
一种大规模并行作业运行故障快速定位方法
2019-12-19 06:24朱光慧曾云辉
郑州大学学报(理学版) 2019年4期
朱光慧, 曾云辉
(1. 齐鲁工业大学(山东省科学院) 山东 济南 250101; 2. 山东省计算中心(国家超级计算济南中心) 山东 济南 250101; 3.山东省计算机网络重点实验室 山东 济南 250101)
0 引言
随着E级计算机的建设,高性能计算系统日益复杂.由于参与大规模计算的节点数巨大,并行作业运行过程中发生故障的概率也随之增加[1].目前,利用已有的作业管理系统和工具,在一定程度上可以获取作业运行状态、计算资源状态及其故障信息.但是,一方面,由于导致故障发生的原因复杂多样且关联性强,仅通过获取的故障信息无法清晰地定位故障根源;另一方面,由于故障处理策略不合理,导致故障响应时间过长,无法快速恢复.因此,如何充分利用获取到的故障信息进行快速的故障定位是亟须解决的关键问题.
针对故障定位问题,国内外许多学者提出了不同的解决方案.文献[2-3]分别为高性能计算系统如“天河二号”等提供了一种轻量级的分布式数据收集框架,有助于更好地进行故障检测与分析.文献[4]基于超图理论实现了网络空间中任务故障到作业故障、作业故障到资源故障的定位.文献[5]介绍了在高性能计算集群环境下实现的故障监控管理系统及其功能实现.文献[6]提出并分析了高性能计算系统中故障的发生概率、位置、时间分布等特征.文献[7]提出通过主动探测技术实现故障定位.文献[8]较为详细地论述了基于规则、模型以及案例的事件关联实现方式.为了预防故障,有些学者研究故障预警技术[9-10],如Blue Gene/P和故障容错技术. 基于检查点的恢复技术[11]是从应用程序层面采取的一种有效保护措施.但是,现有容错方法都会引起可靠性墙,必须研究故障影响系统的规律和探索新的方法.通过分析高性能计算系统组成及其功能模块之间的关联关系发现,系统中的关键服务和关键组件对作业运行的影响较大,往往可以通过问题规模及其分布范围表现出来,目前针对这方面的研究较少.因此,本文结合机器架构的关联关系提出了一种基于问题规模的故障快速定位方法,考虑了从提交作业到作业退出整个生命周期中可能出现的问题.该方法由上而下、逐层排查故障原因,缩小了故障的处理范围,有助于运行管理人员根据故障的严重等级,优先处理影响范围大、紧急度高的故障,缩短了故障的响应时间,有效解决了大规模作业运行过程中故障快速定位的问题.
1 基于状态信息的故障发现
高性能计算系统包括由处理器构成的运算系统、提供存储服务的文件系统、用于系统管理的控制管理节点及高速互联网络等.高性能计算系统结构示意图如图1所示.
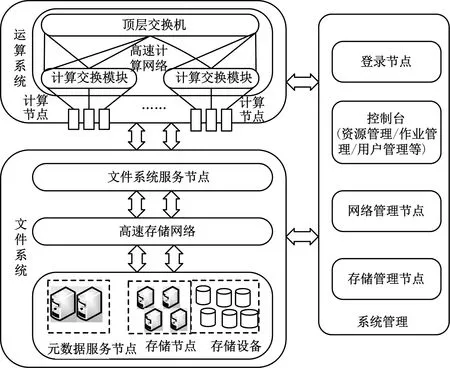
图1 高性能计算系统结构示意图Fig.1 Architecture of high performance computing system
用户通过登录节点使用超级计算机,在上传程序和数据后提交计算作业.在作业结束后,用户提取计算结果数据进行使用和分析.从用户将作业提交到系统中,到作业完成并退出,每个阶段都有对应的作业状态.作业状态转换关系如图2所示.

图2 作业状态转换关系Fig.2 Job state transition relation
各种作业状态的含义如下.
1) PEND:作业正在调度.正在队列中进行调度并等待分派系统资源,作业还未占用系统资源.
2) STARTING:作业正在启动.分配到系统资源后至作业启动完成并开始运行之间的过渡状态.
3) RUN:作业正在运行.作业已经完成调度和分派,作业占用系统资源.
4) DONE:作业正常完成并退出.
5) EXIT:作业异常完成并退出.
6) HANG:作业挂死.仍显示RUN,但作业数据已停止输出,且没有退出.
除了作业本身的运行状态,还需要通过已有的系统监测管理工具获取作业运行所依赖的系统资源状态,包括计算节点状态、网络系统状态、文件系统状态等.其中计算节点状态是指高性能计算系统中计算节点的状态,包括idle节点空闲、busy节点忙、boot节点正在引导、hardft节点发生硬件故障、down节点宕机或监测不通、softft节点发生软件错误.网络系统状态是指高性能计算系统中计算节点的网络接口状态,包括ok正常、down关闭、init初始化、need_reboot需要重新加载系统、iblink_err节点IB链路故障.文件系统状态是指高性能计算系统中全局文件系统的状态,包括ok正常、unmounted未挂载.全局文件系统是大规模并行处理计算机系统的关键技术,是一种基于网络共享存储空间的文件系统.
2 对事件进行分类和严重等级分级
按照高性能计算系统组成及其功能和相关关系,导致并行作业运行故障的原因主要包括以下4类事件.
A类事件:运算系统故障.运算系统故障包括电源故障、运算节点插件故障、CPU故障、内存故障、CPU利用率异常、内存利用率异常、运算性能异常、访存性能异常.
B类事件:网络系统故障.网络系统故障包括IB子网管理服务故障、IB子网管理节点故障、IB交换机故障、计算交换模块故障、IB网络端口故障、IB光纤故障、IB带宽异常、IB延迟异常.
C类事件:文件系统故障.文件系统故障包括文件系统服务故障、元数据服务节点故障、文件系统服务节点故障、存储管理节点故障、存储节点故障、磁盘故障、磁盘超限、IO带宽异常.
D类事件:作业与资源管理系统故障.作业与资源管理系统故障包括资源管理总控故障、作业管理总控故障、作业调度器故障、控制台故障.
事件分类的目的是确定故障所属的类型,并将事件分配给相应的系统管理员进行调查分析和处理.事件分级的目的是确定故障的严重程度,以确保支持人员对事件予以相应的关注.事件的严重程度通过事件严重等级策略确定从1 (极高)到4 (低)逐级递减,事件的影响度如表1所示,事件的紧急度如表2所示.其中表1中的关键业务服务为系统功能,具体包括文件系统服务、IB子网管理服务、资源管理总控服务、作业管理总控服务和作业调度服务.事件严重等级的分类根据事件的影响度等级和紧急度等级组合决定,见表3.

表1 事件的影响度Tab.1 Impact of events

表2 事件的紧急度Tab.2 Urgency of events

表3 事件严重等级Tab.3 Severity of events
基于高性能计算系统的逻辑组件,按照表3计算方法,对部分运行故障进行分类、分级,事件分类、分级说明(部分示例)见表4.由表4可知,事件严重等级为1级的事件称为全局事件,2级的事件称为区域事件,1级和2级都属于主要故障;3级的事件称为个别事件,属于局部故障;4级的故障属于系统性能故障.
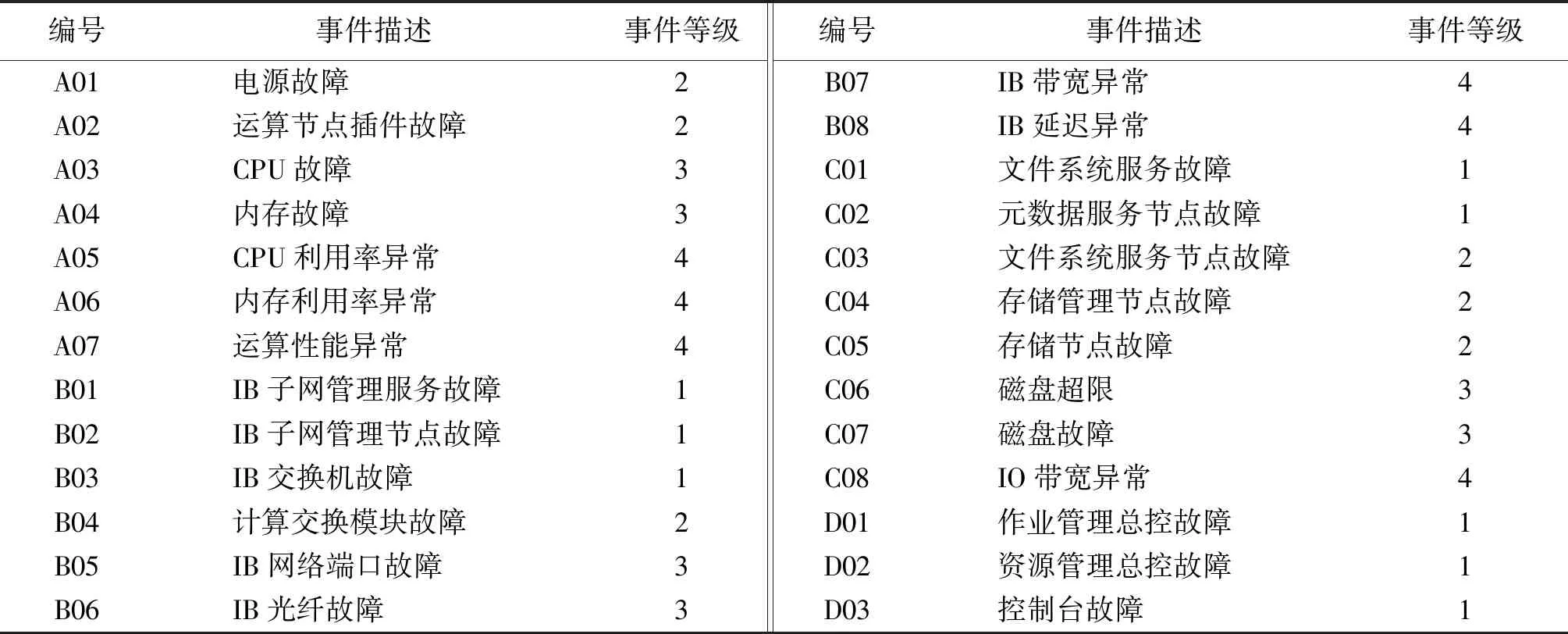
表4 事件分类、分级说明Tab.4 Classification and gradation of events
3 故障定位分析方法
在作业发生故障时,如作业提交不上、作业提交上但一直处于PEND状态、作业提交运行后非正常结束、作业挂死等,可以获取到一些故障信息,主要包括作业ID号、作业状态、与作业相关的故障节点数量,对应的计算节点号、结构号、计算节点状态、HCA卡状态、文件系统状态等.
导致故障发生的原因分为直接原因和间接原因.直接原因通过故障现象本身或直接关联知识库,即可给出故障原因和处理建议;间接原因则通过故障关联分析方法找到故障的根本原因.对于故障之间存在关联关系的情况,可以结合机器的架构特征,首先根据问题规模及其关联关系,判断故障的类型和级别,筛选出主要故障;然后按照已有历史故障处理方法排查局部故障.故障定位分析流程如图3所示.
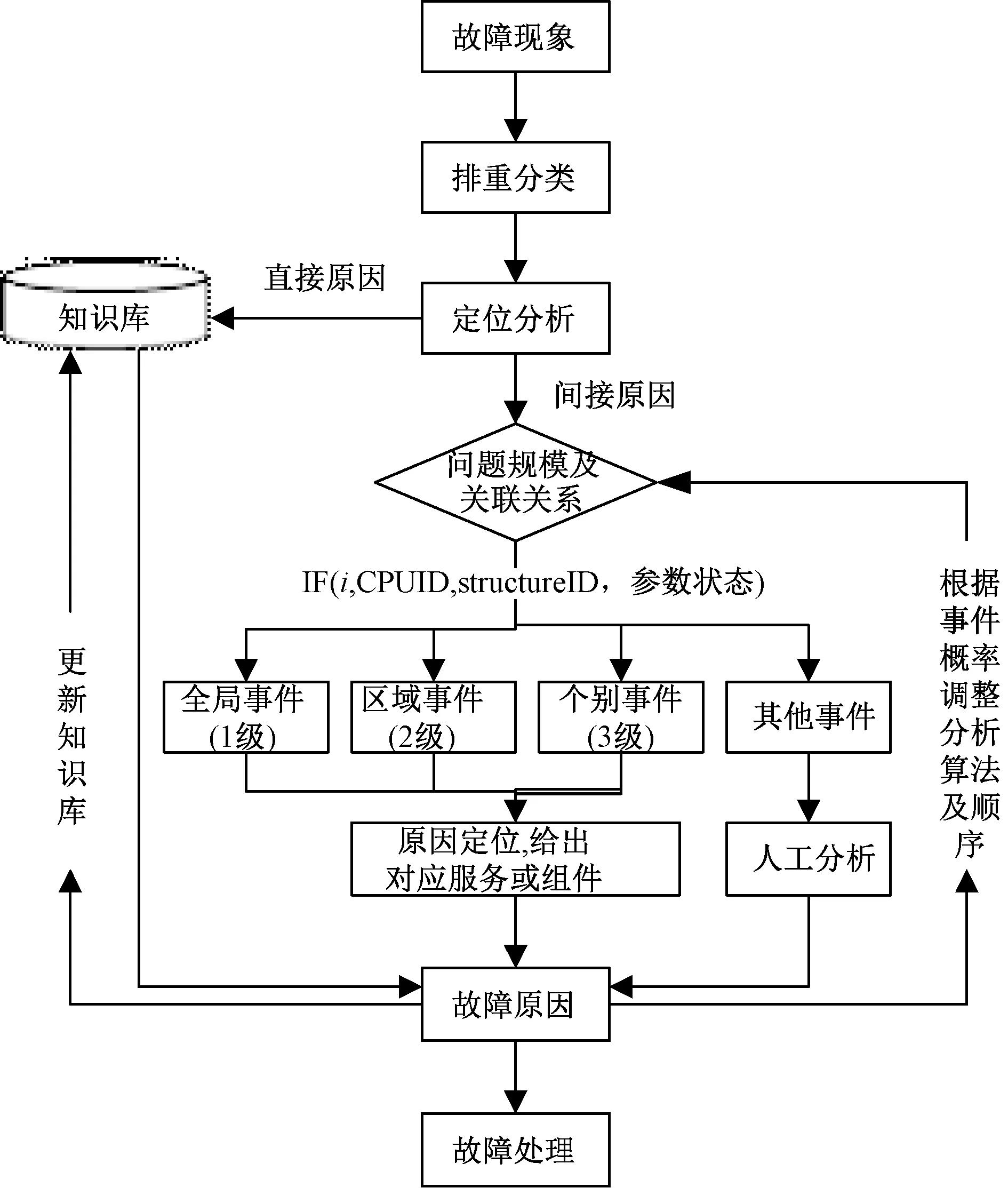
图3 故障定位分析流程Fig.3 Flow chart of fault localization analysis
假设整个系统的计算节点数为n,文件系统服务节点数为m,运算节点插件数为l,计算交换模块数为k,则每n/m个计算节点对应1个文件系统服务节点,每个运算节点插件对应n/l个CPU;运算节点是1个插件,一般由CPU、存储器、连接计算节点的计算交换模块等组成.分析方法如下.
1) 如果作业提交失败,则根据返回的报错信息,通过关联知识库给出故障原因和处理建议,判定为作业与资源管理系统中的作业管理总控故障或资源管理总控故障,事件严重等级为1.关联知识库,即通过查询常见问题知识库,把报错信息和知识库中的记录进行关联,给出故障原因和处理建议;该知识库由运维人员补充和维护.
2) 如果作业提交后一直处于PEND状态,则作业调度失败,判定为作业与资源管理系统中的作业调度器故障,事件严重等级为1;进一步检查作业调度器的状态.
3) 如果作业在启动运行时出现异常,则作业资源分配失败,初步判定为作业与资源管理系统中的资源管理总控故障,事件严重等级为1;进一步检查资源管理总控状态.如果资源管理总控状态正常,则计算资源临时出现故障,判定为运算系统故障或网络系统故障或文件系统故障.
4) 作业完成调度和资源分配后,作业占用的系统资源正在运行中;如果作业运行一段时间后异常退出,则计算资源出现故障,判定为运算系统故障或网络系统故障或文件系统故障.
针对上述计算资源故障,如果出现故障的节点数大于n/l时,则首先根据问题规模及其关联关系判断故障的类型和级别,筛选出主要故障.具体判定方法如下.
1) 如果作业所有节点的文件系统状态为unmounted未挂载,且计算节点状态为softft、网络系统状态为ok正常,则判定为文件系统服务故障,事件严重等级为1;进一步检查文件系统服务状态或元数据服务节点状态.
2) 如果作业所有节点的网络系统状态为init初始化,且计算节点状态为softft、文件系统状态为unmounted未挂载,则初步判定为网络系统中的IB子网管理服务故障,事件严重等级为1;进一步检查IB子网管理服务状态或IB子网管理节点状态.
3) 如果出现连续n/m的整数倍个计算节点的文件系统状态为unmounted未挂载,且计算节点状态为softft、网络系统状态为ok正常,且计算节点的物理结构号对应1个文件系统服务节点,则判定为文件系统服务节点故障,事件严重等级为2;进一步检查对应的文件系统服务节点状态.
4) 如果出现连续n/k的整数倍个计算节点的网络系统状态为down关闭,且计算节点状态为softft、文件系统状态为unmounted未挂载,且计算节点的物理结构号对应1个计算交换模块,则判定为网络系统中的计算交换模块故障,事件严重等级为2;进一步检查对应的计算交换模块状态.
5) 如果出现连续n/l的整数倍个计算节点的网络系统状态为down关闭,且网络系统状态和文件系统状态均无结果显示,且计算节点的物理结构号对应1个运算节点插件,则判定为运算系统中的运算节点插件故障,事件严重等级为2;进一步检查对应运算节点插件的状态或电源状态.
6) 如果作业状态为HANG,则判定为文件系统故障或网络系统故障或计算资源性能异常.按照上述方法将主要故障处理完成后,再排查局部故障和系统性能问题.最后,执行终止作业命令,并重新提交作业进行测试.如果作业运行正常,则问题解决,故障定位结束.
4 实验结果与分析
以神威蓝光国产超级计算机为例,通过实验验证了故障分析方法的有效性.神威蓝光国产超级计算机由8 704颗申威-1600 CPU组成,每颗CPU分成4个核组、16个核心,每128个计算节点对应1个文件系统服务节点,每个运算节点插件对应8个CPU,每相邻32个CPU对应1个运算网络插件.故障分析算法如下.
输入:故障现象;输出:故障原因,并给出处理建议;
其中,异常计算节点列表(n1,n2,…,nK)和结构号,其结构编号格式为机仓号:中板号:插件号,(ri,si,ti)为ni节点的结构号,ni为CPUID.
WHILE(JOB_STATE==EXIT) DO
IF(i>=8 704*20%)THEN
∥首先,根据问题规模进行全局故障初筛;
IF(Bjobs_STATE of i nodes==null) THEN
∥检查作业管理系统服务是否异常;
ELSEIF(GFS_STATE of i nodes==unmounted) THEN
∥检查文件系统服务是否异常;
ELSEIF(HCA_STATE of i nodes==init) THEN
∥检查IB子网管理服务是否异常;
ELSEIF(HCA_STATE of i nodes==down) THEN
∥检查IB交换机是否异常;
ENDIF
ELSEIF(8<=i<8 704*20%)THEN
∥然后,根据问题规模进行区域故障初筛;
IF(GFS_STATE of 128 nodes==unmounted && ni/128==nj/128) THEN
∥检查文件系统服务节点是否异常;
ELSEIF(HCA_STATE of 32 nodes==down && ni/32==nj/32) THEN
∥检查运算网络插件是否异常;
ELSEIF(HCA_STATE of 8 nodes==down && ni/8==nj/8) THEN
∥检查HCA板是否异常;
ELSEIF(CPU_STATUS of 8 nodes==down && ni/8==nj/8) THEN
∥检查运算插件或电源是否异常;
ENDIF
ELSEIF(i<8)
∥最后,处理局部细节故障;
IF(CPU_STATUS of some nodes==down) THEN
∥检查相应的CPU;
ELSE
∥关联知识库
ENDIF
ENDIF
END WHILE
输出故障原因,并给出故障处理建议.
举例说明:某客户提交了2个并行作业,作业1分配的计算资源为0~63号CPU,作业2分配的计算资源为64~127号CPU.在作业运行过程中执行bjobs命令检查发现作业1状态变为EXIT,如图4所示.

图4 作业1状态图Fig.4 The state of Job 1
通过执行cnload命令检查发现计算资源的故障信息,部分示例计算节点状态如图5所示.
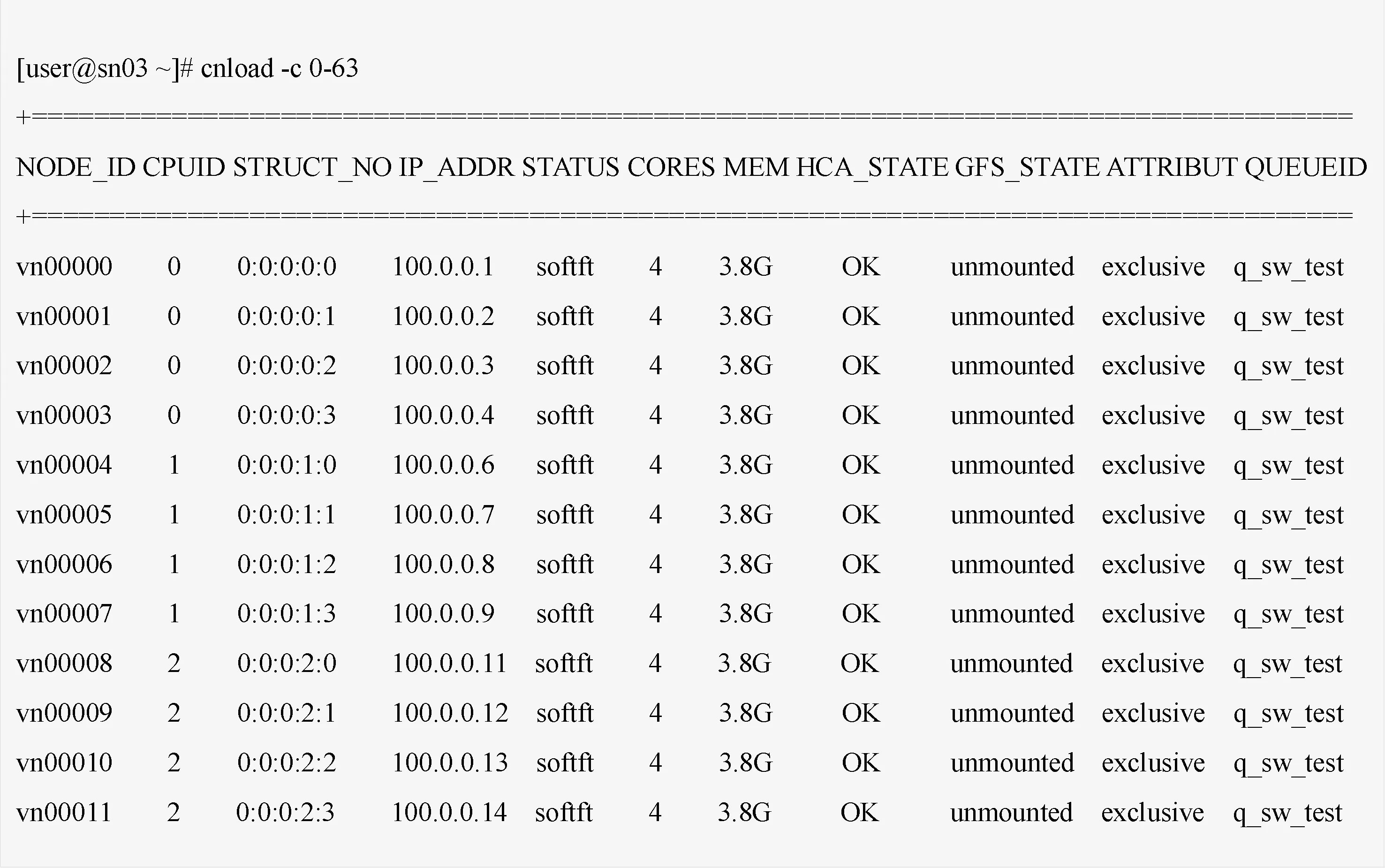
图5 计算节点状态图Fig.5 The state of compute nodes
现有的故障分析方法为:根据故障现象判定作业1已非正常结束,计算节点状态为softft,说明节点已经引导成功,但HCA卡或文件系统不可用,由于网络状态为ok正常,则说明是文件系统为unmounted未挂载导致了计算节点状态不正常.由此,初步判定为文件系统故障,交由文件系统管理员进行排查.由于神威蓝光存储系统是1个两层的存储架构,一旦出现问题,在排除程序和人为因素后,会按照传统的排错方法进一步定位是前端还是后端的故障.如果仍无法定位故障原因,还会涉及运算系统、网络系统等方面的深入排查.如此排查思路不清晰,而且费时又费力.
按照本文方法,基于机器架构进行关联分析的过程为:当检查到作业非正常结束时,首先判定批量作业的问题规模,检查发现作业1和作业2分配的计算节点0~63号和64~127号CPU都出现了同样的文件系统挂载失败现象;根据故障定位分析算法,符合连续的128个计算节点且对应1个文件系统服务节点FS00. 由此,可直接判定为FS00服务节点状态出现异常.通过重启该服务节点后,问题解决并恢复正常.
由此可见,单故障分析时只能获取到资源和作业的一部分信息,而且信息不连续,信息量也有限.而采用本文提出的故障分析方法可以充分利用多个作业运行故障信息来进行综合判断,更有益于全局或区域性的故障排查.
5 结束语
本文提出一种并行作业运行故障快速定位方法,基于机器架构间的关联关系,通过问题规模建立了一种故障快速定位的分析方法,由上而下、逐层排查故障原因,缩小了故障的处理范围,提高了问题分析的时效性,有效解决了高性能计算系统中故障定位难度高且准确性差的问题.本文方法有助于运行管理人员根据故障的严重等级,优先处理影响范围大、紧急度高的故障,缩短了故障的响应时间,有效解决了大规模作业运行过程中故障快速定位的问题.基于近年来神威蓝光超级计算机的运行管理经验,针对主要故障进行了分析,积累了部分知识库,后续还需继续完善知识库,并采用概率统计分析等手段进行故障因素优化的排查顺序和异常事件发生概率的预测.
猜你喜欢
中学生数理化(高中版.高考数学)(2022年1期)2022-04-26
数学小灵通(1-2年级)(2020年6期)2020-06-24
四川大学学报(自然科学版)(2020年2期)2020-04-01
电子制作(2019年22期)2020-01-14
火力与指挥控制(2019年5期)2019-06-13
数码世界(2017年7期)2017-12-29
军事运筹与系统工程(2017年1期)2017-07-31
中学生数理化·八年级数学人教版(2017年2期)2017-03-25
软件(2016年6期)2017-02-06
客车技术与研究(2014年5期)2014-02-28
