴韬,孙嘉,等. 时空轨迹聚类方法研究进展[J]. 地理科学进展, 2011, 30(5):522-534. (GONG X, PEI T, SUN J, et al. Review of the research progresses in trajectory clustering methods[J]. Progress in Geography, 2011, 30(5): 522-534.)
[15]LEI J, YIN J, SHEN H. GFO: a data driven approach for optimizing the Gaussian function based similarity metric in computational biology[J]. Neurocomputing, 2013, 99: 307-315.
[16]von LUXBURG U. A tutorial on spectral clustering[J]. Statistics and Computing, 2007, 17: 395-416.
[17]ROUSSEEUW P J. Silhouettes: a graphical aid to the interpretation and validation of cluster analysis[J]. Journal of Computational and Applied Mathematics, 1987, 20: 53-65.
[18]HAN J, KAMBER M, PEI J.數据挖掘: 概念与技术[M]. 范明,孟小峰,译. 3版. 北京: 机械工业出版社, 2015:317. (HAN J W, KAMBER M, PEI J. Data Mining: Concepts and Techniques[M]. FAN M, MENG X F, translated. 3rd edition. Beijing: China Machine Press, 2015: 317.)
[19]OZO N. Flight tracks, Northern California TRACON[DB/OL]. [2019-01-01]. https://c3.nasa.gov/dashlink/resources/132.
[20]SHEN H. On optimizing Gaussian function based similarity metric in computational biology[EB/OL]. [2019-04-01]. http://www.csbio.sjtu.edu.cn/bioinf/GFO/.
This work is partially supported by the Foundation of Research Base of Air Traffic Management of Civil Aviation University of China (KGJD201702).
SUN Shilei, born in 1982, M. S., lecturer. His research interests include machine learning, data mining.
WANG Chao, born in 1971, Ph. D., professor. His research interests include air traffic system simulation and analysis, transportation planning and management.
Zhao Yuandi, born in 1983, Ph. D., research assistant. His research interests include air traffic management information processing.
猜你喜欢
软件导刊(2016年11期)2016-12-22
科技创新导报(2016年21期)2016-12-17
对外经贸(2016年8期)2016-12-13
数学学习与研究(2016年19期)2016-11-22
商场现代化(2016年26期)2016-11-21
大经贸(2016年9期)2016-11-16
中国市场(2016年33期)2016-10-18
科技视界(2016年20期)2016-09-29
企业导报(2016年9期)2016-05-26
