
基于高光谱图像信息融合的红提糖度无损检测
2019-12-20 06:10王巧华
发光学报 2019年12期
高 升,王巧华,2*
(1. 华中农业大学 工学院,湖北 武汉 430070;2. 农业农村部长江中下游农业装备重点实验室,湖北 武汉 430070)
1 引 言
葡萄被誉为四大水果之首,2017年我国的葡萄总产量高达1308.0万吨[1]。红提葡萄颗粒饱满、果肉坚实、香甜可口、富含较多的营养物质,受到人们的广泛喜爱。糖度(可溶性固形物)是水果的重要品质之一,决定了果实的风味,是消费者进行购买时的重要参考,也是反映水果成熟度的重要指标[2-3]。
水果糖度(可溶性固形物)的传统检测方法为进行破坏试验,挤出汁液利用折射法进行测定[4],因检测方法繁琐费时,且只能进行抽样检测,检测范围较小,检测完的实验样本已完全损坏,无法销售,造成较大的浪费。光谱技术具有检测时间短、操作简单、能保证果实的完整性和安全性等优点[5-7]。高光谱技术是近些年发展起来的新技术,它涵盖了光谱技术和图像技术两种检测方法,被广泛应用在苹果[8]、哈密瓜、梨、脐橙[9]等水果和蔬菜的内部品质的无损检测[10-11]。金瑞等[12]针对随机放置的马铃薯缺陷多项指标难以同时检测的问题,提出了一种基于高光谱信息融合的流形学习降维算法,结果表明高光谱信息融合技术结合流形学习降维算法可同时识别随机放置马铃薯的多种缺陷指标。Dong等[13]利用高光谱成像技术研究了在不同地方生长的‘富士’苹果的可溶性固形物含量(SSC)的无损测定,使用连续投影算法(SPA)和无信息变量消除(UVE)方法从全光谱中选择有效波长并分别建立偏最小二乘法回归(PLSR)、最小二乘支持向量机(LSSVM)和极端学习机(ELM)模型,最终确定了最优SSC预测模型是基于SPA选择的有效波段所建立的LSSVM模型,模型预测集的相关系数和均方根误差分别为0.878和0.908°Brix。Guo等[14]通过近红外(NIR)高光谱成像确定“Xixuan”和“Huayou”品种的完整猕猴桃的可溶性固形物含量(SSC),并确定了“Xixuan”和“Huayou”品种及两种品种结合的最佳SSC模型分别为SPA-LSSVM、FS-LSSVM和FS-LSSVM,预测集的相关系数分别为0.766,0.971,0.911,且预测集的均方误差分别为0.968,0.589,1.137。该研究证明了使用近红外高光谱成像技术作为预测猕猴桃SSC方法的可行性。目前,国内外在葡萄品质检测方面有较多研究,Julio等[15]以高光谱成像方法检测葡萄皮多酚含量、果肉汁的糖度酸度来确定成熟期间白葡萄的成熟度。Arana等[16]采用漫反射光谱对白葡萄的成熟度、品种、产地进行检测。Baiano等[17]利用高光谱技术测定7个品种的鲜食葡萄的内部品质指标,可溶性固形物含量的相关系数分别为0.94和0.93,但模型的稳定性及预测准确性可进一步提高。然而,已有研究中大都只利用光谱信息建立葡萄糖度的模型,模型的预测性能不高,利用高光谱技术融合图像信息的红提糖度无损检测研究还未见报道。
本文通过高光谱成像技术,采集红提的高光谱图像信息和光谱信息,分别对比分析了基于光谱特征、图像颜色形态特征、光谱信息与图像信息融合,三种模式下所建立的红提糖度PLSR和LSSVM模型的优劣,提出了一种结合高光谱图像信息和光谱信息建立稳定的红提糖度预测模型,为红提糖度的无损检测提供了可靠的检测模型及方法。
2 材料和方法
2.1 材料
实验材料为新鲜的红提,在每穗红提的穗外部、穗中部、穗顶部、穗尖分别挑选大小相近、颜色差异较大、完好无损的红提果粒作为实验样本,建模样本总数为260粒。将样本编号并放入恒温恒湿箱中保存12 h,恒温箱温度设置为(22±1) ℃,相对湿度为65%。
2.2 仪器与设备
申光WAY(2WAJ) 阿贝尔折射仪,上海仪电物理光学仪器有限公司;恒温恒湿箱,上海新苗医疗器械制造有限公司;Zolix Hyper SIS-VNIR-CL高光谱成像系统,美国海洋光学公司,该系统主要由高光谱成像光谱仪(芬兰Spectral Imaging Ltd.公司)、CCD相机(日本Hamamatsu公司)、4个50 W的卤素灯(北京卓立汉光仪器有限公司)、1台丝杆式位移控制平台(北京卓立汉光仪器有限公司)等主要部件组成。该系统采集的光谱波长范围为391~1 043 nm(含有520个波长),分辨率为2.8 nm,整个采集系统置于暗箱内。
2.3 方法
2.3.1 高光谱图像信息采集
高光谱成像系统预热半小时后进行实验。由于暗电流及CCD相机芯片不稳定的影响,图像会产生一定的噪声,因此在样本采集前需要对高光谱图像进行黑白校正。将标准白板(聚四氟乙烯长方形白板)放在采集平台上,获得白板数据IW;盖上相机盖,获得全黑标定图像ID;将红提放在采集平台上获得原始高光谱漫反射图像IR;根据公式(1)得到校正后红提的图像R[9]:
(1)
实验时,在平台上放置自制的带孔载物平板。高光谱成像系统的参数设置为:相机曝光时间为0.15 s,平台移动速度为1.7 mm/s,移动范围为0~245 mm,样本平台与镜头的距离为420 mm。高光谱图像采集系统如图1所示。
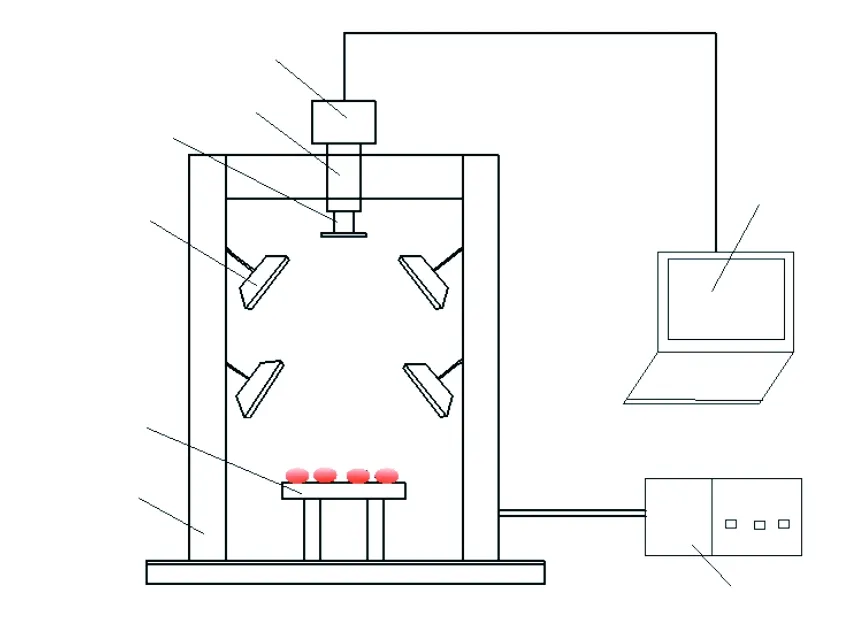
图1 高光谱图像采集系统
2.3.2 光谱数据采集
试样制备:光谱采集完的红提样本,按照国家鲜葡萄行业标准GH/T 1022-2000,分别对红提果粒压成汁,并用玻璃棒搅匀,并立即进行糖度的测定。
糖度测定:用一次性滴管将取出的汁液滴到折射仪上,糖度测定参照NY/T 2637-2014《水果、蔬菜制品可溶性固形物含量的测定——折射仪法》[4],并记录数据。
2.3.3 感兴趣区域的提取及光谱数据处理
本研究把单粒图像作为感兴趣区域进行光谱信息的提取,需要将单粒红提从带有背景的高光谱图像中进行分割。在Matlab R2016a软件上对高光谱图像进行处理,选择图像中整粒红提的图像作为RIO(感兴趣区域),提取RIO的平均光谱作为原始光谱信息。分析时去除两端噪声较大的波长,本文选取450~1 000 nm(含有439个波长)的波长进行建模。在进行RIO提取时,由图2中背景与红提果粒区域的反射率可知,在600~900 nm范围内背景的反射率较低而红提果粒反射率较高,在726.6 nm时两者反射率的差值最大。因此选取726.6 nm处的灰度图像进行果粒区域的提取,如图3(a)所示。首先将灰度图像采用Otsu阈值分割方法获得二值图像,灰度图像如图3(b),然后利用中值滤波和腐蚀运算,得到背景区域为0、果粒区域为1的二值图像,并将得到的二值图像作为掩膜模板,如图3(c)所示。最后依次将每个果粒分割出来,并提取高光谱图像中单个样本红提果粒区域的光谱信息进行建模,掩膜后红提区域图像如图3(d)所示。
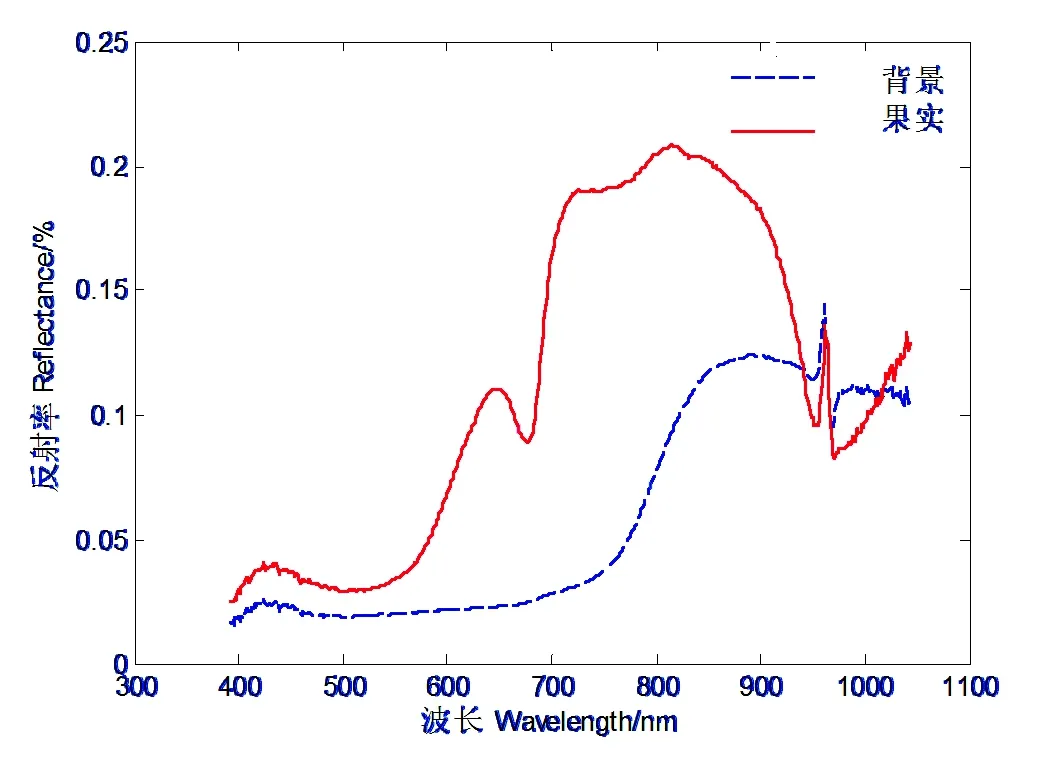
图2 高光谱图像中背景与红提区域的反射率
Fig.2 Reflectivity of background and red-lifted areas in hyperspectral images
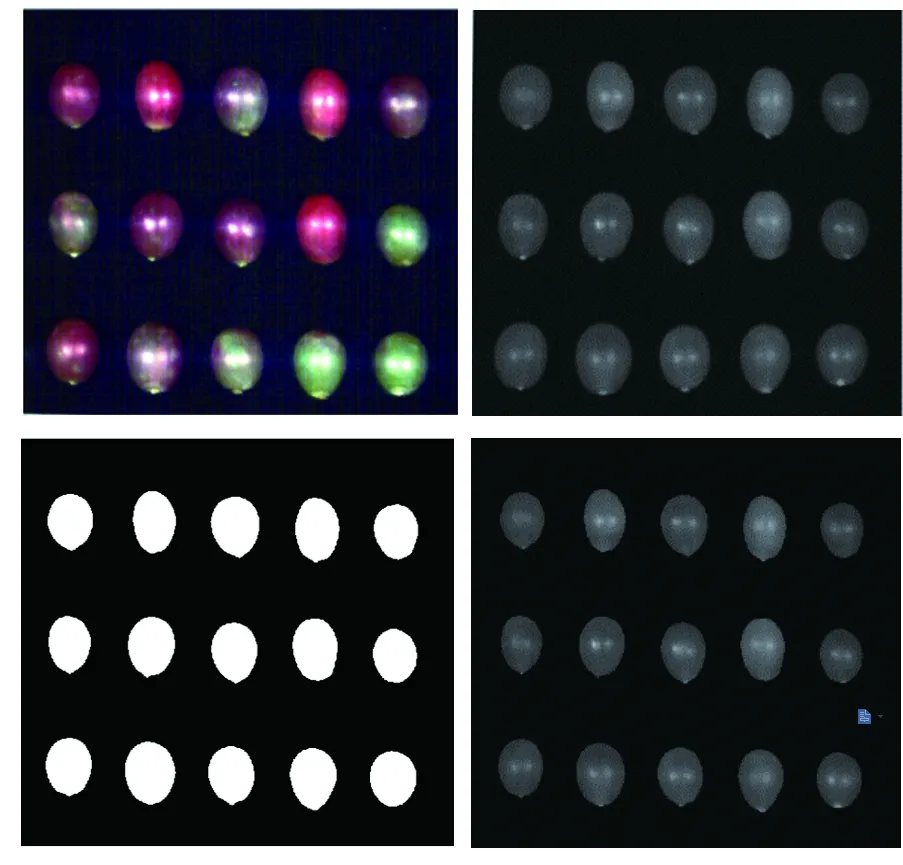
图3 光谱信息提取过程。(a)高光谱原始图像;(b)灰度图像;(c)掩膜模板图像;(d)掩膜后红提图像。
Fig.3 Spectral information extraction process. (a) Hyperspectral image. (b) Grayscale image. (c) Mask template image. (d) Red globe grape image after mask.
2.3.4 图像特征参数的提取
灰度共生矩阵(Gray level co-occurrrence matrix,GLCM)具有适应性强、鲁棒性好的特点,经常应用于图像纹理特征的提取[18]。由于纹理是灰度分布在空间位置上重复出现的结果,故在灰度图像上,任意2个像素点之间存在一定的灰度关联性质,GLCM可以表示出图像灰度的改变方向、变化幅度、相隔间距等的综合纹理信息。灰度共生矩阵的计算公式为:
P(i,j,d,θ)=
[(x,y)(x+D,y+D)|{f(x,y)=i;
f(x+D,y+D)=j}],
(2)
其中,P为灰度共生矩阵;(x,y)为原图形中任意点的像素坐标;i是位于(x,y)处像素点的灰度;j是位于(x+D,y+D)处像素点灰度;θ、D为(x+D,y+D)和(x,y)像素点之间偏移的角度和距离;f(x,y)是图像中坐标为(x,y)的灰度;d为灰度共生矩阵的步长,取值为1。
其中角度一般采用0°、45°、90°、135°,为保证实际计算中参数的旋转不变性,将4个角度所计算出的特征值取平均值[18]。
彩色图像有RGB、HSV、Lab三种色彩空间,且每种色彩空间都具有明显的特征信息,本研究共提取9个通道(R、G、B、H、S、V、L、a、b等9个颜色通道)信息作为图像的颜色特征参数。纹理信息可以较好地描述物体表面的特征,本文采集红提灰度图像的均值、对比度、相关性、能量、同质性、熵、灰度标准差、平滑度、三阶矩、一致性共10个作为图像的纹理特征信息,总共组合得到红提图像的19个图像特征。
首先将高光谱原始图像3(a)转换为灰度图像,按照光谱提取的方法依次将每个果粒分割出来,根据图像特征参数的提取方法,分别提取单个果粒的19个图像特征。
2.3.5 模型建立及评价方法
本文分别基于光谱信息和图像信息融合建立红提糖度的线性PLSR、非线性LSSVM模型。
对比分析原始光谱及光谱预处理后所建模型的优劣,确定了最优的光谱预处理方式,并在最优光谱预处理下,分别采用一次降维(GA、CARS、IRIV)算法和组合降维算法(CARS-SPA、IRIV-SPA、GA-SPA)六种降维方法对光谱信息进行特征变量提取;分别结合偏最小二乘回归算法(Partial least squares regression,PLSR)与最小二乘支持向量机(Least squares support vector machine,LSSVM)进行模型的建立,对比分析模型的优劣。
PLSR是一种经典的通过最小化偏差平方和对曲线进行线性拟合的方法,结合了多元线性回归、相关分析和主成分的优点。最小二乘支持向量机(LSSVM)通过求解一次线性组来代替支持向量机中复杂二次优化问题,有效地简化了模型,提高了模型的运算速度。
模型的准确性和稳定性由校正集相关系数(Rc)及均方根误差(RMSEC)、预测集相关系数(Rp)及均方根误差(RMSEP)、残差预测偏差(Residual predictive deviation,RPD)ΔRPD进行模型性能的评价。相关系数越接近1,均方根误差越接近0,模型的预测性能及稳定性越好。ΔRPD的评价指标:ΔRPD的值小于1.5表示预测性能较差;1.5~2.0之间表示模型可以预测低值和高值;2.0~2.5之间表示可以进行粗略的定量预测;2.5~3.0或更高的值表示具有良好的预测精度[19]。

(5)
(6)
ΔRPD=Δstdp/RMSEP,
(7)
其中,ypi为预测集或校正集中的第i个样本的预测值及其实际测量值;ymi为校正集中的第i个样本的预测值及其实际测量值;ymean表示对应所有nc个校正集样本或np个预测集样本实际测量值的平均值;Δstdp为预测集的标准差。
3 结果与讨论
3.1 样本集的划分
KS(Kennard-Stone,KS)法[20]的优点是能够有效地选取光谱数据差异较大的样本作为校正集,剩余的样本划分为预测集,提高模型的稳定性和预测精度。实验中共采集了260份红提样本,按照3∶1比例利用KS算法划分为195个校正集样本,65个预测集样本(表1)。从表2中可以看出,糖度分布范围为(15.500~22.000)°Brix,校正集和预测集的标准差值分别为1.068和1.099。

表1 利用KS算法划分样本集的数据统计

表2 采用不同预处理方法的全波长PLSR预测模型
3.2 光谱数据采集及预处理
从图4中可以得出,所有红提样本的光谱都呈现出相同的变化趋势,在450~550 nm区间内曲线平滑,吸光度变化较小,550 nm之后反射强度快速升高,波峰为640,963 nm,波谷为675,955,970 nm。
进行光谱预处理能有效地消除由于仪器噪音、暗电流等因素的影响,因此本研究采用标准正态变量变换(Standard normal variate transformation,SNV)、Savitzky-Golay卷积平滑处理法(SavitZky-Golay,S-G)、多元散射校正(Multivariate scatter correction,MSC)、移动窗口平滑(Moving-average method,MA)等预处理方法。由图2可知,原始光谱所建模型效果最好,下文中选择原始光谱进行特征波长的提取。

图4 原始光谱信息
3.3 光谱特征波长的提取
由于实验采集的高光谱反射图像包含较多的波段,且波段之间存在较大的相关性及冗余信息,为提高模型的预测速度和精度,进行光谱特征波长的提取。
3.3.1 GA提取特征波长
GA算法使用现则、交叉和变异三类遗传算子把复杂的模型用繁殖机制结合简单的编码技术表现,并不断地进行迭代、优化来进行优胜劣汰,得到最优解。
以对原始光谱利用GA算法提取特征波长为例,在GA算法中设定初始群体为30,交叉率为50%,变异率为1%,迭代次数为100,以最小的RMSECV值作为评价标准,筛选出在迭代过程中出现频次较多的波长点作为最优提取的特征波长;经过20次随机搜索后,最终提取的特征波长点数目为72,占原始光谱信息16.40%的特征波长如图5所示。

图5 红提糖度的GA特征波长选取图
Fig.5 GA characteristic wavelength selection map of red globe grape sugar content
3.3.2 连续投影算法
连续投影算法(Successive projection algorithm,SPA)是一种可有效消除变量共线性的算法。对经过IRIV特征波长提取后的光谱信息利用SPA算法提取特征波长,设定波长选择变量数范围为5~35,选择步长为1,根据RMSEC的变化确定选择特征变量个数,最终提取的特征波长点数目为23,如图6(a)所示;在原始光谱中所选特征波长位置如图6(b)所示。

图6 红提糖度的SPA特征波长选取图
Fig.6 SPA characteristic wavelength selection map of red globe grape sugar content
3.3.3 CARS提取特征波长
对原始光谱利用竞争性自适应加权算法(Competitive adaptive reweighted sampling,CARS)提取特征波长,本研究设定蒙特卡罗采样为50次,采用5折交叉验证法。由图7可知,取采样50次所建立的PLSR模型中所对应的最小RMSECV作为最优结果。由图7(b)可知,当RMSECV值达到最小值时,各变量的回归系数位于图7(c)中竖直线位置,采样运行24次,最终提取的特征波长点数目为35。

图7 红提糖度的CARS特征波长选取图。(a)采样变量数;(b)RESECV;(c)回归系数路径。
Fig.7 CARS characteristic wavelength selection map of red globe grape sugar content. (a) Number of sampled variables. (b) RESECV. (c) Regression coefficients path.
3.3.4 IRIV提取特征波长
迭代保留信息变量法(Iteratively retains informative variables,IRIV)是一种新型变量选择算法。该算法假设所有变量被采样的几率相同,充分考虑波长变量间的联合效应,根据对模型的有益程度将变量分为强信息变量、弱信息变量、无信息变量和干扰信息变量。在特征变量选择过程中,移除无信息变量和干扰信息变量,保留有益的强信息变量和弱信息变量[21],并利用反向消除策略对剩余变量进行消除,得到特征变量。对原始光谱利用CARS算法提取特征波长,设定IRIV算法的最大主成分为10,交叉验证次数为5,最终提取的特征波长点数目为42。经过IRIV提取的特征波长如图8所示。

图8 红提糖度的IRIV特征波长选取图
Fig.8 IRIV characteristic wavelength selection map of red globe grape sugar content
3.4 图像特征提取
获得红提高光谱图像信息灰度共生矩阵的纹理信息,结合图像的颜色信息(R、G、B、H、S、V、L、a、b),组成19个图像特征参数,采用主成分分析(Principal component analysis,PCA)算法[22]对图像信息进行降维。PCA算法的原理是沿着协方差最大的方向由高维数据空间向低维数据进行空间投影,获得相互独立的主成分分量。该算法既可以去除原始数据中的大量冗余信息,又可以最大限度表征原始信息。
由于提取的图像特征量纲的不同,在进行PCA降维前,先进行归一化运算。由图9可知,对提取的19个图像特征进行PCA降维后提取的前5个主成分的累积贡献率已经达到99.992%,完全达到了建模的要求,为简化模型的运算速度和可靠性,对PCA降维提取的前5个主成分进行建模研究。

图9 基于主成分分析算法的图像特征提取
Fig.9 Image feature extraction based on principal component analysis algorithm
3.5 模型建立及结果比较
3.5.1 光谱模型建立
基于特征波长建立的红提糖度PLSR预测模型和LSSVM预测模型如表3、4所示。由表3、4可知,对于建立的PLSR模型和LSSVM模型,一次降维和组合算法特征波长提取后两种模型的校正集和预测集的相关系数相近,都有效地提高了模型的稳定性。在一次降维特征波长提取后进行SPA后的组合算法有效地提高了各个一次降维所建模型的相关系数和残差预测偏差,均方根误差减小,说明模型的预测精度提高,模型稳定性增强。进行组合算法可有效地剔除冗余信息,提取有效信息,大大简化模型。

表3 基于特征波长建立的红提糖度PLSR预测模型
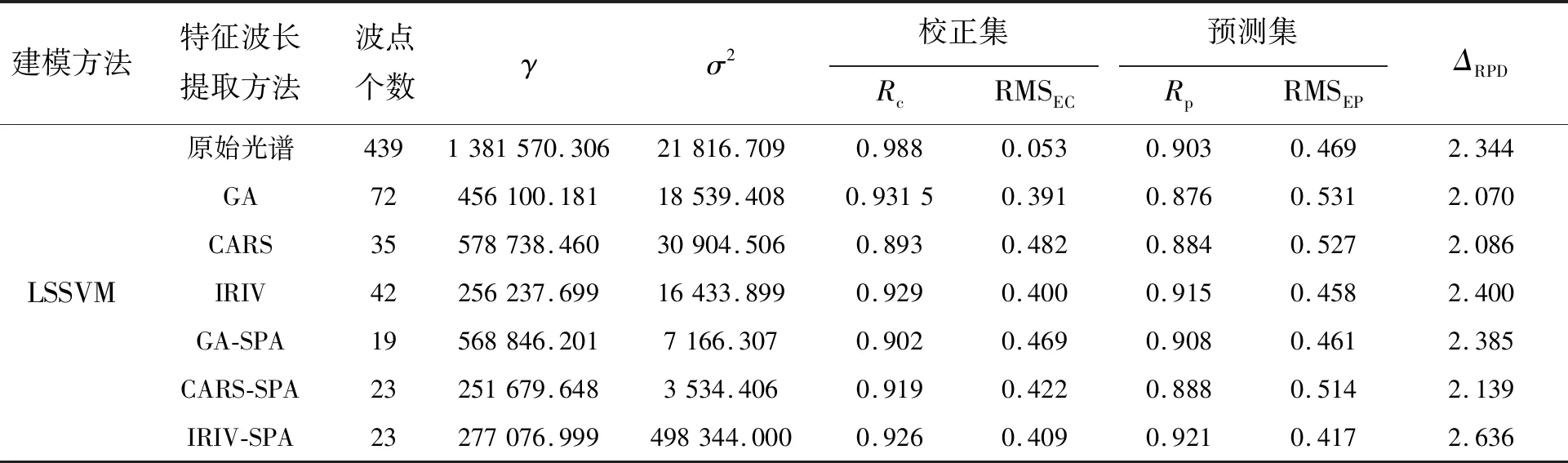
表4 基于特征波长建立的红提糖度LSSVM预测模型
高光谱采集后利用光谱信息,通过IRIV-SPA特征波长提取后,挑选出了有用的光谱特征信息,简化了模型。红提糖度最优模型特征波点如表5所示。

表5 糖度最优模型特征波点列表
3.5.2 图像模型建立
基于图像信息建立的红提糖度PLSR和LSSVM预测模型如表6所示,利用提取的19个图像特征分别建立PLSR模型和LSSVM模型,模型的相关系数低于0.65,模型的预测性能不佳。LSSVM模型的相关系数和残差预测偏差大于PLSR模型,效果要好于PLSR模型。

表6 基于图像信息建立的红提糖度PLSR和LSSVM预测模型
3.5.3 光谱特征和图像特征融合建模
基于光谱信息融合图像信息建立的红提糖度PLSR和LSSVM预测模型如表7所示。由表7可知,通过PCA算法提取图像特征后建立模型的相关系数与19个原始图像特征相比,模型的相关系数增大,模型性能有所提高。利用光谱特征建立模型的相关系数大于图像特征所建模型,光谱信息与图像信息相比,能更好地预测红提糖度。图像光谱融合后所建模型最好,模型的稳定性最好,所建的LSSVM模型效果好于PLSR所建模型的效果。
表7 基于光谱信息融合图像信息建立的红提糖度PLSR和LSSVM预测模型
Tab.7 Prediction model of red globe grape sugar content PLSR and LSSVM based on spectral information fusion image information

特征(数量)PLSR模型LSSVM模型RcRMSECRpRMSEPΔRPDRcRMSECRpRMSEPΔRPD图像特征(5)0.6270.9650.6010.9081.2100.6510.9390.6320.8641.272光谱特征(23)0.9170.4310.9150.4482.4540.9260.4090.9210.4172.636图像光谱融合(28)0.9430.3670.9410.3613.0450.9540.3290.9520.3323.311
3.5.4 最优模型结果比较
分别利用图像光谱融合建立红提糖度的PLSR及LSSVM模型,校正集和预测集样本的预测值和化学测量值之间的散点图如图10~11所示。
由图10、11可知,校正集和预测集的数据都比较集中,模型的预测效果较好;所建立的红提糖度的最优PLSR模型的校正集和预测集的相关系数分别为0.943和0.941,所建立的红提糖度的最优LSSVM模型的校正集和预测集的相关系数分别为0.954和0.952,LSSVM模型可以更好地预测红提的糖度。
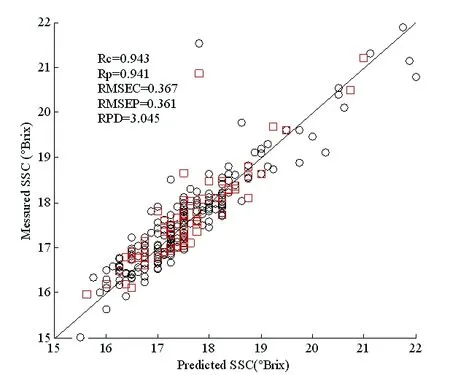
图10 基于IRIV-SPA-PLSR红提糖度最优PLSR模型
Fig.10 Optimal PLSR model based on IRIV-SPA-PLSR red globe grape sugar content

图11 基于IRIV-SPA-LSSVM红提糖度最优LSSVM模型
Fig.11 Optimal PLSR model based on IRIV-SPA-LSSVM red globe grape sugar content
4 结 论
本文利用光谱信息进行建模分析,IRIV-SPA组合降维算法可有效地提取红提糖度光谱信息的特征波长;只利用图像信息进行建模分析,模型的预测性能不佳;将IRIV-SPA特征波段提取后的光谱和经PCA降维后的图像信息进行融合所建模型的效果最好,并将融合信息分别建立PLSR和LSSVM模型,红提糖度的最优PLSR模型的校正集和预测集相关系数分别为0.943和0.941;红提糖度的最优LSSVM模型的校正集和预测集相关系数分别为0.954和0.952;同时有效地提高了红提糖度预测性能,为红提糖度的检测找到了一种新的方法。
非线性LSSVM模型的效果好于线性PLSR模型,且模型更加稳定,但模型的运算时间较长。
猜你喜欢
今日农业(2022年13期)2022-09-15
江苏农业科学(2019年6期)2019-09-25
绿色科技(2017年20期)2017-11-10
中国管理信息化(2017年5期)2017-06-22
中国糖料(2016年1期)2016-12-01
中国照明(2016年4期)2016-05-17
分析化学(2015年6期)2015-06-18
软件导刊(2015年1期)2015-03-02
中国当代医药(2015年26期)2015-03-01
物理实验(2015年9期)2015-02-28
