
基于多任务深度学习的齿轮箱多故障诊断方法
2019-12-23 05:28赵晓平吴家新钱承山张永宏王丽华
振动与冲击 2019年23期
赵晓平,吴家新,钱承山,张永宏,王丽华
(1. 南京信息工程大学 计算机与软件学院,南京 210044; 2. 南京信息工程大学 信息与控制学院,南京 210044)
齿轮箱主要由齿轮、轴承、轴和箱体等重要零部件组成,具有结构紧凑、传动效率高、寿命长、工作可靠等特点,是航空、电力系统、汽车、工业机床等现代化工业中必不可少的通用部件[1]。但是由于齿轮箱的结构复杂,并且通常在恶劣的环境下持续高速运转,很容易发生故障,因此齿轮箱的故障是诱发机器故障的重要因素。齿轮和轴承作为齿轮箱的两个重要零件,极易因疲劳磨损出现局部故障,导致齿轮箱运行的异常,轻则机器中断,造成经济损失,重则机毁人亡。因此研究高效的齿轮箱状态监测与故障识别技术,对保障生产安全,预防和避免重大事故发生有着重要的意义[2]。
近年来,深度学习技术迅猛发展,尤其在图像分类、目标识别等领域取得了难以置信的成功,也有一些研究表明深度学习技术同样可以运用在语音识别领域。受这些研究的启发,机械故障领域的许多专家学者也尝试将深度学习技术运用于机械故障诊断,并取得了不错的效果。
Shao等[3]、Wang等[4]和Chen等[5]均采用深度信念网络(Deep Belief Network, DBN)实现了滚动轴承和齿轮箱的故障诊断,并与一些现有的主流故障诊断方法进行了比较,验证了DBN的鲁棒性和精确性。随后,Li等[6]紧跟前人的研究,在DBN的基础上,对高背景噪声下信息提取与融合等方面进行研究,且取得了传统方法无法比拟的效果。
Sun等[7]利用稀疏自编码器(Sparse Autoencoder, SAE)实现了异步电机的故障诊断,通过具有无监督特征提取优势的稀疏自编码模型来自适应提取故障特征,并在降噪编码的作用下去除特征的干扰项,提高了特征表示的鲁棒性和故障诊断的精度。类似的研究还扩展至航空发动机[8]、核电站[9]、风力发电机组设备[10]、齿轮箱[11]、滚动轴承[12]、变压器[13]以及旋转机械[14]等复杂系统的故障诊断领域,并且均取得了良好的效果。
Zhang等[15]构建了一个多层的一维卷积神经网络(Convolutional Neural Network,CNN),并使用凯斯西储大学的轴承数据的时域信号进行故障诊断研究,取得了不错的效果。Wang等[16]使用短时傅里叶变换将采集得到的电机振动信号转换成频谱图,然后构建二维卷积神经网络进行故障诊断,获得了较高的诊断精度。Verstraete等[17]则使用短时傅里叶变换、小波包变换和希尔伯特黄变换三种方法将滚动轴承时域信号转变成时频谱图,然后分别使用卷积神经网络进行训练,并且通过改变输入时频谱图的尺寸和加噪方式研究了网络的性能,结果表明通过时频转换方法将一维信号转变成二维的时频图,再通过卷积神经网络进行故障诊断,能够取得很好的效果。
上述的研究展示了深度学习在面对机械大数据任务时,强大的自适应特征提取和分类能力。然而这些研究均运用在单标签体系下,诊断单一目标故障,在大数据背景下,单标签体系不仅割裂了机械装备不同故障之间的联系,也难以完整描述装备故障位置、类型、程度等种类繁多的健康状态信息。因此本文引入多标签体系,使用一维卷积神经网络构建多任务深度学习模型,对采集得到的齿轮箱轴承和齿轮的多故障信号进行故障分类,实验结果表明在两种故障同时存在的情况下,该模型能够准确的判断出齿轮和轴承各自的故障类型。
1 基于一维卷积神经网络的多任务深度学习
1.1 卷积神经网络
卷积神经网络(Convolutional Neural Network,CNN)通常包括输入层、卷积层、池化层和最后的全连接层。卷积层通过卷积核对输入信号进行卷积操作,是特征提取的主要执行者,具有局部观察、权值共享和高层聚合等特性[19]。为了适应齿轮箱振动频域信号的一维特性,本文使用一维卷积构建卷积神经网络。
1.1.1 一维卷积
卷积层上的一个卷积核能够检测输入信号所有位置上的特定特征,实现对同一输入信号的权值共享。为了提取不同的特征,往往需要在同一个卷积层中设置不同的卷积核进行卷积操作。卷积的一般形式如公式(1):
(1)

1.1.2 池化层
池化是一个采样的过程,能够大大降低特征的维数,避免过拟合。本文使用最大值池化的方法,使下一层神经元在面对一些较小幅度的改变时能够保持不变性,提高网络的鲁棒性。
1.1.3 全连接层
全连接层的所有神经元节点,都与上一层输出的特征图中所有的神经元节点互相连接,将最后一层的输出特征图映射成一维的向量。其输出如式(2)所示。
h(x)=f(w·x+b)
(2)
式中:x为全连接层的输入;h(x)为全连接层的输出;w为权值;b为加性偏置;f(·)为激活函数。为了防止分类时出现过拟合的情况,通常在全连接层引入“Dropout”[19]的方法。即在训练时,以一定的概率P,让隐藏层的某个神经元停止工作,从而提高网络的泛化能力,防止过拟合。
1.1.4 分类器
Softmax[20]是Logistic分类器的一种推广,主要解决多分类问题。假设训练数据中输入样本为x,对应的标签为y,则将样本判定为某个类别j的概率为p(y=j|x)。所以对于一个K类分类器,输出的将是一个K维的向量(向量的元素和为1),如式(3)所示。
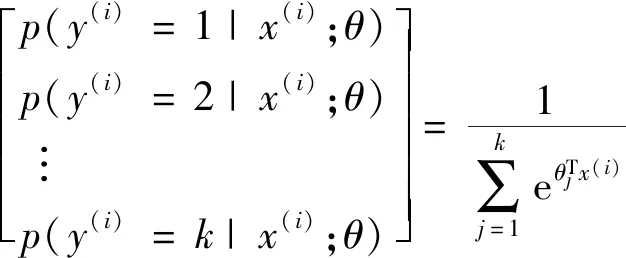
(3)

1.2 多任务深度学习模型
本文的研究对象为齿轮箱内的齿轮故障及轴承故障,不是单个目标而是两个。因此本文使用多任务学习方式来构建网络模型。多任务学习可以提取多个任务的共享特征,这个共享特征具有较强的抽象能力,能够适应多个不同但相关的目标,通常可以使模型获得更好的泛化能力。此外,通过使用共享层,在多个任务同时进行预测时,可以减少整体模型参数的规模,提高诊断效率。
图1为本文所使用的多任务深度学习模型,图中方框A为共享层,使用两个卷积层来提取任务1和2的共享特征,方框B为任务1层,用于识别轴承故障,方框C为任务2层,用于识别齿轮故障。本文使用联合训练的方式训练网络,即求Loss1与Loss2的平均损失,然后使用优化器进行参数优化。本研究中使用交叉熵损失函数定义Loss1和Loss2,使用Momentum优化器(学习率:0.1,动量衰减:0.9)进行参数优化,各网络层结构参数见表1。

图1 多任务深度学习模型

表1 网络结构参数
2 实验与分析
2.1 数据采集
深度学习网络的训练需要大量的数据支持,训练数据的质量会直接影响模型的效果。因此本文以动力传动故障诊断试验台(如图2)为研究对象。通过更换齿轮箱内的故障齿轮和故障轴承,模拟齿轮箱可能会发生的30种多故障情况,如图3所示。

图2 动力传动故障诊断试验台
为了增加样本的多样性,在数据采集时通过改变转速和负载,尽可能的模拟实际生产中可能发生的工况类型。通过控制前端的驱动电机来改变转速,采集时选取1 700 r/min、1 800 r/min、3 400 r/min和3 800 r/min四种转速,使采集到的数据不仅包含相近转速数据,同时包含跨度较大的转速数据。同时在每种转速下通过调节试验台后端的磁粉制动装置,改变负载,负载种类见表2。

表2 负载种类
本研究对采集得到的振动信号进行分析,采集数据时使用单向加速度传感器(SQI608A11-3F)。安装传感器时,本研究参考凯斯西储大学轴承数据的采集方式,通过螺栓联接将加速度传感器安装在齿轮箱定轴的左右两侧(如图2中传感器1、2的位置)。设置传感器采样频率为20 kHz,采样时间为20 s。当驱动电机转速平稳后进行数据采集,采集时为了更真实的模拟生产环境,会随机的通过金属敲击的方式进行人为噪声污染,约占采得总信号的5%。
最终,每种工况下可采集得到的左右两个通道的时域信号。最终采集到了960个(30种多故障组合类型*4种不同转速*4种不同负载*2(左右双通道))振动信号文件,每个信号文件中包含409 600个信号点。
2.2 数据切分及预处理
实验前对原振动信号文件进行随机切分,将每个信号文件中的409 600个点切分为200个[1,2 000]的时域信号。为了能够充分研究本文模型的识别能力,制定了9种不同的数据的划分方式,具体划分方式如下:
1) 按百分比切分:随机选取每个原始信号的75%(即150个)作为训练集,剩余25%(即50个)作为测试集
2) 按转速切分:选取1种转速下的所有信号作为测试集,余下3种转速下的信号作为训练集。
3) 按负载切分:选取1种负载下的所有信号作为测试集,余下3种负载下的信号作为训练集。
按上述方式切分后获得的实验数据如表3所示。
切分后得到时域信号,而在文献[12,16]的研究中均表明将时域信号直接作为输入数据进行网络训练的效果不佳。同时实际实验时也发现,将时域信号作为输入,训练时网络的损失无法收敛,且准确率仅有30%。因此在验证本文网络模型前,使用快速傅里叶变换求解频域信号,得到的信号长度为1 000个点。将频域信号作为网络输入,验证模型效果。在进行实验前,需要对数据的标签进行编码,本文采用One-Hot编码方式,具体故障编码如表3。在训练、测试及实际诊断时,表3中轴承,和齿轮故障分别对应本文提出的表1中多任务深度学习模型Softmax S1和S2层的输出,该层输出一个长度为5和6的概率向量,将此概率向量的最大值位置记为1,其余为记为0,则可得到网络预测出的两个One-Hot编码,该预测编码用于表示诊断结果和统计准确率。
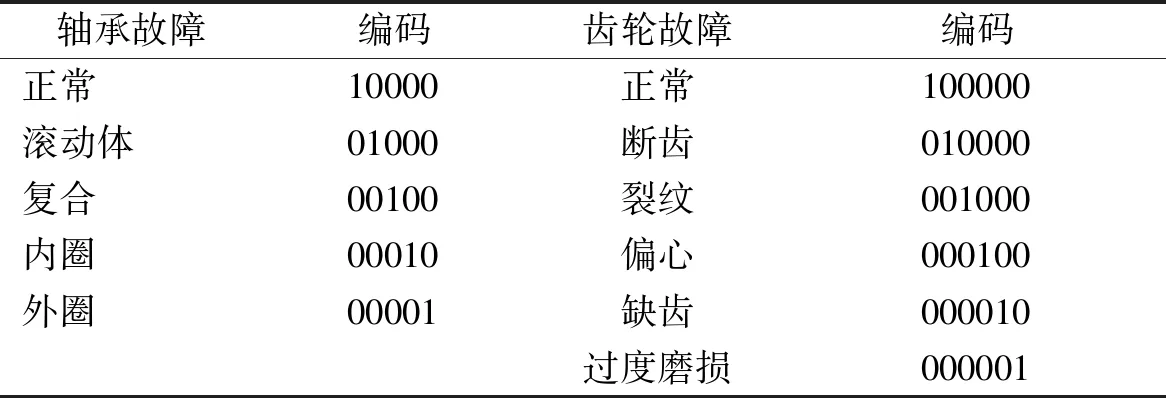
表3 故障编码
2.3 实验验证
本实验训练和测试的硬件环境为i7-6700 CPU、英伟达GTX970显卡(显存4G)、16G内存,软件编程环境为python3.6、Tensorflow1.2、CUDA8.0。网络训练时输入样本大小为1 000×1,设置Batch-size为600,训练上限设置为40 000次,且每20次记录一次训练集准确率。为了更好的观察模型的效果,设置每200次迭代进行一次测试集的测试,并记录测试集准确率。
使用表4中的数据分别输入图1中的网络进行模型训练,并统计了实验中准确率变化,表5中列出了各个实验取得的最高测试集联合准确率(即任务1诊断正确且任务2诊断正确),以及所对应的单个任务测试集准确率和训练集准确率。
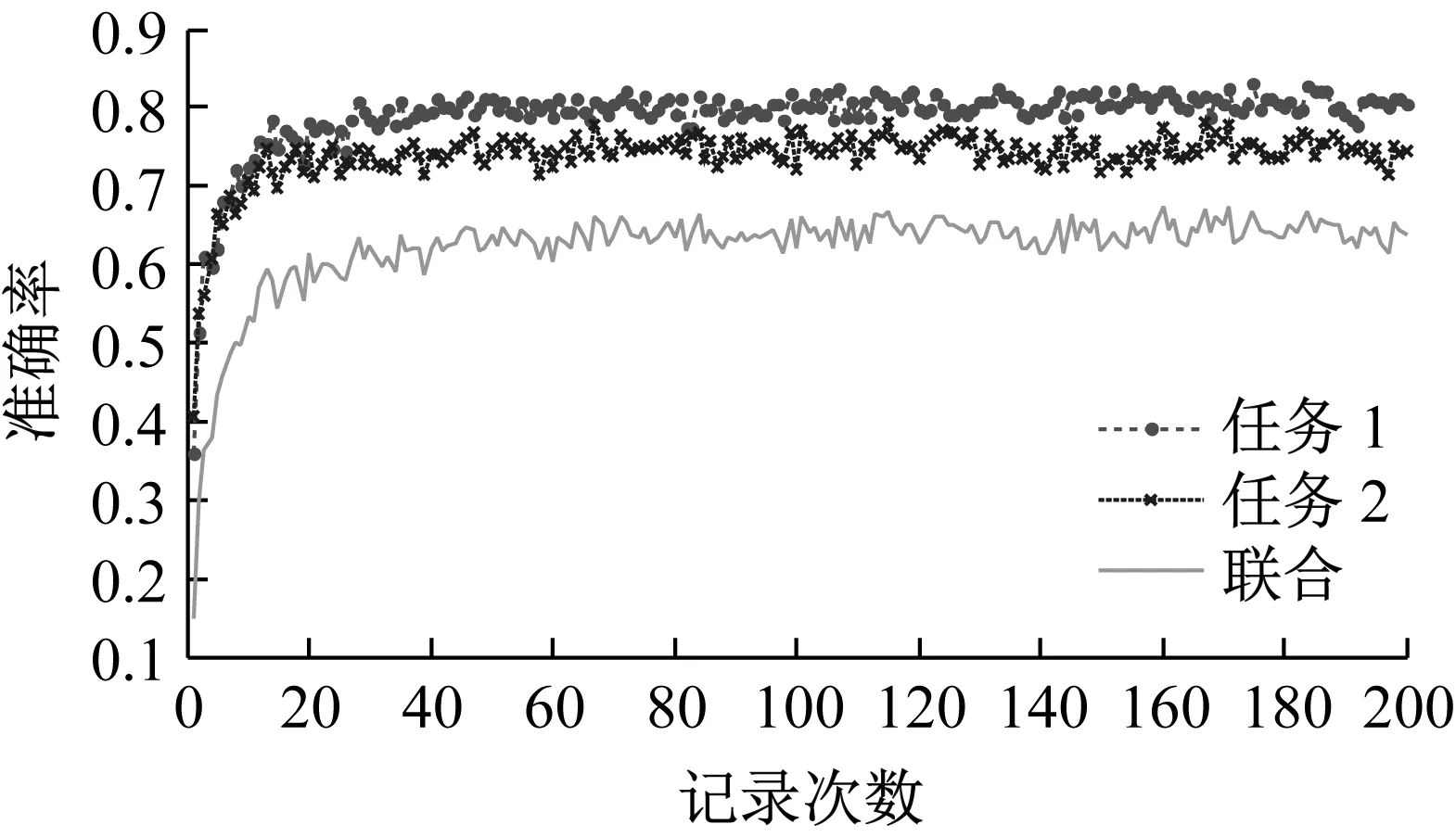
从表5中实验结果可以看出,当按百分比切分数据(即训练数据充足,包含各种转速和负载情况),并且对数据进行归一化处理时(即表5实验10),模型的联合准确率最高可以达到94.6%,且轴承和齿轮识别任务的单独准确率达到96.37%和97.69%。如图4、5分别为实验10中测试集和训练集准确率上升曲线。从图4,5中可以看出,随着不停的迭代训练,准确率平稳上升。使用缺失某种负载的数据训练网络,且使用该缺失负载数据进行网络测试时(实验2-5,11-14),依然能够获得很高的单一任务准确率,且联合准确率可以达到90±2%。而使用缺失某种转速的数据训练网络,且使用该缺失转速数据进行网络测试时(实验6-9,15-18),网络模型产生了严重的过拟合现象,测试集准确率很低。
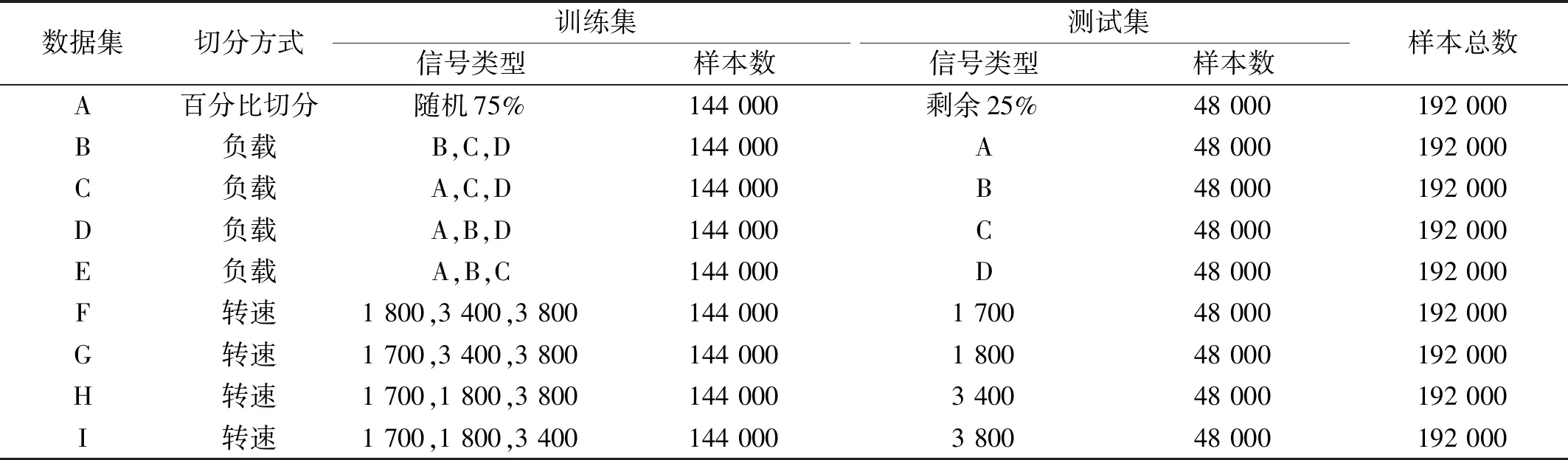
表4 实验数据切分

图4 实验10测试集准确率
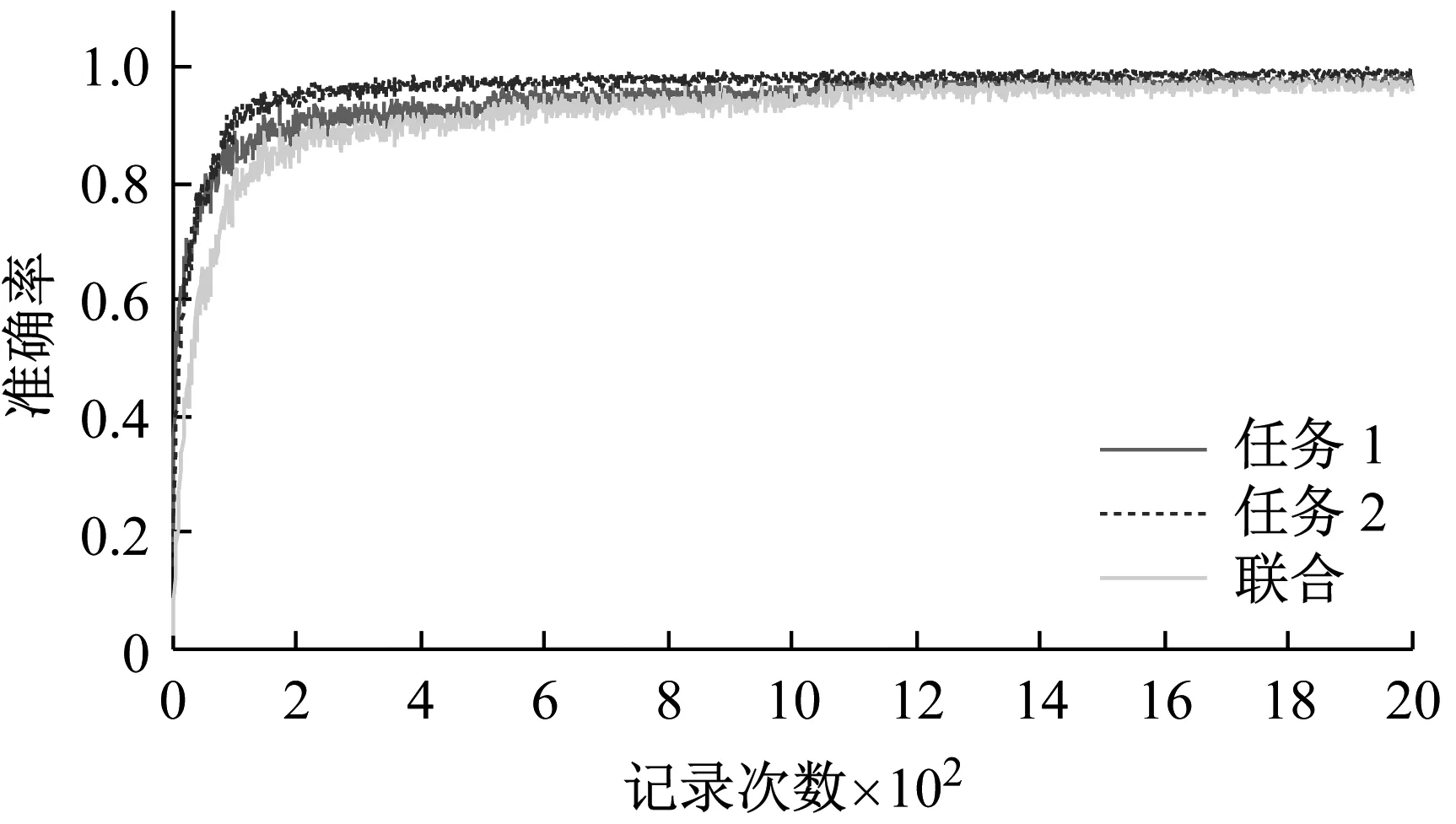
图5 实验10训练集准确率

表5 多任务网络实验结果

图6 单标签网络模型
Fig.6 The model of single label network
2.4 实验对比分析
为了与传统单标签网络进行对比,验证本文提出的多任务网络的有效性,本文使用如图6所示的单标签网络进行对比实验。制作标签时,对30种组合故障类型使用One-hot编码。经过多轮迭代后,实验结果如表6所示。

表6 单标签网络实验结果
从表6中可以看出,使用单标签网络进行多故障诊断时,效果较本文提出的多任务网络差异明显。最高的测试集准确率仅有73%,无法有效的进行齿轮箱多故障识别。
本文提出方法能够在数据充分的情况下取得较高诊断精度的根本原因之一是:该方法通过使用共享层和独立的两个任务层,能够自适应的从一个信号中提取两种不同故障目标的特征。为了更加直观的验证提出方法在特征提取上的能力,随机选取了一段信号,将其输入表5中实验10取得最高准确率的网络模型,将图1中卷积层C3_1,和卷积层C3_2输出的特征进行可视化。

图7 卷积层C3_1输出特征可视化

图8 卷积层C3_2输出特征可视化
从图7和8能够明显看出,对于同一段输入信号,不同任务层的同一级卷积层所提取出的特征差异很大。这也是本文提出的多任务深度学习模型在单独对轴承和齿轮任务进行诊断时,能够取得较高准确率的原因。而使用图6中传统的单标签网络处理这种多故障的任务时,由于单标签网络不能够很好的分离提取同一信号中不同故障目标的特征,因此即使在数据充足的情况下也不能够获得很高的准确率。
2.5 实验展望
对比表5中6-9、15-18实验的结果发现,当使用按转速切分数据集时,网络模型出现了严重的过拟合现象,测试集单个任务的准确率较训练集降低了12%~40%,而测试集联合准确率也同样出现了相同程度的降低。图9列举了实验15-18的测试集准确率上升曲线,从图中可以看出,当训练集缺失的转速较低(实验15∶1 700 r/min;实验16∶1 800 r/min)时,其测试集准确率明显高于训练集缺失转速较高的情况(实验17∶3 400 r/min;实验18∶3 800 r/min)。

(a) 实验15
(b) 实验16

(c) 实验17

(d) 实验18
在文献[12,16]等均使用了深度学习方法对机械故障诊断进行研究,且划分训练和测试数据时都使用了随机百分比切分的方式。而在本方法的实验中,加入了按转速和负载切分数据的方式来模拟实际应用中可能发生的数据缺失问题。结果表明在缺失转速数据的情况下对模型进行训练,模型的泛化能力不足。因此下一步的研究重点因集中在转速及负载缺失数据下,对模型泛化能力的提升。
3 总 结
本文首次使用多任务深度学习模型同时对齿轮箱内轴承和齿轮故障进行诊断,并通过不同的方式对采集得到的数据集进行切分,来模拟实际应用中可能遇到的缺失某种工况数据的情况,从而验证网络模型的性能,同时构建了单标签网络进行对比分析,结论如下:
(1) 当数据种类不存在缺失时,多任务深度学习模式在同时应对多个故障的识别任务时,能够自适应的提取各任务的特征。在面对单一任务时能够取得96.37%和97.69%的准确率,且其诊断的联合准确率依然很高,能够达到94.6%,远远高于使用单标签网络进行诊断的效果。
(2) 当使用缺失某种负载的数据训练网络,且使用该缺失负载数据进行网络测试时,依然能够获得很高的单一任务准确率,且联合准确率可以达到90±2%。
(3) 当使用缺失某种转速的数据训练网络,且使用该缺失转速数据进行网络测试时,网络模型产生了严重的过拟合现象,测试集准确率很低。
(4) 本文所采集的齿轮箱多故障数据集具有一定的研究价值,可用于评估针对此类问题的模型。下一步的研究重点因集中在转速及负载缺失数据下,对模型泛化能力的提升。
猜你喜欢
山东冶金(2022年3期)2022-07-19
北京航空航天大学学报(2021年9期)2021-11-02
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
中国交通信息化(2018年5期)2018-08-21
北京航空航天大学学报(2018年1期)2018-04-20
制造技术与机床(2017年4期)2017-06-22
